单个任务创建
Download
聚焦模式
字号
说明:
如果离线同步任务需要跟其他任务进行编排或配置任务依赖,建议在数据开发的编排空间创建离线同步任务,或在数据集成创建完任务后通过数据开发的导入任务(数据集成)功能将任务导入到编排空间。
在数据集成中已提交的任务无法导入到数据开发的编排空间中,仅支持对未提交的任务进行导入操作。
背景信息
单表同步采用固定字段同步的方式,仅将在任务配置中指定映射关系的来源字段数据同步至目标端。单表任务支持画布、表单、脚本三种配置模式,覆盖 MySQL、Hive、DLC、Doris 等数据源。
条件与限制
1. 已配置好来源及目标端的数据源以备后续任务使用。
2. 已购买数据集成资源组。
3. 已完成数据集成资源组与数据源的网络连通。
4. 已完成数据源环境准备。您可以基于您需要进行的同步配置,在同步任务执行前,授予数据源配置的账号在数据库进行相应操作的权限。
5. 若数据源配置的数据库账号不具备读写权限将导致任务运行失败,请根据实际读写场景配置具备相应权限的账号。
操作步骤
步骤一:新建离线同步任务并选择配置模式
1. 在数据集成页面下,单击离线开发 > 文件夹 >工作流 > 数据集成 > 新建任务 > 离线同步即可进入同步任务列表。
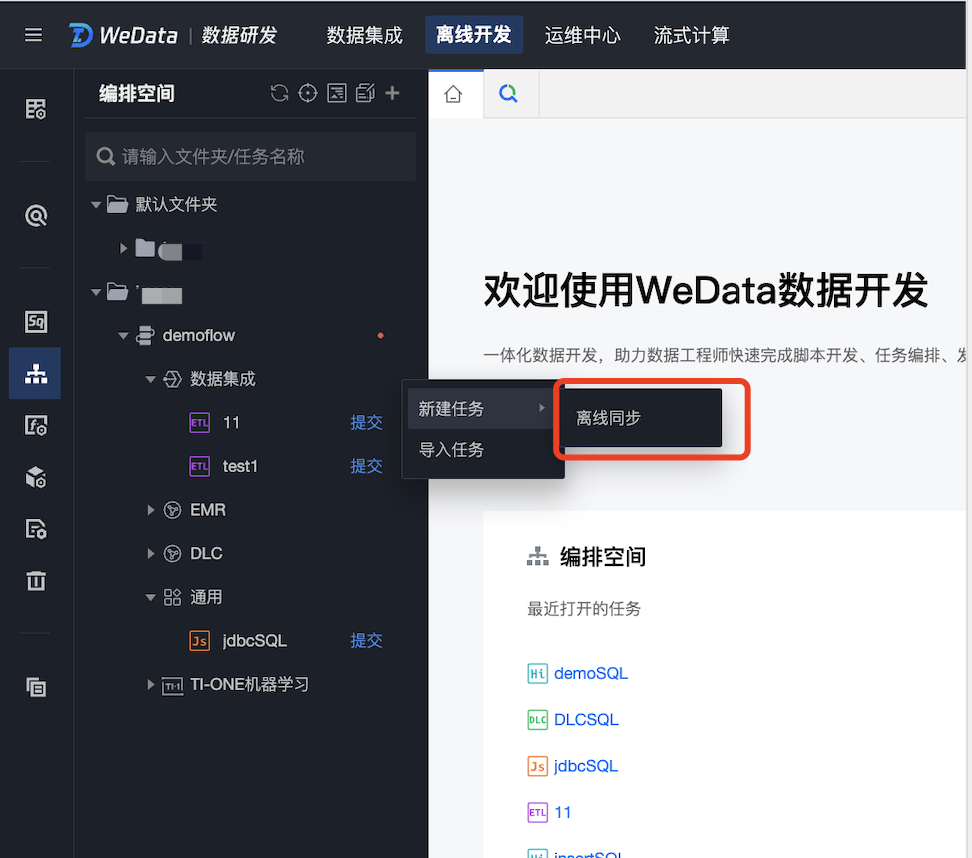
2. 在弹窗中配置任务基本信息,单击确定后,即可进入任务配置页面。
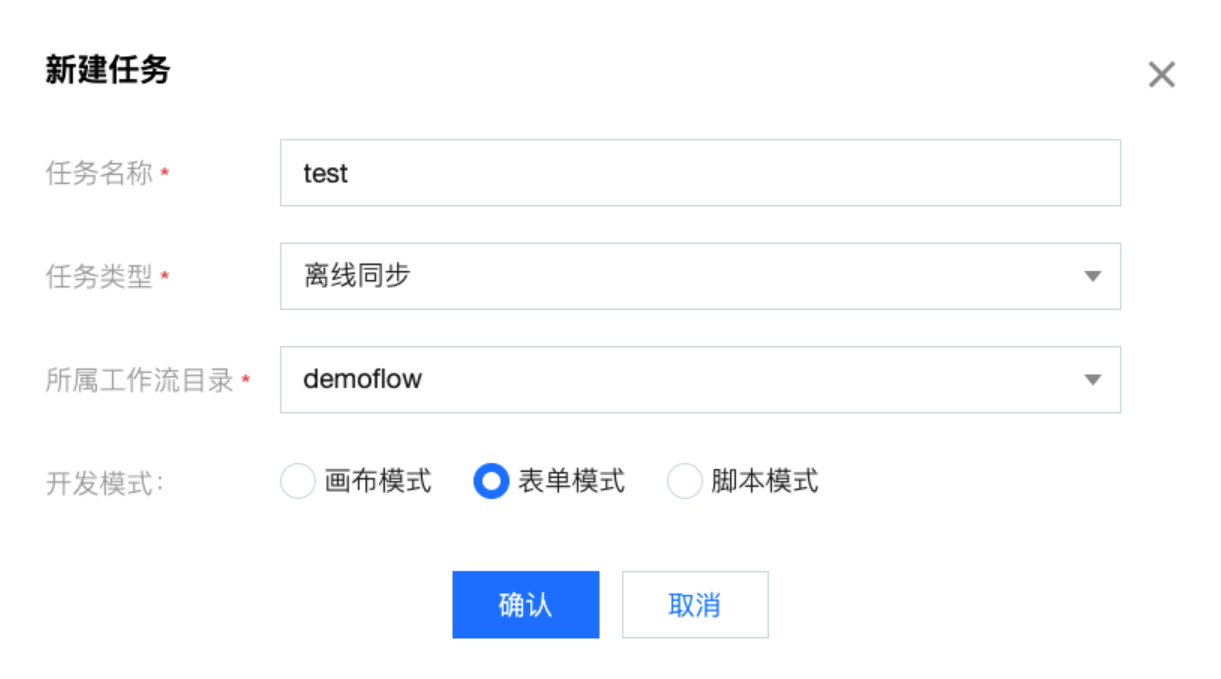
参数 | 说明 |
任务名称 | 必填项。 |
任务类型 | 选中离线同步。 |
