AutoML 实验
Download
聚焦模式
字号
功能概述
AutoML(自动化机器学习,Automated Machine Learning)是一种自动化机器学习流程的技术,旨在让用户无需深入掌握机器学习算法和调参细节,也能高效地完成数据预处理、特征工程、模型选择、超参数优化、模型评估等一系列机器学习任务。AutoML 平台通常会自动尝试多种算法和参数组合,帮助用户快速找到最佳的机器学习模型。
简而言之,AutoML 让机器学习变得更简单、更高效,适合没有深厚算法背景的业务人员,也能帮助专业数据科学家提升建模效率。AutoML 会自动为这些任务准备数据、尝试多种主流算法,并生成包含完整训练流程的 Python notebook,便于您复查、复用和修改代码。
注意:
AutoML 当前仅支持 DLC 引擎的任务。并且只有 DLC 引擎建立资源组时选择“wedata-data-science”镜像,才可以用于 AutoML 实验。
应用场景
任务类型 | 适用场景 | 核心目标 |
AutoML - 分类 | 预测类别(如客户风险等级、商品分类) | 输出类别标签(如 “高风险”、“中风险”、低风险) |
AutoML - 回归 | 预测连续数值(如销售额、库存数量) | 输出具体数值(如 “500 件”) |
AutoML - 时序预测 | 基于历史时间序列预测未来趋势(如销量预测) | 输出未来时间段的数值序列(未来7天的销量) |
操作步骤
AutoML 实验新建入口
1. 登录 WeData 平台,在左侧导航栏找到“模型实验”模块,单击进入 “实验列表” 页面。
2. 页面顶部将显示 3 个 AutoML 实验入口:新建 AutoML - 分类实验、新建 AutoML - 回归实验、新建 AutoML - 时序预测实验,根据业务需求选择对应入口。
支持创建分类场景的 AutoML 实验,帮助您自动化搜索最优模型和参数。

创建实验,自动生成 AutoML 实验代码。
