实时同步常见问题
Download
聚焦模式
字号
MySQL 类
1. MySql serverid 冲突
错误信息:
com.github.shyiko.mysql.binlog.network.ServerException: A slave with the same server_uuid/server_id as this slave has connected to the master。
解决办法:目前已经优化增加随机生成 serverid,之前的任务中如果在 mysql 高级参数中显示指定了 server-id 建议删除,因为可能多个任务使用了相同的数据源,并且 server-id 设置的相同导致冲突。
2. 报 binlog 文件找不到错误信息:
错误信息:
Caused by: org.apache.kafka.connect.errors.ConnectException: The connector is trying to read binlog starting at GTIDs xxx and binlog file 'binlog.xxx', pos=xxx, skipping 4 events plus 1 rows, but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed。
错误原因:
作业正在读取的 binlog 文件在 MySQL 服务器已经被清理时,会产生报错。导致 Binlog 清理的原因较多,可能是 Binlog 保留时间设置的过短;或者作业处理的速度追不上 Binlog 产生的速度,超过了 MySQL Binlog 文件的最大保留时间,MySQL 服务器上的 Binlog 文件被清理,导致正在读的 Binlog 位点变得无效。
解决办法:如果作业处理速度无法追上 Binlog 产生速度,可以考虑增加 Binlog 的保留时间也可以优化作业减轻反压来加速 source 消费。如果作业状态没有异常,可能是数据库发生了其他操作导致 Binlog 被清理,从而无法访问,需要结合 MySQL 数据库侧的信息来确定Binlog被清理的原因。
3. MySQL 报连接被重置
错误信息:
EventDataDeserializationException: Failed to deserialize data of EventHeaderV4 .... Caused by: java.net.SocketException: Connection reset。
错误原因:
1. 网络问题。
2. 作业存在反压,导致 source 无法读取数据,binlog client 空闲,如果 binlog 连接在超时后仍然空闲 mysql 服务器会断开空闲的连接。
解决方法:
1. 如果是网络问题,可以调大 mysql 网络参数 set global slave_net_timeout = 120; (默认30s) set global thread_pool_idle_timeout = 120。
2. 如果是作业反压导致,可以通过调节作业减轻反压,比如增加并行度,提升写入速度,提升 taskmanager 内存减少 gc。
4. Mysql2dlc 任务 JobManager Oom
错误信息:
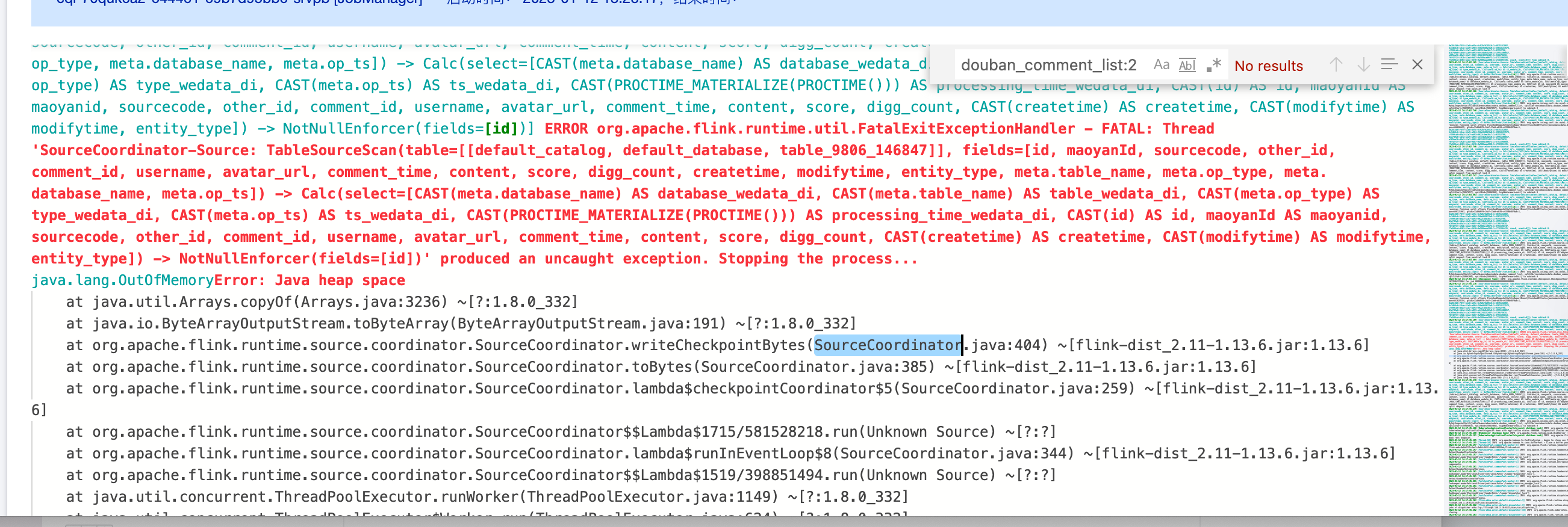
错误原因和解决方法:
1. 用户数据量比较大,可以调大 jobmanager CU 数,使用 mysql 高级参数 scan.incremental.snapshot.chunk.size 调大 chunk size 大小,默认是8096。
2. 用户数据量不大,但是主键最大值-最小值的差值却很大,导致使用均分 chunk 的策略时划分很多 chunk,修改分布因子,让用户数据走非均匀的数据切分逻辑,split-key.even-distribution.factor.upper-bound=5.0d,默认值分布因子已经修改为10.0d。
5. 用户的 binlog 数据格式不对,导致 debezium 解析异常
错误信息:
ERROR io.debezium.connector.mysql.MySqlStreamingChangeEventSource [] - Error during binlog processing. Last offset stored = null, binlog reader near position = mysql-bin.000044/211839464.2023-02-20 21:37:28.480 [blc-172.17.48.3:3306] ERROR io.debezium.pipeline.ErrorHandler [] - Producer failureio.debezium.DebeziumException: Error processing binlog event.