任务模式 | 表单模式:仅提供读取、写入节点,适用于单表至单表固定字段同步。适用于 ODS 层无需数据清洗环节的数据同步。 画布模式:提供读取、写入、转换三类节点。适用于包含清洗环节、多对多数据链路。 脚本模式:支持初始化的脚本模式配置页面,支持用户选择不同的数据来源、数据目标,展示对应的脚本模板: 用户需要先选择数据来源与数据目标,未选择的状态下不允许编辑。 选择后,展示对应的脚本模块。 在脚本中,用户可以手动编写数据源、连接信息等参数。 支持在脚本中写 sql 语句,将 querysql 写到 connection 中。 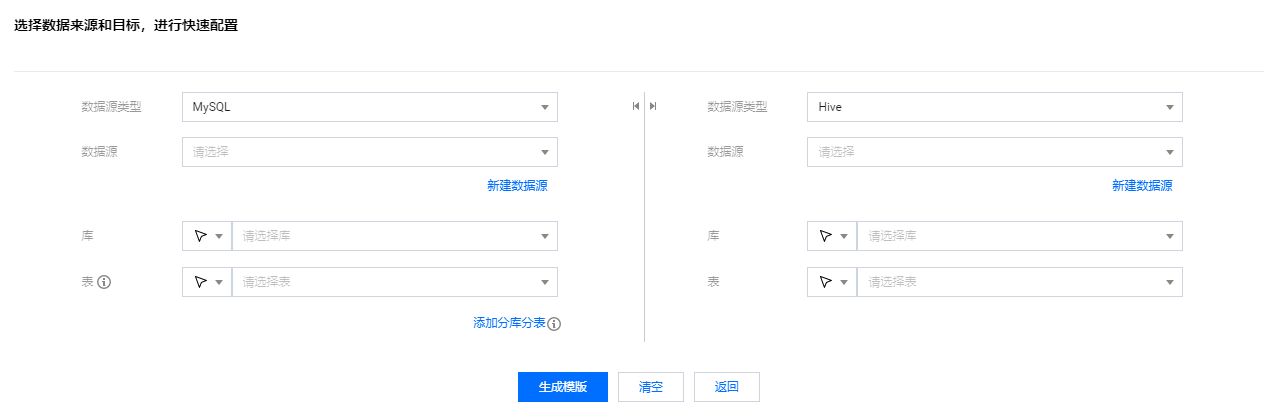 |
所属工作流 | 选中已存在的某个工作流。 |
说明:
脚本模式目前支持以下数据源:
读取:MySQL、TDSQL-C MySQL、TDSQL MySQL、TDSQL PostgreSQL、PostgreSQL、TCHouse-P、SQL Server、Oracle、IBM DB2、达梦DM、SAP HANA、SyBase、Doris、Hive、HBase、Clickhouse、DLC、Kudu、HDFS、Greenplum、GaussDB、Impala、Gbase、TBase、Mongodb、COS、FTP、SFTP、REST API、Elasticsearch、Kafka、Iceberg、StarRocks、Graph Database。
写入:MySQL、TDSQL-C MySQL、TDSQL MySQL、TDSQL PostgreSQL、PostgreSQL、TCHouse-P、SQL Server、Oracle、IBM DB2、达梦DM、SAP