自动评测
Download
聚焦模式
字号
概述
自动评测提供向导式的评测任务提交的方式进行评测任务构建,可直接基于平台内置的评测集快速进行通用效果测试,也可通过自定义评测集以及评测指标的方式启动评测任务,其功能的详细描述为:
入口1:从 任务式建模的 CheckPoint 处新建自动评测
可对训练任务的 CheckPoint 快速轻量化进行评测,用户只需配置任务的基础信息和选择平台提供的内置评测集,便可开启自动评测。
支持对评测结果进行查看。
入口2:从自动评测 Tab 页处新建自动评测
通过内置的开源评测集以及自动指标(如 pass@1、ROUGE、F1 等)快速创建评测任务。
通过使用自定义的评测集、自定义评测指标启动评测任务,支持三种评测模式,分别为“仅评测”模式和“推理及评测”、“自定义评测”的评测模式。
评测模式 | 模式说明 | 指标配置及结果输出 |
仅评测 | 用户上传带模型推理结果的评测集,在自动评测模块完成打分功能。 | 此两种模式下支持自定义评测指标、调试指标、整体结果查看和单条评测结果查看: 自定义指标: 在自定义的评测指标时,需要对每个指标的打分方式进行配置。例如使用裁判模型打分时,需要设置裁判模型、打分 Prompt、以及支持自定义前后脚本对输入输出进行处理,以获得指标结果。 调试指标: 支持在正式发起评测任务前对评测样本进行少量评测,调试时,通过调整打分 Prompt 和前后处理脚本以获得预期的评测效果。 整体结果查看: 支持查看各模型在各评测集的评测结果各模型在各评测集的评测结果查看。 单条评测结果查看: 支持对每条评测数据进行各打分步骤的结果进行查看。 |
推理及评测 | 用户上传只有query(问题)的评测集,在自动评测模块完成推理结果输出和打分。 | |
自定义评测 | 支持用户通过自定义评测镜像进行评测。可将评测集、自定义镜像以及存储挂载等内容合并为一个“任务配置”,每一组配置包含评测集、选择镜像、选择版本、挂载路径设置、启动命令、参数设置、环境变量。用户可通过仅选择镜像和版本,或者选择镜像和版本后再设置挂载路径,以实现镜像或者镜像+挂载路径的方式进行评测。 | |
前置条件
创建自动评测任务时,需要用户准备好评测集(使用内置评测集或者上传自定义评测集)、待评测模型/服务。
准备评测集
内置评测集
自定义上传评测集
和直接使用平台内置的开源评测集不同的是,准备好评测集后,创建任务时需要填写评测集在 CFS/GooseFSx/数据源中的路径。
以 CFS 为例,为方便任务的创建,在准备评测集阶段,需要在开发机中挂载您的 CFS 文件系统,以获得评测时所需填写的路径。CFS 文件系统使用如下:
1、请您准备好 CFS 文件系统。您可以挂载您的 CFS 文件系统并启动开发机。
2、请根据模型评测的格式要求准备评测集。
待评测模型/服务
待评测模型
内置大模型
自有大模型
准备好待评测模型后,创建任务时需要填写评测集在 CFS/GooseFSx/数据源中的路径。获得路径的方式参见上文“准备评测集中的自定义上传评测集”的说明。
