Iceberg 数据源
下载
聚焦模式
字号
支持版本
支持 Iceberg 1.1.x 版本。
使用限制
1. 需要连接 Hive Metastore 服务,请在数据源正确配置 Metastore Thrift 协议的 IP 和端口。如果是自定义 Iceberg 数据源,还需要上传 hive-site.xml、core-site.xml 和 hdfs-site.xml 。
2. 目前只支持 Hive catalog,不支持 Hadoop catalog。
3. 数据源读取的 where 条件目前只支持 iceberg java api,不支持 spark SQL 语法。详情请参见 Iceberg JavaAPI Expressions。
Iceberg 离线单表读取节点配置
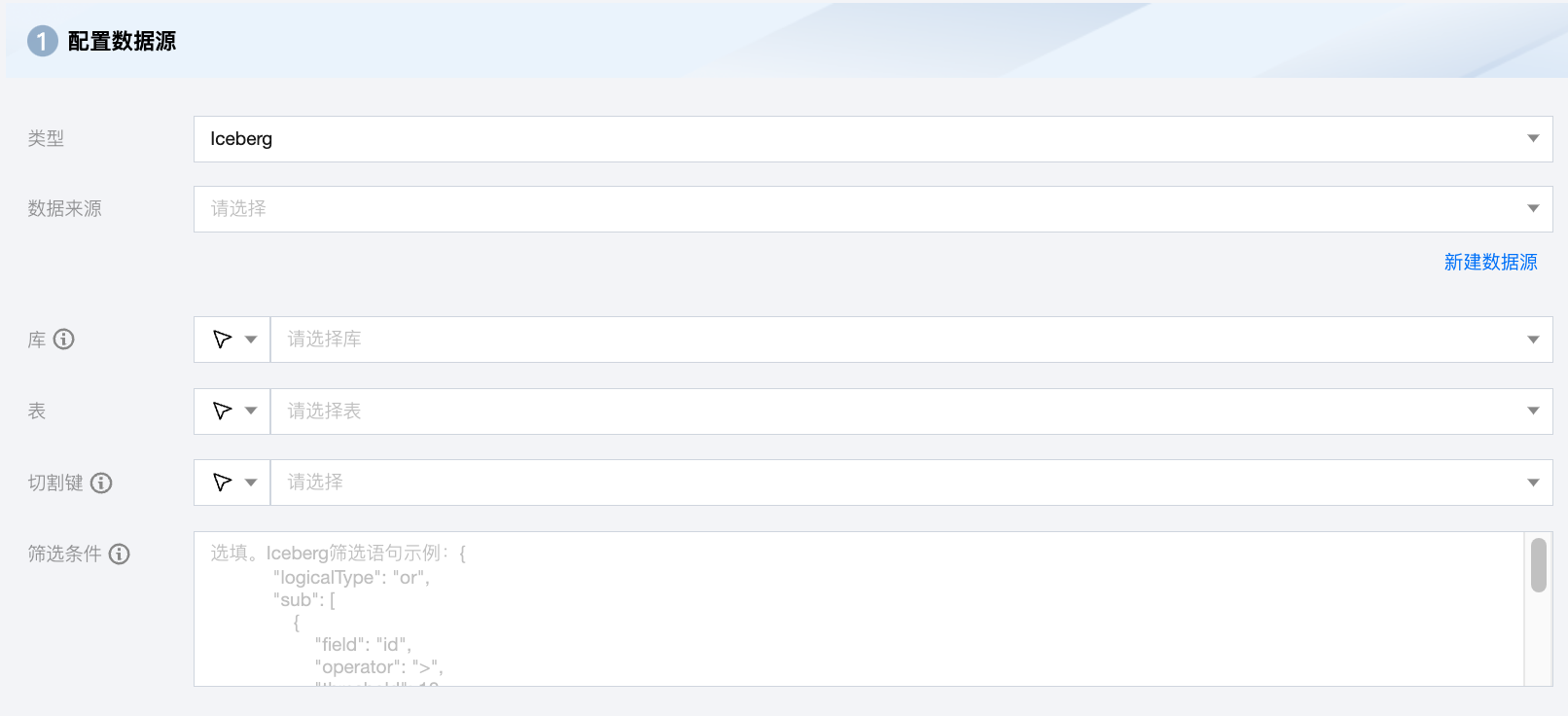