HANA、Hive、HBase、Clickhouse、DLC、Kudu、HDFS、Greenplum、GaussDB、Gbase、TBase、Impala、COS、FTP、SFTP、Elasticsearch、Redis、Mongodb、Kafka、Iceberg、Doris、StarRocks、Graph Database。
步骤二:数据节点配置
配置读取节点
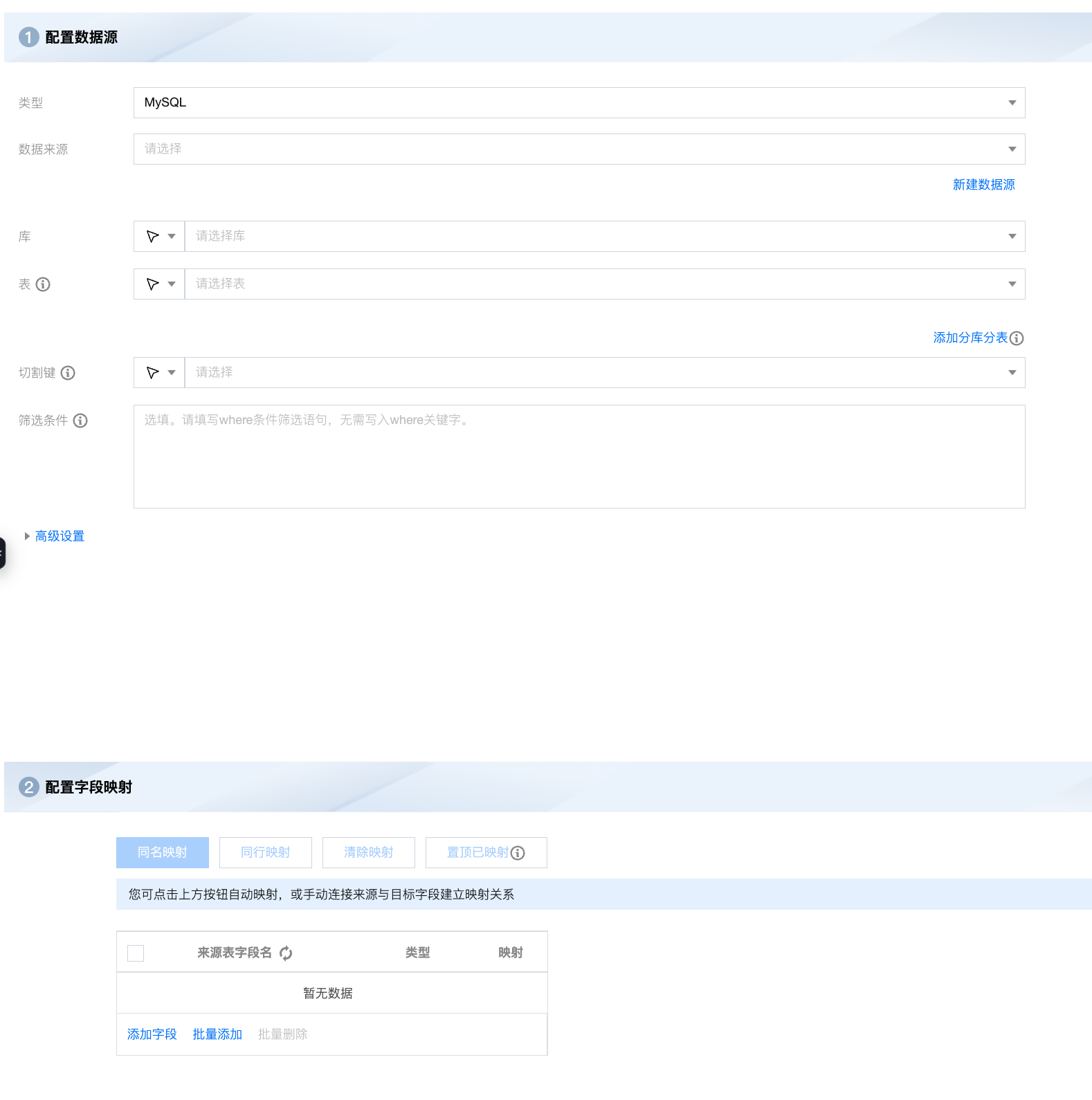
读取节点配置包括基本信息、数据来源、数据字段三部分。
基本信息
节点名称不可为空,且单个任务内不可存在同名的数据节点。
数据来源
配置需要读取的库表对象以及同步方式等信息。
数据字段
根据配置的数据表对象,系统支持默认拉取字段元数据信息以及手动配置字段两种方式。
默认拉取:针对 MySQL、Hive、PostgreSQL 等类型,系统已支持根据其库表信息自动拉取元数据字段及类型,无需手动编辑。
手动配置:文件(例如 HDFS、COS)以及列式存储数据源(例如 HBase、Mongo)等数据源系统不支持自动拉取元数据,可单击添加字段/批量添加手动添加字段名称及类型。读取节点还额外支持配置时间参数以及常量。
批量添加
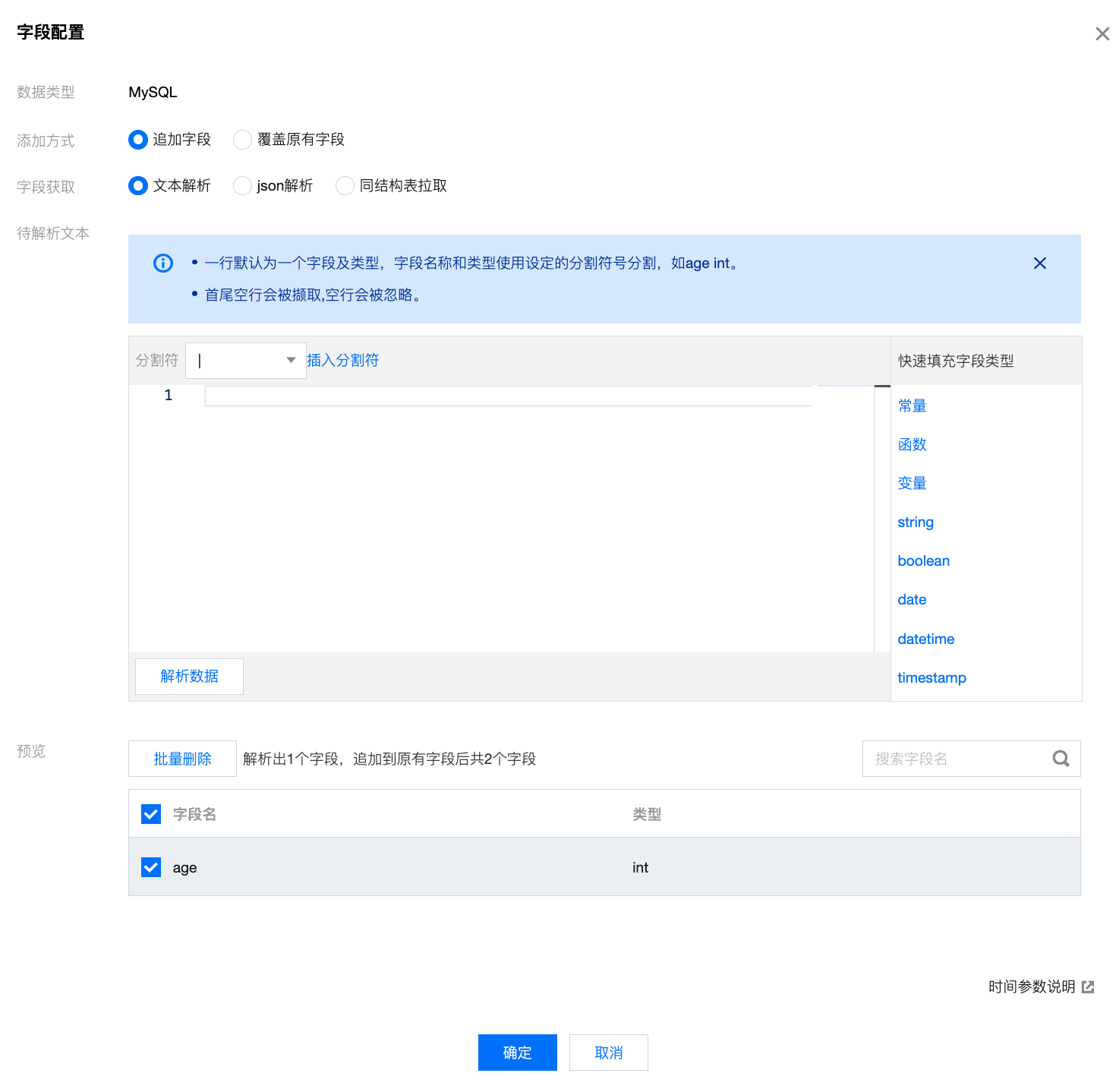
参数 | 描述 | |
数据类型 | | 当前节点的数据源类型。 |
添加方式 | | 追加字段:在表的原有字段后追加解析的新字段。 覆盖原有字段:解析的新字段覆盖当前来源表的原有字段信息。 |
字段获取 | | 文本解析:根据文本内容解析。 json 解析:输入 json 内容,根据 key/value 值快速进行内容解析,如 {"age":10,"name":"demo"}。 同结构表拉取:指定一个数据源的表对象,解析该表的字段。 |
