Hive 数据源
Download
聚焦模式
字号
支持版本
支持 Hive 1.x、2.x、3.x 版本。
使用限制
1. 目前仅支持读取 TextFile、ORCFile 和 ParquetFile 三种格式的文件,建议为 ORC 或者 Parquet。
2. Hive 读取利用 JDBC 连接 HiveServer2 获取数据,需要在数据源正确配置 HiveServer2 的 jdbc url。
3. Hive 写入需要连接 Hive Metastore 服务,请在数据源正确配置 Metastore Thrift 协议的 IP 和端口。如果是自定义 Hive 数据源,还需要上传 hive-site.xml、core-site.xml 和 hdfs-site.xml 。
4. 重建 Hive 表时如需增加列字段,需要加上 cascade 关键字。防止 Partition Metadata 没有更新,影响数据查询。
5. 使用数据集成向 Hive 集群进行离线同步的过程中,会在服务端侧产生临时文件,在同步任务执行完成时,会自动删除。您需要留意服务端 HDFS 目录文件数限制,避免非预期的文件数达到上限导致 HDFS 文件系统不可用,无法保障文件数在 HDFS 目录允许范围内。
Hive 离线单表读取节点配置
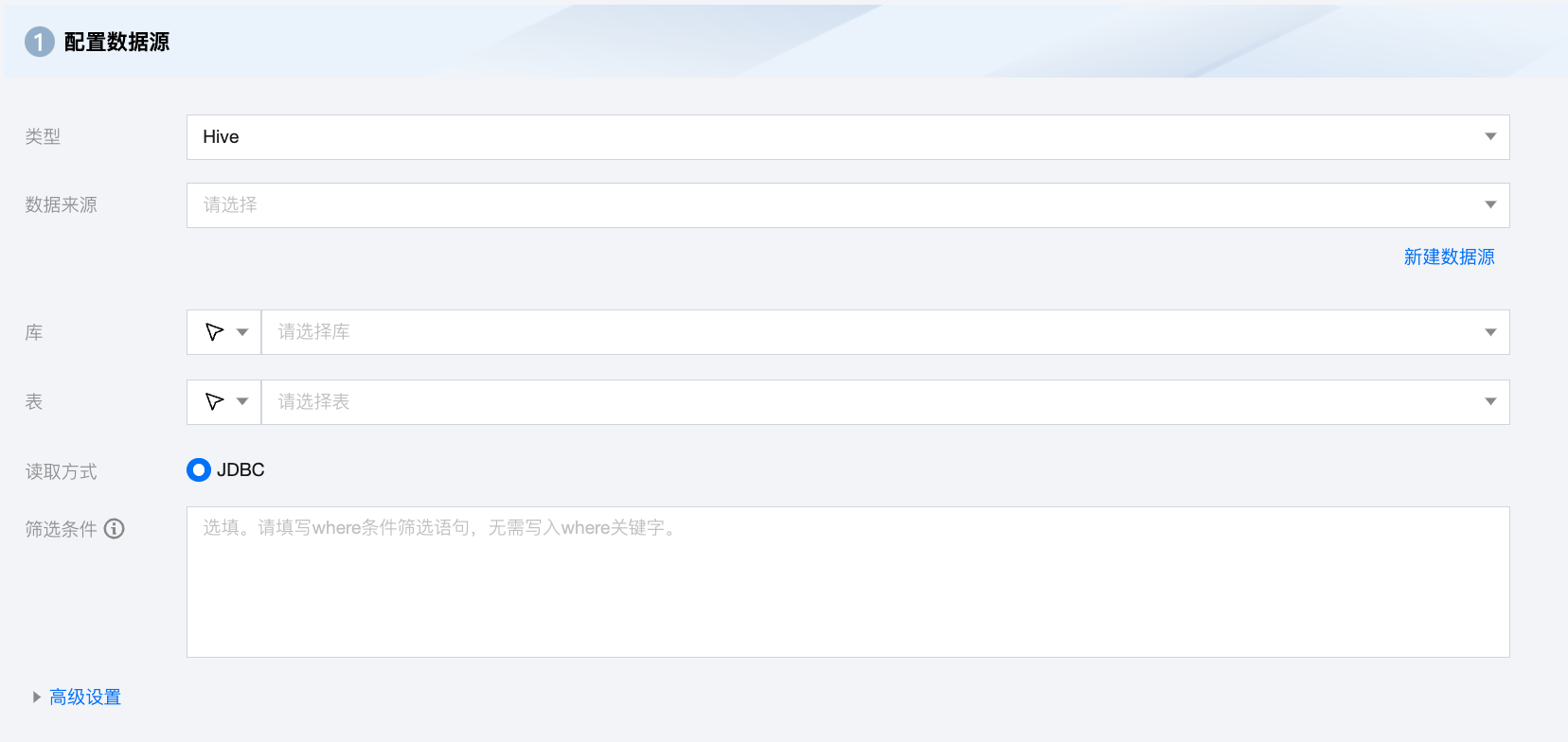