参数 | 说明 |
数据来源 | 可用的 Iceberg 数据源。 |
库 | 支持选择、或者手动输入需读取的库名称。 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需读取的表名称。 |
切割键 | 指定用于数据分片的字段,指定后将启动并发任务进行数据同步。您可以将源数据表中某一列作为切分键,建议使用主键或有索引的列作为切分键。 注意: 若希望启动并发任务进行数据同步,则必须指定切割键,否则无法启动。 |
筛选条件(选填) | 在实际业务场景中,通常会选择当天的数据进行同步,将 where 条件指定为 gmt_create>$bizdate 。where 条件可以有效地进行业务增量同步。如果不填写 where 语句,包括不提供 where 的 key 或 value,数据同步均视作同步全量数据。 |
Iceberg 离线单表写入节点配置
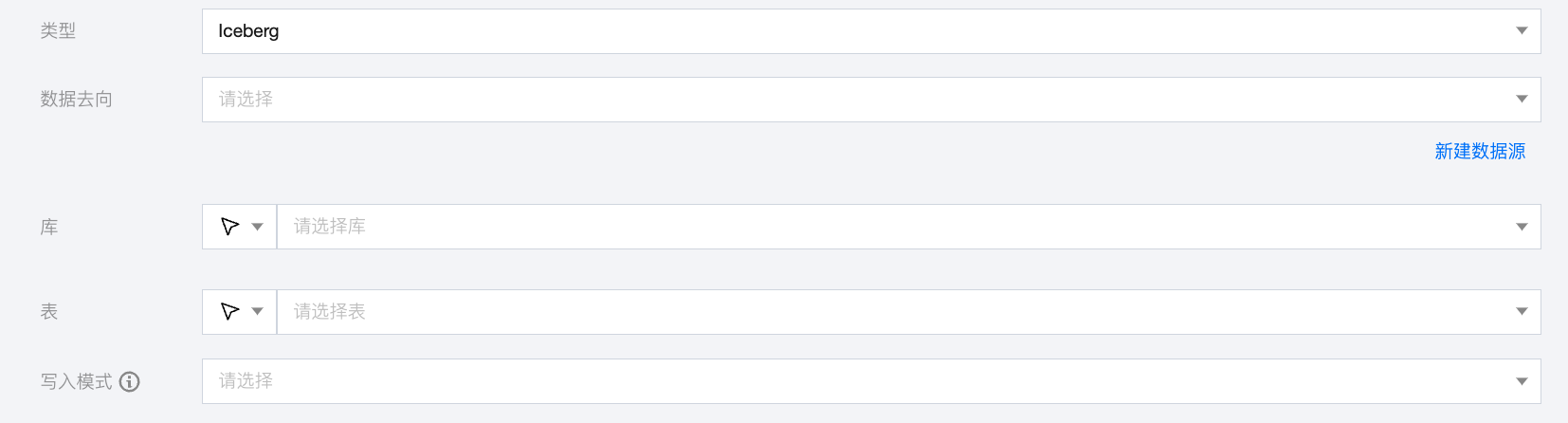
参数 | 说明 |
数据去向 | 需要写入的 Iceberg 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
写入模式 | Iceberg 写入支持三种模式: overwrite:覆盖写入。 append:追加写入。 upsert:根据设置主键字段进行数据更新写入。 |
数据类型转换支持
读取
Iceberg 数据类型 | 内部类型 |
int、long | Long |
float、double、decimal | Double |
string、fixed、binary、struct、list、map | String |