待解析文本 | 分割符 | 用于分割字段名称和类型,支持 tab、|、空格,例如"age|int"。 |
| 快速填充字段类型 | 常用字段类型,支持常量、函数、变量、string、boolean、date、datetime、timestamp、time、double、float、tinyint、smallint、tinyint unsigned、int、mediumint、smallint unsigned、bigint、int unsigned、bigint unsigned、double precision、tinyint(1)、char、varchar、text、varbinary、blob。 |
| 解析数据 | 解析输入内容。 |
预览 | 批量删除 | 勾选预览列表后,批量删除解析结果。 |
| 字段名 | 字段的名称。 |
| 类型 | 字段的类型。 |
说明
时间参数字段:仅离线任务的读取节点支持配置时间参数字段,常用将实例运行时间值写入表的一级或多级分区。
常量字段:仅读取节点支持配置常量字段。常量字段可在来源与目标表字段个数不一致的情况下固定将某个常量值写入目标表。
配置转换节点
转换节点配置包括基本信息、转换规则、数据字段三部分。其中,转换转换节点必须作为读取节点下游,在创建与读取节点连线后系统将自动获取上游节点内字段信息,同时根据转换规则完成数据转换。
基本信息
配置节点名称信息。节点名称不可为空,且单个任务内不可存在同名的数据节点。
转换规则
