人工评测
Download
聚焦模式
字号
人工评测对大模型的输出效果进行评估,提供人工标注的打分模式,客观评估模型效果。
前提条件
自定义评测集准备
准备好评测集后,创建任务时需要选择评测集来源( CFS/GooseFSx/数据源)及其路径。
以 CFS 为例,为方便任务的创建,在准备评测集阶段,需要在开发机中挂载您的 CFS 文件系统,以获得评测时所需填写的路径。CFS 文件系统使用如下:为方便任务的创建,在准备评测集阶段,您需要在开发机中挂载您的 CFS 文件系统,以获得评测时所需填写的路径。CFS 文件系统使用如下:
1. 请您准备好 CFS 文件系统。您可以在挂载您的 CFS 文件系统并启动开发机。假设已经准备好 CFS,且 /data1 代表本地挂载的 CFS 根路径。
2. 您可以根据自己需要,为希望用于评测的主观数据集创建本地对应的主观数据集文件夹。
3. 例如,我们可以将需要的主观数据集 test.csv 放置于
/data1/test_data 目录下:cd /data1mkdir -p test_datacp userdata/test.csv test_data
4. 在评测时,请对应填写您 CFS 实例上的数据集所在的目录,例如
/data1/test_data。注意:
如果填写的目录内包含多个评测集文件,模型评测将对每个评测集文件都进行评测。
操作步骤
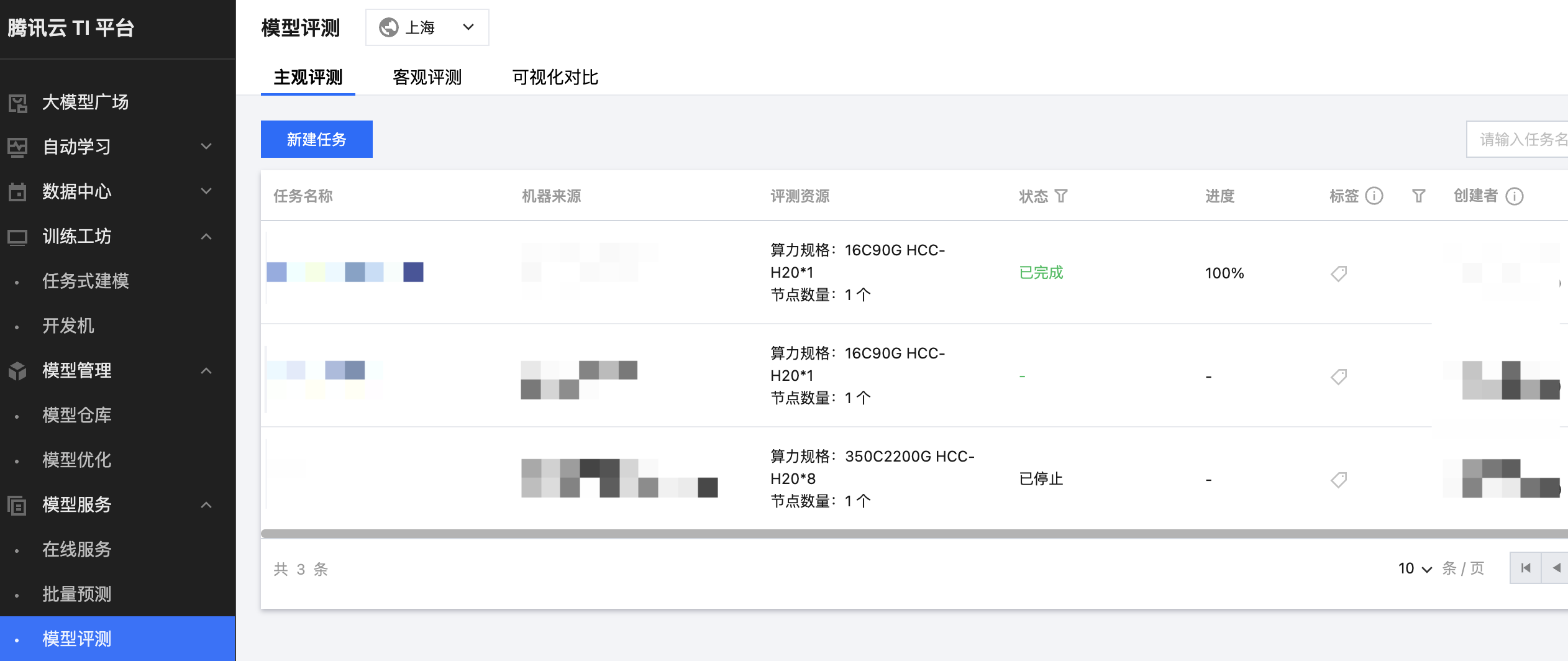
1. 登录 TI-ONE 控制台,在左侧导航栏中选择模型服务 > 模型评测,单击人工评测 Tab 页,进入任务列表页面。
