批量任务创建
Download
聚焦模式
字号
批量创建周期性单表任务,支持30+以上关系型数据源,提升任务配置效率。
条件与限制
1. 已配置好来源及目标端的数据源以备后续任务使用。
2. 已购买数据集成资源组。
3. 已完成数据集成资源组与数据源的网络连通。
4. 已完成数据源环境准备。您可以基于您需要进行的同步配置,在同步任务执行前,授予数据源配置的账号在数据库进行相应操作的权限。
5. 若数据源配置的数据库账号不具备读写权限将导致任务运行失败,请根据实际读写场景配置具备相应权限的账号。
步骤一:新建批量单表同步任务
1. 登录 数据开发治理平台 WeData 控制台。
2. 单击左侧菜单中的项目列表,找到需要操作的目标项目。
3. 选择项目后,单击进入数据集成模块。
4. 单击左侧菜单中的离线同步 > 批量创建单表同步任务。
5. 单击新建后,即可进入批量创建单表同步任务配置页面,填写任务名称和描述后,单击创建并配置。
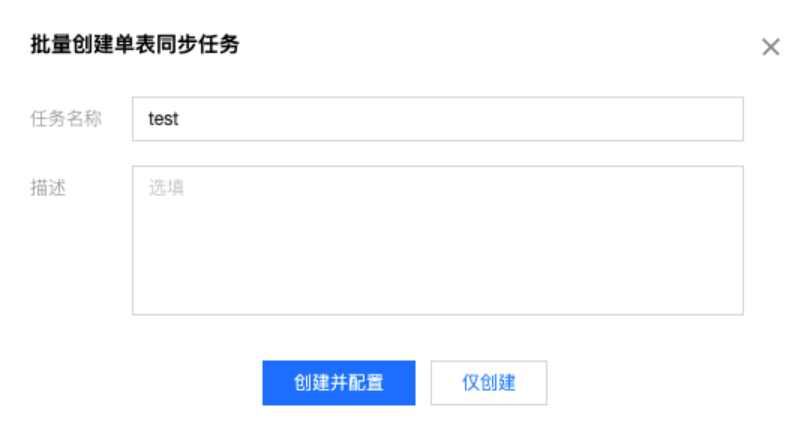
参数 | 说明 |
任务名称 | 任务的名称。 |
描述 | 选填。 |
步骤二:数据节点配置
读取节点
读取节点通用配置包括类型、数据来源、来源表等。
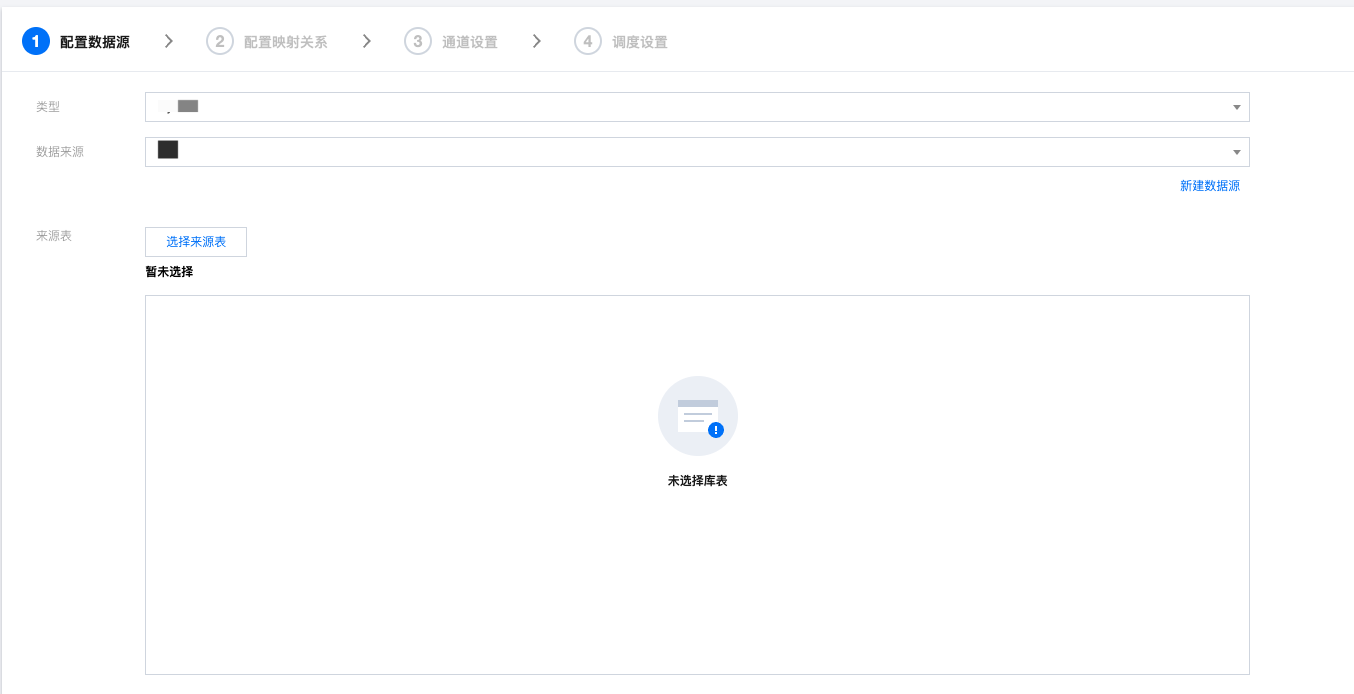
参数 | 说明 |
类型 | 选择数据源类型 |
数据来源 | 选择所选数据源类型下可用的数据源。 |
来源表 | 选择来源库、表 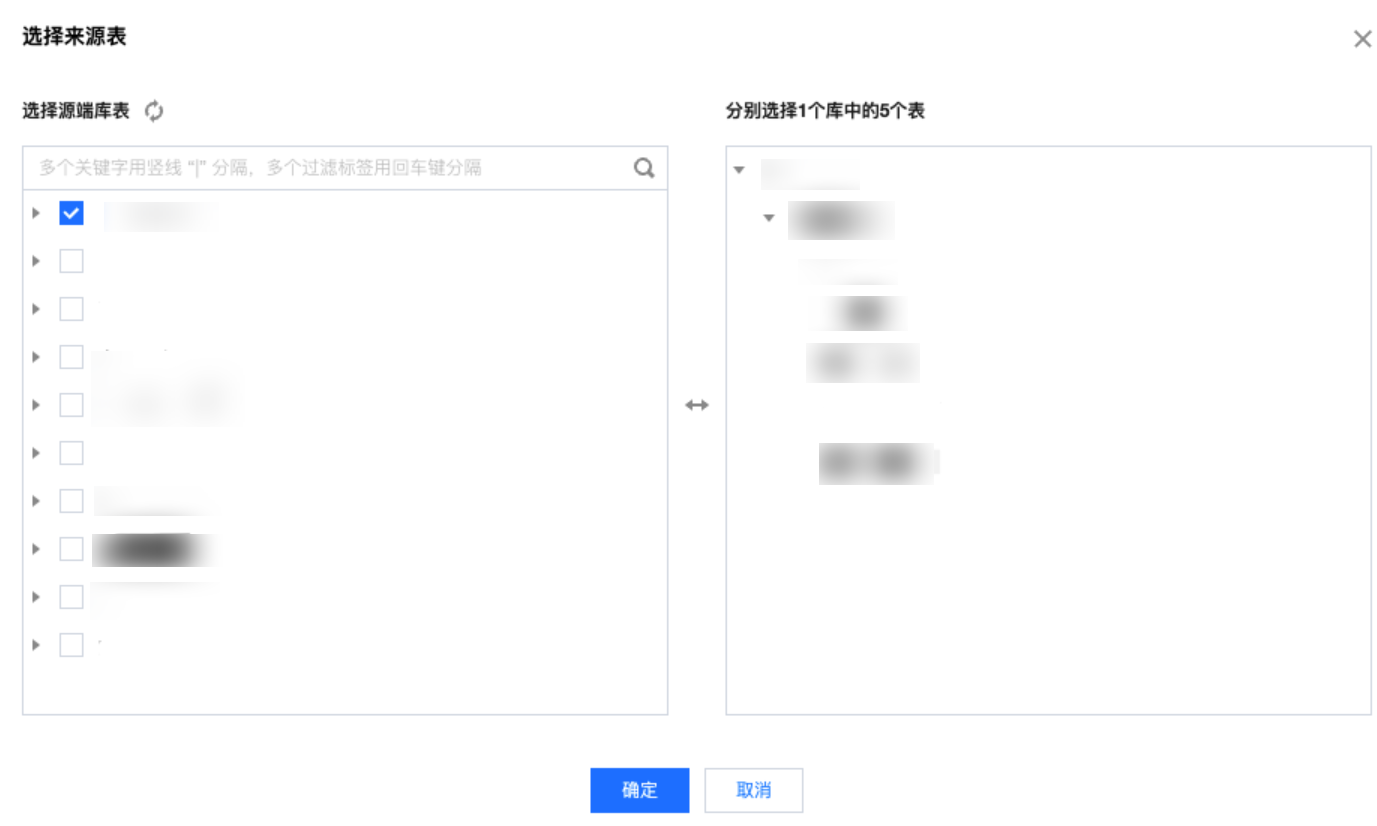 注意: 来源表的单次批量任务支持的最大数量为500张表 |