配置字段或数据级转换规则,其中字段信息继承自上游节点,在与上游节点连线后系统将自动获取上游节点内字段信息。
数据字段
默认拉取上游节点全部数据字段用于后续写入节点映射。
配置写入节点
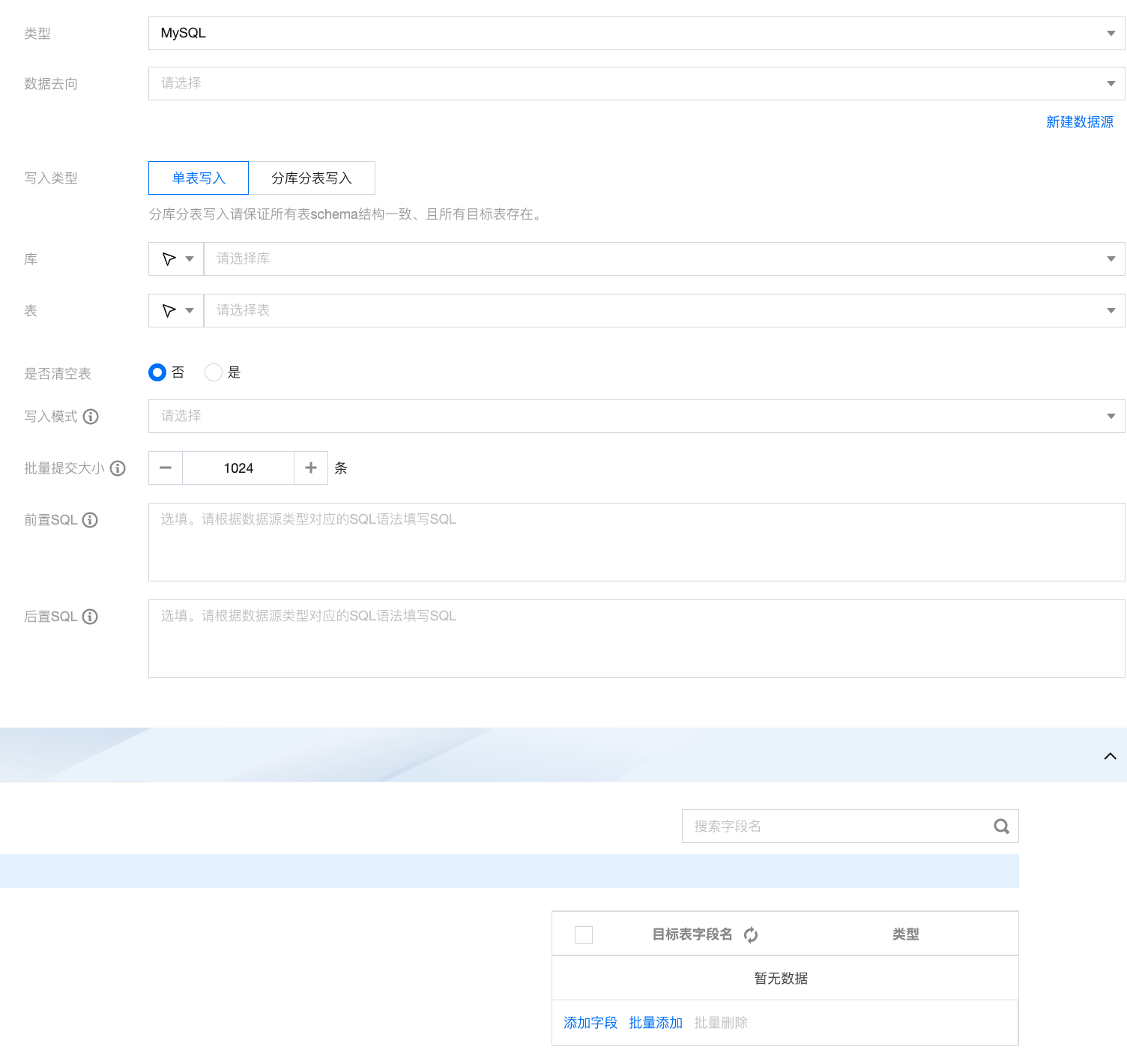
写入节点配置包括基本信息、数据来源、数据字段、字段映射四部分。写入节点将根据连线关系,将上游数据内容写入目标对象内。
基本信息
节点名称不可为空,且单个任务内不可存在同名的数据节点。
数据来源
配置需要读取的库表对象以及同步方式等信息。
数据字段
根据配置的数据表对象,系统支持默认拉取字段元数据信息以及手动配置字段两种方式。
默认拉取:针对 MySQL、Hive、PostgreSQL 等类型,系统已支持根据其库表信息自动拉取元数据字段及类型,无需手动编辑。
手动配置:文件(例如 HDFS、COS)以及列式存储数据源(例如 HBase、Mongo)等数据源系统不支持自动拉取元数据,可单击字段配置手动添加字段名称及类型。
字段映射
写入节点相对于读取节点需额外配置字段映射关系。字段映射关系旨在通过连线的方式指定目标字段内容的来源,支持同名映射、同行映射、以及手动连线三种方式配置来源与目标节点间关系。
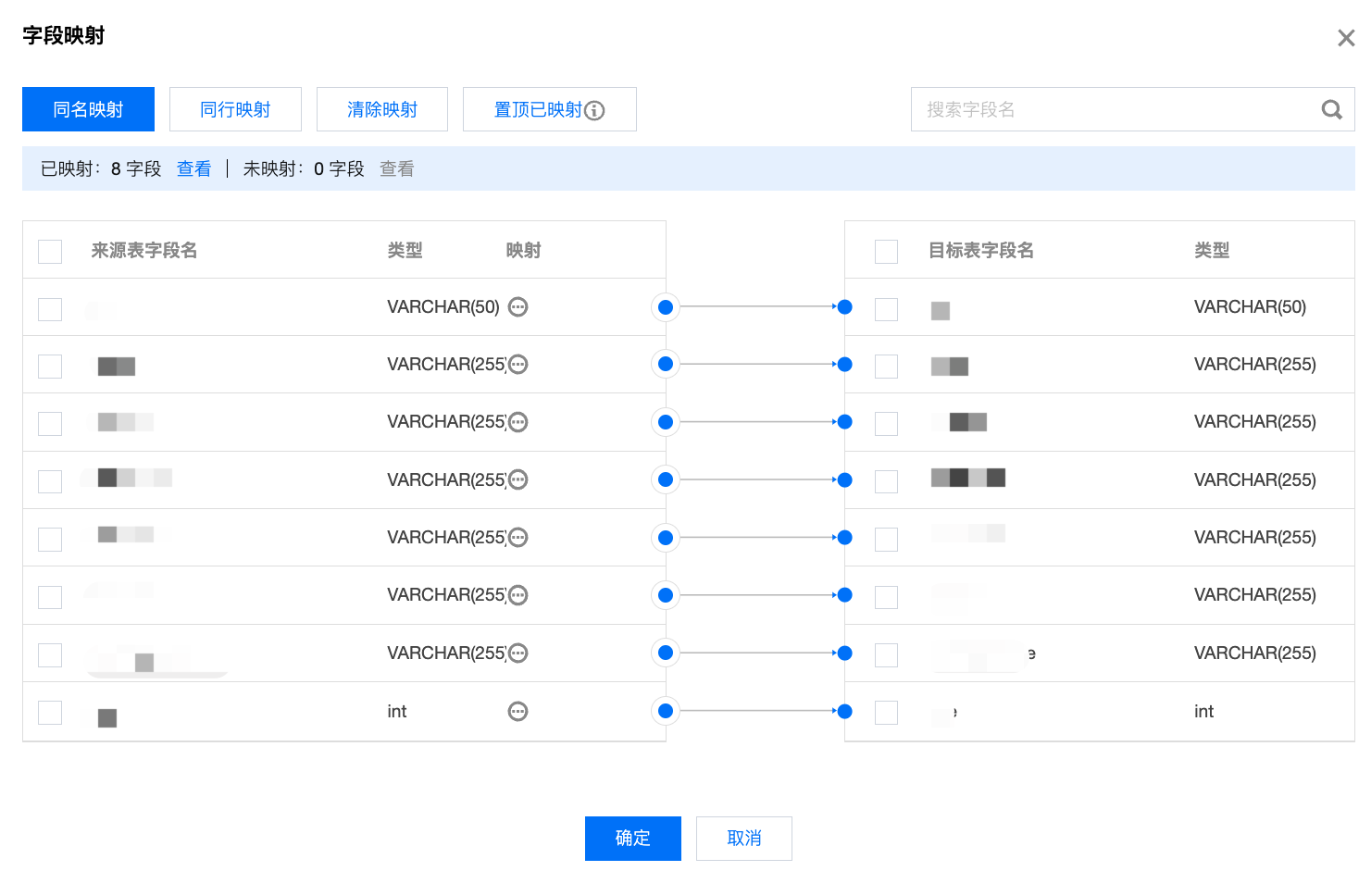
参数 | 描述 | |
同名映射 | | 来源表字段与字段名称一致的目标表字段间建立映射关系。 |
同行映射 | | 来源表字段与所在行数一致的目标表字段间建立映射关系。 |
清除映射 | | 清除已建立的来源表字段与目标表字段之间的映射关系。 |
置顶已映射 | | 置顶并格式化显示已建立映射关系字段;此格式化不影响表实际存储字段顺序,仅用于前端优化展示。 |