待评测模型服务
从在线服务中选择
评测时支持从TI在线服务中选择,用户需要提前在TI在线服务模块把待评测模型启动成服务,部署指南请参见 在线服务部署。
填写服务地址
评测时支持用户输入服务地址,用户需要提前准备好服务并记录服务地址以便填入。
创建入口一共有2处,分别为任务式建模的 CheckPoint 自动评测 、模型评测tab页面的自动评测入口
基于任务式建模的 CheckPoint 新建自动评测
概述:登录 TI-ONE 控制台,在左侧导航栏中选择训练工坊 > 任务式建模,进入任务列表页面。 在任务页面单击训练的任务名称,进入任务详情页面。使用此入口的前提条件为需已完成 任务式建模 的任务创建,已完成 CheckPoint 的输出。
步骤1:配置基础信息和评测集
单击 CheckPoint Tab 页,选择要进行初步体验模型效果的 CheckPoint 卡片。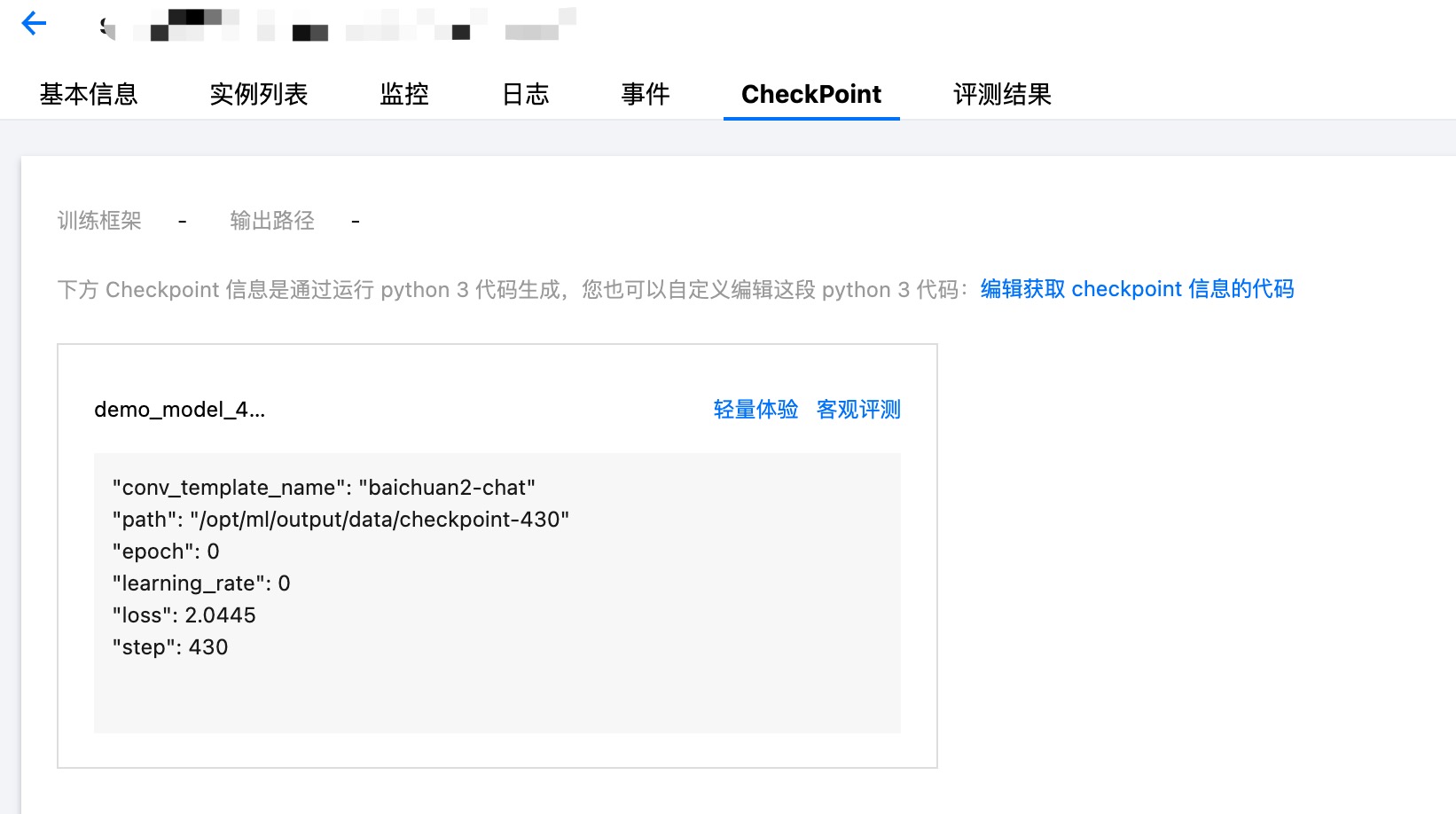
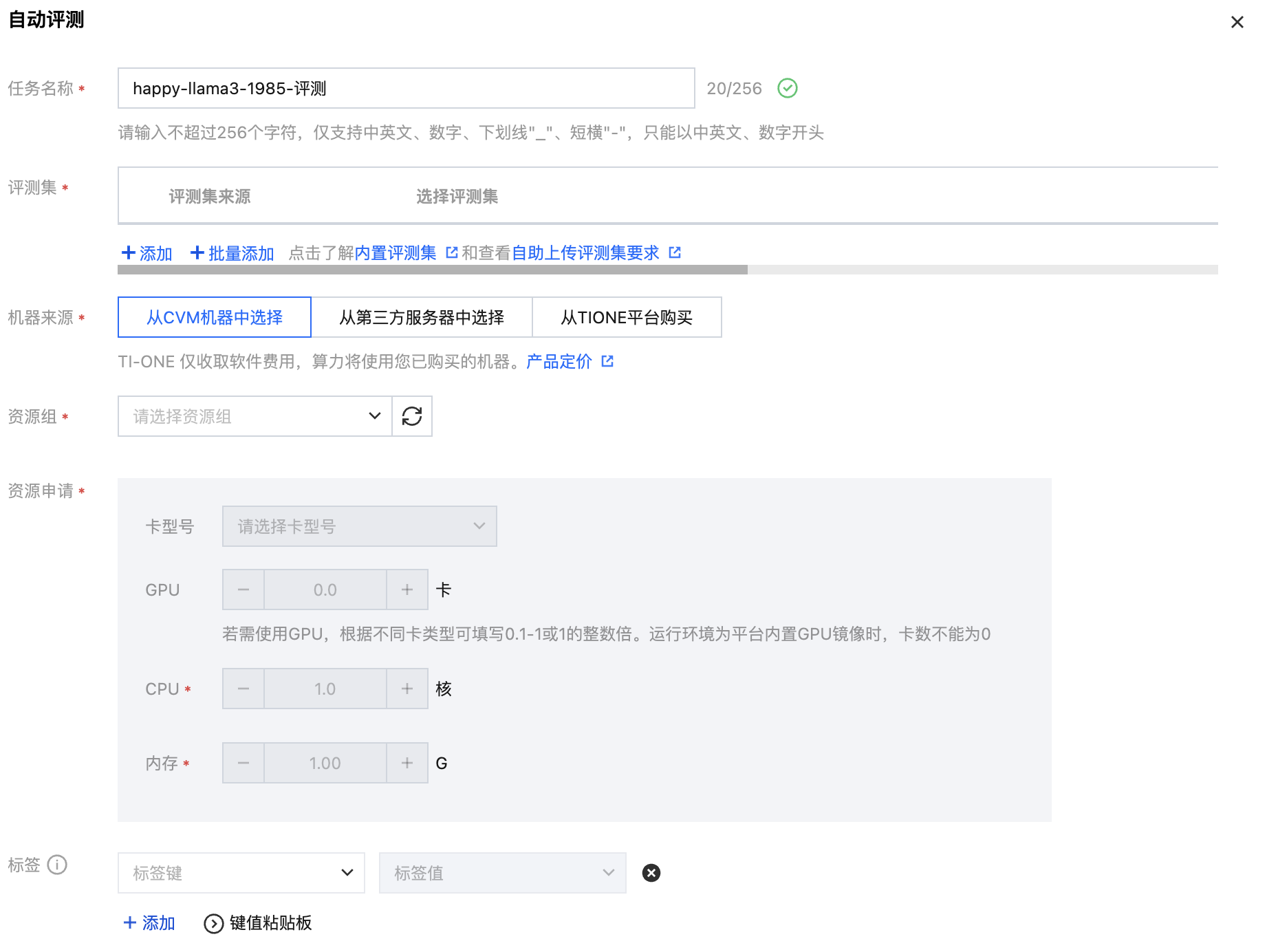
单击自动评测按钮,拉起弹窗,填写任务名称、选择平台内置的评测集,选择所需的资源,支持按量计费和包年包月。目前仅支持对内置评测集进行评测。
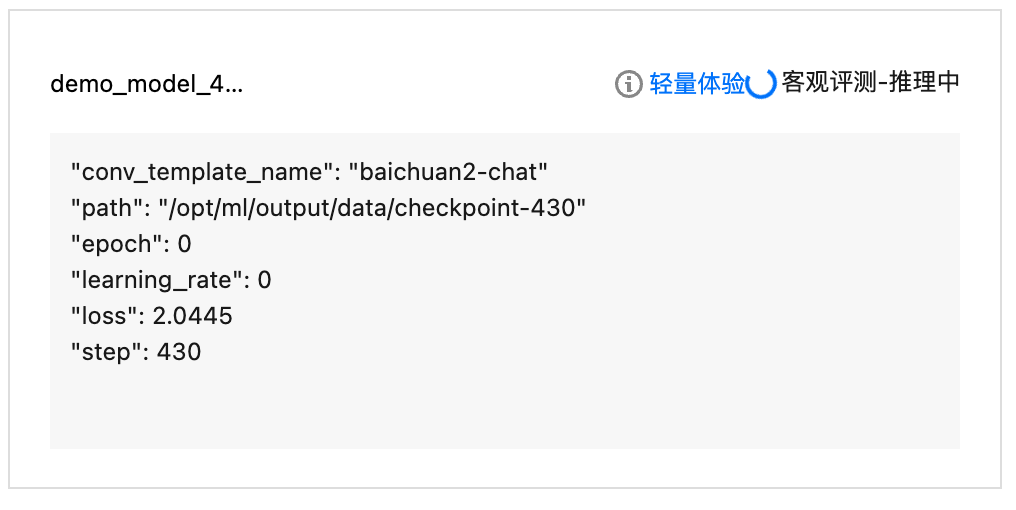
步骤2:评测结果查看
填好信息单击新建,会进入自动评测-推理中的状态,请您耐心等待。
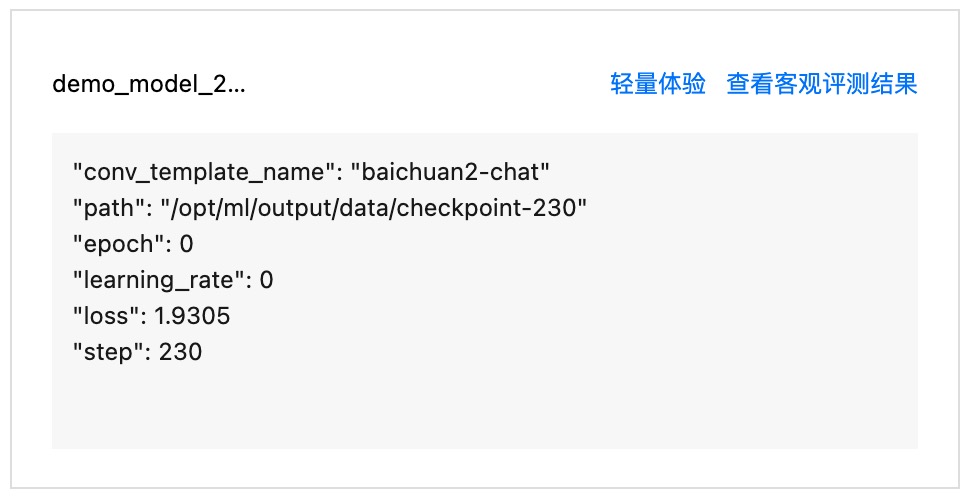
自动评测完成后,可单击查看自动评测结果。
在自动评测模块中新建“仅评测、推理及评测”评测任务
“仅评测”和“推理及评测”的自动评测任务分为两步,第一步为基础任务配置,需要选择评测集、待评测模型、评测资源;第二步为指标配置和调试,需要自定义评测指标及其配置,并且在任务提交前可进行调试,初步查看结果。
“自定义评测”的自动评测任务需要进行任务配置,选择待评测模型、评测资源。
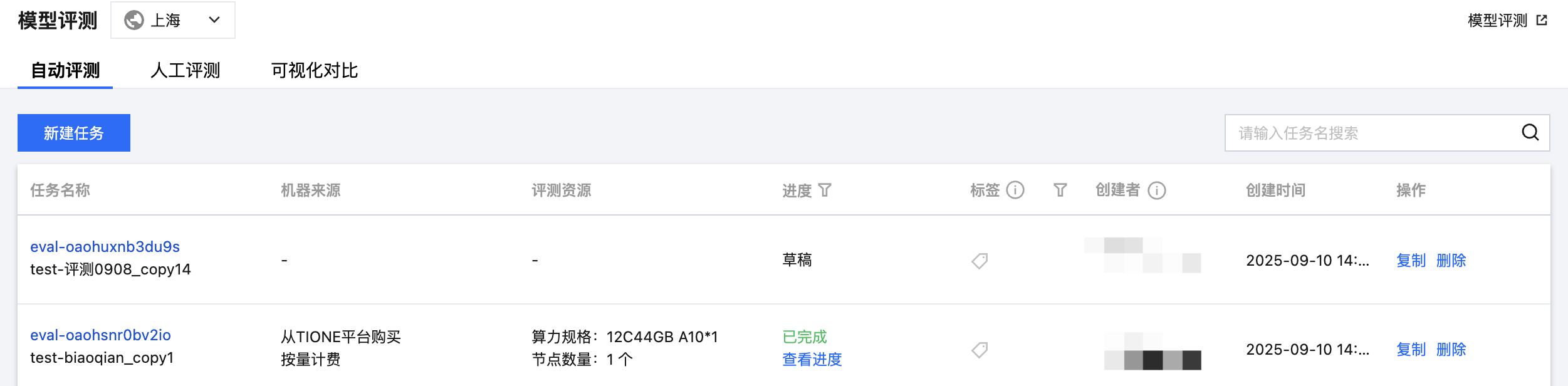
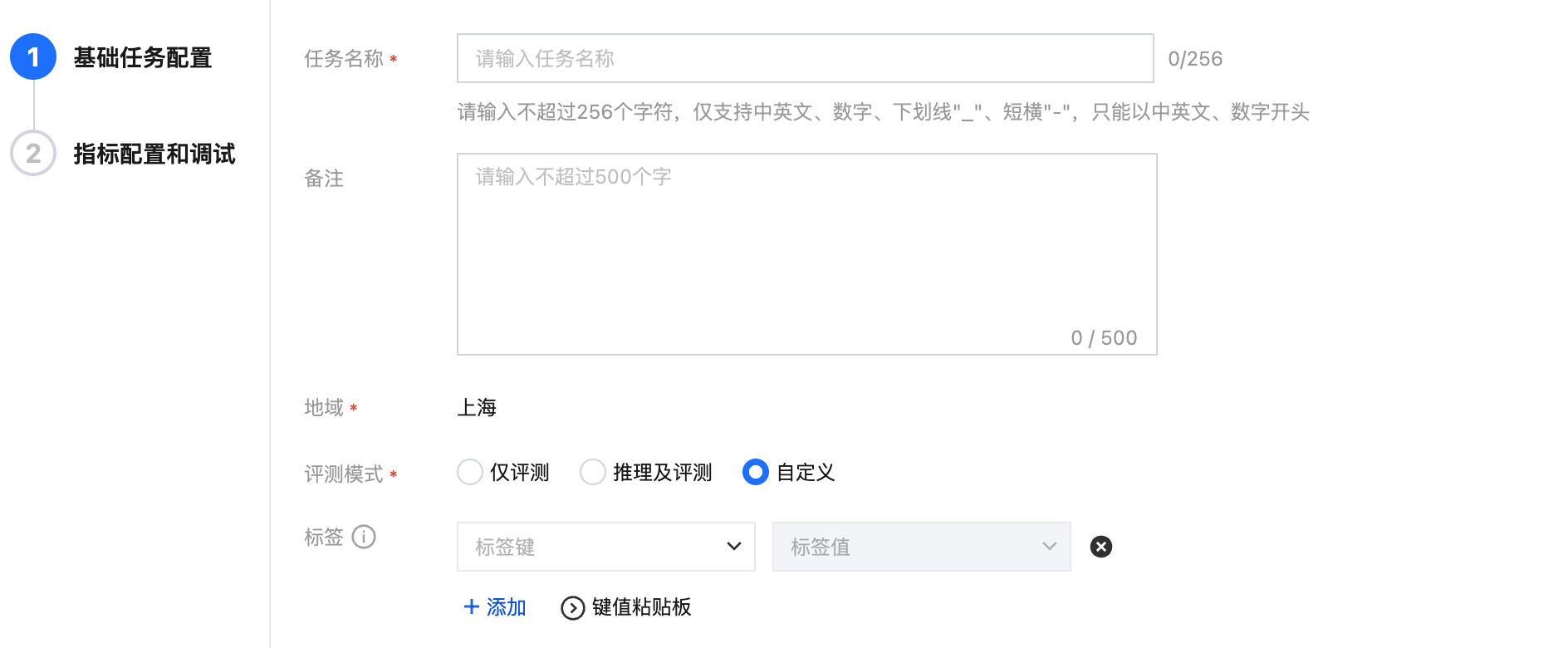
步骤1:配置基础任务
参数 | 说明 |
任务名称 | 自动评测任务的名称,按照界面提示的规则填写即可。 |
备注 | 可按需为任务备注描述信息。 |
地域 | 同账号下的服务按地域进行隔离,地域字段取值根据您在服务列表页面所选择的地域自动带入。 |
标签 | 用于评测任务间进行权限隔离。 |
计费 | 计费模式:当评测模式为“推理及评测”时,可选择按量付费模式或包年包月(资源组)模式: 按量付费模式下,用户无需预先购买资源组,根据服务依赖的算力规格,启动服务时冻结两小时费用,之后每小时根据运行中的实例数量按量扣费。 包年包月(资源组)模式下,可使用在资源组管理模块已购买的资源组部署服务,算力费用在购买资源组时已支付,启动服务时无需扣费。 资源组:若选择包年包月(资源组)模式,可选择资源组管理模块的资源组。 |
步骤2:配置评测集