其他配置项 | 可参考具体数据源的配置方式,请参见 离线同步支持的数据源。 |
写入节点
写入节点通用配置包括类型、数据去向、库匹配策略、表匹配策略等。
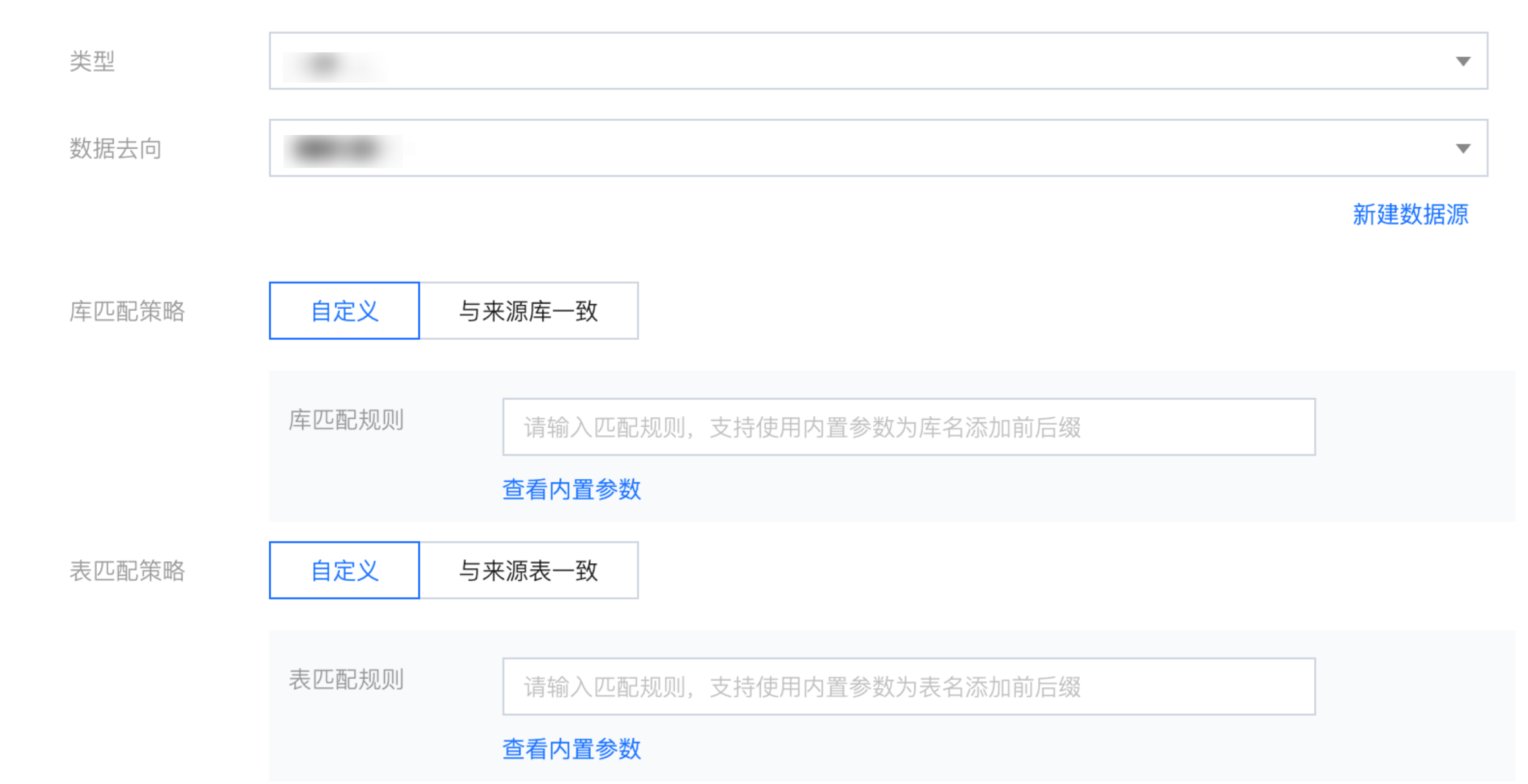
参数 | 说明 |
类型 | 选择数据源类型 |
数据去向 | 选择所选数据源类型下需要写入的可用数据源。 |
库匹配策略 | 与来源库同名:匹配与读取节点所选择的数据库名称一致的数据库。 自定义:需输入匹配规则,支持使用内置参数和字符串组合生成目标库名称。 |
表匹配策略 | 与来源表同名:匹配与读取节点所选择的数据表名称一致的数据表。 自定义:需输入匹配规则,支持使用内置参数和字符串组合生成目标表名称。 |
其他配置项 | 可参考具体数据源的配置方式,请参见 离线同步支持的数据源。 |
说明:
读取端支持的数据源类型:MySQL、TDSQL-C MySQL、TDSQL MySQL、TDSQL PostgreSQL、TCHouse-P专有云、PostgreSQL、Oracle、SQL Server、IBM DB2、达梦DM、SAP HNNA、SyBase、OceanBase、Doris、HBase、Hive、Kudu、Greenplum、Clickhouse、GaussDB、Gbase、Impala、Vertica、Tbase、HDFS、COS、FTP、SFTP、S3、Iceberg、StarRocks。
写入端支持的数据源类型:MySQL、TDSQL-C MySQL、TDSQL MySQL、TDSQL PostgreSQL、TCHouse-P专有云、PostgreSQL、Oracle、SQL Server、IBM DB2、达梦DM、SAP