实时节点高级参数
下载
聚焦模式
字号
参数说明
类型 | 参数级别 | 读/写 | 适用场景 | 配置内容 | 描述 |
Mysql / tdsql-c Mysql | 节点级别 | 读 | 单表+整库 | scan.newly-added-table.enabled=true | 参数描述 : 设置这个参数,在暂停 > 继续后可以感知新增的表。默认是 false 1. 全增量同步时使用该参数,新增的表会读取存量数据后再读取增量数据 2. 增量同步时使用该参数,新增的表只会读取增量数据 |
| | 读 | 单表+整库 | scan.incremental.snapshot.chunk.size=20000 | 参数描述 : 对于数据分布均匀的任务,这个参数代表一个 chunk 内大约的条数,可以用总的数据量除以 chunk size 估算任务有多少个 chunk 数,chunk 数的多少影响了 jobmanager 是否 oom,目前 2CU 的情况下可以支持10w多 chunk,如果数据量太大,我们可以调大 chunk size 来减少 chunk 数量 注意事项 : 大数据量任务(例如,总数据量1个亿以上,单条记录大于0.1M)一般建议设置20000 |
| | 读 | 单表+整库 | split-key.even-distribution.factor.upper-bound=10.0d | 参数描述 : mysql 存量数据读取阶段,如果数据比较离散、主键字段的最大值超大,可以修改这个参数,来使用非均匀分割,减少由于主键值超大情况下导致 chunk 数量太大从而 jm oom 的问题 注意事项 : 默认值为10.0d一般不用修改 |
| | 读 | 单表+整库 | debezium.query.fetch.size=0 | 参数描述 : 代表每次读取从数据库拉取的数据条数,默认是0代表jdbc 默认的 fetch size 注意事项 : 1. 大任务(例如,总数据量1个亿以上,单条记录大于0.1M)只有一个读取实例时建议取1024条 2. 任务存在多个读取实例时建议降低这个值,减少内存消耗,建议取512条 |
| | 读 | 单表+整库 | debezium.max.queue.size=8192 | 参数描述 : 属性定义了内部队列中存储的最大事件数。如果达到此限制,Debezium 将暂停读取新事件,直到处理和提交尚未处理的事件。这个属性可以帮助避免过多事件积压在队列中,导致内存耗尽和性能下降。默认是8192 注意事项 : 1. 大任务(例如,总数据量1个亿以上,单条记录大于0.1M)只有一个读取实例建议取4096 2. 任务存在多个读取实例时建议降低这个值,减少内存消耗,建议取1024 |
| 作业级别 | - | - | taskmanager.memory.managed.fraction=0.1 | 参数描述 : 调整 flink 程序 taskmanager 托管内存比例 |