2. 单击新建任务,拉起新建页面。
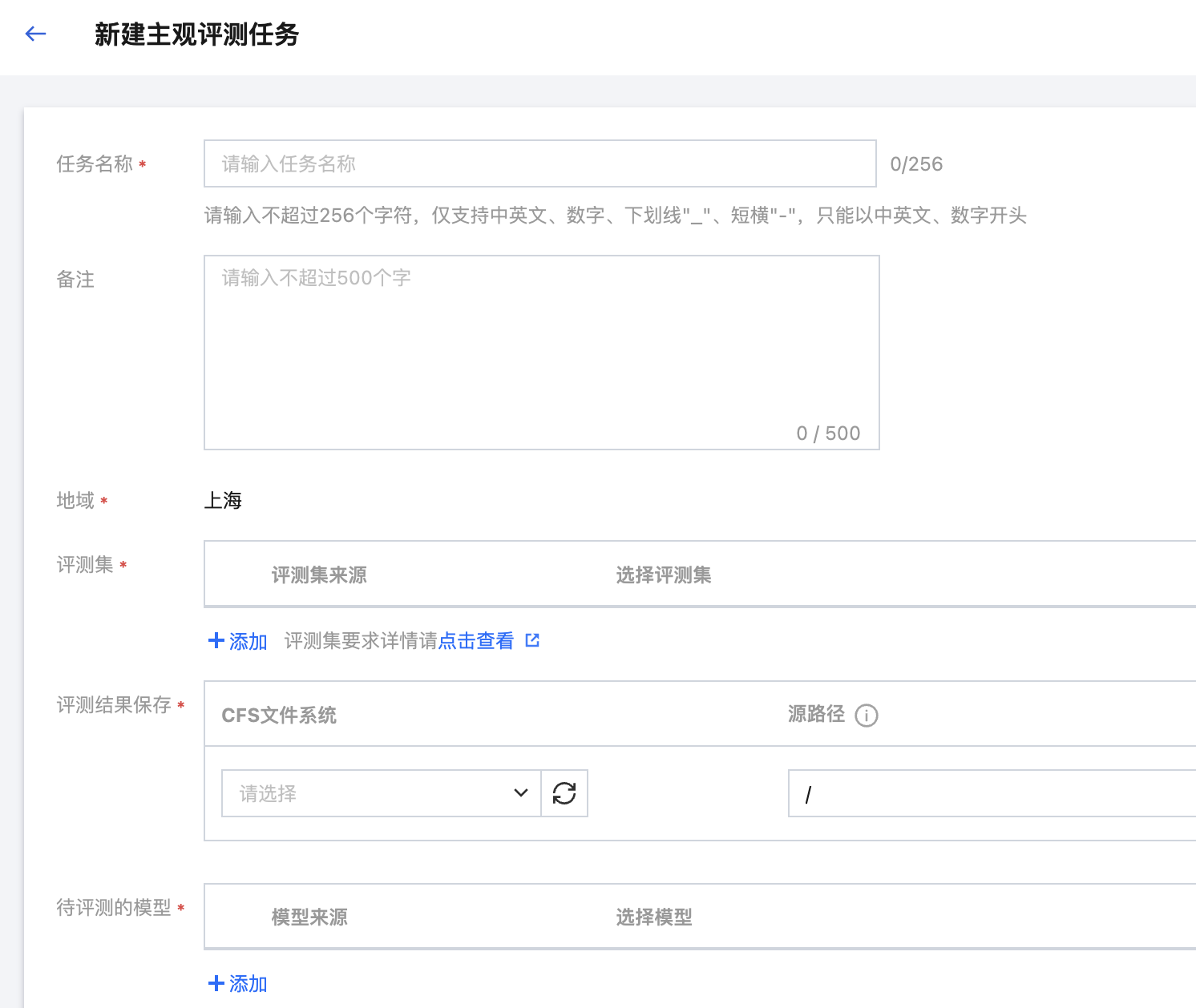
所需填写的信息如下:
参数 | 说明 |
任务名称 | 人工评测任务的名称,按照界面提示的规则填写即可。 |
备注 | 可按需为任务备注描述信息。 |
地域 | 同账号下的服务按地域进行隔离,地域字段取值根据您在服务列表页面所选择的地域自动带入。 |
评测集 | 可选择 CFS/GooseFSx/数据源 文件系统实例和评测数据集所在目录。 若选择数据源,则需要首先在平台管理 > 数据源管理创建数据源(注意:数据源挂载权限分为只读挂载和读写挂载,需要输出训练结果数据的数据源请配置为读写挂载)。 若选择 CFS、GooseFSx,可选择 文件系统实例和评测数据集所在目录。仅支持以下格式:jsonl、csv;内容为2列,分别为“prompt”和“answer”。 可选择内置评测集,一键开启快速评测 |
评测结果保存 | 可选择保存路径为 CFS/GooseFSx/数据源 文件系统实例和评测数据集所在目录。 若选择数据源,则需要首先在平台管理 > 数据源管理创建数据源(注意:数据源挂载权限分为只读挂载和读写挂载,需要输出训练结果数据的数据源请配置为读写挂载)。 若选择 CFS、GooseFSx,则需要下拉选择 CFS 文件系统、GooseFSx 实例,同时填写需要平台挂载的数据源目录。 |