当评测模式为“仅评测”或者“推理及评测”时,用户需要配置评测集以进行评测,评测集的来源为 内置评测集/数据中心/CFS/GooseFSx/数据源/资源组。配置评测集时,提供对数据进行参数设置/预览的功能。
选择评测集来源
若选择内置评测集,可直接一键开启评测。
若选择数据中心,则需要首先在平台数据中心 > 数据集管理挂载对应的数据集。对于数据中心的评测集,支持在选择时筛选“业务标签”,以提高选择评测集的效率。
若选择数据源,则需要首先在平台管理 > 数据源管理创建数据源(注意:数据源挂载权限分为只读挂载和读写挂载,需要输出训练结果数据的数据源请配置为读写挂载)。
若选择 CFS、GooseFSx,则需要下拉选择 CFS 文件系统、GooseFSx 实例,同时填写需要平台挂载的数据源目录,路径最后一层为文件夹目录,如“
/test_data/ceval” 。挂载时请确保该目录中的数据集为待评测数据集,否则将会评测失败,目前填写路径时暂不支持指定具体的文件名。
评测集参数设置及预览功能
参数设置:支持对评测集批量设置推理超参数和裁判模型打分参数。
推理超参说明如下:
repetition_penalty:用来控制重复惩罚。
max_tokens:用来控制输出文本的最长数量。
temperature:数值越高,输出越随机;数值越低,输出越集中和确定。
top_p、top_k:影响输出文本的多样性,数值越高,生成文本的多样性越强。建议该参数和 temperature 只设置1个
do_sample:确定模型推理时的采样方式,取值 true 时为 sample 方式;取值为 false 时为 greedy search 方式,此时,top_p、top_k、temperature、repetition_penalty 不生效。
裁判模型打分参数说明如下:
MAX_JUDGING_CONCURRENCY:每个待评测模型推理本数据集后,打分时同时向裁判模型发起的请求数上限;设置过低可能由于模型吞吐量下降导致评测耗时较长,设置过高可能导致请求超时。
MAX_JUDGING_RETRY_PER_QUERY:每条数据在打分出现异常时(如网络故障或打分请求排队超时)的最大重试次数;该值为0则不进行重试。注意:较大的重试次数可能导致评测时间延长。
INFERENCE_COUNT:默认生成的推理数据条数。
数据预览:支持对所选数据集进行预览。
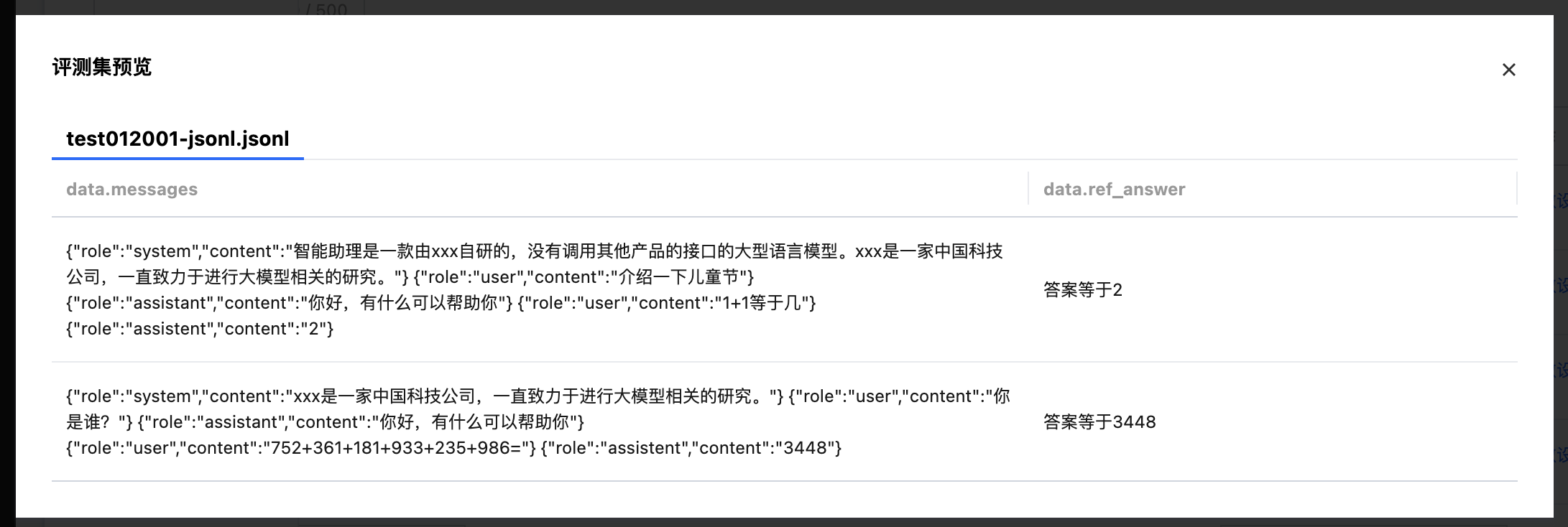
步骤3:配置待评测模型/服务
用户需要选择待评测模型或者服务,以生成推理结果后进行评测。待评测模型来源为 内置大模型/训练任务/CFS/GooseFSx/数据源/资源组 ,模型服务来源为 在线服务/填写服务地址。配置待评测模型/服务时,提供参数设置的功能。
选择模型:
若选择内置大模型快速开启评测。
若从训练任务中选择模型,选择该地域下的训练任务或者该任务的 CheckPoint。
若选择数据源,则需要首先在平台管理 > 数据源管理创建数据源(注意:数据源挂载权限分为只读挂载和读写挂载,需要输出结果数据的数据源请配置为读写挂载)。