| | - | - | table.exec.sink.upsert-materialize=NONE | 参数描述 : 由于分布式系统中的 shuffle 会造成 Changelog 数据的乱序,所以 sink 接收到的数据可能在全局的 upsert 中乱序,所以要在 upsert sink 之前添加一个 upsert 物化算子。该算子接收上游 changelog 数据,并且给下游生成一个 upsert 视图。这个参数用于控制物化算子的添加 注意事项 : 1. 默认情况下,在唯一 key 遇到分布式乱序时,该物化算子会被添加,也可以选择不物化(NONE),或者是强制物化(FORCE) 2. 可选值有:NONE、AUTO、FORCE |
| | - | - | table.exec.sink.not-null-enforcer=DROP | 参数描述 : 决定当 NOT NULL 字段遇到 null 值时任务如何处理 建议值及作用: 1. ERROR:NOT NULL 字段遇到 null 值时抛出运行时异常。 2. DROP:NOT NULL 字段遇到 null 值时直接丢弃数据 |
dlc | 节点级别 | 写 | 单表+整库 | write.distribution-mode=hash | 参数描述 : dlc 并发写入,支持参数 none|hash(默认)|range: 1. none:存在主键则根据主键进行并发写入,否则单并发写入 2. hash:存在分区字段,根据分区字段并发写入,否则根据参数 none 的策略写入 3. range:暂不支持,策略和 none 一致 |
doris | 节点级别 | 写 | 仅单表 | sink.properties.*=xxx | 参数描述 : Stream Load 的导入参数。 例如 'sink.properties.column_separator' = ', ' |
| 节点级别 | 写 | 仅单表 | sink.properties.columns=xxx | 参数描述 : 配置 columns 的函数映射关系。 例如 'sink.properties.columns' = 'dt,page,user_id,user_id=to_bitmap(user_id)' |
| 节点级别 | 写 | 单表+整库 | sink.batch.size = 100000 sink.batch.bytes= 83886080 sink.batch.interval= 10s | 参数描述 : 提高写入 doris 效率 注意事项 : tm cu 建议设置为2CU,避免 tm oom |
