PySpark
Download
聚焦模式
字号
注意:
1. 当前用户在 EMR 集群有权限。
2. 已在 Hive 中创建对应的数据库和表,如示例中的:wedata_demo_db。
3. PySpark 系统自动使用 cluster 模式提交任务。
代码示例
from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, IntegerType, StringTypespark = SparkSession.builder.appName("WeDataApp").getOrCreate()schema = StructType([StructField("user_id", IntegerType(), True),StructField("user_name", StringType(), True),StructField("age", IntegerType(), True)])data = [(1, "Alice", 25), (2, "Bob", 30)]df = spark.createDataFrame(data, schema=schema)df.show()
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("WeDataApp").enableHiveSupport().getOrCreate()df = spark.sql("SELECT * FROM WeData_demo_db.user_demo")count = df.count()print("The number of rows in the dataframe is:", count)
参数说明
参数 | 说明 |
Python 版本 | 支持 Python2、Python3。 |
在 PySpark 任务中使用调度资源组的 Python 环境
在调度资源组中安装 Python 库
1. 进入项目管理 > 执行资源组 > 标准调度资源组界面,单击资源详情,进入资源运维界面。
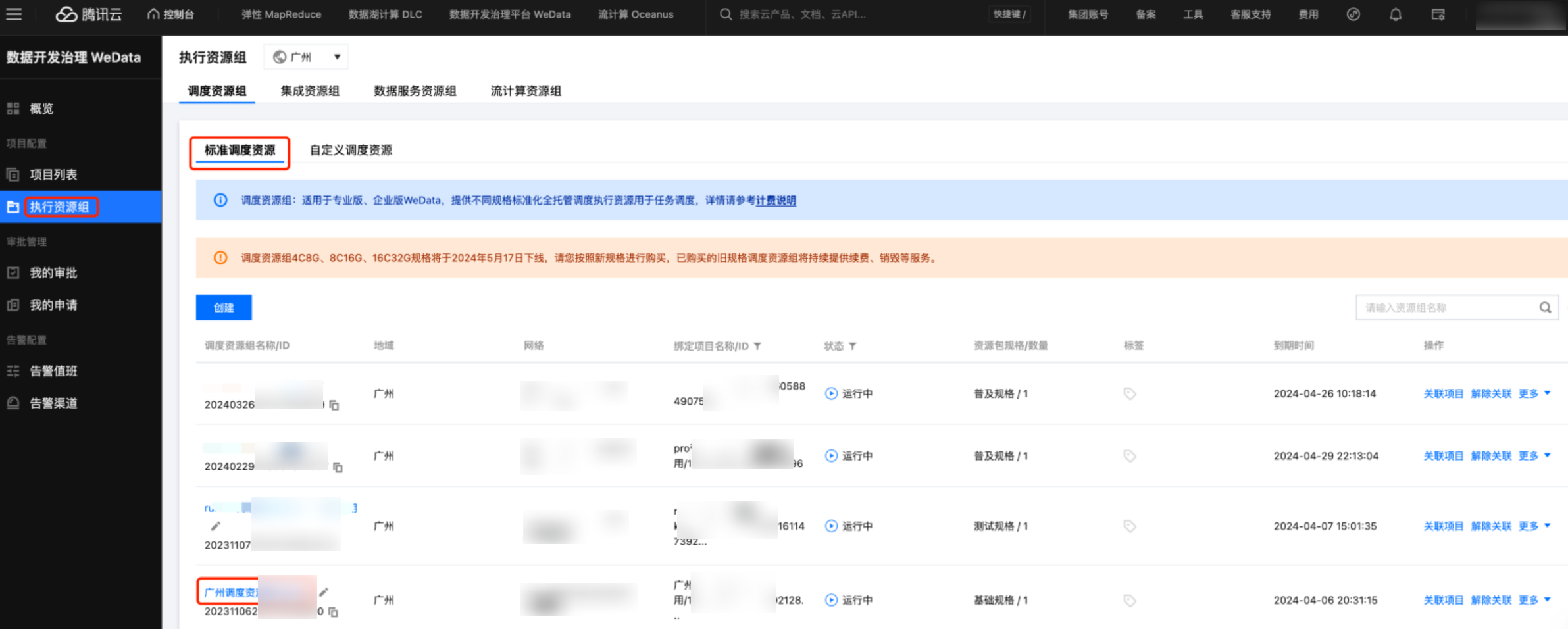
2. 在资源运维界面,单击 Python 包安装,可以安装内置的 Python 库,推荐安装 Python3 的版本。
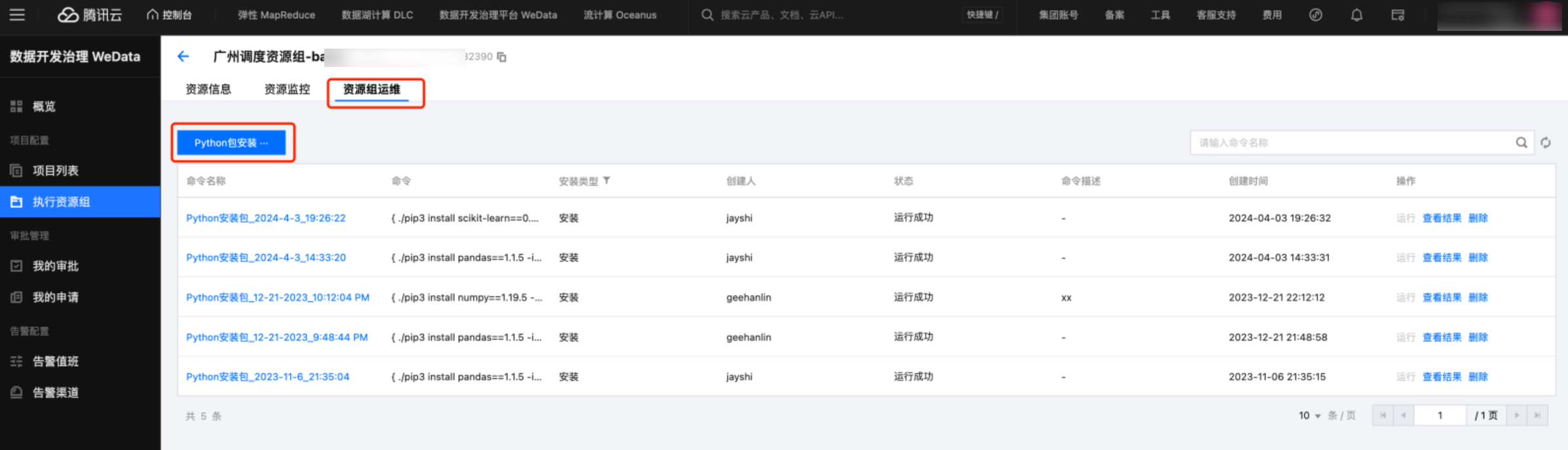
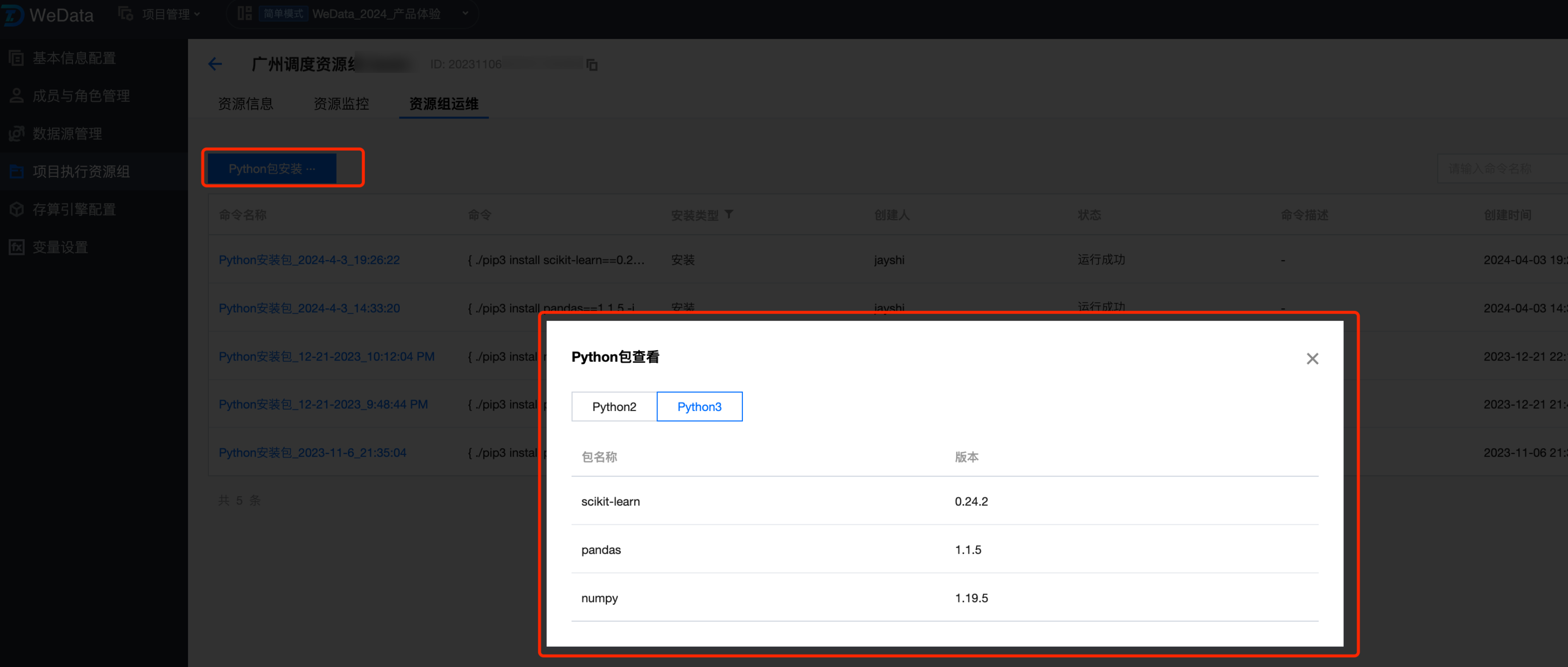
