自定义任务调度池
Download
フォーカスモード
フォントサイズ
使用场景
适用引擎:Spark SQL 引擎。
当您向引擎提交多个任务时,例如同时提交多个 SQL 任务到 Spark SQL 集群,由于业务提交的任务可能存在前后依赖,所以引擎在调度执行这些任务时,会默认按照 FIFO 的方式来调度这些任务。
但是某些特殊情况,可能您需要自己定义某些任务的优先级,例如以下场景:
提交的任务优先级很高,需要最高优先级执行这个任务,不希望它排队等待集群资源。
提交的任务优先级很低,希望这个任务尽量不抢占其他任务的资源,有资源时就执行,没资源时就排队等待。
自定义调度规则
在 Spark SQL 引擎中,每个执行的 SQL 任务 Job 都会被切分成多个 Task 的集合 TaskSet,我们的调度是基于 TaskSet 来调度的。每当集群有空闲资源时,就从所有 Job 的 TaskSet 中按调度算法取一个 Task 下发执行。
我们的调度算法就是定义多个调度池,将 Job/TaskSet 放在对应的调度池中,按调度池来获取需要下发执行的 Task。
调度池及其属性
您可以定义多个调度池,每个调度池有四个属性:
name:调度池的名称,您可以自己命名。可以命名为 default,表示默认的调度池。
schedulingMode:调度规则,支持 FIFO 和 FAIR 两种模式。一个调度池内有多个 TaskSet 时的调度算法。
FIFO:按照 TaskSet 提交的先后顺序依次下发。
FAIR:多个 TaskSet 的任务都公平地被下发。具体下发规则与调度池的 minShare 和 weight 属性有关。
minShare:最小满足的核数,必须大于0,也就是最小可以运行的 Task 数。在调度时会优先满足该调度池内运行的 Task 数目达到 minShare。
weight:权重。权重高的调度池,Task 会优先被调度。在满足 minShare 后才会对比权重。
调度的配置需要您撰写一个 xml 文件,格式如下:
<?xml version="1.0"?><allocations><pool name="production"><schedulingMode>FAIR</schedulingMode><weight>1</weight><minShare>2</minShare></pool><pool name="test"><schedulingMode>FIFO</schedulingMode><weight>2</weight><minShare>3</minShare></pool></allocations>
调度配置参考示例
您可以参考设置三个调度池:
默认调度池 default:schedulingMode = FIFO,weight = 1,minShare =(集群核数 - driver 核数)。该调度池是任务默认提交的调度池,优先级普通,按照先后顺序执行,可以使用集群全部的计算资源。
