Elasticsearch/腾讯云 Elasticsearch 数据源
Download
聚焦模式
字号
腾讯云 Elasticsearch 数据源与 Elasticsearch 数据源配置方式相同,此处以 Elasticsearch 数据源为例进行讲解。
支持版本
支持 ElasticSearch 6.x、7.x 版本。
使用限制
1. Elasticsearch Reader 会获取 Server 端 shard 信息用于数据同步,需要确保在任务同步中 Server 端的 shards 处于存活状态,否则会存在数据不一致风险。
2. 不支持同步 scaled_float 类型的字段。
3. 不支持同步字段中带有关键字 $ref 的索引。
Elasticsearch 离线单表读取节点配置
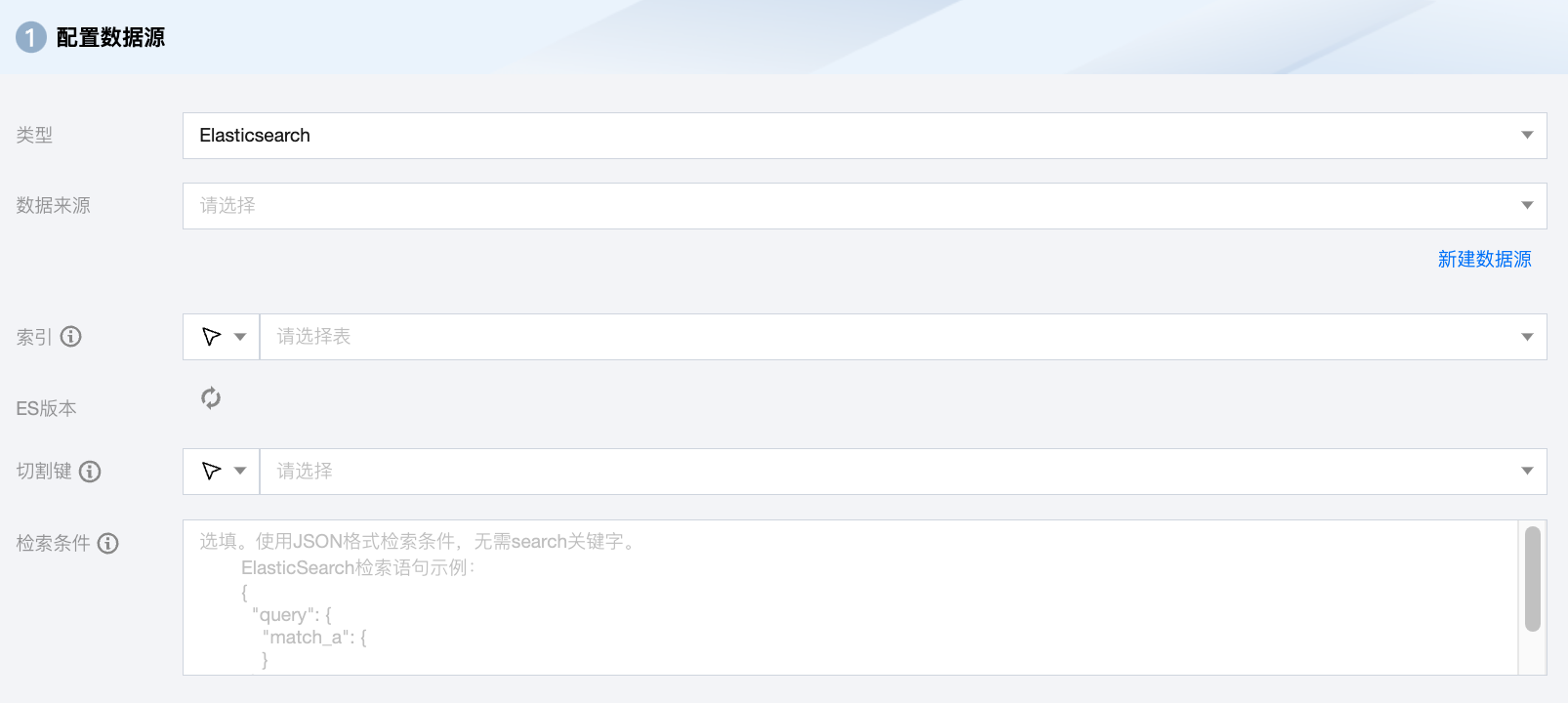
参数 | 说明 |
数据来源 | 选择当前项目中可用的 Elasticsearch 数据源。 |
索引 | 支持多个索引名称或正则表达式。索引名称正则表达式请使用通配符(*),如 index_*。 |
ES 版本 | 根据数据源和索引确定 ES 版本。 |
切割键 | 指定用于数据分片的字段,指定后将启动并发任务进行数据同步。您可以将源数据表中某一列作为切分键,建议使用主键或有索引的列作为切分键。 |
检索条件(选填) | 使用 JSON 格式进行检索。 |
Elasticsearch 离线单表写入节点配置
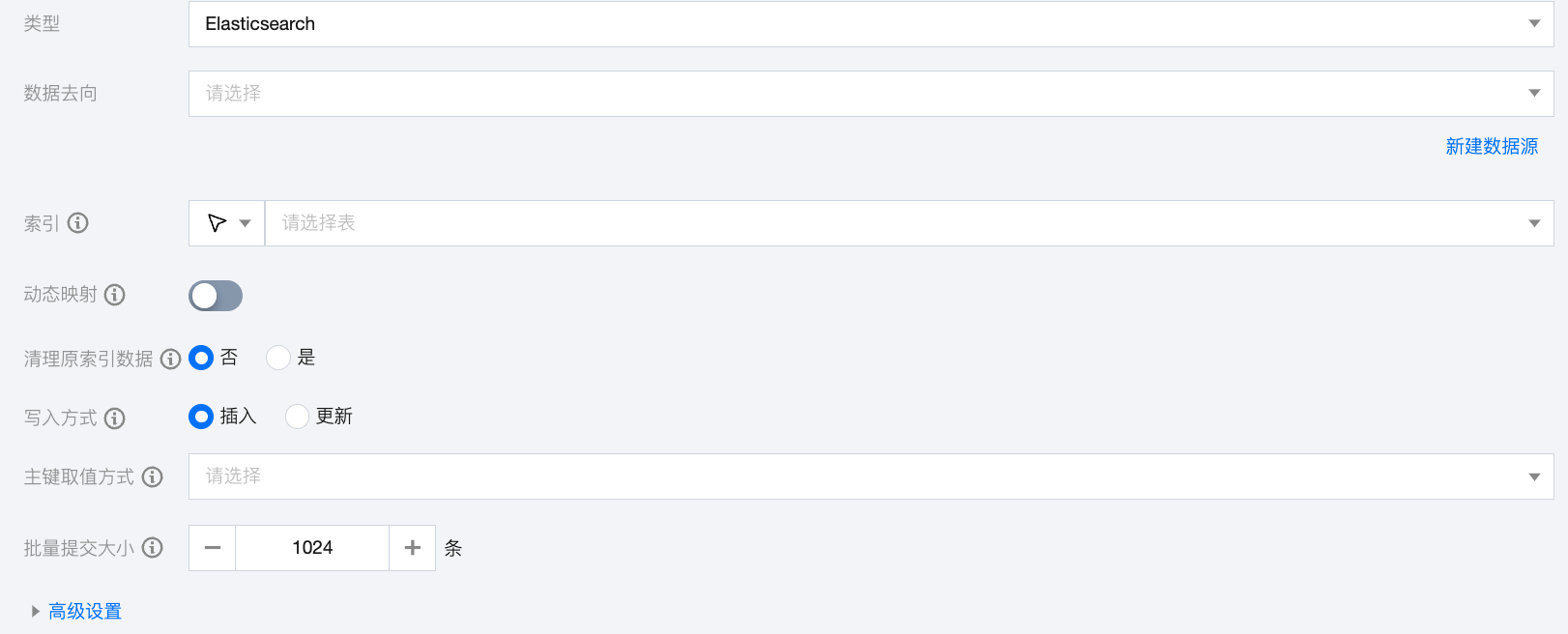
参数 | 说明 |
数据去向 | 选择当前项目中可用的 Elasticsearch 数据源。 |
索引 | ElasticSearch 中的索引名称。 |
动态映射 | 定义当在文档中发现未存在的字段时,同步任务是否通过 Elasticsearch 动态映射机制为字段添加映射。 打开:保留 Elasticsearch 的自动 mappings 映射。 关闭:默认关闭,根据同步任务配置的 column 生成并更新 Elasticsearch 的 mappings 映射。 Elasticsearch 7.x 版本的默认 type 为_doc。使用 Elasticsearch 的自动 mappings 时,请配置 _doc 和 esVersion 为7。 |