oracle | 节点级别 | 读 | 单表+整库 | 'debezium.log.mining.strategy' = 'online_catalog' 'debezium.log.mining.continuous.mine' = 'true' | 参数描述 : 开启这个参数后,可以减少数据同步的延迟和减少 redo 日志的存储,适用于单表同步 + 整库同步(指定表) 注意事项 : 1. 设置后无法感知新增表,如果配置同步 所有库表 / 指定库 将无法读取新增表数据 2. 不适用于 oracle19 版本不支持这个参数,因此需要设为 false,否则将导致任务失败。 |
| 节点级别 | 读 | 单表+整库 | debezium.lob.enabled=false | 参数描述 : 是否同步 blob 类型数据,默认是 false 注意事项 : 1. 如果设置会 true,可能会影响同步性能 2. oracle 默认推荐配置为 false |
mongodb | 节点级别 | 读 | 仅单表 | scan.incremental.snapshot.enabled=true | 参数描述 : 开启并发读,默认为 false 注意事项 : mongodb4.0 版本以上才支持 |
| 节点级别 | 读 | 仅单表 | copy.existing=false | 参数描述 : 是否从源集合复制现有数据: 1. 默认是 true,表示从全量开始读取数据 2. false 表示从增量开始读取数据 |
| 节点级别 | 读 | 仅单表 | poll.await.time.ms | 参数描述 : 变更事件拉取时间间隔,默认为1500ms 注意事项 : 1. 对于变更频繁的集合,可以适当调小拉取间隔,提升处理时效 2. 对于变更缓慢的集合,可以适当调大拉取时间间隔,减轻数据库压力 |
| 节点级别 | 读 | 仅单表 | poll.max.batch.size | 参数描述 : 每一批次拉取变更事件的最大条数,默认为1000条 注意事项 : 调大改参数会加快从 Cursor 中拉取变更事件的速度,但会提升内存的开销 |
| 节点级别 | 读 | 仅单表 | scan.incremental.snapshot.chunk.size.mb | 参数描述 : 增量快照的块大小,单位是 mb ,默认大小为 64mb |
| 节点级别 | 读 | 仅单表 | changelog.normalize.enabled | 参数描述 : 是否开启 changelogNormalize 算子,默认为 true,表示开启 注意事项 : mongodb 缺乏 -u 消息,开启该算子会补齐 -u 消息,但是会消耗一定性能。关闭该算子会提高传输速度,但是 delete 操作无法同步到下游,其他操作不影响 |
节点级配置方式
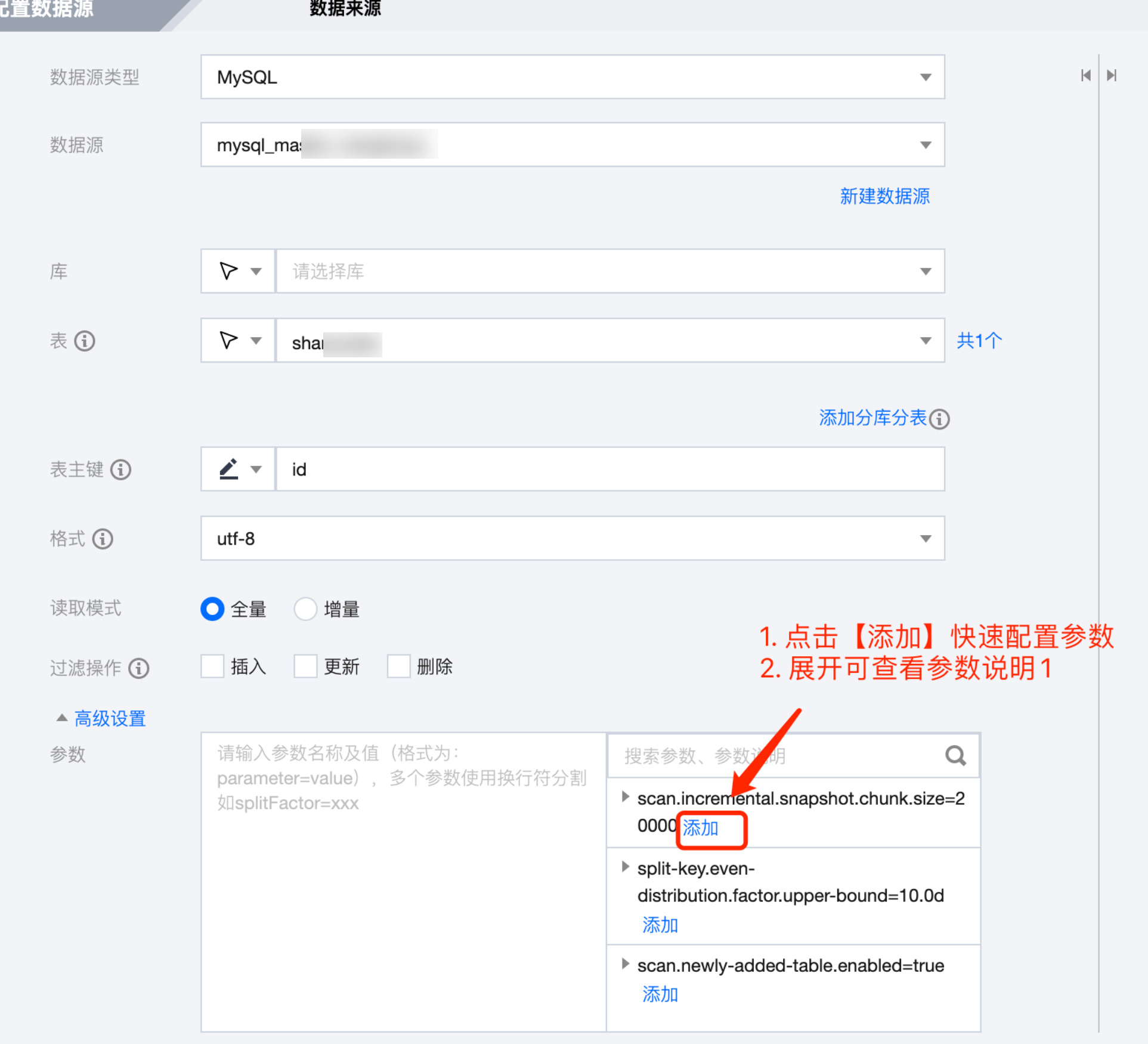
任务级配置方式
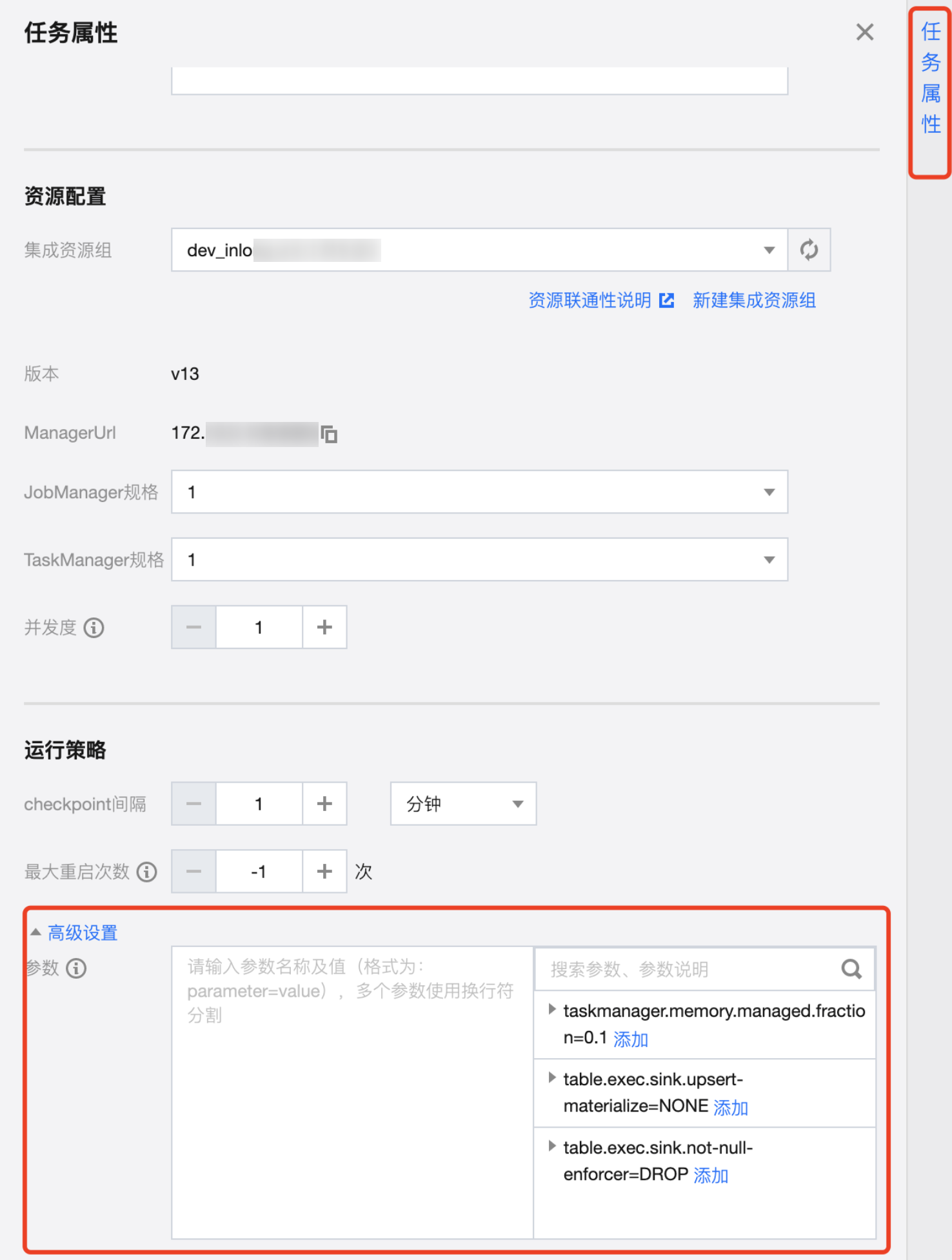
说明:
1. 一个参数一行;若需配合使用的参数写在一行内。
2. 每个参数带默认值。
文档反馈