慢任务调度池 straggler:schedulingMode = FAIR,weight = 1,minShare = 1。该调度池专用于慢任务提交,优先级普通。由于minShare = 1,并不会抢占其他提交到 default 调度池的任务的资源。当集群有更多空闲资源时才会执行 straggler 调度池中的 Task。
高优调度池 special:schedulingMode = FIFO,weight = 1000,minShare =(集群核数 - driver 核数)。该调度池用于特殊情况需要优先执行的任务。但是,由于 minShare 的存在,该调度池并不会抢占集群全部资源,default 调度池中的任务仍然也会继续执行,一般情况下 default 池和 special 池各发下同等数量的 Task。
以16CU的集群(driver 为4CU)为例,这种参考示例的配置如下:
<?xml version="1.0"?><allocations><pool name="default"><schedulingMode>FIFO</schedulingMode><weight>1</weight><minShare>12</minShare></pool><pool name="straggler"><schedulingMode>FAIR</schedulingMode><weight>1</weight><minShare>1</minShare></pool><pool name="special"><schedulingMode>FIFO</schedulingMode><weight>1000</weight><minShare>12</minShare></pool></allocations>
操作方式
1. 在准备好调度池的 xml 文件后,放置在 cos 的某个路径,例如 cosn://bucket-appid/fairscheduler.xml。
2. 在引擎配置中新增以下配置。
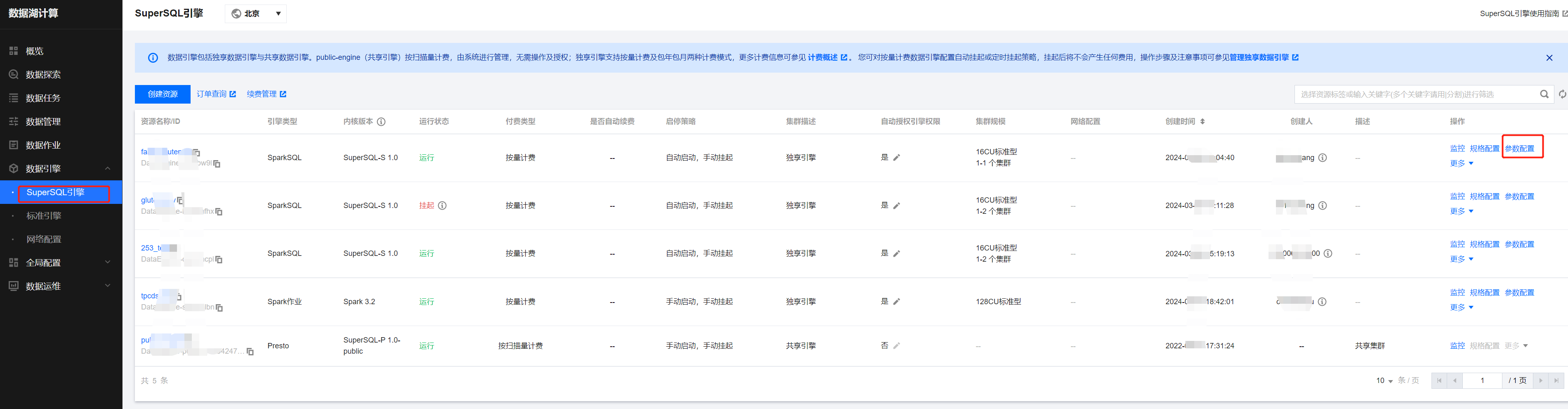
参数配置 spark.scheduler.allocation.file,取值为您的调度池 xml 文件路径 cosn://bucket-appid/fairscheduler.xml。
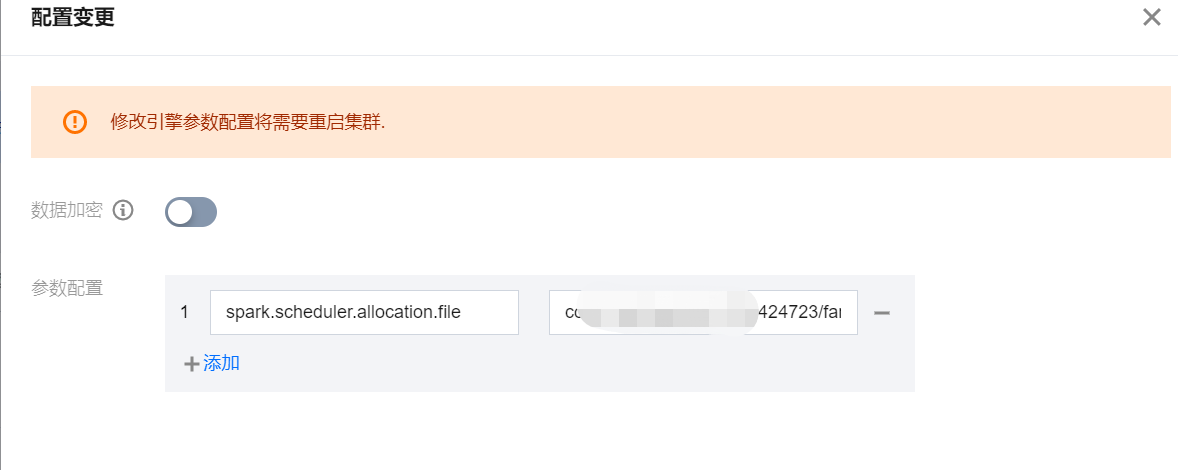
该操作需要重启集群。
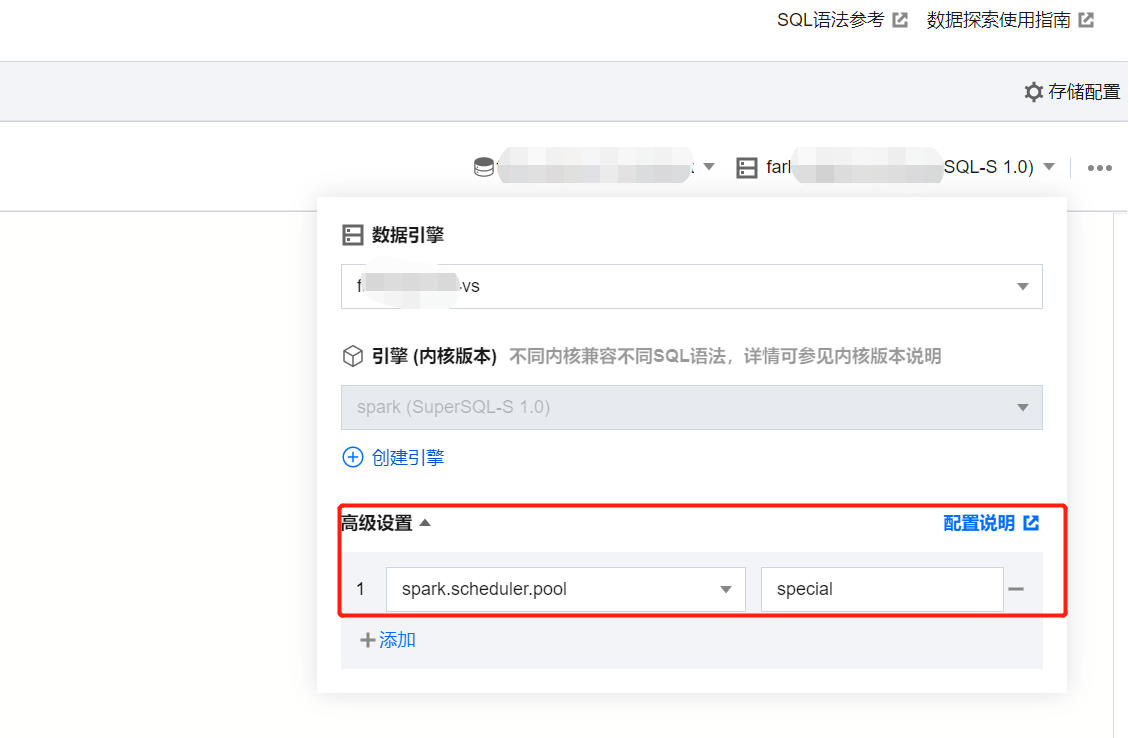
3. 在任务提交时,指定以下参数作为任务参数。spark.scheduler.pool = 要提交到的调度池 name。如果是 default 调度池,可以不指定。
注意事项
调度发生的时间节点在:集群有空闲资源,而有任务需要调度时。因此,如果集群已经被某个任务,例如某个慢任务,全部占满后,必须等待该任务有一个 Task 执行完成,才会开始调度其他优先级更高的任务。所以需要注意,慢任务的单个 Task 耗时最好要相对合理,否则仍然可能会导致长时间占据集群资源。
フィードバック