若选择 CFS、GooseFSx,则需要下拉选择 CFS 文件系统、GooseFSx 实例,同时填写需要平台挂载的目录。
选择服务:
若选择 从在线服务选择,需要选择在线服务名称,为保证评测的顺利开启请确保服务为正常运行状态。同时,需要选择对应的鉴权信息。
若选择 填写服务地址,需要输入完整的服务调用地址以及对应的鉴权信息。对于此种方式,支持通过连通性测试检查服务是否能够正常运行。
设置参数,支持配置推理超参、启动参数设置和性能参数设置。
配置推理超参,推理超参支持如下:
repetition_penalty:用来控制重复惩罚。
max_tokens:用来控制输出文本的最长数量。
temperature:数值越高,输出越随机;数值越低,输出越集中和确定。
top_p、top_k:影响输出文本的多样性,数值越高,生成文本的多样性越强。建议该参数和 temperature 只设置1个
do_sample:确定模型推理时的采样方式,取值 true 时为 sample 方式;取值为 false 时为 greedy search 方式,此时,top_p、top_k、temperature、repetition_penalty 不生效。
配置启动参数,可参考服务部署参数填写指引。平台配置默认参数 MAX_MODEL_LEN,指模型单次推理能处理的最大 token 数(平台默认8192),启动时设置过高可能引发显存溢出或性能下降,可根据任务需求合理调整该值。
配置性能参数,平台配置默认参数 MAX_CONCURRENCY 和 MAX_RETRY_PER_QUERY。
MAX_CONCURRENCY 指评测过程中同时向模型发起的请求数上限;设置过低可能导致模型吞吐量下降导致评测耗时较长,设置过高可能导致显存溢出或请求超时(平台默认24)。用户可根据任务需求合理调整该值。
MAX_RETRY_PER_QUERY 指每条数据在请求推理服务出现异常时(如请求超时或网络故障)的最大重试次数。该值为0则不进行重试(平台默认0)。用户可根据任务需求合理调整该值。
支持复用以往的评测结果
选择待评测模型时,支持选择以往相同模型名称、相同评测集名称的评测任务的评测结果。
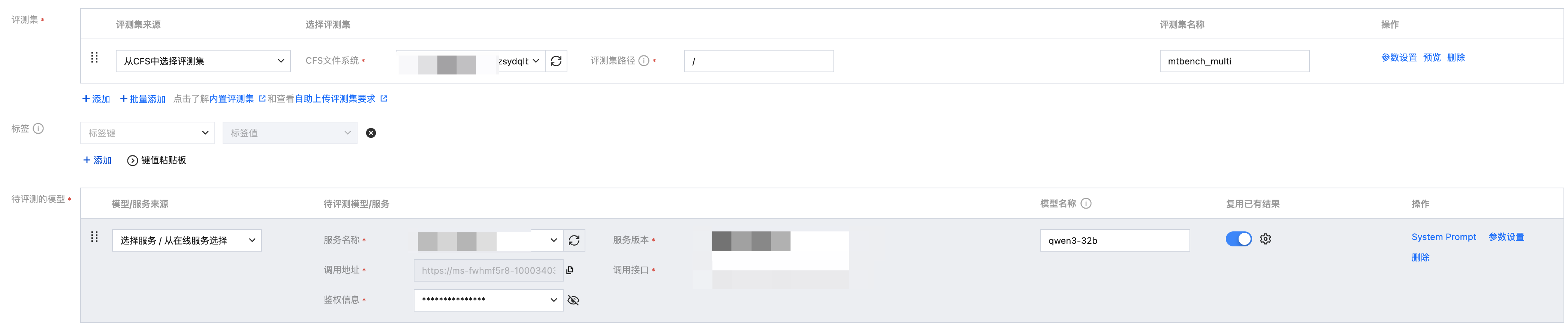
打开复用开关,选择需要复用的评测任务。
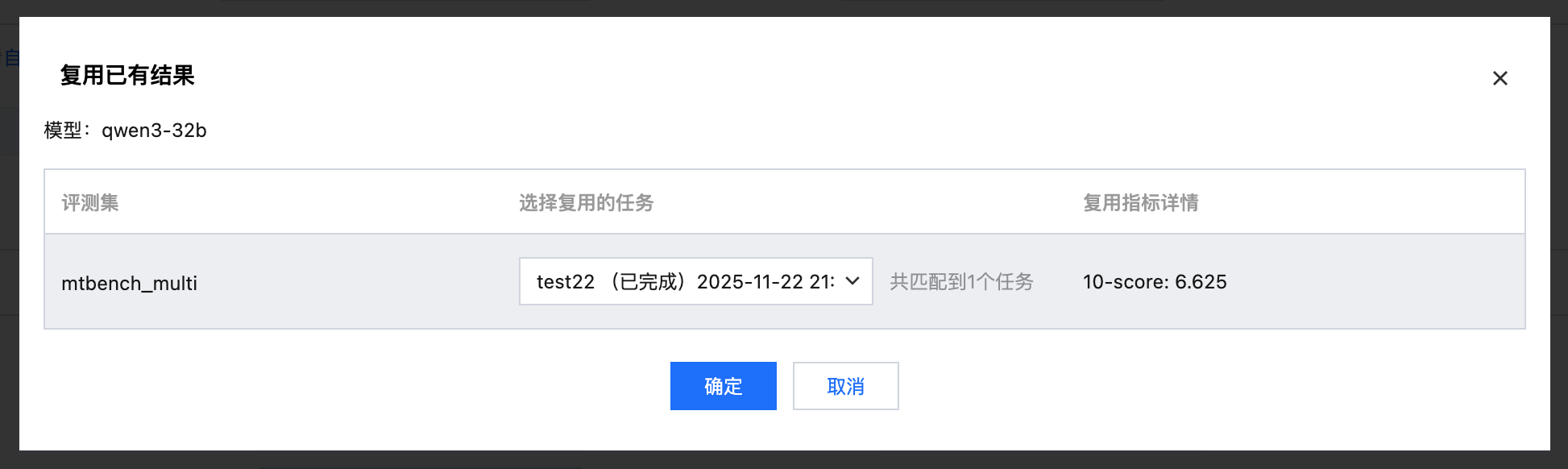
可直接复用结果, 不需要再次进行推理和打分。
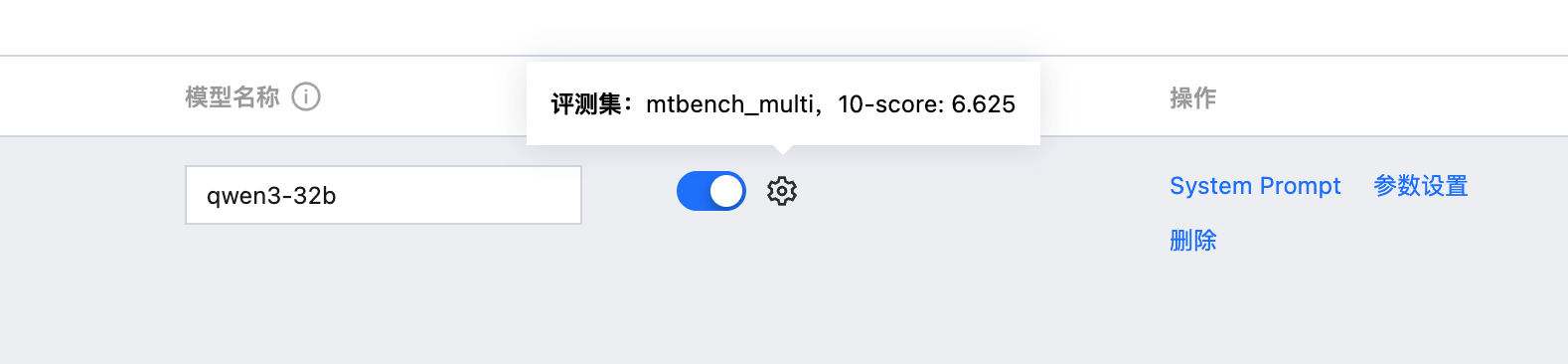
步骤4:配置指标
对于内置评测集,用户无需设置指标,平台将提供默认的指标自动进行评测。对于自定义评测集,用户需要自行设置指标。对于自定义指标提供裁判模型打分的方式进行,同时支持用户自行设置前后处理脚本,以对数据的输入输出高度自定义以获得理想的评测效果。