根据配置发起 AutoML 训练,并自动化搜索模型和参数。
进入实验管理,监控模型训练过程,对比模型训练结果。
单击后进入创建表单。
新建 AutoML 实验
分类实验
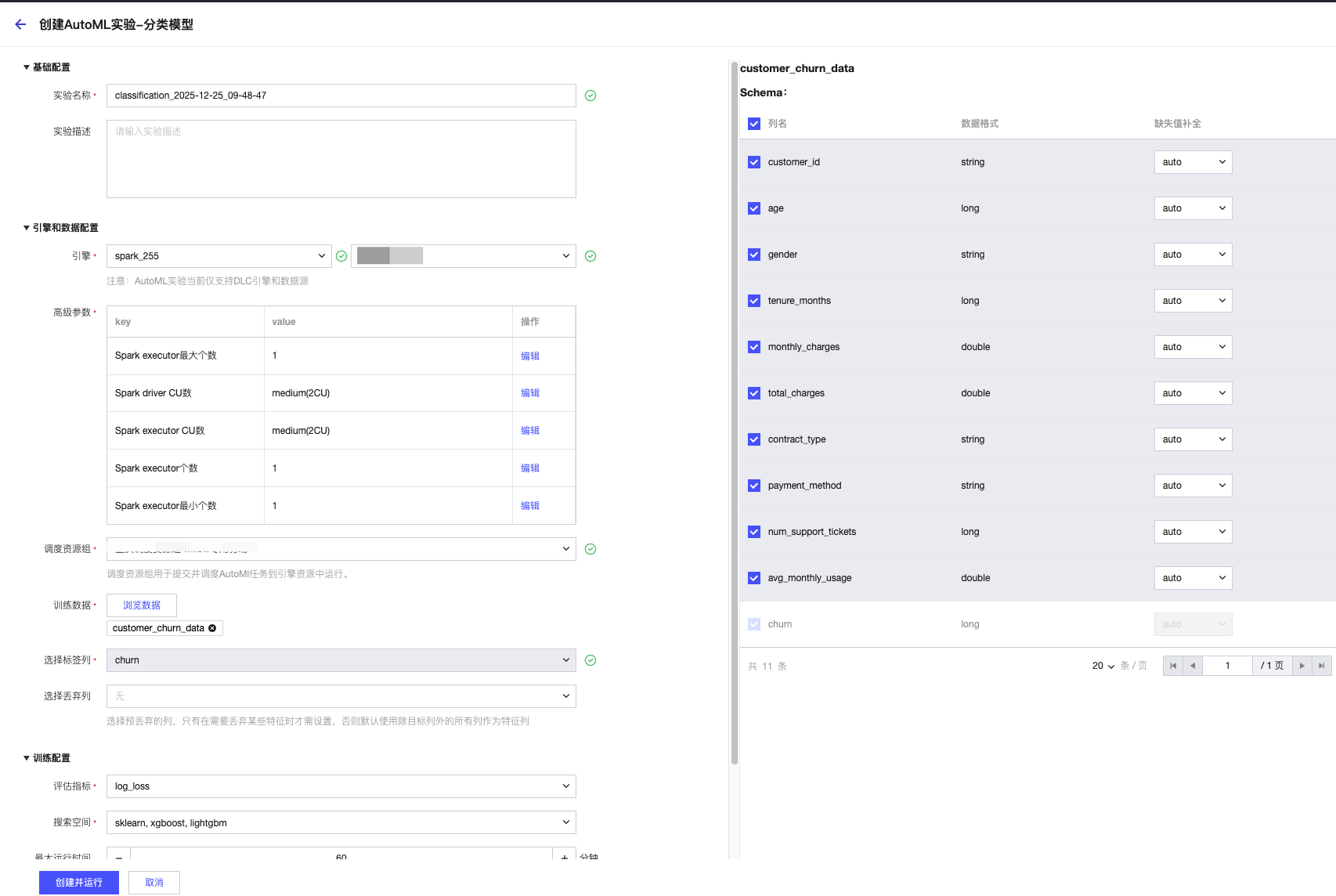
步骤 1:基础配置
实验名称:输入不超过 50 个字符的名称(如 “2025Q4 客户风险分类实验”)。
实验描述:可选,输入不超过 100 个字符的说明(如 “基于客户消费数据预测风险等级”)。
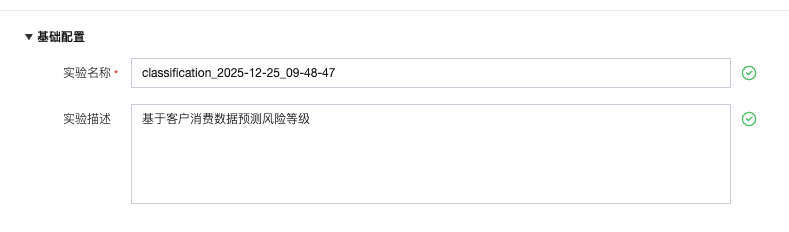
步骤 2:引擎和数据配置
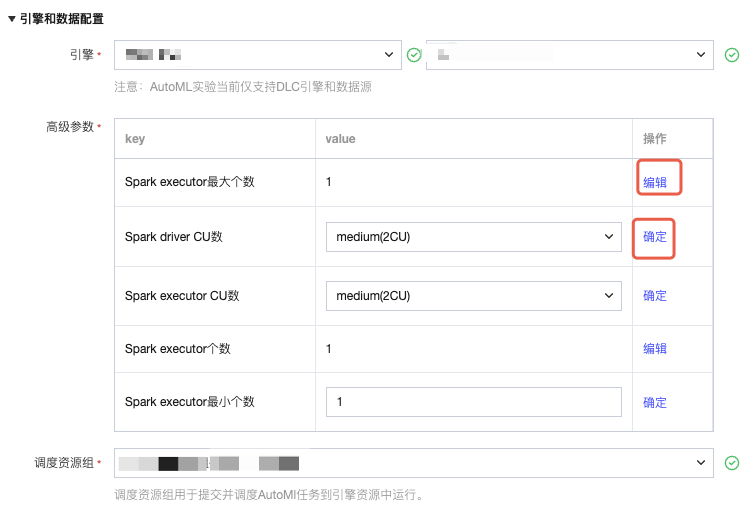
1. 引擎选择:仅支持 “DLC 引擎”,下拉选择对应资源组(提示:资源组需与数据所在网络一致)。
高级参数:可选,如需配置内核参数(如内存、CPU),单击 “编辑” 填写,填写后单击确定保存。