date、time、timestamp、timestamptz | Date |
boolean | Boolean |
写入
内部类型 | Iceberg 数据类型 |
Long | int、long(bigint) |
Double | float、double、decimal |
String | string、struct、list、map |
Date | date、time、timestamp、timestamptz |
Bytes | binary |
Boolean | boolean |
实践教程
优化 Iceberg 表读取速率
1. 目前 Iceberg 支持分片并发读取的,切割键可以是 string,long,int, decimal,timestamp 类型。
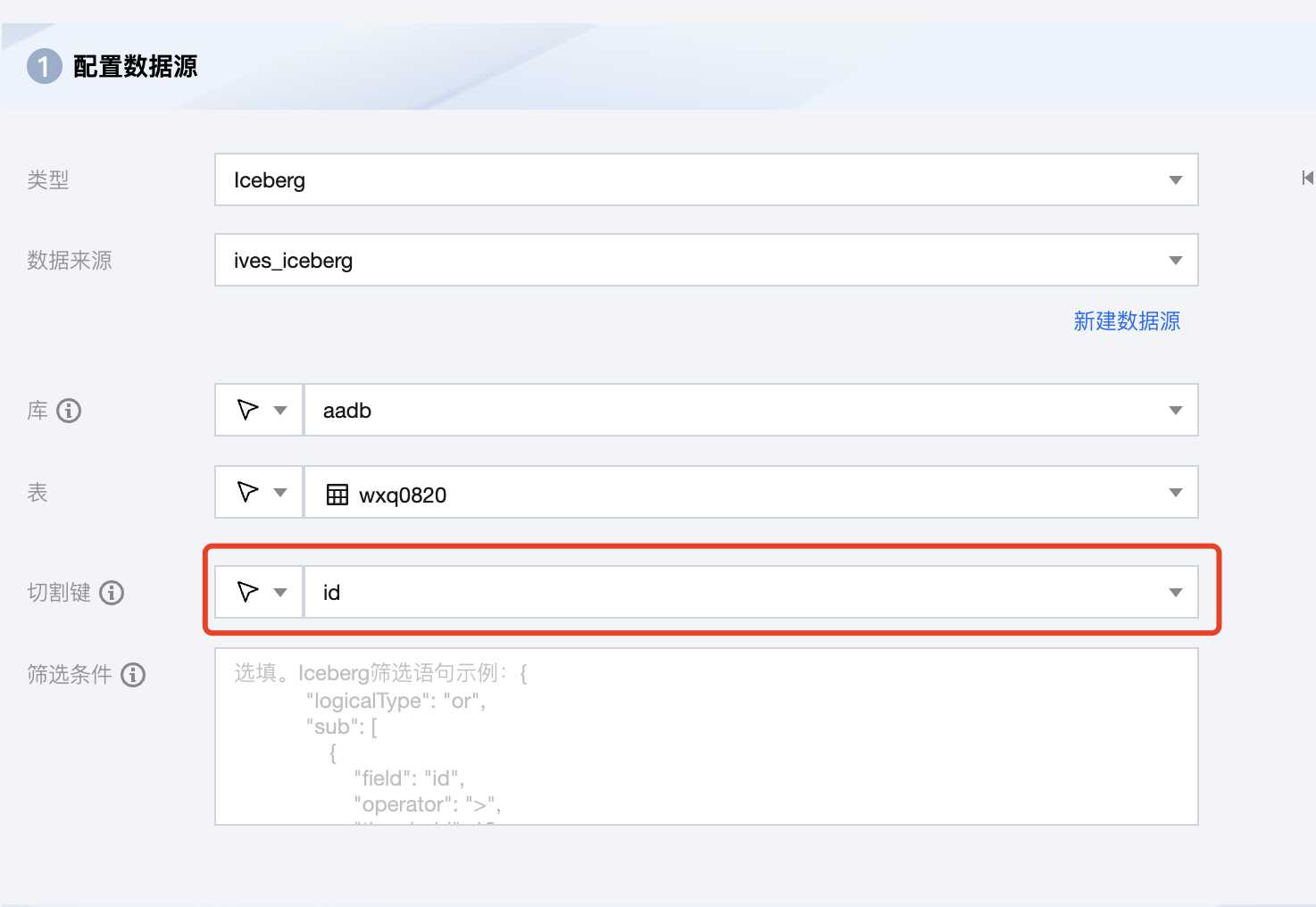