3. 目前平台只支持内置库的安装,这里安装 sklearn 和 pandas 库,安装完成后,可以通过 Python 包查看功能,查看已安装的 Python 库。
编辑 PySpark 任务
1. 创建任务,调度资源组选中安装了 Python 包的调度资源组。
2. 编写 PySpark 代码使用 Python 库,这里使用了 pandas 和 sklearn。
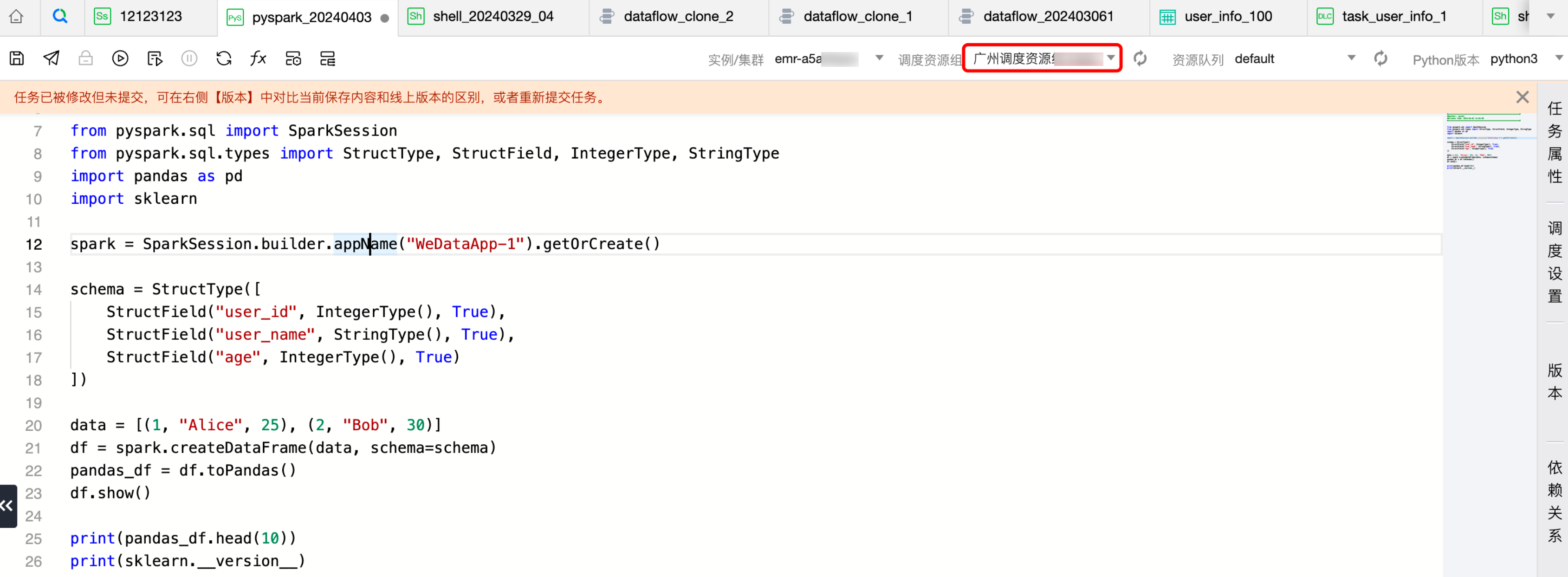
from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pandas as pd import sklearn spark = SparkSession.builder.appName("WeDataApp-1").getOrCreate() schema = StructType([ StructField("user_id", IntegerType(), True), StructField("user_name", StringType(), True), StructField("age", IntegerType(), True) ]) data = [(1, "Alice", 25), (2, "Bob", 30)] df = spark.createDataFrame(data, schema=schema) pandas_df = df.toPandas() df.show() print(pandas_df.head(10)) print(sklearn.__version__)
调试 PySpark 任务
1. 单击调试运行,查看调试运行的日志和结果。
示例:日志中可以查看使用调度资源组的 Python 环境作为任务运行的环境。
spark.yarn.dist.archives,file:///usr/local/python3/python3.zip#python3
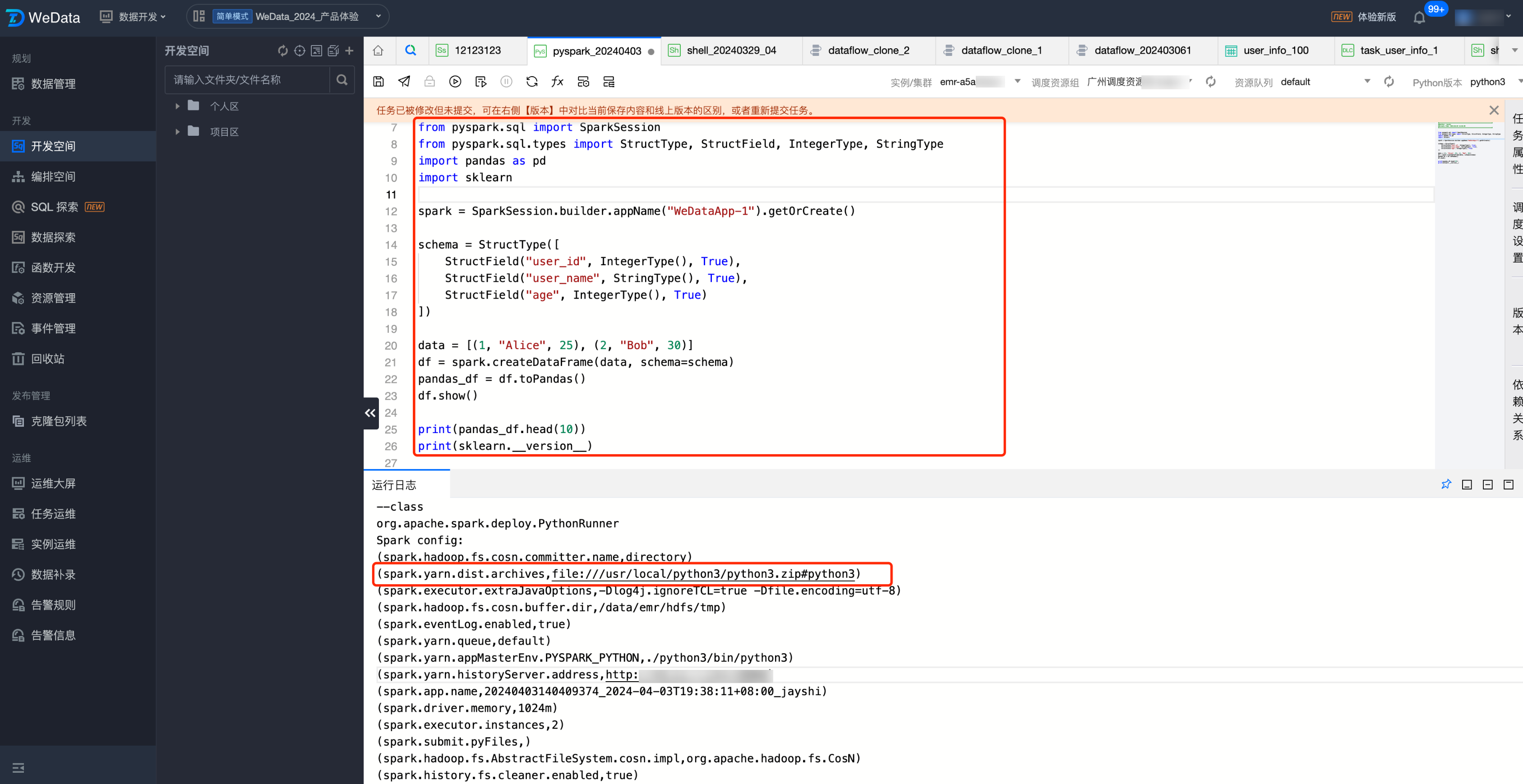
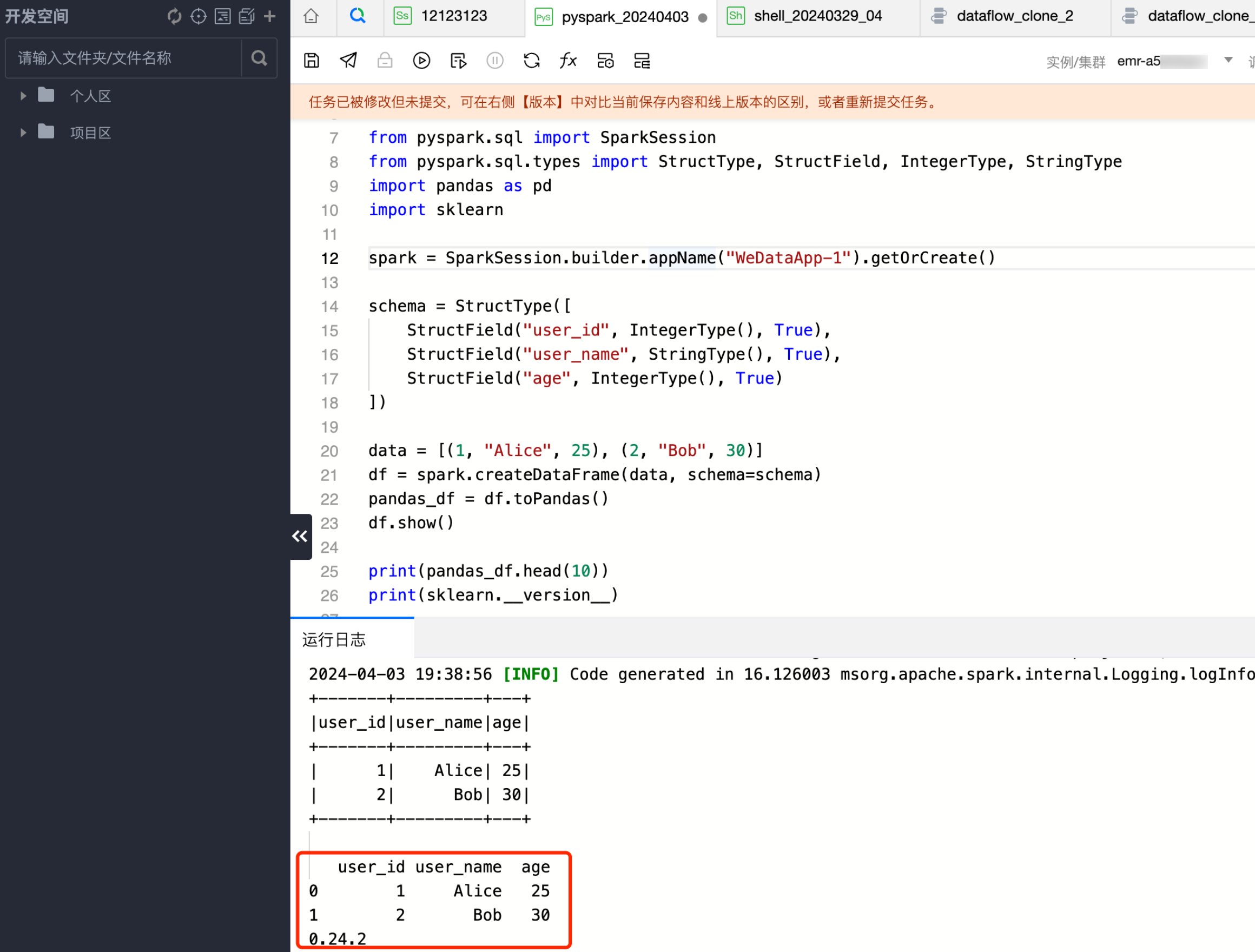
2. 查看日志结果,即可查看使用安装的 pandas 库,正确打印了安装的 sklearn 库的版本。
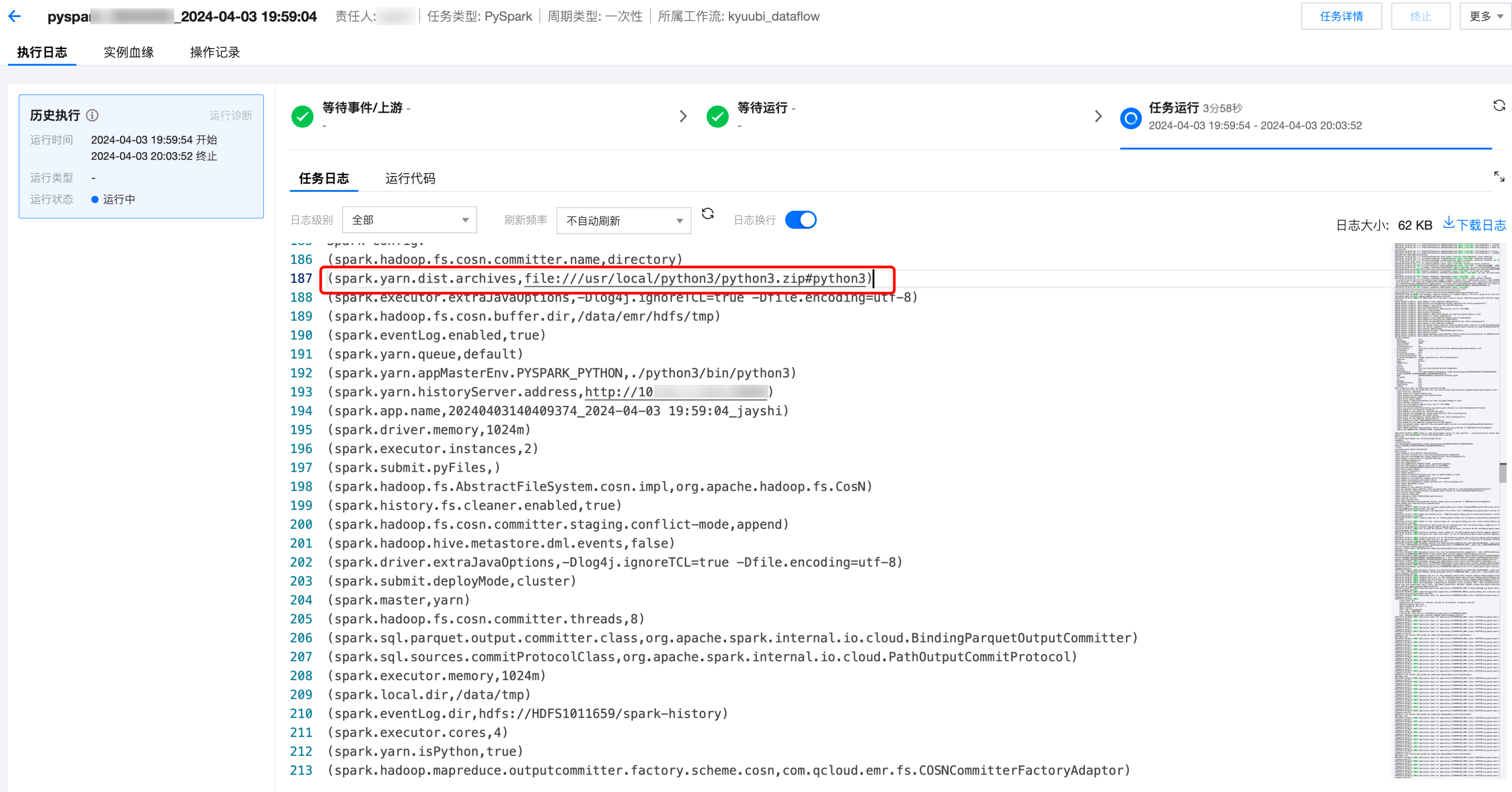
周期调度 PySpark 任务
周期调度运行,查看调试运行的日志和结果。日志中可以查看使用调度资源组的 Python 环境作为任务运行的环境。
文档反馈