手动连线映射 | | 支持通过连线手动建立来源表字段与目标表字段间映射关系。 |
来源表 | 来源表字段名 | 来源表字段的名称。 |
| 类型 | 来源表字段的类型。 |
| 映射 | 快速创建映射。  |
目标表 | 目标表字段名 | 目标表字段的名称。 |
| 类型 | 目标表字段的类型。 |
说明
配置字段映射的前提为当前写入节点有已连线的来源(读取节点或转换节点)。
未配置映射关系的目标字段内容将为空或保持不变。
若来源字段类型与目标字段类型间无法转换,可能会导致任务失败。
步骤三:离线任务属性配置
离线任务属性配置包括任务属性、任务调度、和资源配置三部分:
任务属性
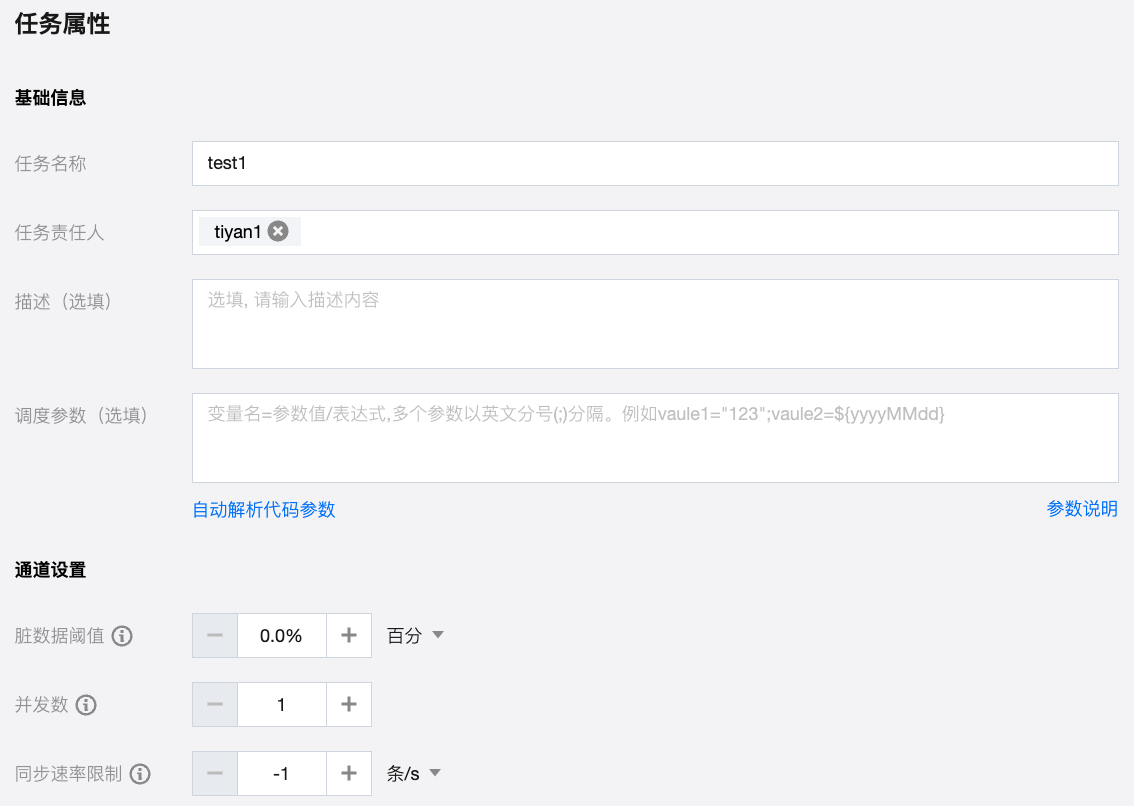
设置任务基本属性、使用资源以及数据链路通道信息。
类别 | 参数 | 说明 |
基本属性 | 任务名称/类型 | 展示当前任务名称及类型基本信息。 |
| 责任人 | 对此任务负责的一个或多个空间成员名称,默认为任务创建者。 |
| 描述 | 展示当前任务备注信息。 |
| 调度参数 | 调度参数是任务调度时使用的参数,会根据任务调度的业务时间及调度参数的取值格式自动替换取值,实现在任务调度时间内参数的动态取值 |
通道设置 | 脏数据阈值 | 脏数据是指同步过程中写入失败的数据脏数据阈值是指同步中可容忍的最大脏数据条或字节数,一旦超过该阈值,任务将自动结束。默认阈值为0,即不容忍脏数据。 |
| 并发数 | 实际执行时期望任务的最大并发数,实际执行时由于资源、数据源类型和任务优化结果等原因并发数可能小于等于此值。该值越大,预分配执行机资源越多。 注意: 并发数>1时,如源端数据源支持设置切割键,则切割键为必填项,否则设置的并发数不生效。 |