参数 | 说明 |
数据来源 | 可用的 Hive 数据源 |
库 | 支持选择、或者手动输入需读取的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步 |
表 | 支持选择、或者手动输入需读取的表名称 |
读取方式 | 仅支持 JDBC 读取方式 |
筛选条件(选填) | 基于 Hive JDBC 方式读取数据时,支持使用 Where 条件做数据过滤,但是此场景下,Hive 引擎底层可能会生成 MapReduce 任务,效率较慢 |
高级设置(选填) | 可根据业务需求配置参数。 |
Hive 离线单表写入节点配置
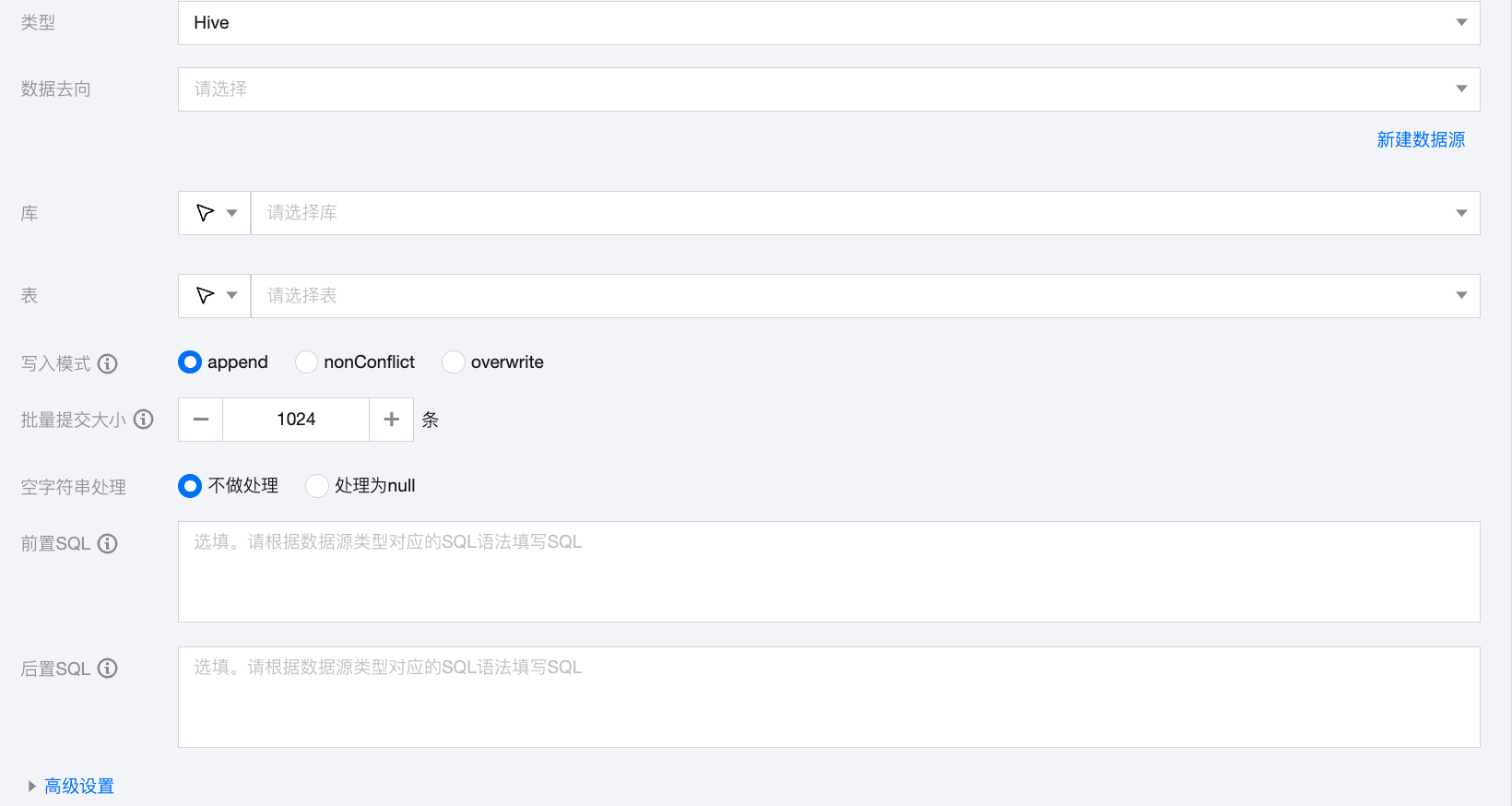
参数 | 说明 |
数据去向 | 需要写入的 Hive 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
写入模式 | Hive 写入支持三种模式: Append:保留原始数据, 新行追加写入 nonConflict:数据冲突时报错 Overwrite:删除原有数据重新写入 writeMode 是高危参数,请您注意数据的写出目录和写入模式,避免误删数据。加载数据行为需要配合 hiveConfig 使用,请注意您的配置。 |