选择待评测的模型 | 支持两种待评测模型来源: 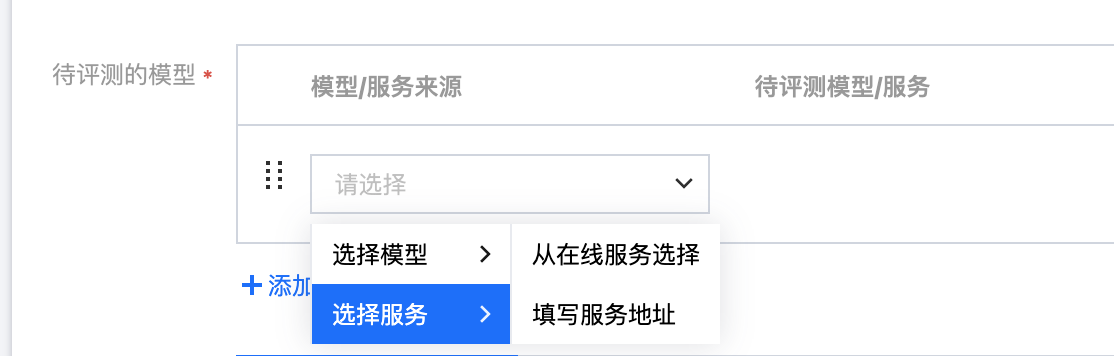 选择模型: 支持选择内置大模型:选择内置好的大模型。 支持从训练任务中选择模型,选择该地域下的训练任务、该任务的 Checkpoint。 支持从 CFS、GooseFSx、数据源中选择模型: 若选择数据源,则需要首先在平台管理 > 数据源管理创建数据源(注意:数据源挂载权限分为只读挂载和读写挂载,需要输出训练结果数据的数据源请配置为读写挂载)。 若选择 CFS、GooseFSx,则需要下拉选择 CFS 文件系统、GooseFSx 实例,同时填写需要平台挂载的数据源目录。 选择服务: 支持从 TI 平台的在线服务选择。 支持填写第三方服务地址进行评测。 支持进行参数设置,支持配置推理超参、启动参数设置和性能参数设置。 配置推理超参,推理超参支持如下: repetition_penalty:用来控制重复惩罚。 max_tokens:用来控制输出文本的最长数量。 temperature:数值越高,输出越随机;数值越低,输出越集中和确定。 top_p、top_k:影响输出文本的多样性,数值越高,生成文本的多样性越强。建议该参数和 temperature 只设置1个 do_sample:确定模型推理时的采样方式,取值 true 时为 sample 方式;取值为 false 时为 greedy search 方式,此时,top_p、top_k、temperature、repetition_penalty 不生效。 配置启动参数,可参考服务部署参数填写指引。平台配置默认参数 MAX_MODEL_LEN,指模型单次推理能处理的最大 token 数(平台默认8192),启动时设置过高可能引发显存溢出或性能下降,可根据任务需求合理调整该值。 