清理原索引数据 | 手动选择是否清理原索引数据: 否:导入数据前保留索引中已存在的数据。 是:导入数据前删除原来的索引并重建同名索引,此操作会删除该索引下的数据。 |
写入方式 | 支持插入和更新两种写入方式: 插入:所有数据直接插入。 更新:存在相同主键时更新数据,否则插入。 |
主键取值方式 | 支持三种取值方式: 源表主键:document 的 id 使用源表的主键。 联合主键:document 的 id 使用源表的多个列共同确定。 无主键:默认生成 _id 值。 |
批量提交大小 | 一次性批量提交的记录数大小,该值可以极大减少数据同步系统与 ElasticSearch 的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程 OOM 异常。 |
高级设置(选填) | 可根据业务需求配置参数。 |
数据类型转换支持
读取
ElasticSearch 数据类型 | 内部类型 |
byte、short、integer、long、unsigned long | Long |
float、double、half_float | Double |
string、text、keyword、integer_range、long_range、float_range、double_range、date_range、array、object、nested、flattened、geo_point、geo_shape | String |
date | Date |
binary | Bytes |
boolean | Boolean |
写入
内部类型 | ElasticSearch 数据类型 |
Long | byte、short、integer、long |
Double | float、double |
String | string、text、keyword、object、nested、geo_point、geo_shape、ip、binary、completion |