批量提交大小 | 一次性批量提交的记录数大小,该值可以极大减少数据同步系统与 Hive 的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程 OOM 异常。 |
空字符串处理 | 不做处理:写入时,不处理空字符串。 处理为 null:写入时,将空字符串处理为 null。 |
前置 SQL(选填) | 执行同步任务之前执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,执行前清空表中的旧数据(truncate table tablename)。 |
后置 SQL(选填) | 执行同步任务之后执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,加上某一个时间戳 alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP。 |
高级设置(选填) | 可根据业务需求配置参数。 |
数据类型转换支持
读取
Hive 读取支持的数据类型及转换对应关系如下(在处理 Hive 时,会先将 Hive 数据源的数据类型和数据处理引擎的数据类型做映射):
Hive 数据类型 | 内部类型 |
TINYINT,SMALLINT,INT,BIGINT | Long |
FLOAT,DOUBLE | Double |
String,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY | String |
BOOLEAN | Boolean |
Date,TIMESTAMP | Date |
写入
Hive 读取支持的数据类型及转换对应关系如下:
内部类型 | Hive 数据类型 |
Long | TINYINT,SMALLINT,INT,BIGINT |
Double | FLOAT,DOUBLE |
String | String,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
Boolean | BOOLEAN |
Date | Date,TIMESTAMP |
常见问题
1.Hive On CHDFS表写入报错:Permission denied: No access rules matched
问题信息:
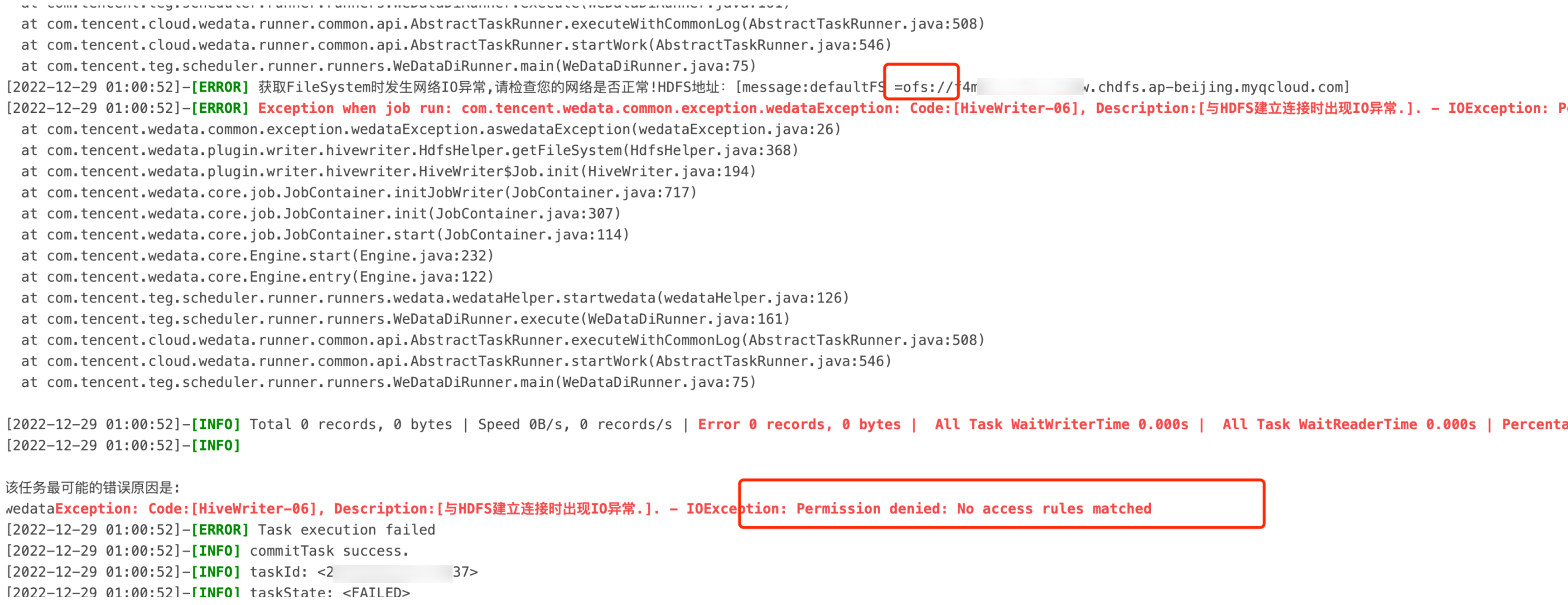
问题原因:
数据集成资源组是全托管资源组,资源组的出口网段非客户的 VPC 内网网段,需要对数据集成资源组放开安全组。
请在 CHDFS 挂载点,对集成资源组的 CHDFS 权限 id 进行授权。

解决方案:
打开页面:API 3.0 Explorer 填入参数,其中 MountPointId 为客户 CHDFS 挂载点,AccessGroupIds.N 为 数据集成资源组的 CHDFS 权限 id(注意,不同区域的权限 id 不同)。
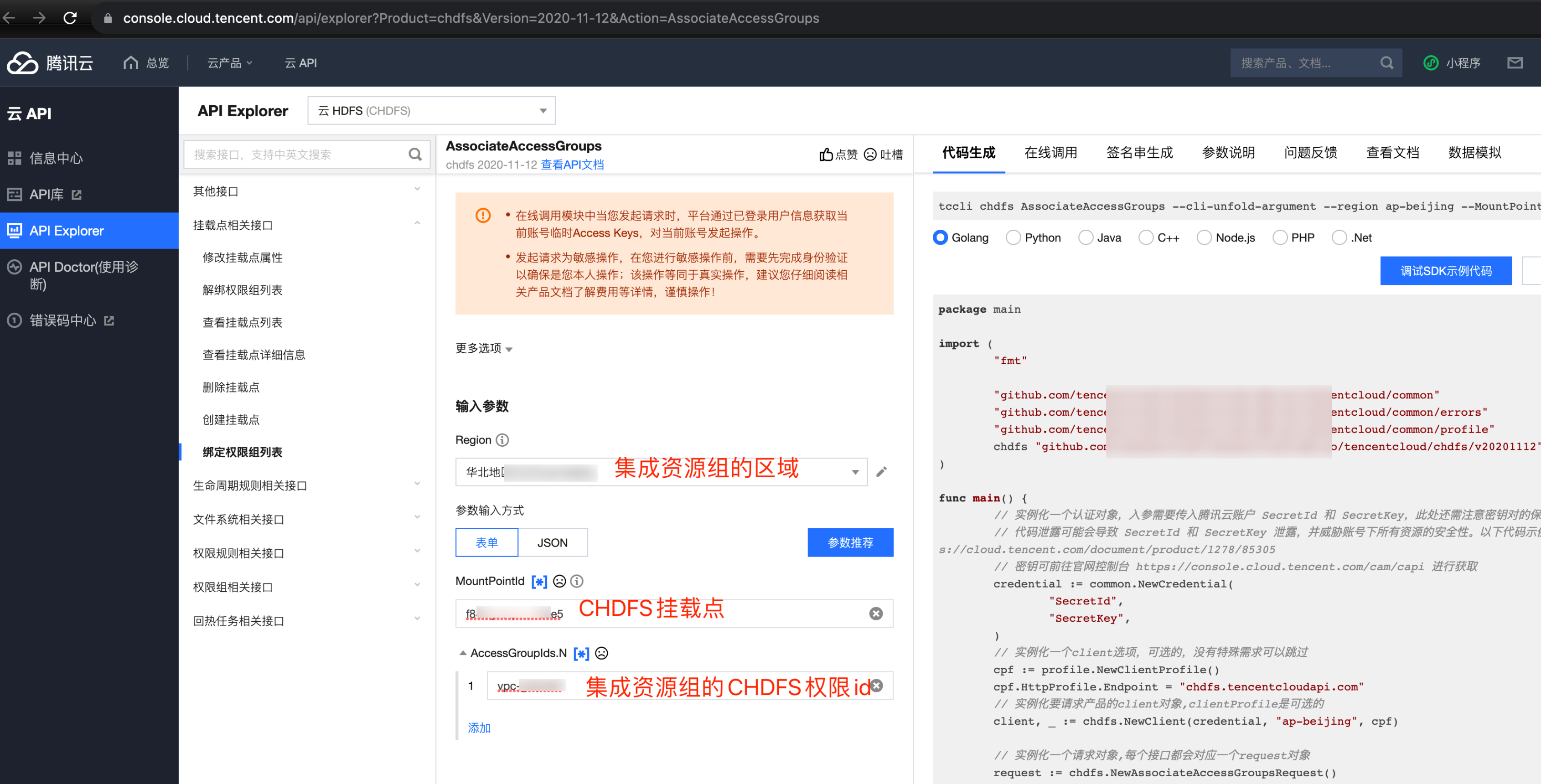
数据集成资源组 CHDFS 权限 id 和区域对照表:
区域 | 数据集成资源组 CHDFS 权限 id |
北京 | ag-wgbku4no |
广州 | ag-x1bhppnr |
上海 | ag-xnjfr9d3 |
新加坡 | ag-phxtv0ah |
美国硅谷 | ag-tgwl8bca |
弗吉尼亚 | ag-esxpwxjn |
2.同步过程中部分字段查询为 NULL
问题原因:
Hive 分区表创建后,后续 ALTER 添加新字段并没有添加 cascade 关键字导致 Partition Metadata 没有更新,影响数据查询。
解决方案:
alter table table_name add columns (time_interval TIMESTAMP) cascade;
3.写Hive报[fs.defaultFS]是必填参数错误
问题信息:
[2023-09-06 17:29:34]-[ERROR] Exception when job run: com.tencent.wedata.common.exception.wedataException: Code:[HiveWriter-01], Description:[您缺少必须填写的参数值.]