配置性能参数,平台配置默认参数 MAX_CONCURRENCY 和 MAX_RETRY_PER_QUERY。 MAX_CONCURRENCY 指评测过程中同时向模型发起的请求数上限;设置过低可能导致模型吞吐量下降导致评测耗时较长,设置过高可能导致显存溢出或请求超时(平台默认24)。用户可根据任务需求合理调整该值。 MAX_RETRY_PER_QUERY 指每条数据在请求推理服务出现异常时(如请求超时或网络故障)的最大重试次数。该值为0则不进行重试(平台默认0)。用户可根据任务需求合理调整该值。 |
计费模式 | 可选择按量付费模式或包年包月(资源组)模式: (A)按量付费模式下,用户无需预先购买资源组,根据服务依赖的算力规格,启动服务时冻结两小时费用,之后每小时根据运行中的实例数量按量扣费。 (B)包年包月(资源组)模式下,可使用在资源组管理模块已购买的资源组部署服务,算力费用在购买资源组时已支付,启动服务时无需扣费。 |
资源组 | 若选择包年包月(资源组)模式,可选择资源组管理模块的资源组。 |
3. 填写对应信息,新建好人工评测任务后,会在任务列表页展示:任务名称、机器来源、评测资源、状态、进度、标签、创建者、创建时间、操作(停止、重启、删除、复制)。
4. 单击推理进度,您可下载查看当前进度下的评测结果集。

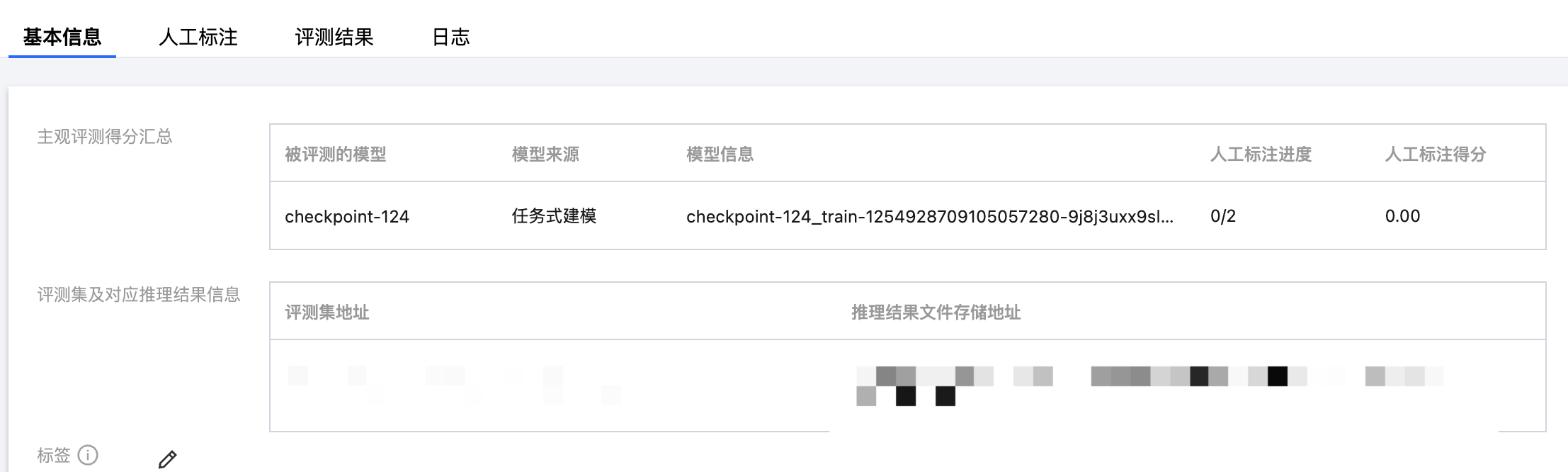
5. 人工评测任务完成后,您可单击任务名称,进入任务详情,查看基本信息、进行人工标注、查看评测结果和日志。
文档反馈