HNNA、Doris、HBase、Hive、Kudu、Greenplum、Clickhouse、GaussDB、Gbase、Tbase、Impala、Vertica、COS、HDFS、FTP、SFTP、S3、Iceberg、StarRocks。
步骤三:配置映射关系
情况一:数据库 - 数据库链路配置映射关系
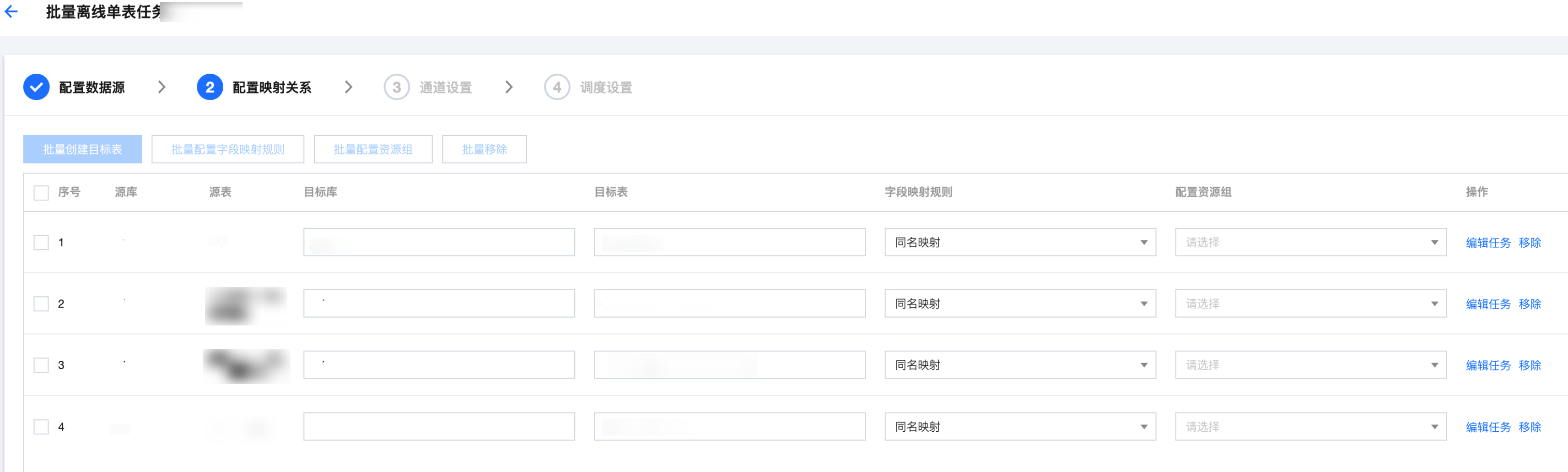
参数 | 说明 | |
序号 | | 从小到大排序,展示映射关系列表序号。 |
源库 | | 数据节点配置中读取端所选择的数据库。 |
源表 | | 数据节点配置中读取端所选择的数据表。 |
目标库 | | 数据节点配置中写入端所选择的数据库,支持输入模式、选择模式。 |
目标表 | | 数据节点配置中写入端所选择的数据表,支持输入模式、选择模式。 |
创建 | | 创建写入端的数据表,根据来源表自动构建生成目标表结构,支持手动修改键表语句。 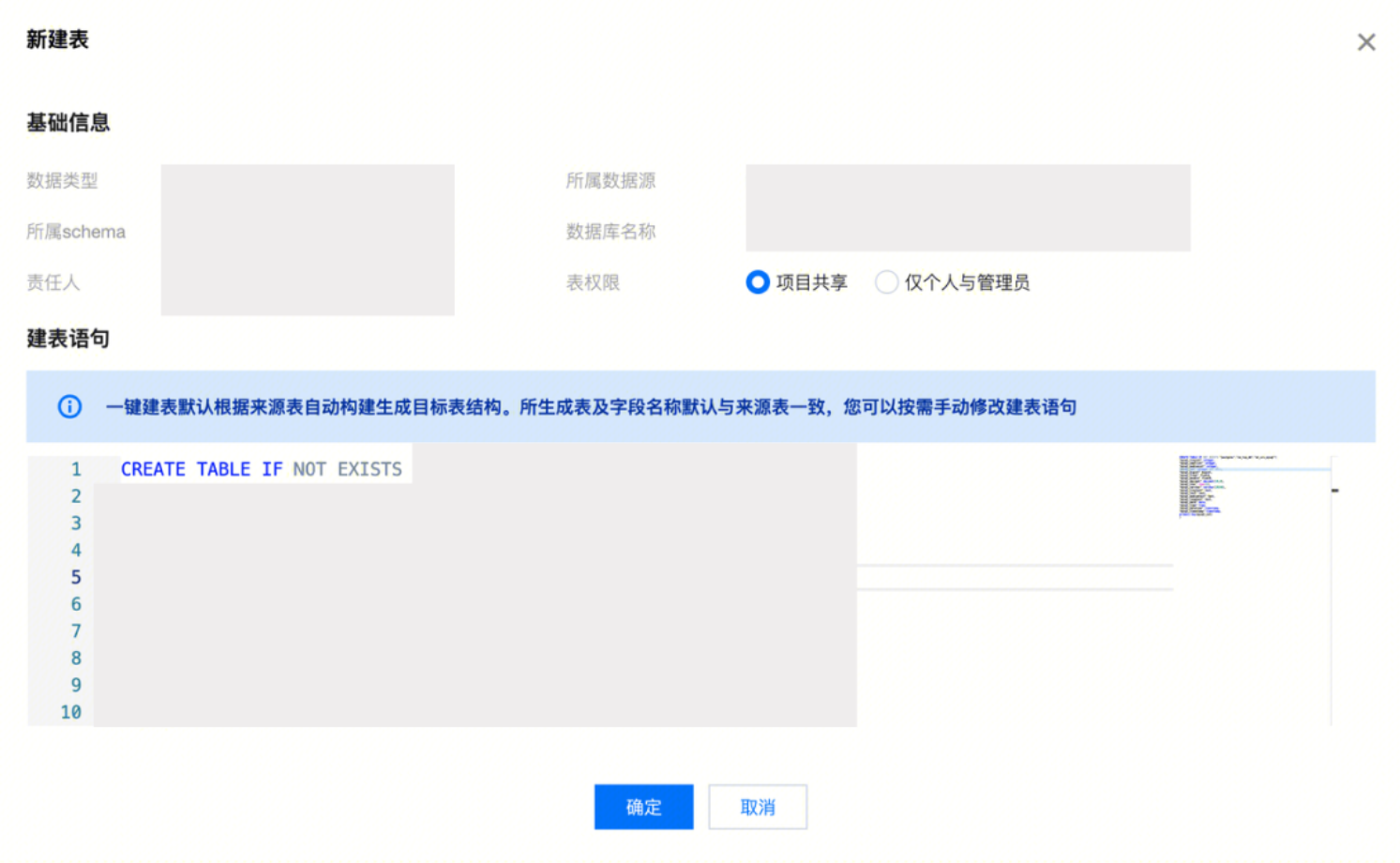 说明: 支持以下链路创建写入端的数据表: MySQL,Oracle,SQL Server,PostgreSQL -> Hive MySQL,TDSQL-C MySQL,PostgreSQL -> Doris MySQL, TDSQL-C MySQL,TDSQL MySQL,Oracle,SQL Server,PostgreSQL,达梦DM -> Iceberg MySQL, TDSQL-C MySQL,TDSQL MySQL,Oracle,OceanBase,PostgreSQL,达梦DM -> TChouse-P |