。-您提供配置文件有误, [fs.defaultFS]是必填参数, 不允许为空或者留白。at com.tencent.wedata.common.exception.wedataException.aswedataException(wedataException.java:28)at com.tencent.wedata.plugin.writer.hivewriter.HiveWriter$Job.init(HiveWriter.java:172)at com.tencent.wedata.core.job.JobContainer.initJobWriter(JobContainer.java:717)at com.tencent.wedata.core.job.JobContainer.init(JobContainer.java:307)at com.tencent.wedata.core.job.JobContainer.start(JobContainer.java:114)
问题原因:
数据源设置时没有上传配置文件,fs.defaultFS 是 core-site.xml 里面的内容。
解决方案:
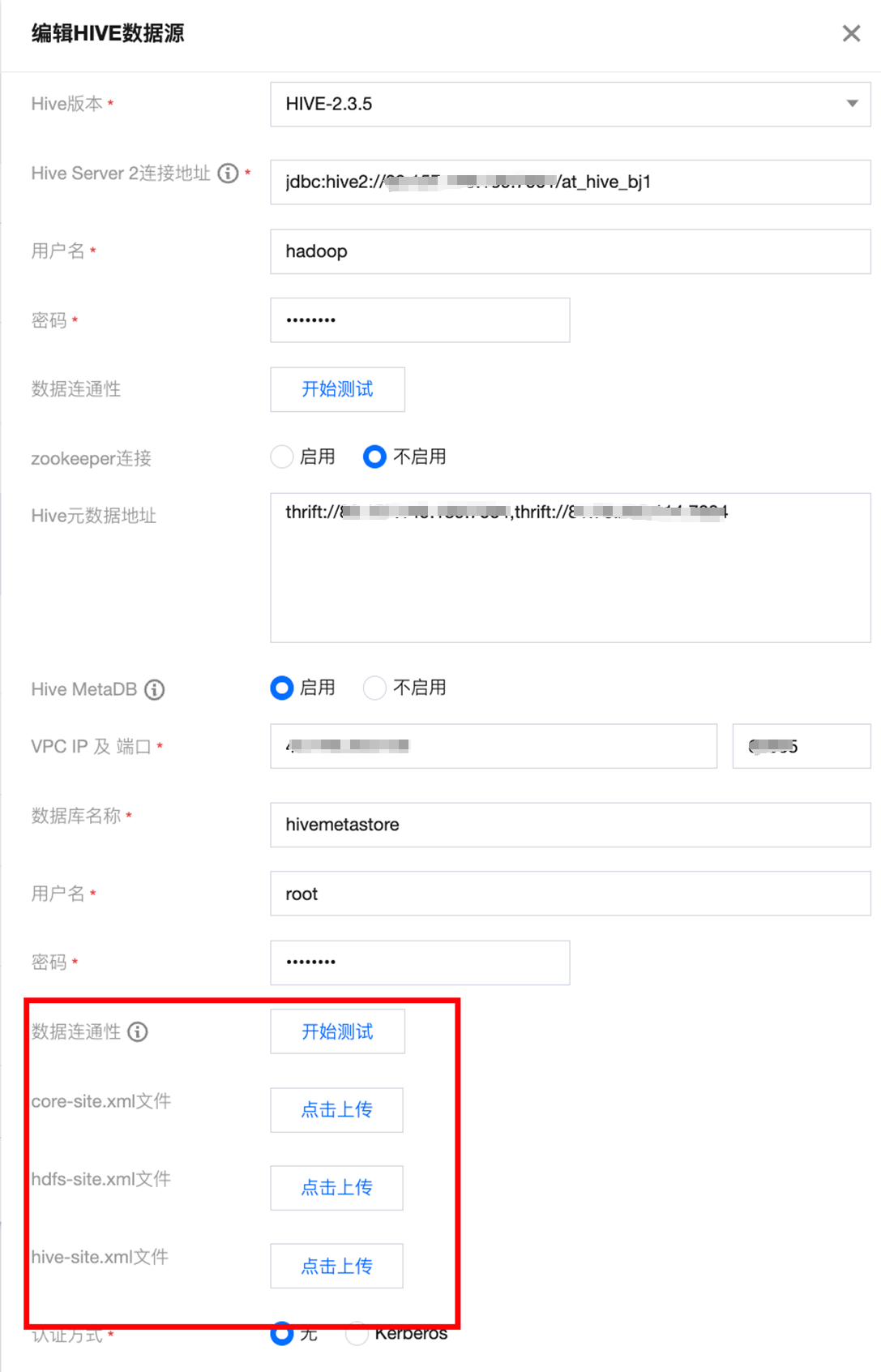

文档反馈