单击“+指标”按钮进行添加指标,或者通过“+复制已有指标”进行指标添加。指标添加成功后,需要对指标进行配置,配置时支持用户自定义评测流程。评测流程包含前处理、裁判模型打分、后处理,其使用规范请参见 裁判模型打分 Prompt 和前后处理格式要求。
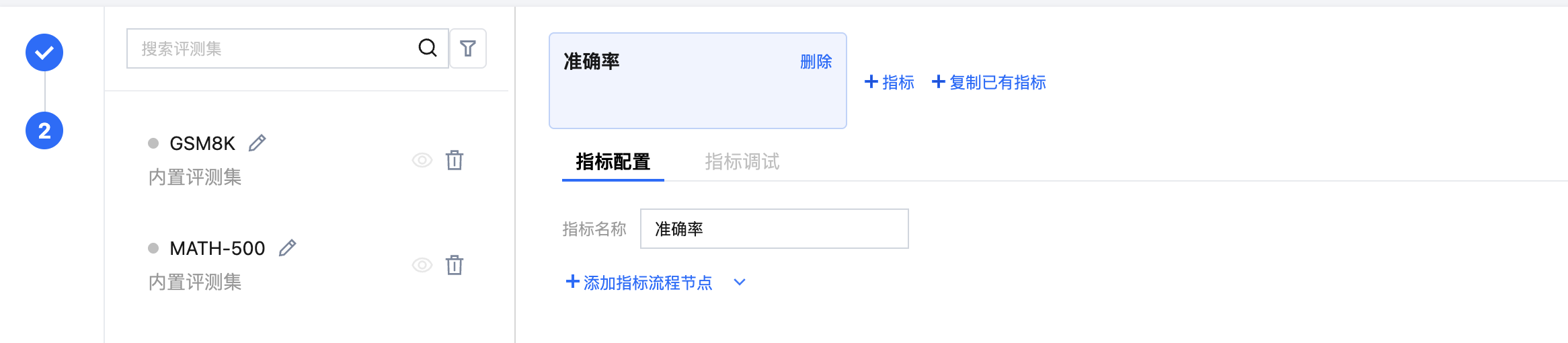
支持通过“快捷配置”高效完成评测指标的配置,“快捷配置”时需要上传文件,文件中需包含评测集、评测集对应的指标名称、每个指标名称对应的详细配置信息(如裁判模型信息、打分 Prompt、前后处理脚本等)。用户点击“快捷配置”按钮,上传自定义 YAML 配置文件以及需引用的文件,上传完毕后单击“应用”按钮,平台将自动根据用户填写的评测集名称对应在 YAML 配置文件中的指标、以及指标的配置信息在页面进行自动填充。快捷配置文件上传指南请参见 指标快捷配置文件规范。
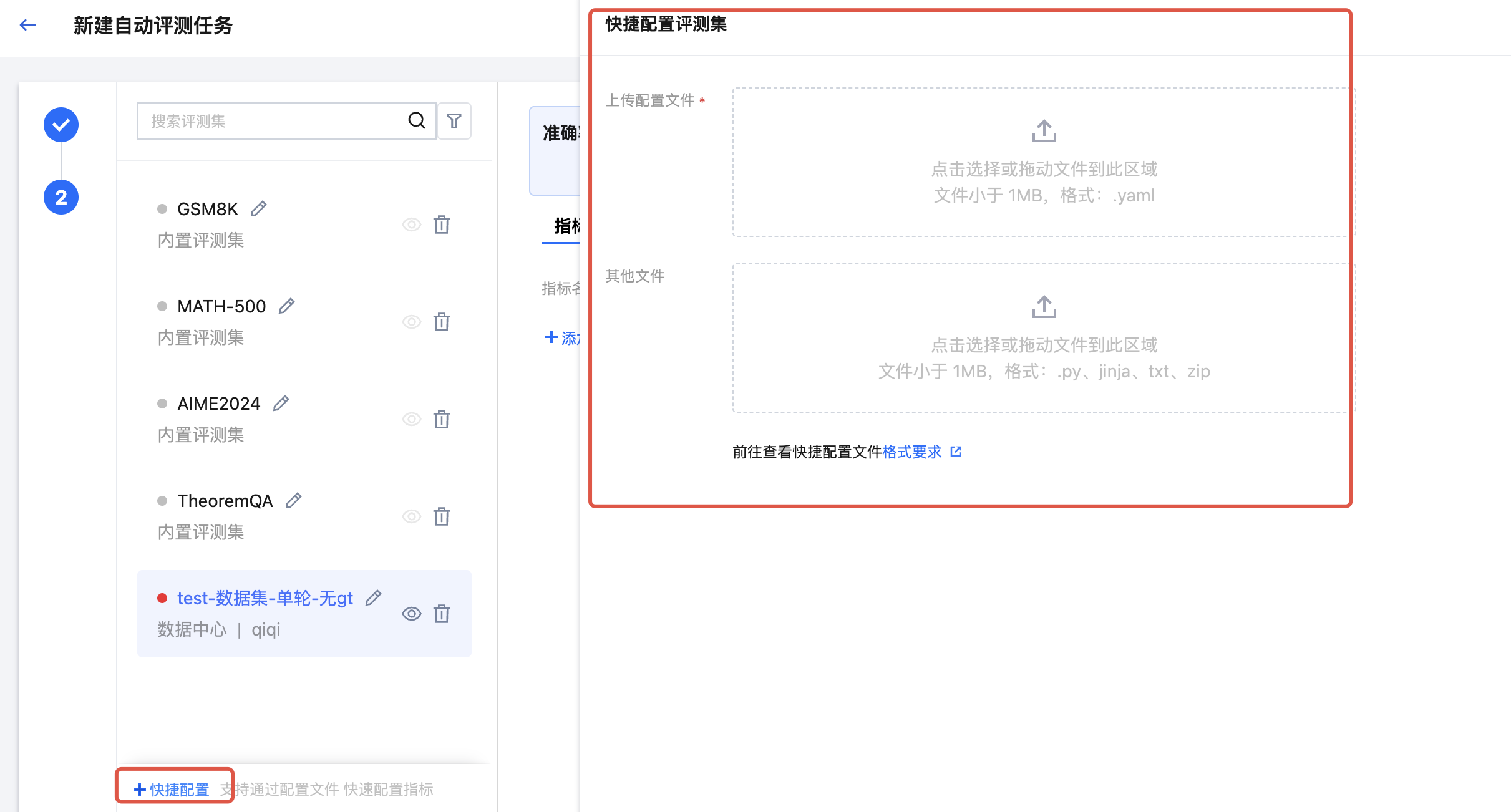
步骤5:调试指标
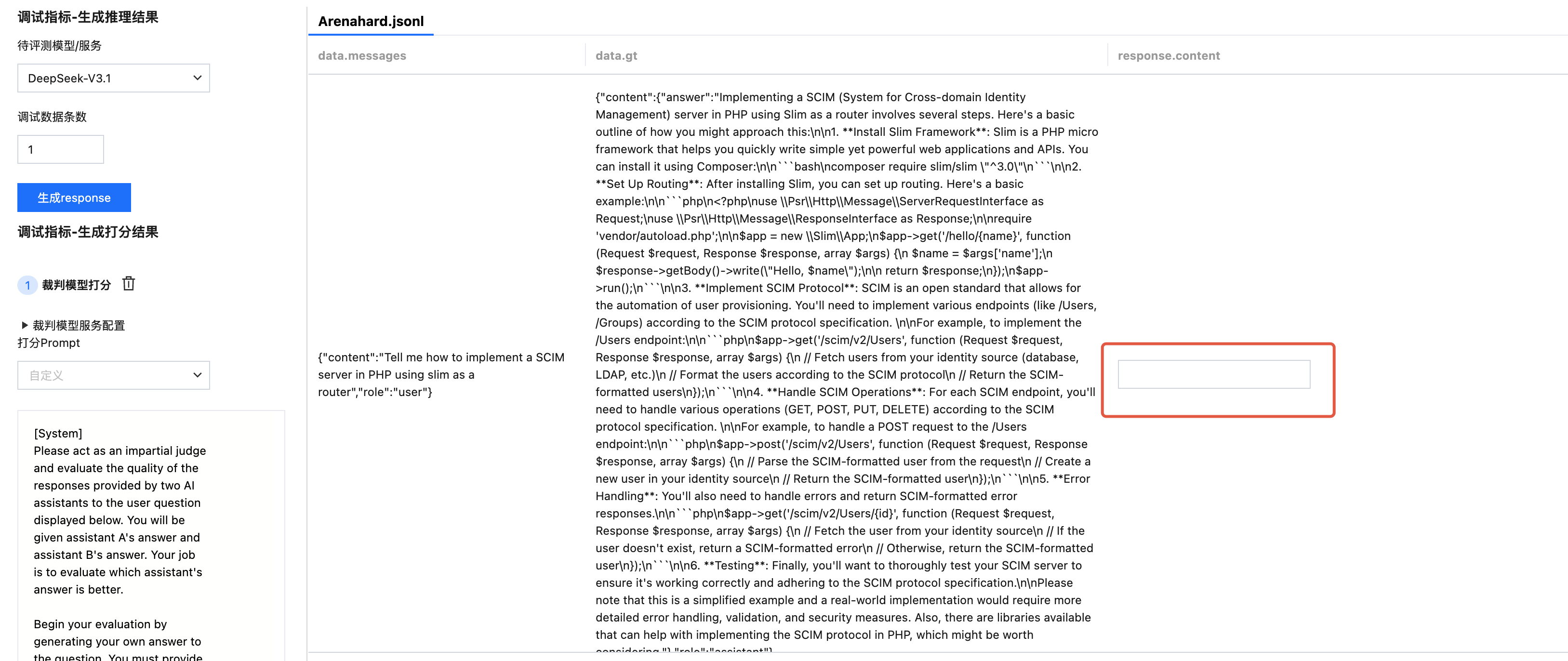
针对自定义评测集配置的指标,支持在正式发起评测前进行调试。支持查看自动生成 response(推理结果)和打分结果来判断打分 Prompt 和处理脚本是否需要调整。调试时,可选择已配置完成的待评测模型服务或者模型。
生成待评测模型的回答
选择待评测服务
单击“生成 response”按钮后,自动生成 response 列。

选择待评测模型
需要手动输入“response”,对手动输入的“response”进行自动打分。
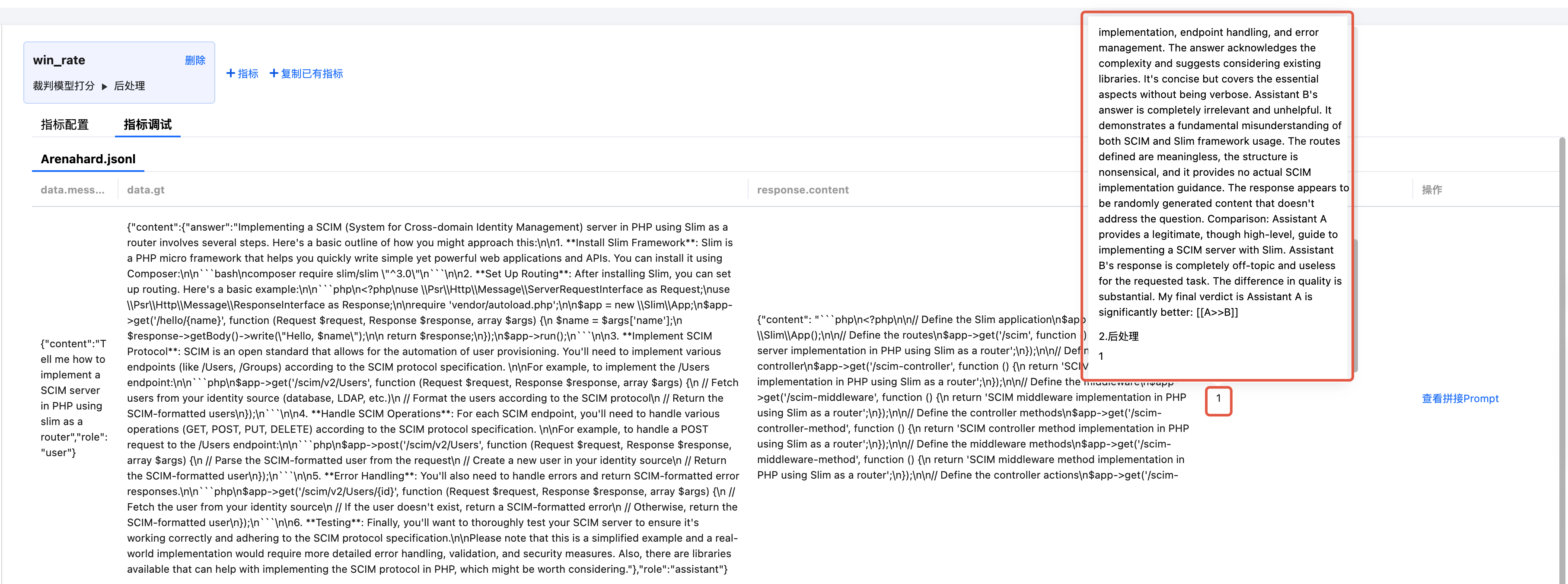
生成“打分结果”
单击“生成打分结果”按钮后,自动生成打分结果列,支持鼠标悬浮查看分步骤打分结果。
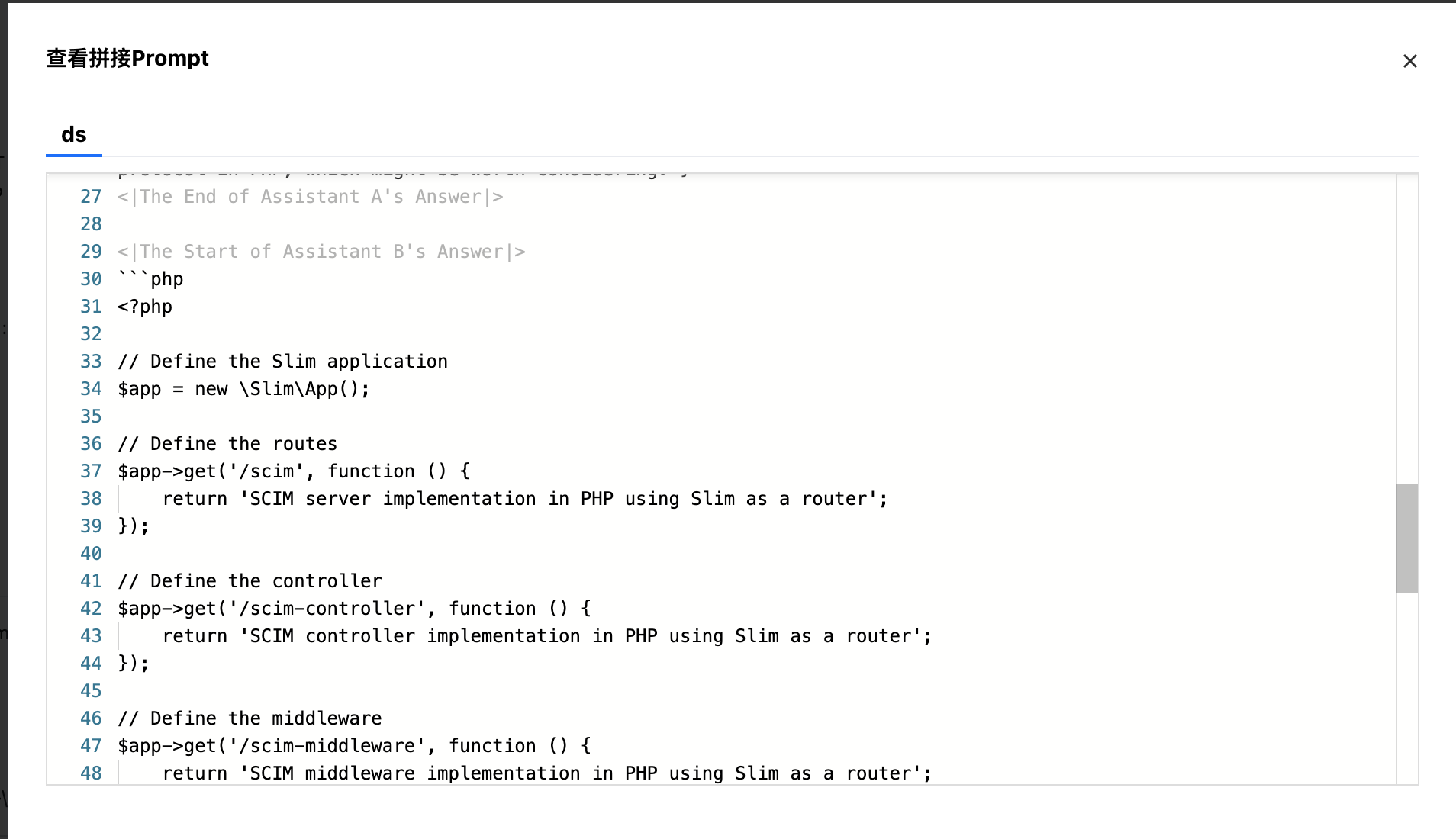
查看拼接 Prompt
单击“查看拼接 Prompt“按钮,支持查看拼接 Prompt 效果。
步骤6:查看评测结果
填写完以上信息后,点击完成开启评测任务。评测任务新建成功后,会在任务列表页展示:任务名称、机器来源、评测资源、进度、标签、创建者、创建时间、操作(停止、重启、删除、复制)。
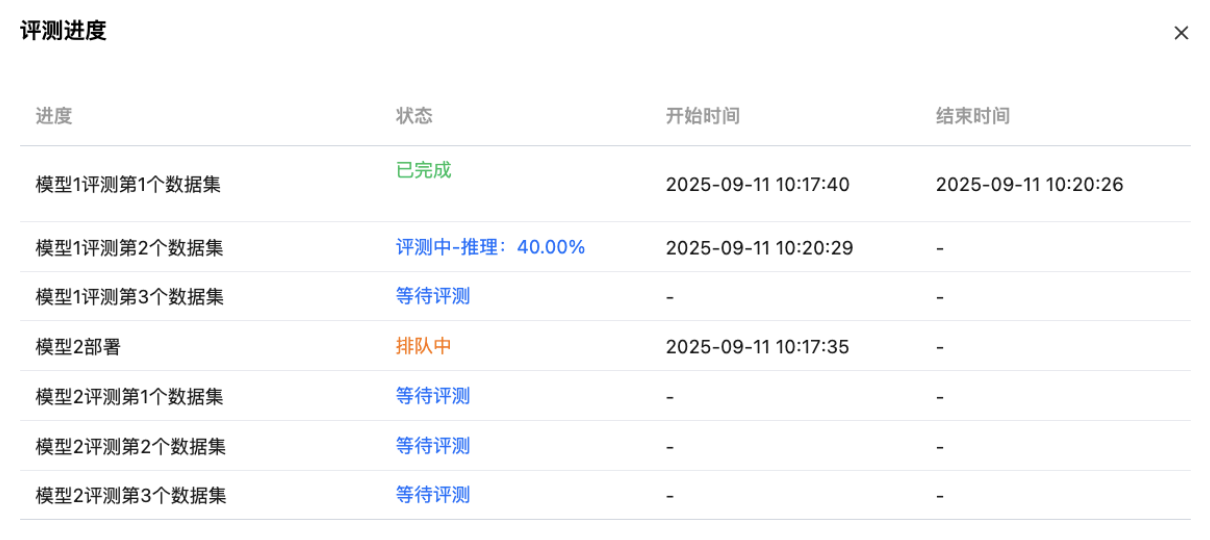
整体评测进度
在评测过程中,可进行进度查看:

说明:
进度的计算公式:评测(推理/打分)数据总条数=模型数*评测数据条数,进度N% = 已评测(推理、打分)数据条数 / 评测(推理、打分)数据总条数 * 100%。
在评测过程中,若有数据评测失败,剩余评测数据也会继续评测,直至全部数据评测结束。
在评测过程中,单击“查看进度”按钮,可进行详细进度查看:
整体评测结果
评测完成后,单击整体评测结果 tab 页面,支持对整体评测的详细进度和最终评测结果进行查看。支持查看模型的综合分数和评分排名,以及对每个模型的详细指标进行查看。用户可单击“调整权重”按钮对评测集的权重和指标的权重。

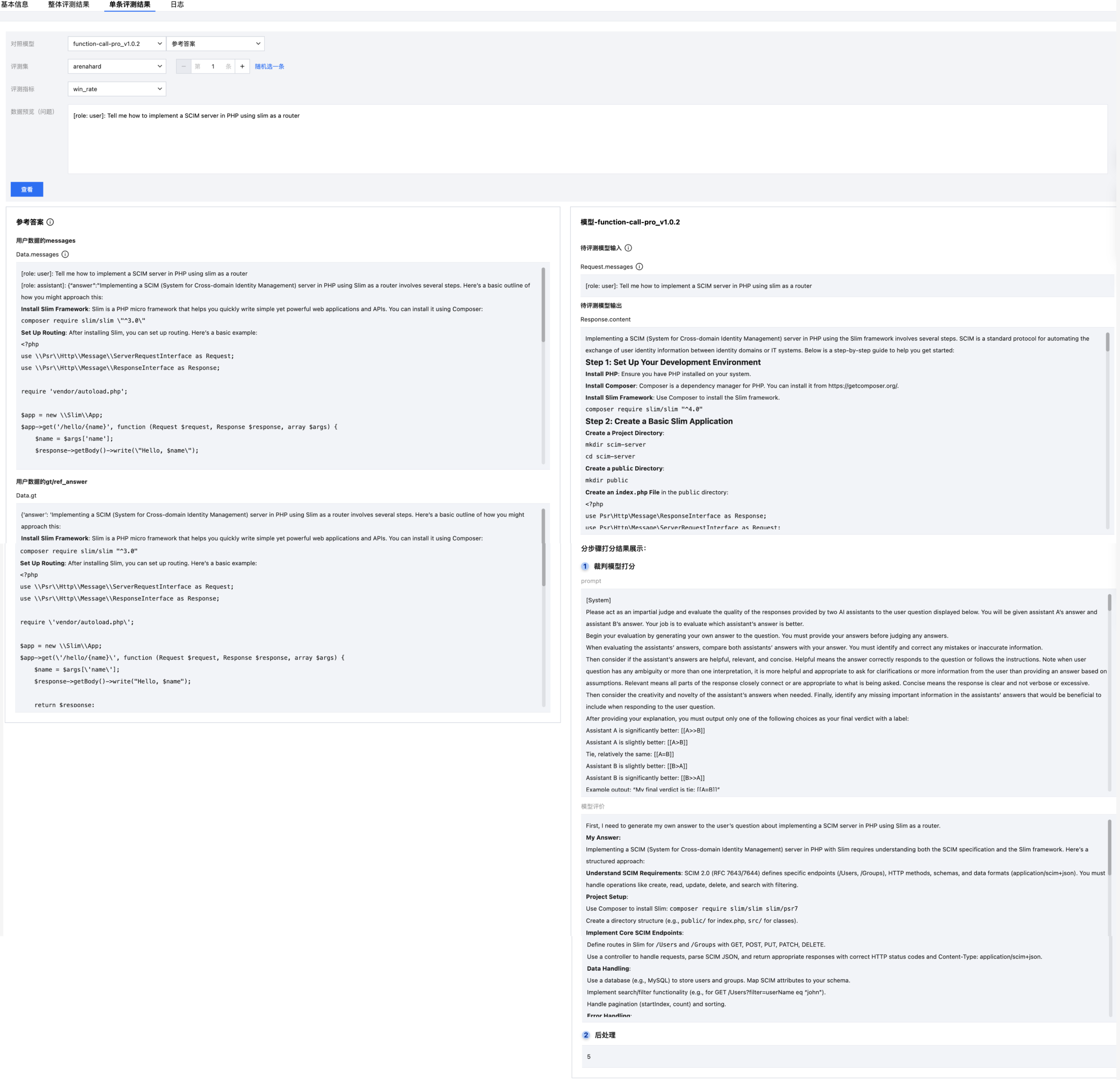