字段映射规则 | | 字段映射关系旨在通过连线的方式指定目标字段内容的来源,支持选择同名映射、同行映射,通过编辑任务支持自定义字段映射规则。 |
配置资源组 | | 支持下拉选择可用的资源组。 |
操作 | 编辑任务 | 支持详细进行个性化配置,如配置数据源、字段映射规则等。 |
| 移除 | 删除该行映射关系。 |
批量创建目标表 | | 勾选列表后,可批量创建写入端的数据表。 确认键表规则:确认键表信息如数据来源、来源库等,支持预览/编辑表语句。 批量键表:展示键表结果,支持查看键表语句、重试。 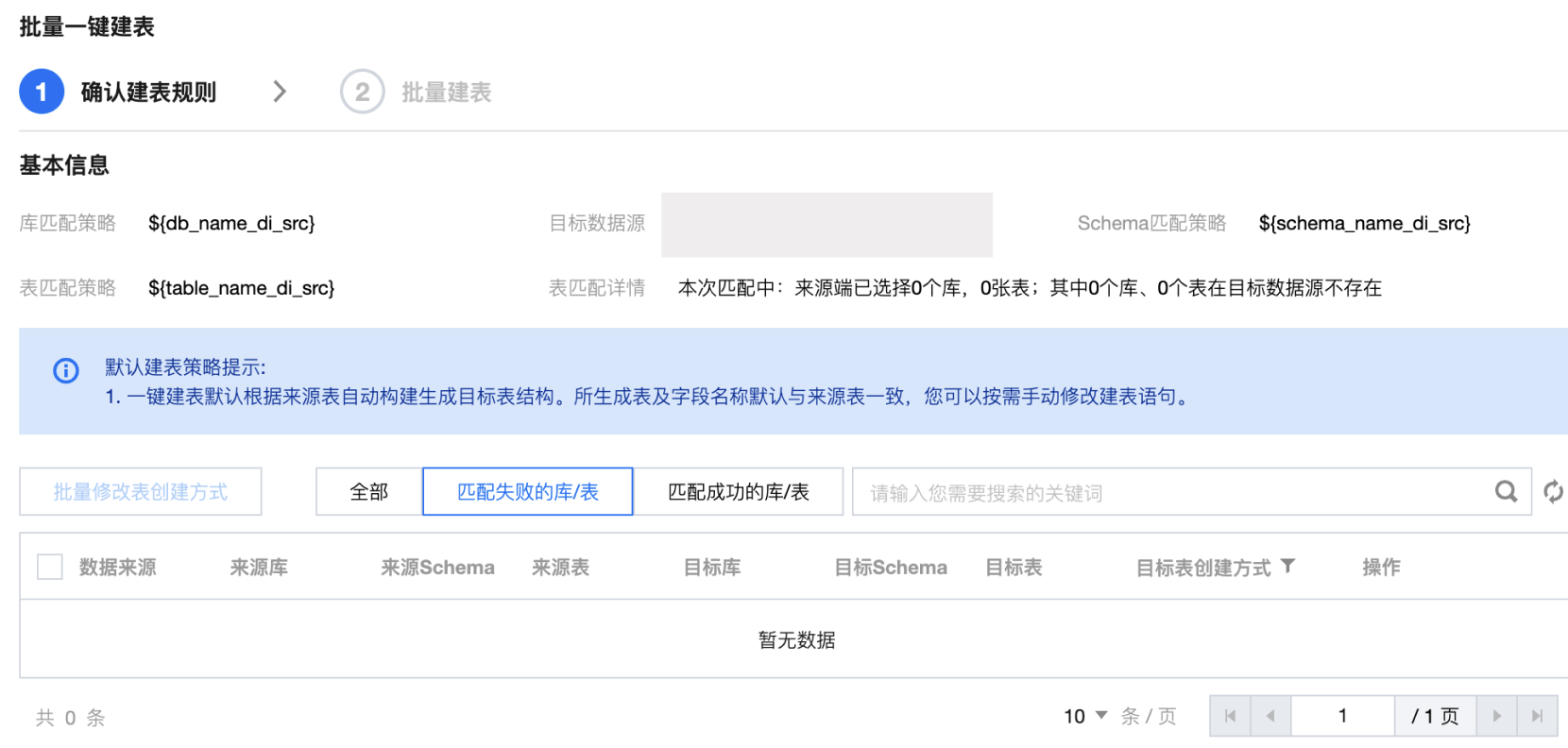 |
批量配置字段映射规则 | | 勾选列表后,支持批量配置映射关系,可选择同名映射、同行映射。 |
批量配置资源组 | | 勾选列表后,支持批量配置可用的资源组。 |
批量移除 | | 勾选列表后,支持批量删除勾选的映射关系。 |
情况二:文件 - 文件链路配置映射关系

参数 | 说明 | |
序号 | | 从小到大排序,展示映射关系列表序号。 |
源文件路径 | | 读取端为 FTP、SFTP、HDFS、S3 时需手动填写。 读取端为 COS 时支持手动输、选择模式。 |
目标文件路径 | | 写入端为 FTP、SFTP、HDFS、S3 时需手动填写。 写入端为 COS 时支持手动输入、选择模式。 |
字段映射规则 | | 字段映射关系旨在通过连线的方式指定目标字段内容的来源,支持选择同名映射、同行映射,通过编辑任务支持自定义字段映射规则。 |
配置资源组 | | 支持下拉选择可用的资源组。 |
操作 | 编辑任务 | 支持详细进行个性化配置,如配置数据源、字段映射规则等。 |