| 同步速率限制 | 按照流量或记录条数限制同步速率以保护数据来源端或者数据去向端的读写压力。该值为最大运行速率,默认-1表示不限制速率。 |
调度设置
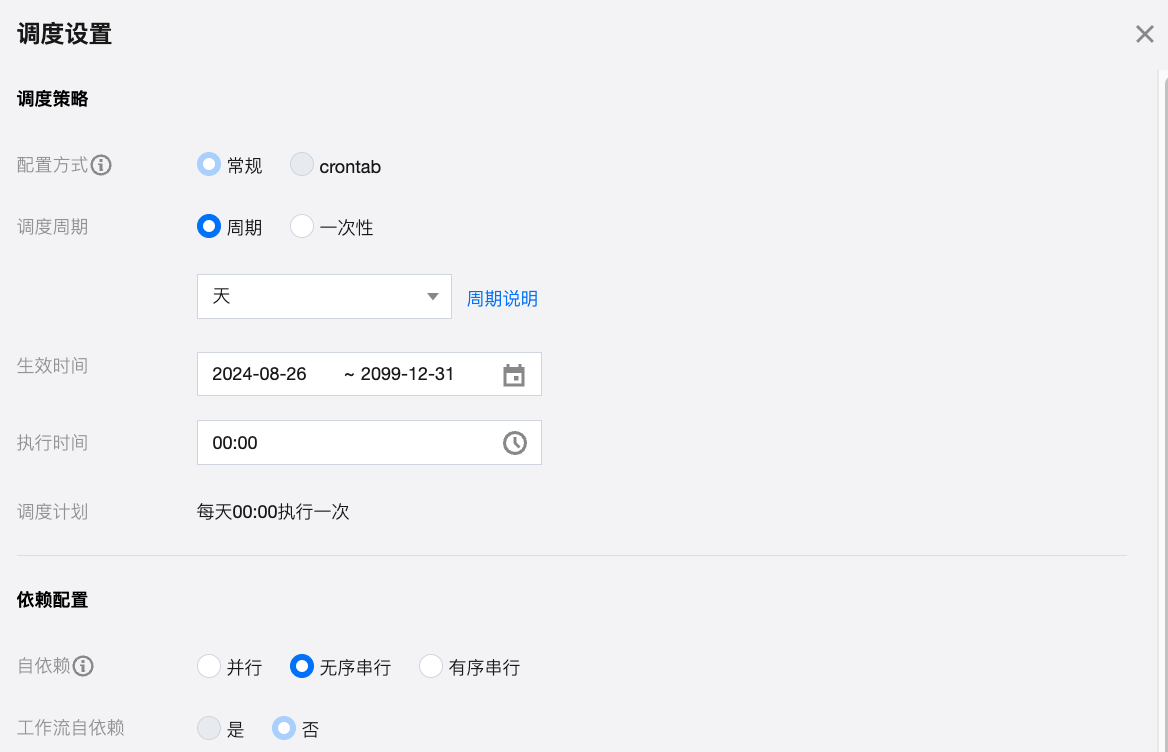
功能 | 描述 |
调度周期 | 任务调度的执行周期单位,支持分钟、小时、天、周、月、年和一次性。 |
生效时间 | 调度时间配置的有效时间段,系统会在该时间范围内按照时间配置自动调度,超过有效期将不会再自动调度。 |
执行时间 | 用户可自行设定该任务每次执行间隔的时长以及任务开始执行的具体时间。 如周期间隔为10分钟,则调度任务将在2022年3月27日到2022年4月27日中每天的00:00到23:59分之间每隔10分钟运行一次。 |
调度计划 | 会根据周期时间的设置自动生成。 |
自依赖 | 为当前工作流中的计算任务统一配置任务自依赖属性。 |
工作流自依赖 | 开启后表示当前工作流中的计算任务依赖当前工作流上个周期的所有计算任务。工作流自依赖功能仅在当前工作流中的任务是同一调度周期,并且是天周期的时候生效。 |
资源配置

任务提交前,需要选择集成资源组作为任务的运行资源。
步骤四:任务测试运行与提交
离线同步任务在配置完成后可进行在线测试运行或提交到生产调度环境中,目前可在任务配置页面支持保存、提交、测试运行、调试停止、锁定/解锁以及前往运维操作。
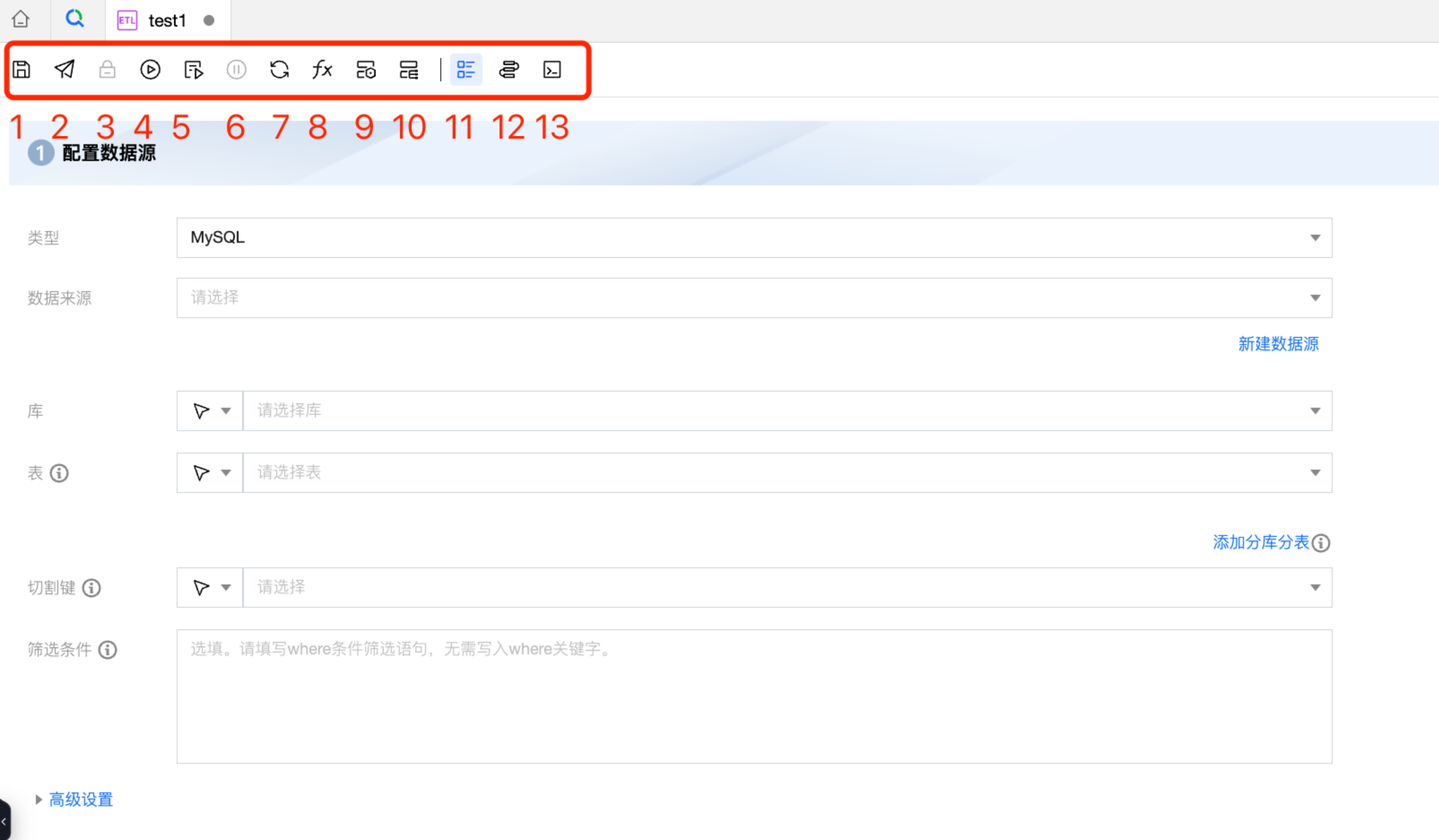
序号 | 参数 | 描述 |
1 | 保存 | 单击图标,可保存当前任务节点。 |