2. 训练数据选择:
单击 “浏览数据”,在弹窗中选择数据所在的 “数据目录→数据库→数据表”(仅显示 DLC 引擎下的数据)。
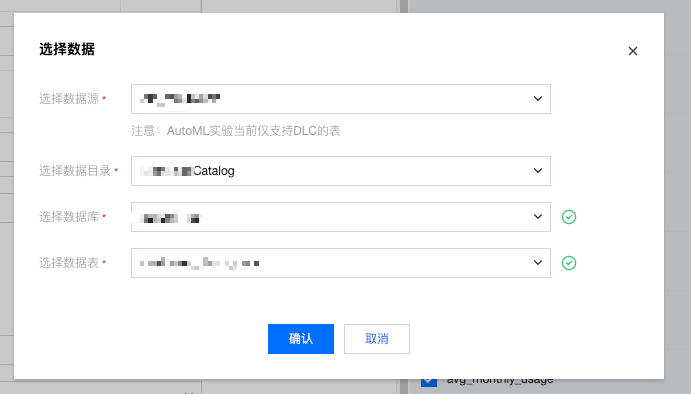
注意:
数据限制:仅支持 DLC 引擎下的数据库 / 数据表,非 DLC 数据需先迁移至 DLC。
数据预览:选择后右侧将显示数据表结构(Schema),默认全选所有列。
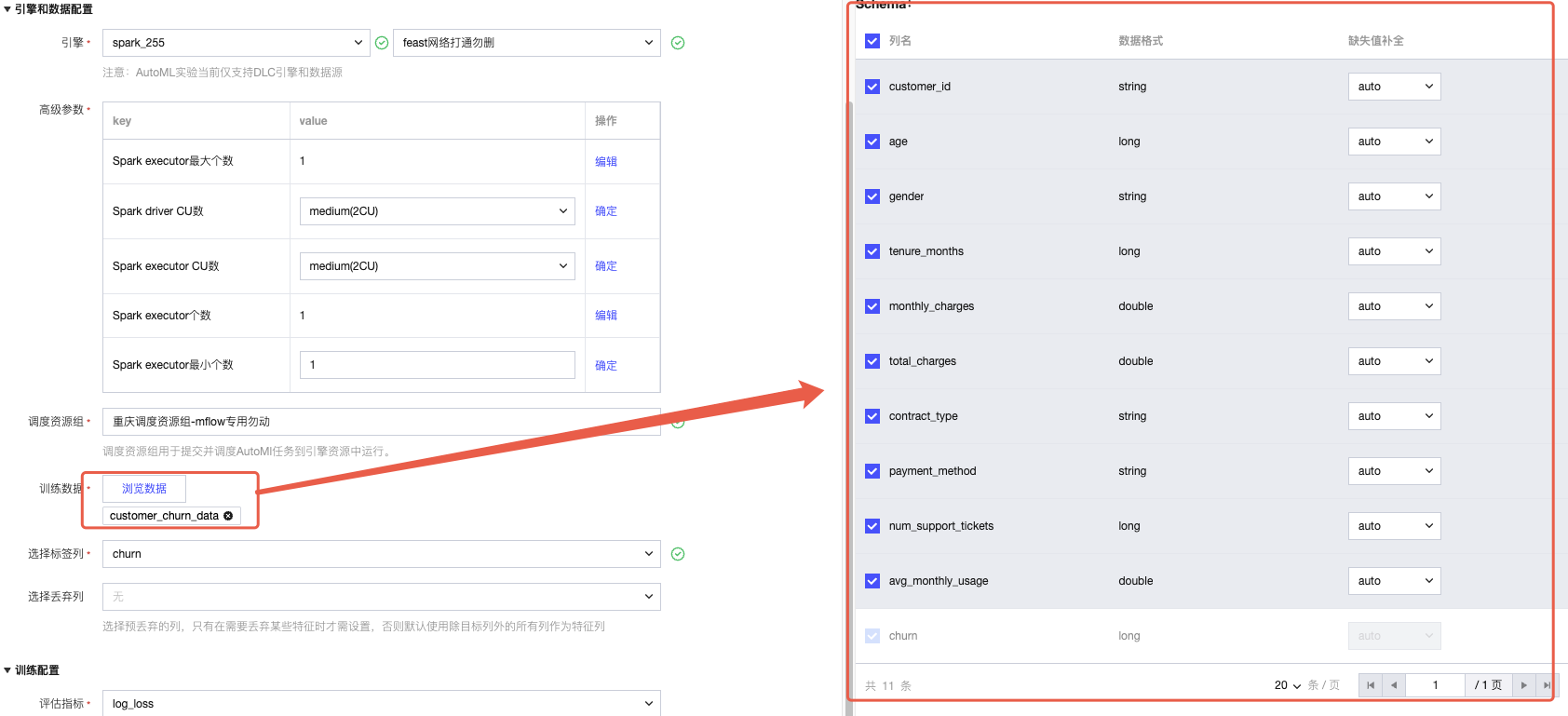
缺失值补全:下拉选择补全方式(auto / 平均值 / 中位数 / 众数)。
选择标签列:单选 “目标类别列”。
选择丢弃列:多选无需作为特征的列(如 “客户 ID”,丢弃后不参与训练)。
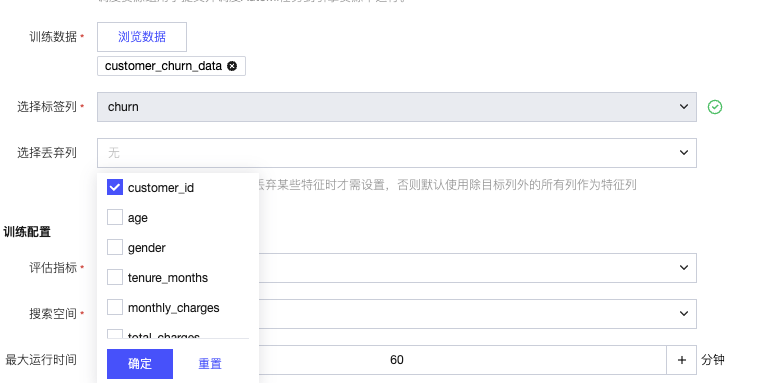
步骤 3:训练配置
评估指标:单选(默认 “log_loss”,可选 “f1”“precision”“accuracy”“roc_auc”)。