| 移除 | 删除该行映射关系。 |
批量配置字段映射规则 | | 勾选列表后,支持批量配置映射关系,可选择同名映射、同行映射。 |
批量配置资源组 | | 勾选列表后,支持批量配置可用的资源组。 |
批量移除 | | 勾选列表后,支持批量删除勾选的映射关系。 |
情况三:数据库-文件链路配置映射关系
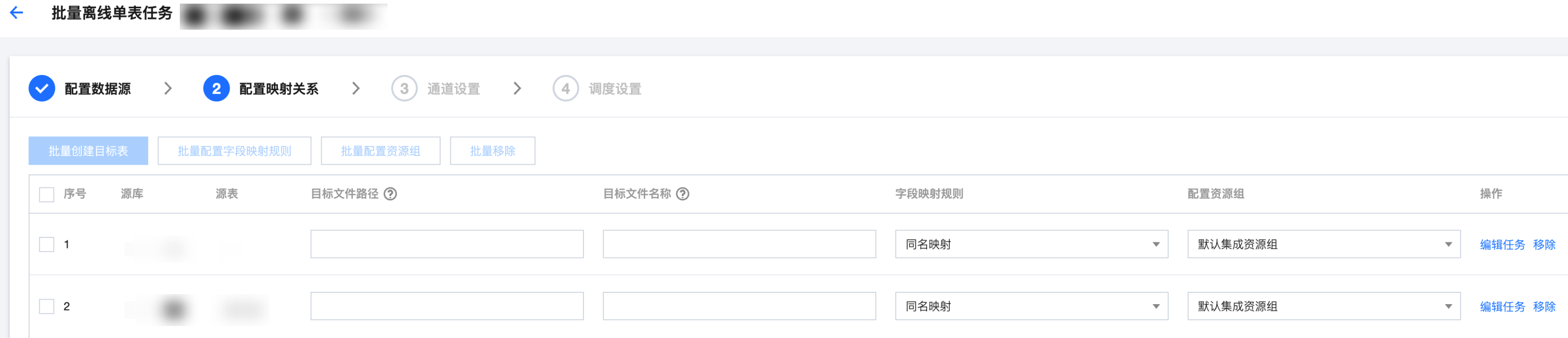
参数 | 说明 | |
序号 | | 从小到大排序,展示映射关系列表序号。 |
源库 | | 数据节点配置中读取端所选择的数据库。 |
源表 | | 数据节点配置中读取端所选择的数据表。 |
目标文件路径 | | 写入端为 FTP、SFTP、HDFS、S3 时需手动填写。 写入端为 COS 时支持手动输入、选择模式。 |
目标文件名称 | | 写入端为 FTP、SFTP、HDFS、S3 时用户手动填写。 写入端为 COS 时支持手动输入、选择模式。 |
字段映射规则 | | 字段映射关系旨在通过连线的方式指定目标字段内容的来源,支持选择同名映射、同行映射,通过编辑任务支持自定义字段映射规则。 |
配置资源组 | | 支持下拉选择可用的资源组。 |
操作 | 编辑任务 | 支持详细进行个性化配置,如配置数据源、字段映射规则等。 |
| 移除 | 删除该行映射关系。 |
批量配置字段映射规则 | | 勾选列表后,支持批量配置映射关系,可选择同名映射、同行映射。 |
批量配置资源组 | | 勾选列表后,支持批量配置可用的资源组。 |
批量移除 | | 勾选列表后,支持批量删除勾选的映射关系。 |
情况四:文件 - 数据库链路配置映射关系

参数 | 说明 | |