2. 在实际操作中,为了达到最优的读取效率,Iceberg 表最好设置为分区表,切割键选择分区字段。
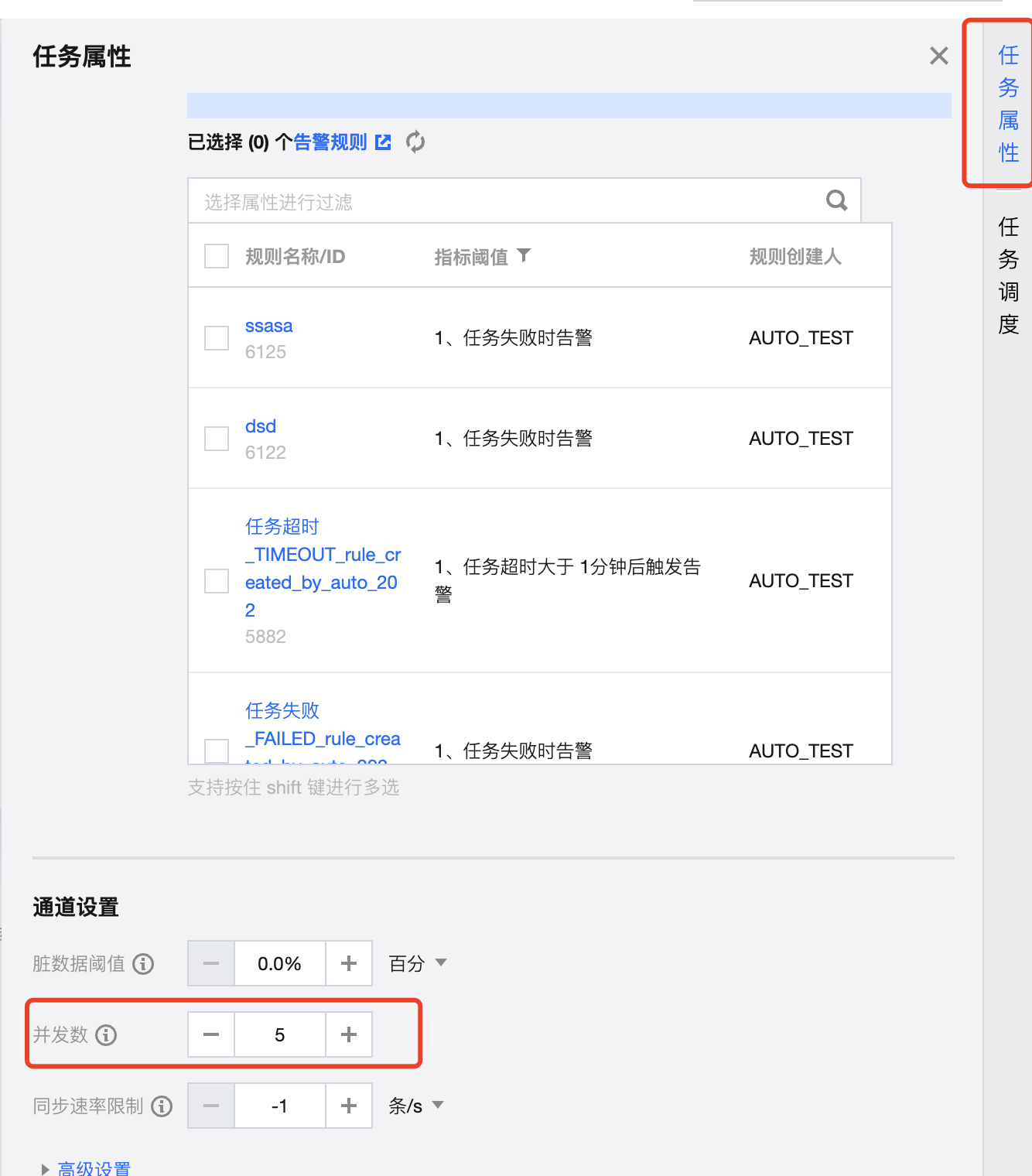
3. 例子:配置离线任务全量读取 Iceberg,原表为非分区表,有74列,共有2亿条数据,选择一个字段 id 作为切割键, 设置8个并发,同步速率仅约为4M/s。
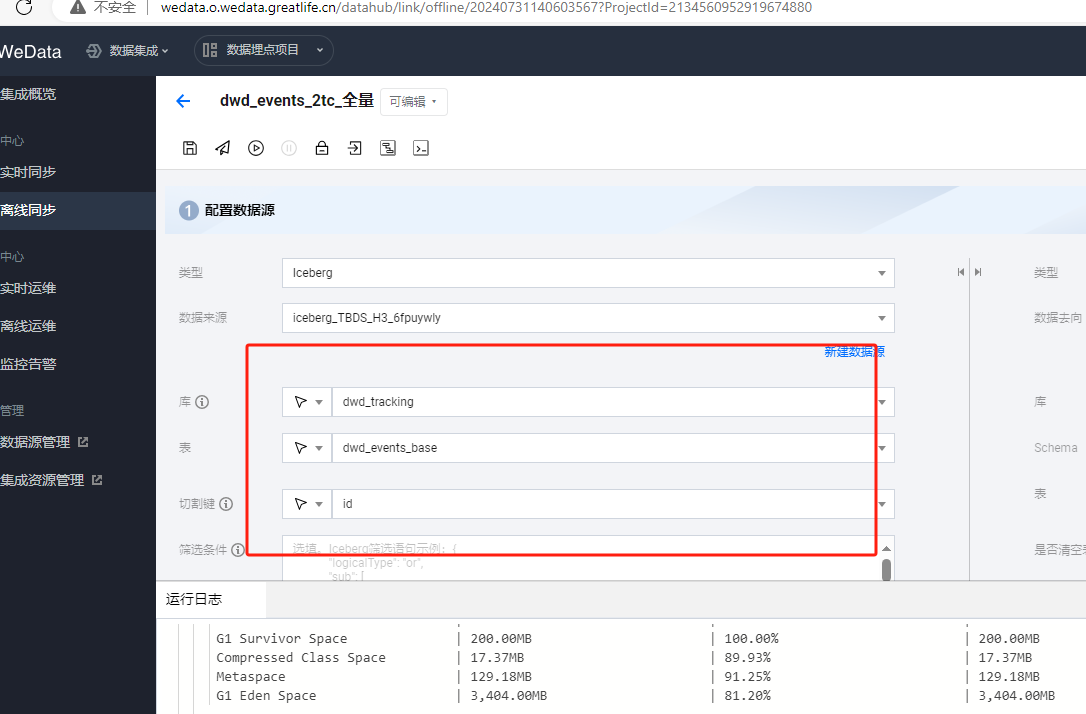
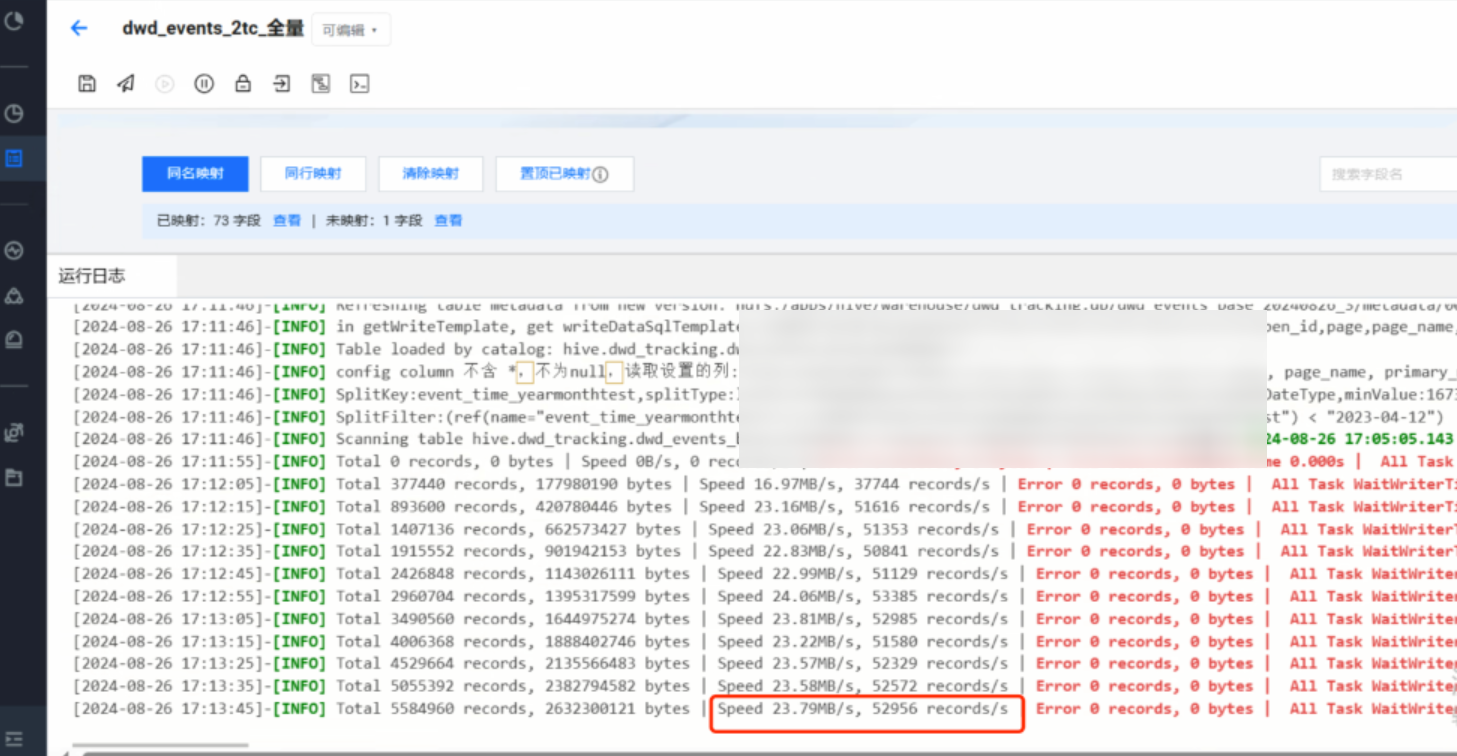
4. 将原表调整为分区表后,以'年份 - 月份'作为分区键,共创建28个分区,同样8个并发,切割键选择分区字段 event_time_yearmonthtest,速率提升到24M/s , 性能提升6倍。
文档反馈