Date | date |
Boolean | boolean |
常见问题
ES writer 清除索引后,自动重建的索引的字段类型不符合预期
问题信息:
ES 写结点配置 “清理原索引数据”,选择“是”重跑任务时,es writer 并不会主动创建索引。直接写数据时ES 会根据数据推断,自动创建索引。新索引字段类型可能与旧版本不一样。
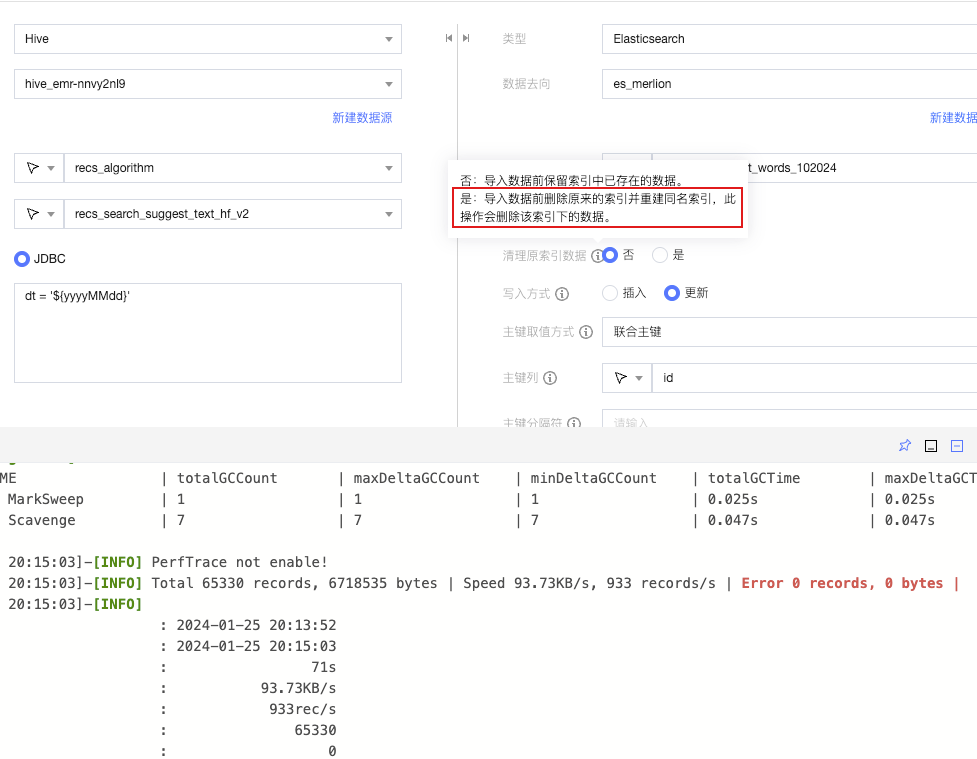
问题原因:
ES writer 清理原索引数据的方式为直接delete 索引,并没有类似 MySQL 的 truncate table 的语法。索引删除后,ES Server 根据数据推断索引字段类型和原索引的字段类型可能不同。
解决方案:
通过 ES template 提前定义索引的字段类型。
创建示例:(merlion_suggest_words_* 表示对所有 merlion_suggest_words_ 打头的索引都生效 )。
PUT _template/merlion_suggest_words{"template": "merlion_suggest_words_*","order": 1,"mappings": {"properties": {"biz_owner": {"type": "keyword"},"create_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||date_hour_minute_second||strict_date_optional_time||epoch_millis"},"is_deleted": {"type": "short"},"sug_words": {"type": "keyword"},"language": {"type": "keyword"}}},"settings": {"refresh_interval": "5s","number_of_replicas": 1,"number_of_shards": 1}}
文档反馈