序号 | | 从小到大排序,展示映射关系列表序号。 |
源文件路径 | | 读取端为 FTP、SFTP、HDFS、S3 时需手动填写。 读取端为 COS 时支持手动输、选择模式。 |
目标库 | | 数据节点配置中写入端所选择的数据库,支持输入模式、选择模式。 |
目标表 | | 数据节点配置中写入端所选择的数据表,支持输入模式、选择模式。 |
字段映射规则 | | 字段映射关系旨在通过连线的方式指定目标字段内容的来源,支持选择同名映射、同行映射,通过编辑任务支持自定义字段映射规则。 |
配置资源组 | | 支持下拉选择可用的资源组。 |
操作 | 编辑任务 | 支持详细进行个性化配置,如配置数据源、字段映射规则等。 |
| 移除 | 删除该行映射关系。 |
批量配置字段映射规则 | | 勾选列表后,支持批量配置映射关系,可选择同名映射、同行映射。 |
批量配置资源组 | | 勾选列表后,支持批量配置可用的资源组。 |
批量移除 | | 勾选列表后,支持批量删除勾选的映射关系。 |
步骤四:通道设置
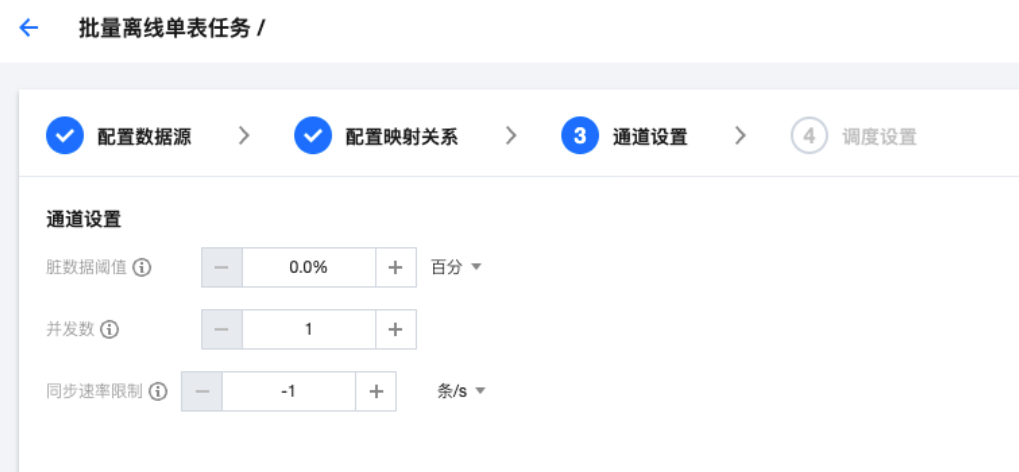
参数 | 说明 | |
脏数据阈值 | | 脏数据是指同步过程中写入失败的数据。脏数据阈值是指同步中可容忍的最大脏数据条数,一旦超过该阈值,任务将自动结束。默认阈值为0,即不容忍脏数据。 |
并发数 | | 实际执行时期望任务的最大并发数,实际执行时由于资源、数据源类型和任务优化结果等原因并发数可能小于等于此值。该值越大,预分配执行机资源越多。 |
同步速率限制 | | 按照流量或记录条数限制同步速率以保护数据来源端或者数据去向端的读写压力。该值为最大运行速率,默认-1表示不限制速率。 |