单条结果展示
支持对单条数据进行分步骤查看打分结果,用户可选择对照模型,分别对比待评测模型和参考答案的 response 和打分效果。
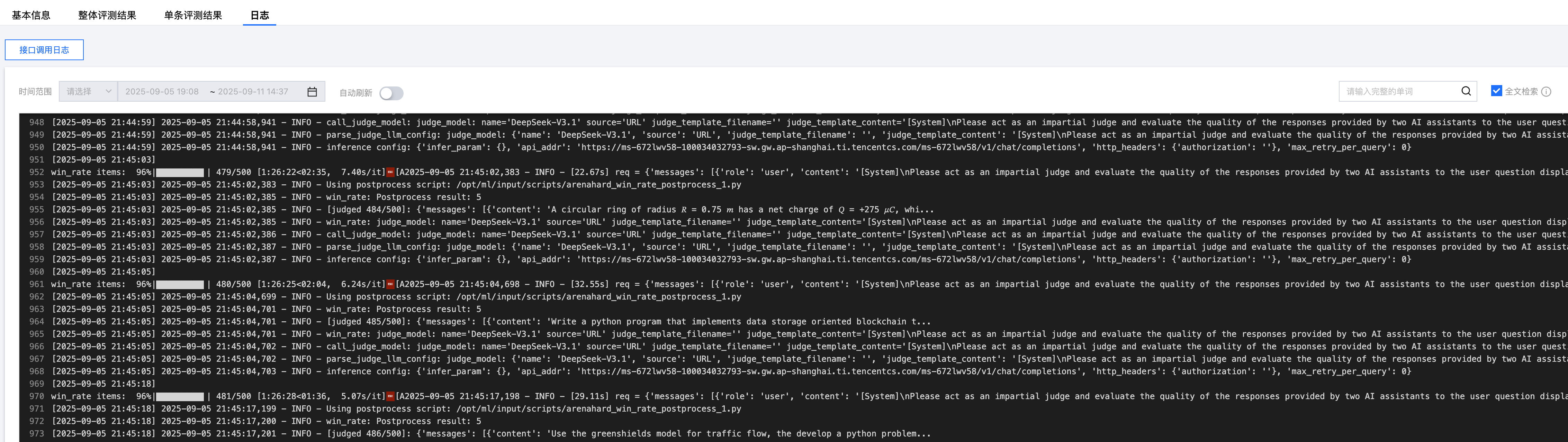
日志查看
支持用户查看评测日志。
在自动评测模块中新建“自定义”评测任务
步骤1:配置基础任务
参数 | 说明 |
任务名称 | 自动评测任务的名称,按照界面提示的规则填写即可。 |
备注 | 可按需为任务备注描述信息。 |
地域 | 同账号下的服务按地域进行隔离,地域字段取值根据您在服务列表页面所选择的地域自动带入。 |
标签 | 用于评测任务间进行权限隔离。同时,只要配置了任务标签,平台会自动添加至评测配置中。 |
计费 | 计费模式:仅当评测模式为“推理及评测”时,可选择按量付费模式或包年包月(资源组)模式: 按量付费模式下,用户无需预先购买资源组,根据服务依赖的算力规格,启动服务时冻结两小时费用,之后每小时根据运行中的实例数量按量扣费。 包年包月(资源组)模式下,可使用在资源组管理模块已购买的资源组部署服务,算力费用在购买资源组时已支付,启动服务时无需扣费。 资源组:若选择包年包月(资源组)模式,可选择资源组管理模块的资源组。 任务资源申请:不同任务配置资源不一致,有多个配置时,建议填写最大的配置资源。 模型资源申请:选择的待评测模型为模型时,需要按照实际情况填写模型部署资源,有多个模型时,建议填写最大的配置资源。 |
步骤2:任务配置
可将评测集、自定义镜像以及存储挂载等内容合并为一个“任务配置”,每一组配置包含评测集、选择镜像、选择版本、挂载路径设置、启动命令、参数设置、环境变量。用户可通过仅选择镜像和版本,或者选择镜像和版本后再设置挂载路径,以实现镜像或者镜像+挂载路径的方式进行评测。
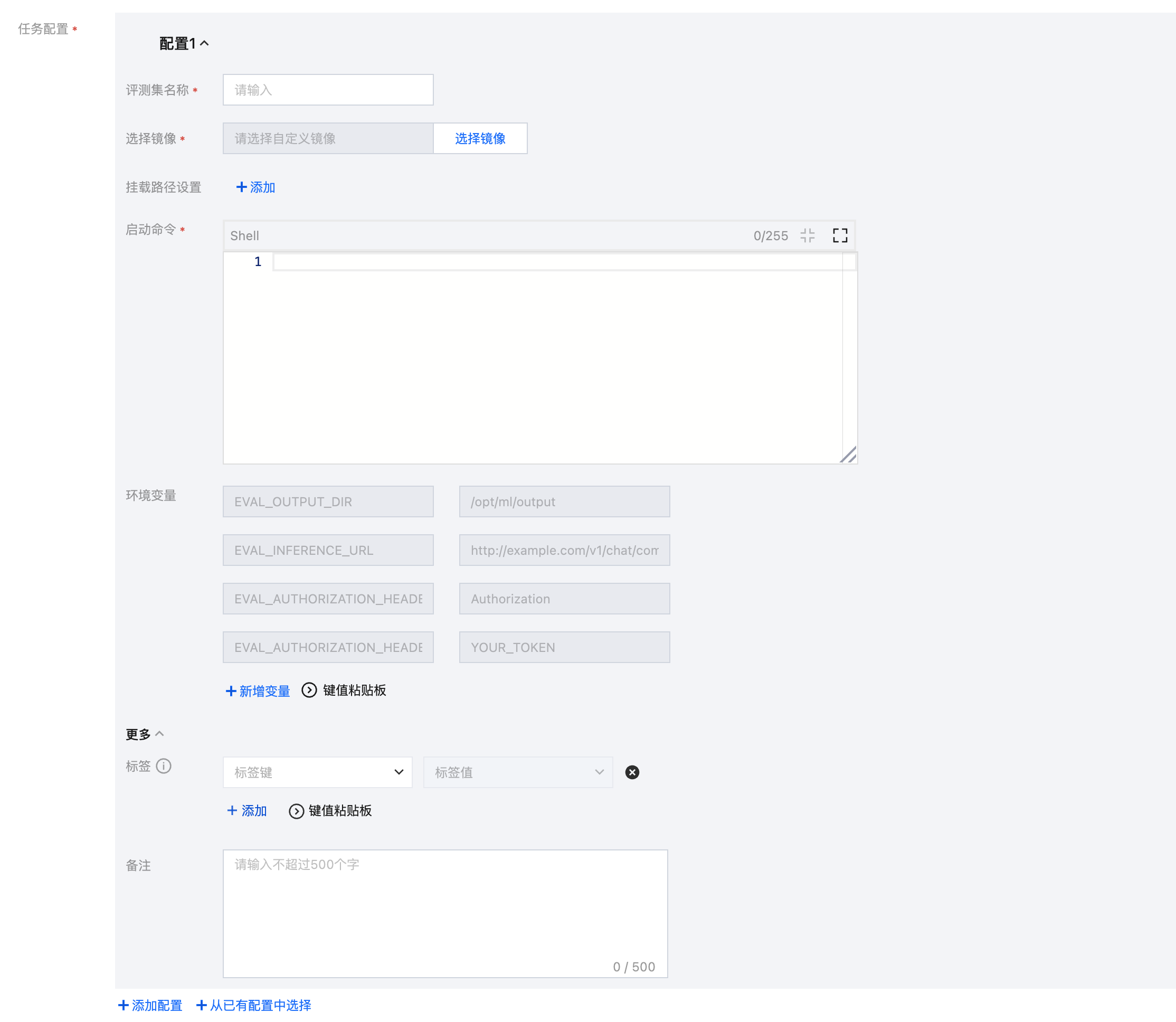
以下为任务配置使用说明:
构建包含评测集与处理逻辑的自定义镜像
可按照相关开源数据集的README,配置并打包基础环境到镜像中。
平台环境变量
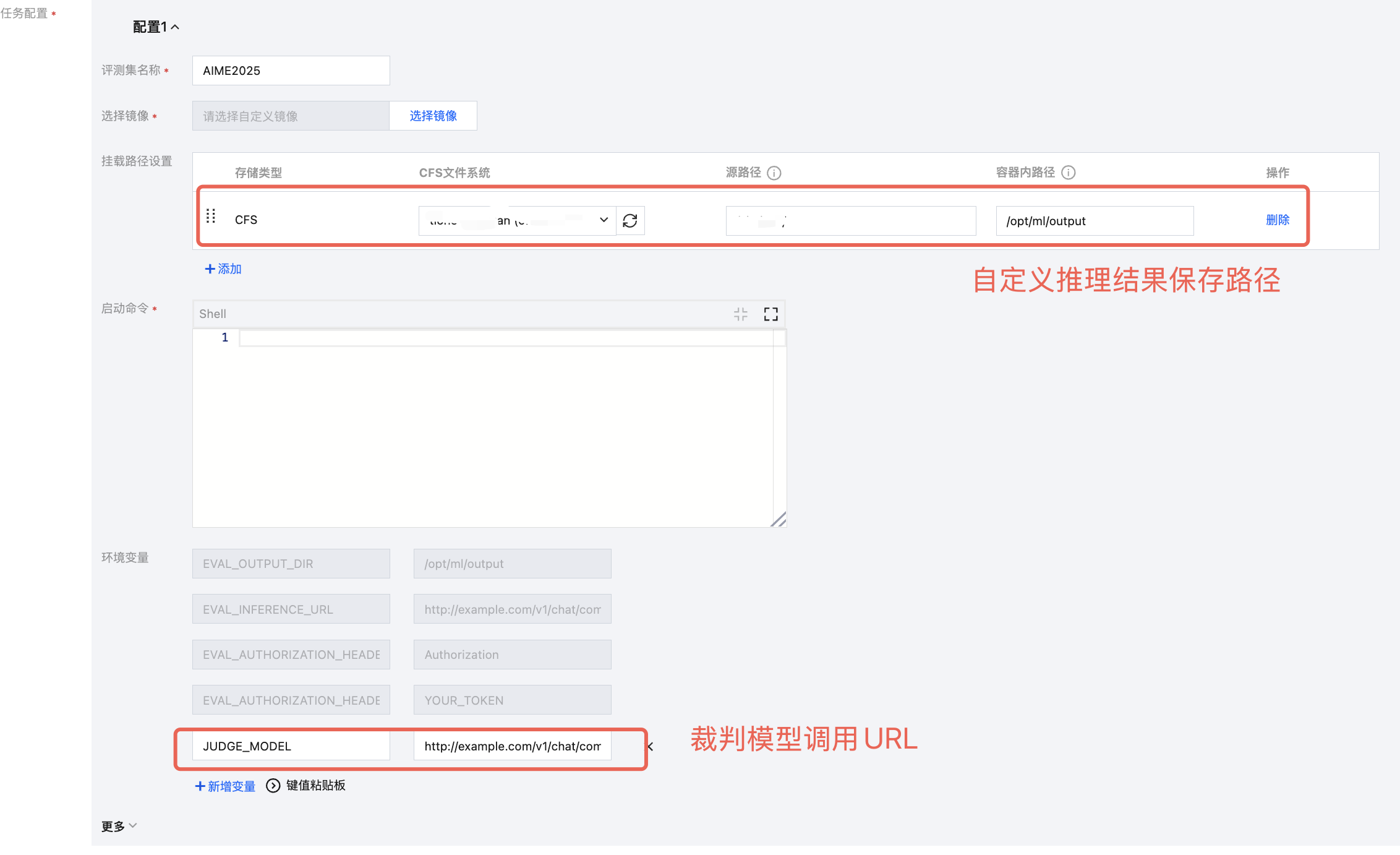
平台会自动注入以下4个环境变量到您的镜像中,如下:
环境变量 | 说明 | 备注 | 示例 |
EVAL_OUTPUT_DIR | 结果输出目录 | 镜像中需要将评测结果保存至此目录,以用于结果展示/可视化对比 | /opt/ml/output |
EVAL_INFERENCE_URL | 模型API地址 | 由于一个任务配置可能会对多个模型服务进行评测,平台通过该环境变量传递模型服务的调用信息 | https://api.openai.com/v1/chat/completions |
EVAL_AUTHORIZATION_HEADER_KEY | 鉴权头名称 | | Authorization |
EVAL_AUTHORIZATION_HEADER_VALUE | 鉴权头值 | | sk-xxx... |
您也可将裁判模型、推理结果等配置通过环境变量或存储挂载的方式注入到执行环境中,以便调用,示例如下:
步骤3:配置待评测模型/服务
根据2.2中相关环境变量进行调用,平台会在执行过程中传入选择的在线服务/第三方URL相关信息;用户需要选择待评测模型或者服务,以生成推理结果后进行评测。待评测模型来源为 内置大模型/训练任务/CFS/GooseFSx/数据源/资源组 ,模型服务来源为 在线服务/填写服务地址。配置待评测模型/服务时,提供参数设置的功能。
选择模型:
若选择内置大模型快速开启评测。
若从训练任务中选择模型,选择该地域下的训练任务或者该任务的 CheckPoint。
若选择数据源,则需要首先在平台管理 > 数据源管理创建数据源(注意:数据源挂载权限分为只读挂载和读写挂载,需要输出结果数据的数据源请配置为读写挂载)。
若选择 CFS、GooseFSx,则需要下拉选择 CFS 文件系统、GooseFSx 实例,同时填写需要平台挂载的目录。
选择服务:
若选择 从在线服务选择,需要选择在线服务名称,为保证评测的顺利开启请确保服务为正常运行状态。同时,需要选择对应的鉴权信息。
若选择 填写服务地址,需要输入完整的服务调用地址以及对应的鉴权信息。对于此种方式,支持通过连通性测试检查服务是否能够正常运行。
设置参数,支持配置推理超参、启动参数设置和性能参数设置。
配置推理超参,推理超参支持如下:
repetition_penalty:用来控制重复惩罚。
max_tokens:用来控制输出文本的最长数量。
temperature:数值越高,输出越随机;数值越低,输出越集中和确定。
top_p、top_k:影响输出文本的多样性,数值越高,生成文本的多样性越强。建议该参数和 temperature 只设置1个
do_sample:确定模型推理时的采样方式,取值 true 时为 sample 方式;取值为 false 时为 greedy search 方式,此时,top_p、top_k、temperature、repetition_penalty 不生效。
配置启动参数,可参考服务部署参数填写指引。平台配置默认参数 MAX_MODEL_LEN,指模型单次推理能处理的最大 token 数(平台默认8192),启动时设置过高可能引发显存溢出或性能下降,可根据任务需求合理调整该值。
配置性能参数,平台配置默认参数 MAX_CONCURRENCY 和 MAX_RETRY_PER_QUERY。
MAX_CONCURRENCY 指评测过程中同时向模型发起的请求数上限;设置过低可能导致模型吞吐量下降导致评测耗时较长,设置过高可能导致显存溢出或请求超时(平台默认24)。用户可根据任务需求合理调整该值。
MAX_RETRY_PER_QUERY 指每条数据在请求推理服务出现异常时(如请求超时或网络故障)的最大重试次数。该值为0则不进行重试(平台默认0)。用户可根据任务需求合理调整该值。
支持复用以往的评测结果
注意:
需要保证自定义评测中配置了指标输出到平台路径,否则无法获取任务指标。
选择待评测模型时,支持选择以往相同模型名称、相同评测集名称的评测任务的评测结果。