解决方法:
修改 binlog_row_image=full 后需要重启数据库。
6. 是否支持 gh-ost?
支持,不会迁移 Online DDL 变更产生的临时表数据,只迁移源库使用 gh-ost 执行的原始 DDL 数据,同时您可以使用默认的或者自行配置 gh-ost 影子表和无用表的正则表达式。
DLC 类
1. 同步增量数据( changlog 数据)到 dlc 时报错
错误信息:

问题原因:
dlc 的表是 v1表不支持 changlog 数据。
解决方法:
1. 修改 dlc 表为 v2表和开启 upsert 支持。
2. 修改表支持 upsert:ALTER TABLE tblname SET TBLPROPERTIES ('write.upsert.enabled'='true')。
3. 修改表为 v2表:ALTER TABLE tblname SET TBLPROPERTIES ('format-version'='2')。
显示表设置的属性是否成功 show tblproperties tblname。
2. Cannot write incompatible dataset to table with schema
错误详情:
Caused by: java.lang.IllegalArgumentException: Cannot write incompatible dataset to table with schema:* mobile should be required, but is optionalat org.apache.iceberg.types.TypeUtil.checkSchemaCompatibility(TypeUtil.java:364)at org.apache.iceberg.types.TypeUtil.validateWriteSchema(TypeUtil.java:323)
错误原因:
用户建 dlc 表时,字段设置了 NOT NULL 约束。
解决办法:
建表时不要设置 not null 约束。
3. 同步 mysql2dlc,报数组越界
问题详情:
java.lang.ArrayIndexOutOfBoundsException: 1at org.apache.flink.table.data.binary.BinarySegmentUtils.getLongMultiSegments(BinarySegmentUtils.java:736) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.binary.BinarySegmentUtils.getLong(BinarySegmentUtils.java:726) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.binary.BinarySegmentUtils.readTimestampData(BinarySegmentUtils.java:1022) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.binary.BinaryRowData.getTimestamp(BinaryRowData.java:356) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.RowData.lambda$createFieldGetter$39385f9c$1(RowData.java:260) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
错误原因:
时间字段做主键导致的问题。
解决方法:
1. 不用时间字段做主键。
2. 用户还是需要时间字段保证唯一性,建议用户在dlc新增一个冗余字符串字段,将上游的时间字段使用函数转换后映射到冗余字段。
4. DLC 任务报不是一个 iceberg 表
错误信息:

错误原因:
1. 可以让用户在 dlc 执行语句查看表到底是什么类型。
2. 语句:desc formatted 表名。
3. 可以看表类型。
解决办法:
选择正确的引擎建 iceberg 类型的表。
5. flink sql 字段顺序跟 dlc 目标表字段不一致导致报错
解决方法:
不修改任务表字段顺序。
Doris类
1. Doris 规格如何选型及调优?
2. 导入任务过多,新导入任务提交报错 “current running txns on db xxx is xx, larger than limit xx ”?
调整 fe 参数 : max_running_txn_num_per_db,默认100,可适当调大,建议控制在500以内。
3. 导入频率太快出现 err=[E-235] 错误?
参数调优建议:可通过适当调大 max_tablet_version_num 参数暂时解决,此参数默认200,建议控制在2000以内。
业务调优建议:降低导入频率才能根本解决这个问题。
4. 导入文件过大,被参数限制。报错 “The size of this batch exceed the max size ”?
调整 be 参数 : streaming_load_max_mb,建议超过需要导入的文件大小。
5. 导入数据报错:“[-238]”?
原因:-238 错误通常出现在同一批导入数据量过大的情况,从而导致某一个 tablet 的 Segment 文件过多(由 )。
参数调优建议:可适当调大BE参数max_segment_num_per_rowset ,此参数默认值200,可按倍数调大(如400、800),建议控制在2000以内;
业务调优建议:建议减少一批次导入的数据量。
6. 导入失败,报错:“too many filtered rows xxx, "ErrorURL":"或 Insert has filtered data in strict mode, tracking url=xxxx.”?
原因:表的 schema、分区等与导入的数据不匹配。可在 TCHouse-P Studio 或客户端执行 doris 命令查看具体原因:show load warnings on `<tracking url>`,<tracking url> 即为报错信息中返回的 error url。
文档反馈