步骤五:调度设置
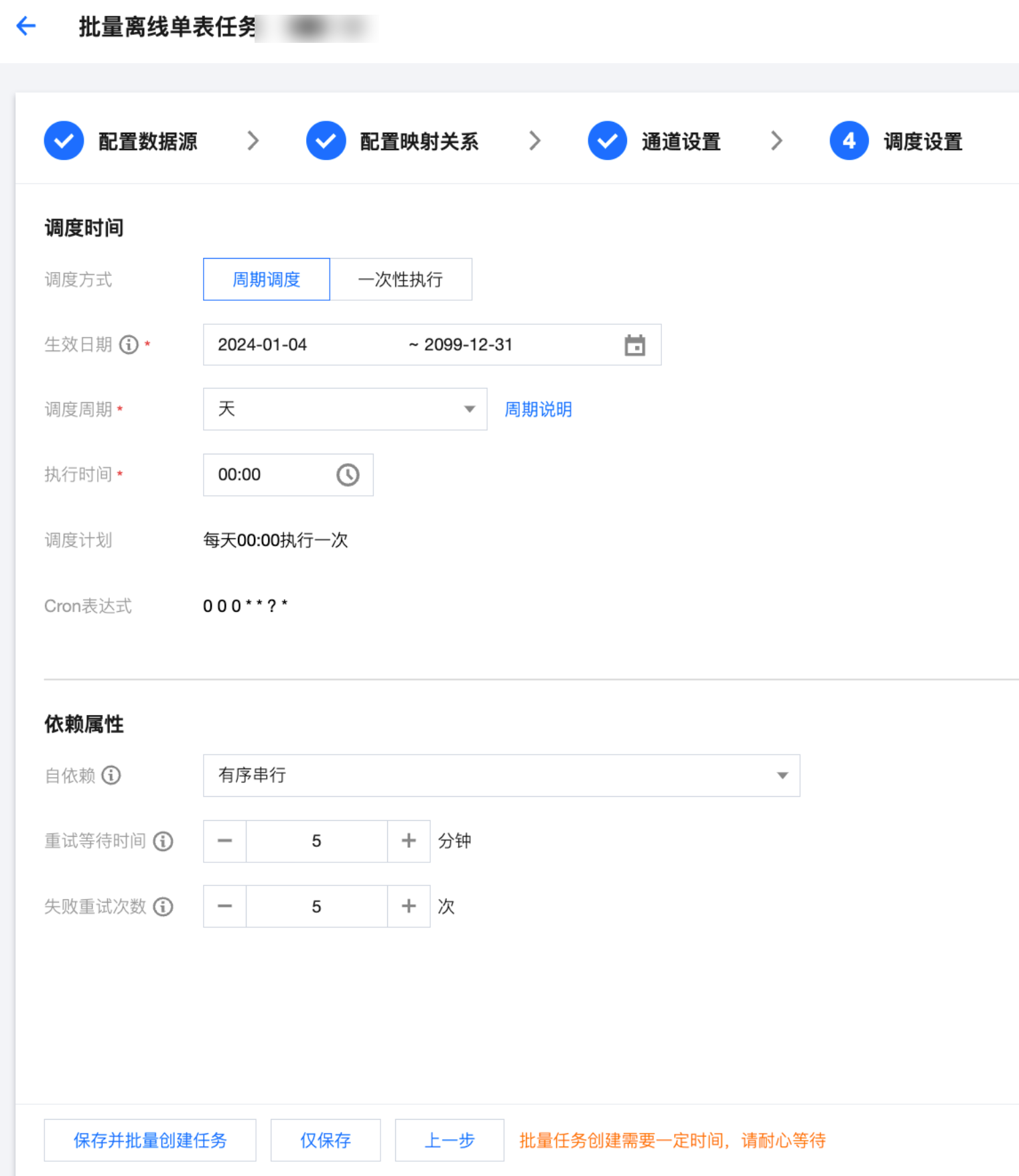
类别 | 参数 | 说明 |
调度时间 | 调度方式 | 周期调度:任务根据配置调度计划周期运行。 一次性执行:任务仅在指定时间运行一次。 |
| 生效日期 | 调度时间配置的有效时间段,系统会在该时间范围内按照时间配置自动调度,超过有效期将不会再自动调度。 |
| 调度周期 | 调度计划间隔步长单位,支持年、月、周、天、小时、分钟: 分钟:需指定具体执行开始时间及间隔,任务将从每小时执行分钟开始,按时间间隔周期运行。如执行时间为02:00 - 23:59,间隔为5分钟,则任务将从02:00开始每隔5分钟运行一次实例。 小时:需指定具体执行开始、结束时间及间隔。如执行时间为02:20~05:00,间隔为1小时,则任务将在02:20、03:20、04:20分别运行一次。 天:需指定每天具体执行时刻,任务每天仅在该时刻运行。 周:需执行每周固定运行的天数(支持多选)以及时间。任务仅在指定当天的该时刻运行。 月:指定每月固定运行的号数及时间。若选择月末,将根据不同的月份取最后一天运行。 年:指定每年固定运行日期及时间。 |
| 调度计划 | 根据配置结果生成的计划。 |
| Cron表达式 | 根据配置结果生成的表达式。 |
依赖属性 | 自依赖 | 自依赖是指同一任务中不同实例之间的依赖关系: 有序串行:当前实例依赖前一个周期实例的状态。 无序串行:当前实例和前一个周期实例没有依赖关系,如果一个任务同时存在多个实例,系统随机选取一个实例运行。同时只有一个实例是运行状态。 并行:前一个周期实例和后一个周期实例之间没有依赖关系,如果一个任务同时存在多个实例,多个实例会同时运行。 |