2 | 提交 | 单击图标,可提交任务节点到调度系统(节点基础内容、调度配置属性),并生成一个新的版本记录。 功能限制:任务的数据源和调度条件设置完整以后才可以正常提交。 |
3 | 锁定/解锁 | 单击图标,可锁定/释放当前文件的编辑,若任务已被他人锁定,则无法编辑。 |
4 | 运行 | 单击图标,可调试运行当前任务节点。 |
5 | 高级运行 | 单击图标,可运行当前带有变量的任务节点。系统会自动弹出代码中使用的时间参数和自定义参数。 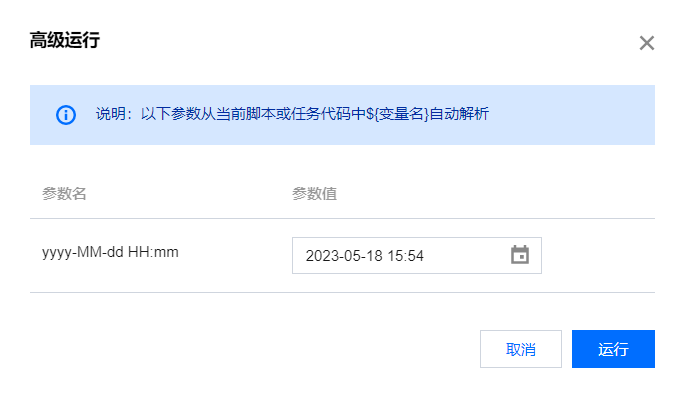 |
6 | 停止运行 | 单击图标,可停止调试运行当前任务节点。 |
7 | 刷新 | 单击图标,刷新当前任务节点的内容。 |
8 | 项目参数 | 单击图标,展示该项目的参数设置,如需修改请前往项目管理。 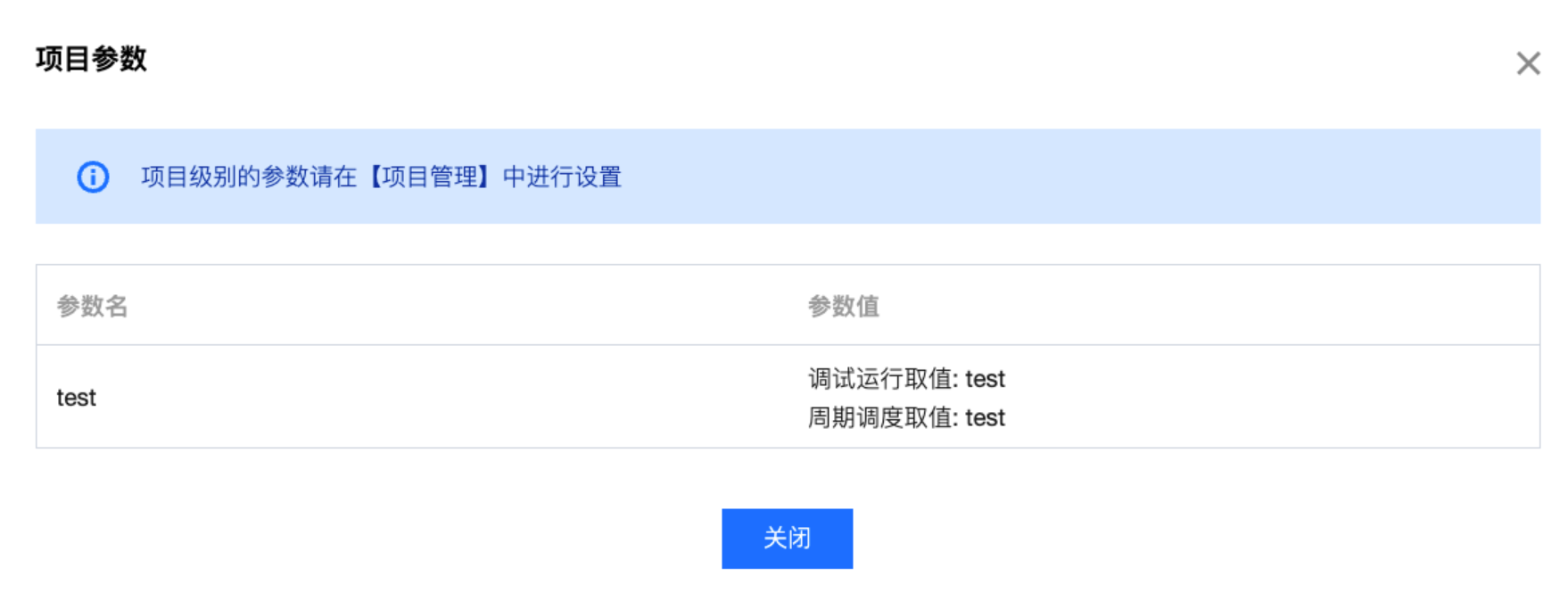 |
9 | 任务运维 | 单击图标,前往任务运维页面。 |
10 | 实例运维 | 单击图标,前往实例运维页面。 |
11 | 表单转换 | 单击图标,将任务配置转换为表单模式。 |
12 | 画布转换 | 单击图标,将任务配置转换为画布模式。 |
13 | 脚本转换 | 单击图标,将任务配置转换为脚本模式,转换后不支持转回表单/画布模式 |
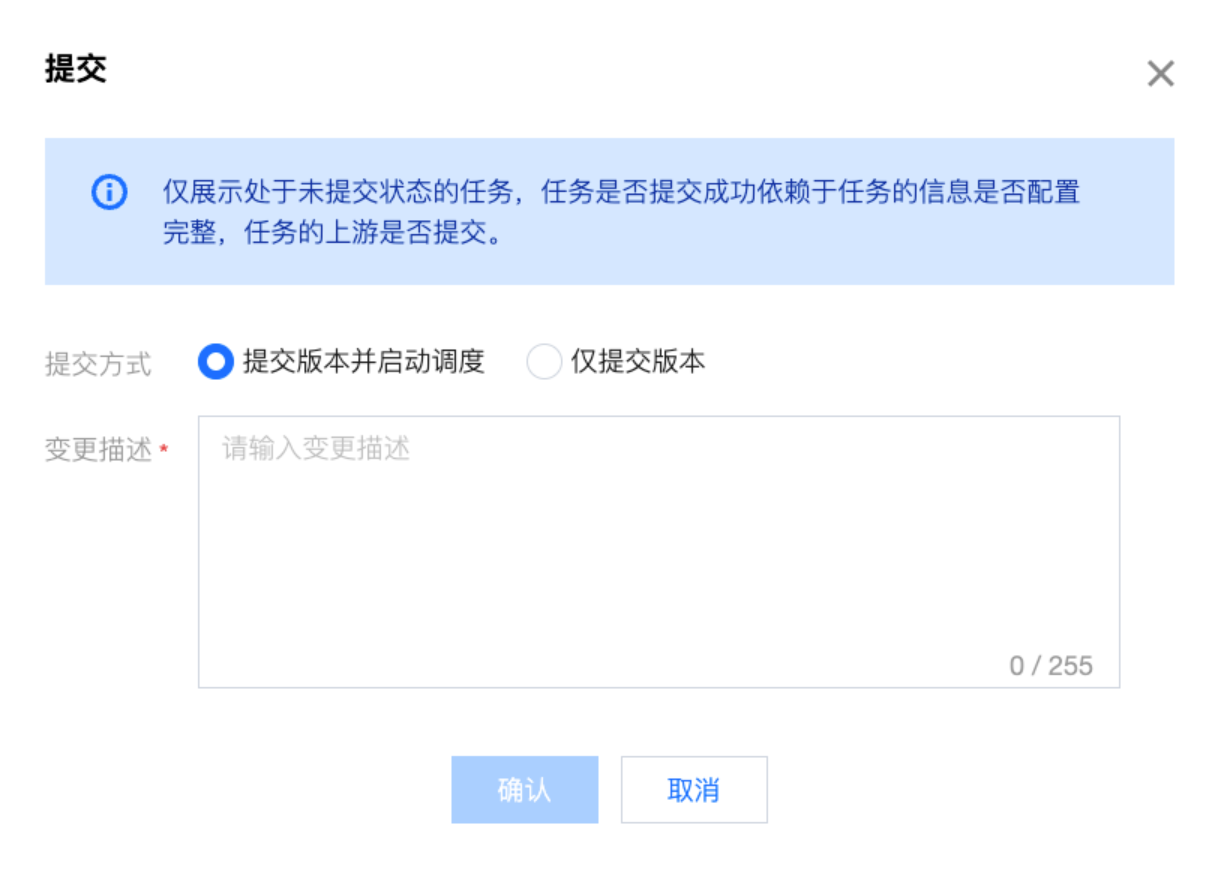
任务提交
数据工作流每次编辑后提交运维,相应的就会生成一个工作流版本。确认无误后,提交方式选择提交版本并启动调度,并且在变更描述栏填写任意内容,即可将 离线同步任务 发布到运维阶段。
文档反馈