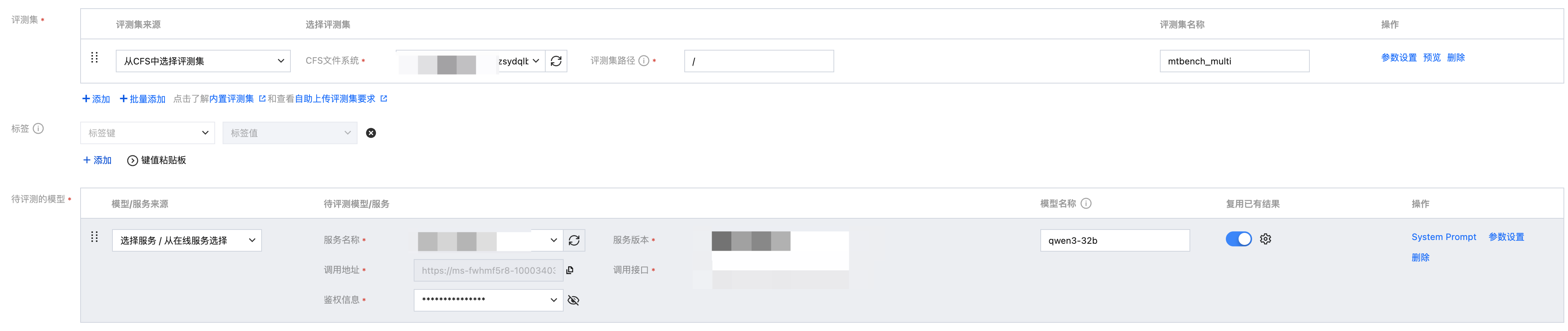
打开复用开关,选择需要复用的评测任务。
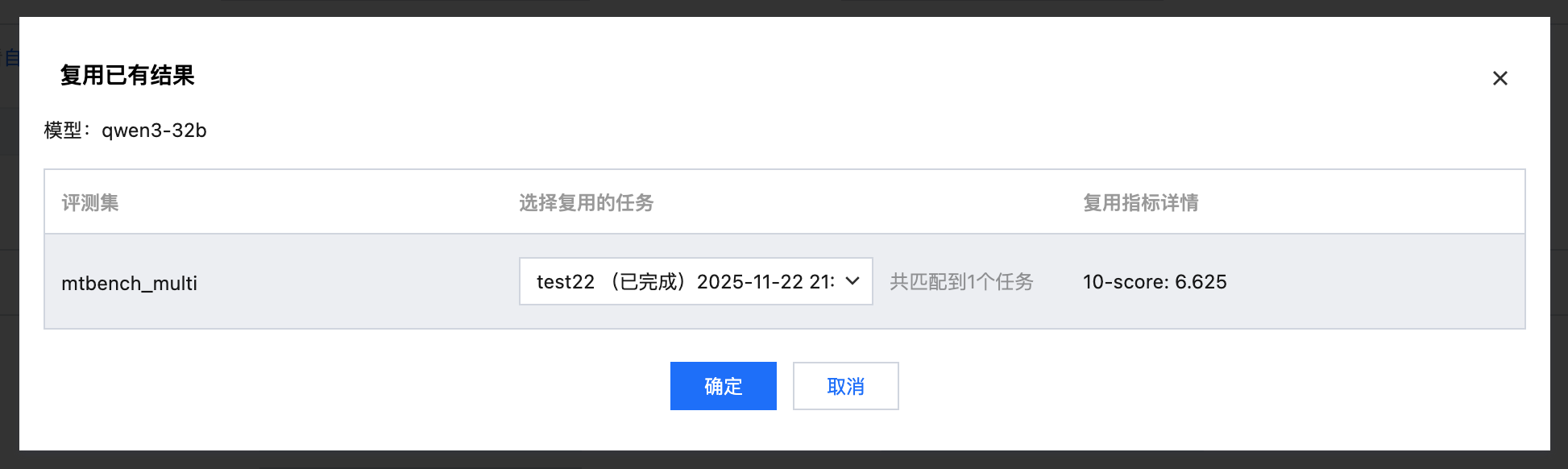
可直接复用结果,不需要再次进行推理和打分。
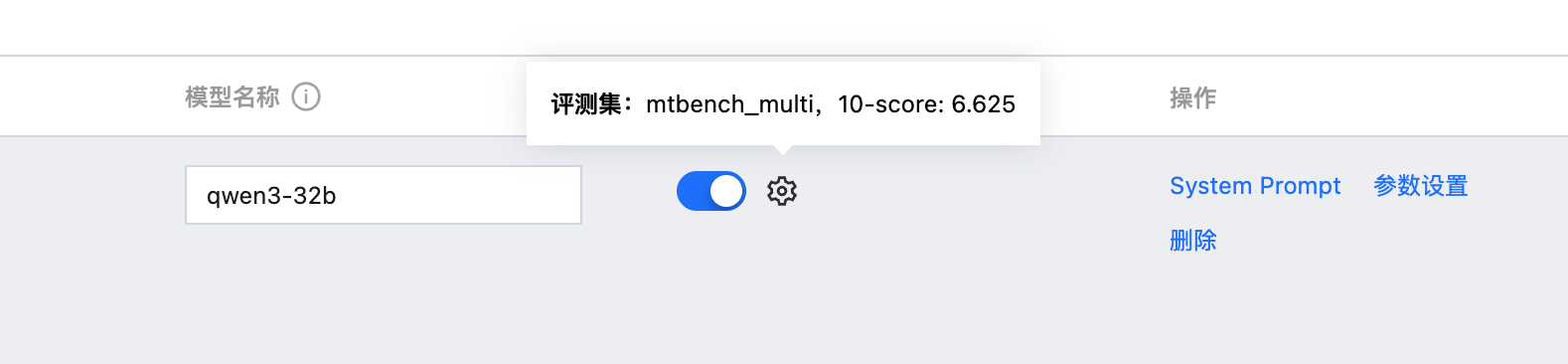
步骤4:查看评测结果
注意:
查看评测的前提需要执行下述步骤,完成后可在整体评测结果中查看指标。若您没有执行此步骤,评测结果只能在日志中根据自定义镜像 log 查看,此外,可视化对比中选不到该评测集在相关模型上的评测结果。
为了在自定义评测结果的详情页查看 数据集-模型 的评测结果,您需要将具体的评测结果存入平台路径
${EVAL_OUTPUT_DIR} 中,文件名为 metrics.json, 该文件内容格式如下:{"metrics": [{"name": "accuracy","value": 0.85},{"name": "f1_score","value": 0.78}]}
您可通过以下代码在自定义镜像中写入:
import jsonimport os# 获取输出目录output_dir = os.getenv('EVAL_OUTPUT_DIR')# 构造结果数据result = {"metrics": [{"name": "accuracy", "value": 0.85},{"name": "f1_score", "value": 0.78}]}# 写入结果文件result_file = os.path.join(output_dir, 'metrics.json')with open(result_file, 'w', encoding='utf-8') as f:json.dump(result, f, indent=2, ensure_ascii=False)
单击整体评测结果 tab 页面,支持对整体评测的详细进度和最终评测结果进行查看。暂时不支持单条评测结果查看。
整体评测进度
说明:
由于自定义评测模式平台无法获取评测集数量,目前进度计算公式为:进度=已完成的评测任务(模型*已评测的评测集)/总评测任务(模型*总评测集)。由于评测进度粒度比较大会导致在某一进度上停留时间较长,不代表评测暂停或者失败,可通过日志查看进展。
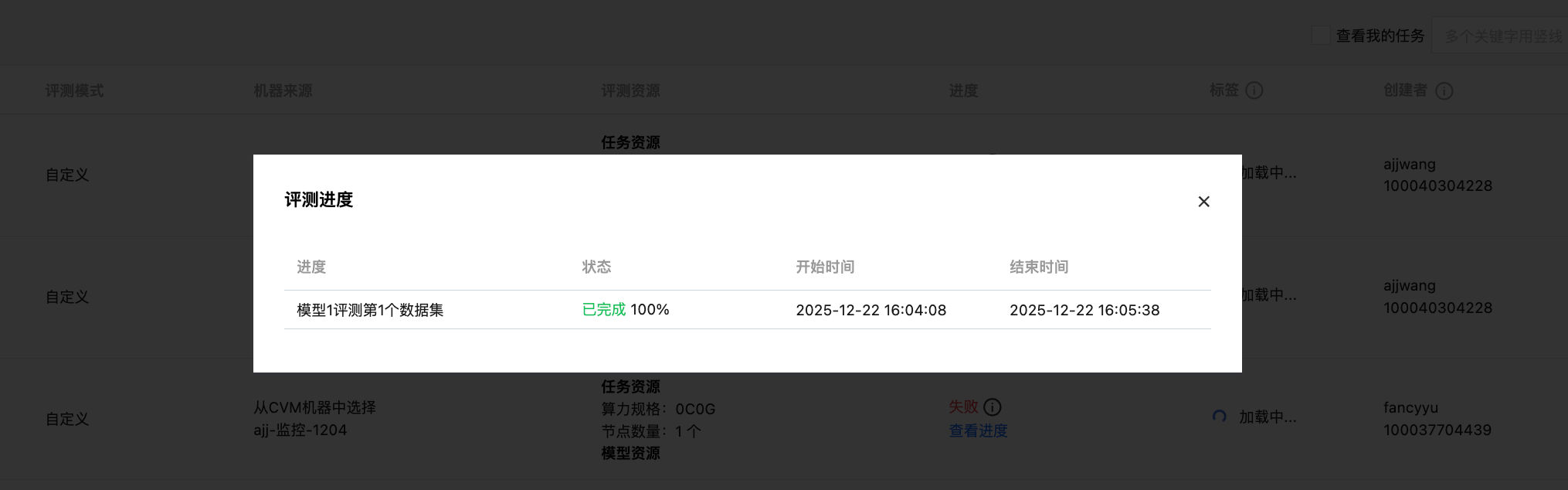
整体评测结果
支持查看模型的综合分数和评分排名,以及对每个模型的详细指标进行查看。用户可单击“调整权重”按钮对评测集的权重和指标的权重。

日志查看
支持用户查看评测日志。
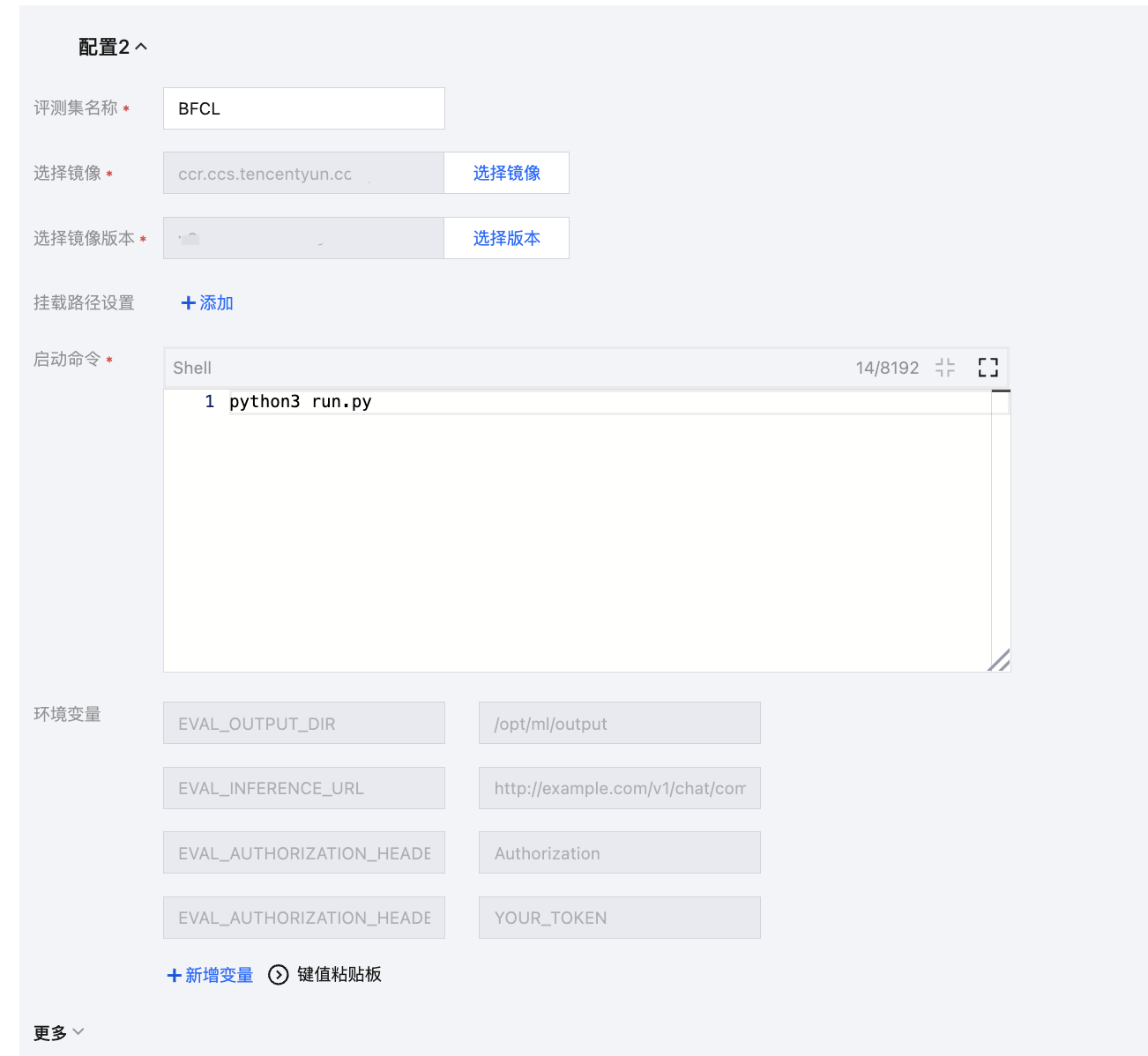
步骤5:自定义评测配置示例(BFCL 评测集)
每个评测集的任务配置会在每个模型服务上串行执行
背景说明:自定义评测镜像,通过挂载 BFCL 评测集进行评测。
任务配置:需要自定义评测集 BFCL 的评测镜像以及存储挂载、环境变量、启动命令。
文档反馈