| 重试等待时间 | 实例运行失败后,每次重试运行的最大等待时间间隔。若超过此值实例仍未重试运行,实例将被置为失败。 |
| 失败重试次数 | 实例运行失败后,最大重试次数。若过超过此值,任务将被置为失败。 |
保存并批量创建 | | 生成批量创建任务本身,且开始创建单表同步任务。 |
仅保存 | | 生成批量创建任务本身,但不开始创建单表同步任务。 |
步骤六:查看生成的批量创建单表同步任务
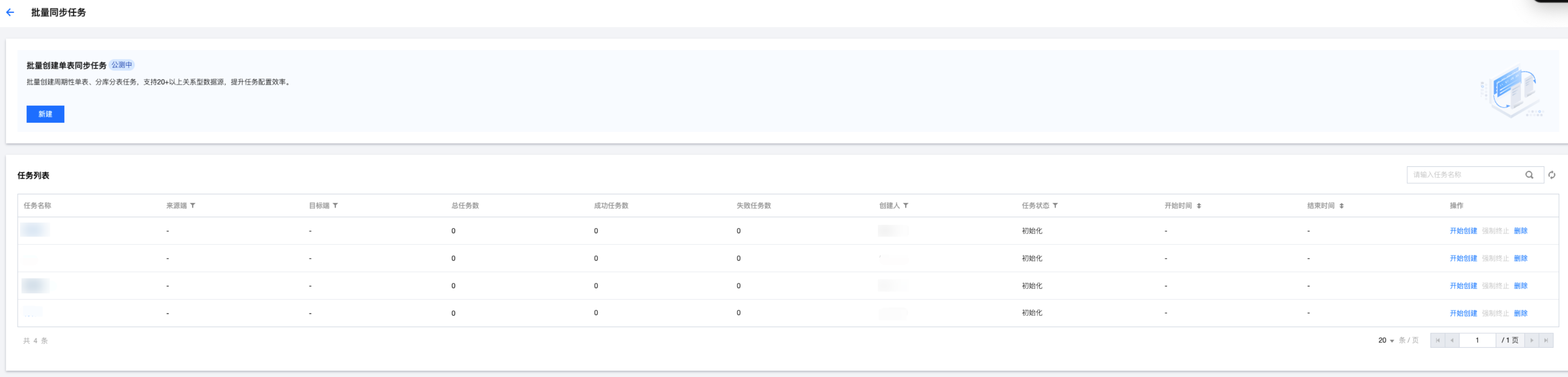
参数 | 说明 | |
任务名称 | | 用户自定义的任务名称。 |
来源端 | | 读取端所选择的数据源名称。 |
目标端 | | 写入端所选择的数据源名称。 |
总任务数 | | 批量任务中包含的单表任务总数。 |
成功任务数 | | 展示已成功创建的单表任务数(60秒刷新一次),点击后可查看具体的任务详情。  |
失败任务数 | | 展示已创建失败的单表任务数(60秒刷新一次),点击后可查看具体的任务详情,支持重试操作。  |
创建人 | | 批量任务的创建用户名称。 |
任务状态 | | 任务当前所处的状态,包括初始化、创建中、已完成、正在终止、已终止。 |
开始时间 | | 开始批量创建单表任务的时间。 |
结束时间 | | 批量创建单表任务完成时间。 |
操作 | 开始创建 | 开始批量创建单表任务。 |
| 强制终止 | 强制终止创建中的批量任务,终止后已创建的任务不会回退,未完成的任务不再创建,未完成的任务统计在失败任务数中。 |
| 删除 | 删除未开始或已完成的批量创建单表任务。 |
文档反馈