搜索空间:多选需自动测试的模型框架(默认全选,可选 “sklearn”“xgboost”“lightgbm”)。
最大运行时间:默认 60 分钟(可调整,超时将停止实验)。
最大运行次数:默认 100 次(可调整,即自动测试的模型参数组合数量)。
最大运行并发:默认 1(可调整,实际并发取决于 DLC 资源情况)。

步骤 4:创建实验与查看结果
1. 单击页面底部 “创建并运行”,系统将自动生成 AutoML 实验代码并发起训练。
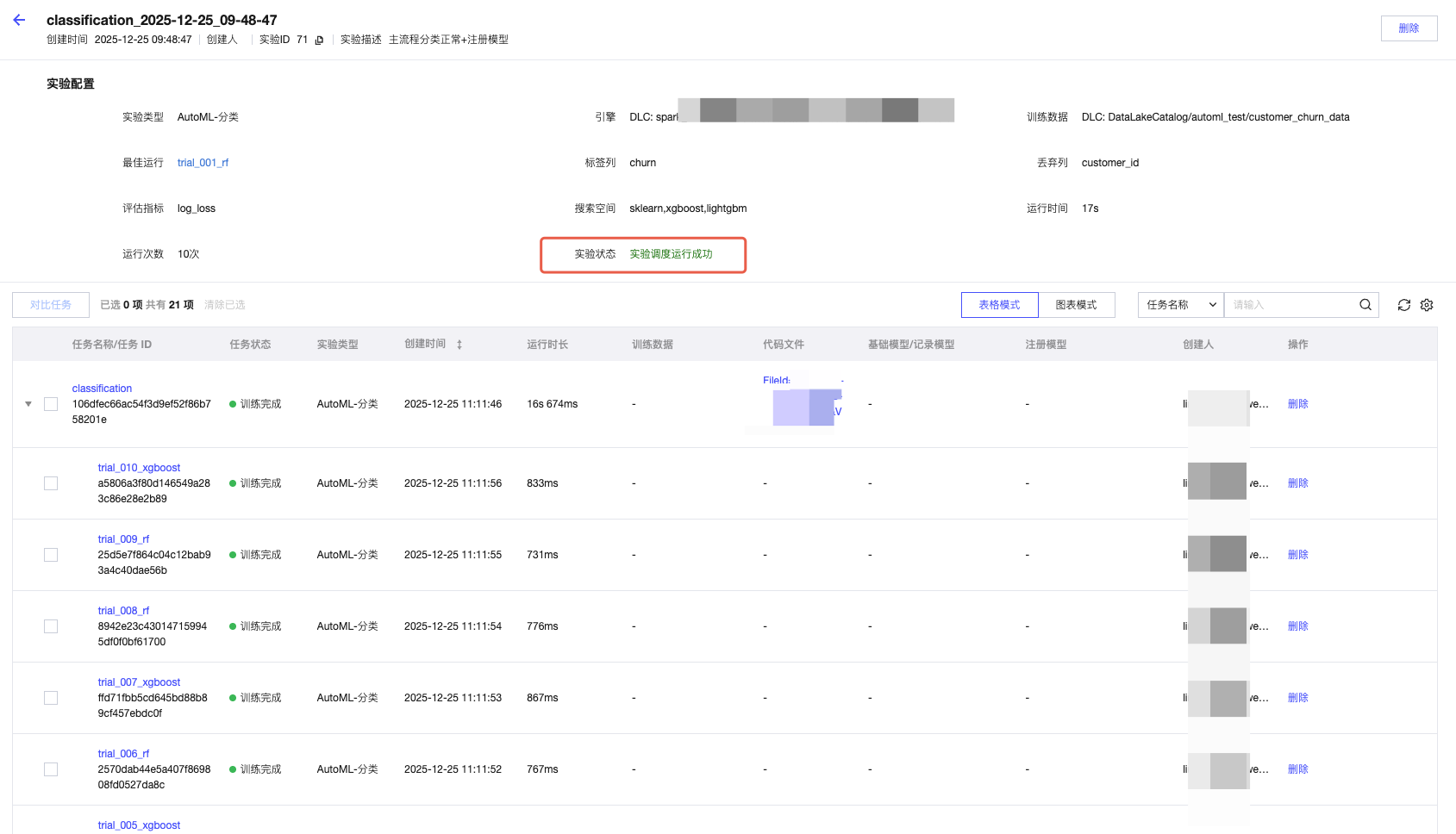
2. 回到 “实验列表”,找到目标实验,可查看 “实验状态”(绿色 = 成功,红色 = 失败,失败时鼠标悬停显示原因)。
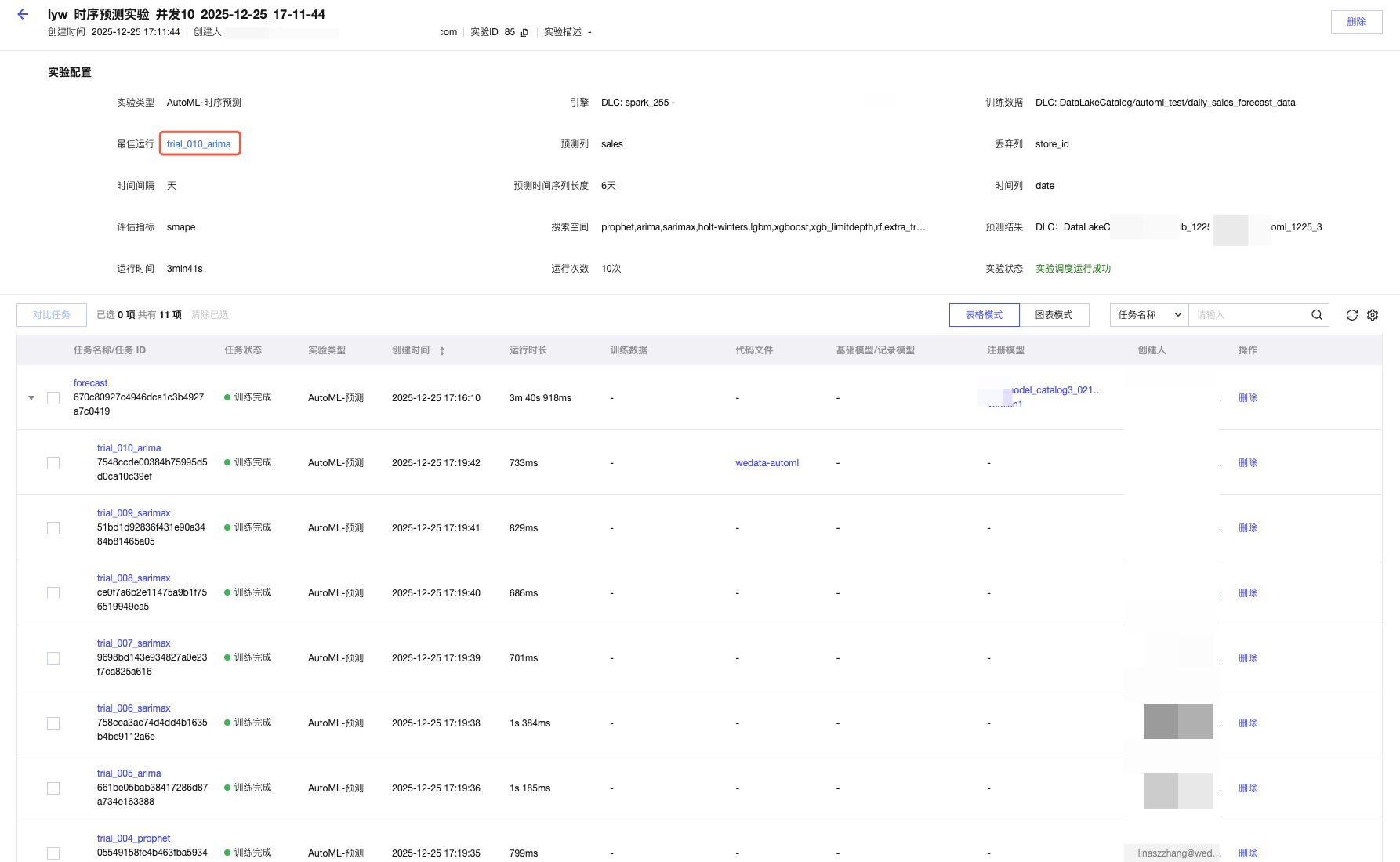
3. 查看详情:单击实验名称进入 “任务详情”,其中 “最佳运行” 字段显示最优模型,单击可查看该模型的参数、评估分数、生成的 Notebook 代码。
说明:
实验成功后,可在 “最佳运行” 详情中下载 Notebook 代码,用于后续手动调整模型。
回归实验
步骤 1-3:与 “分类实验” 基本一致,仅以下配置不同
步骤 3 评估指标:默认 “deviance”,可选 “RMSE”“MAE”“R2”“MSE”。

其他配置(引擎、数据、搜索空间等)与分类实验完全一致。
步骤 4:提交与查看结果
同 “分类实验” 步骤 4(实验状态、最佳运行、部署流程一致)。
时序预测实验
步骤 1:基础配置
与 “分类实验” 一致(实验名称、描述)。
步骤 2:引擎和数据配置(核心差异点)
1. 引擎选择:同分类实验(仅 DLC 引擎 + 资源组)。
2. 训练数据选择:
数据选择逻辑同分类实验(仅 DLC 表)。
选择时间列:单选 “时间列”(如 “日期”,需为 date/time 类型,选择后不可丢弃)。
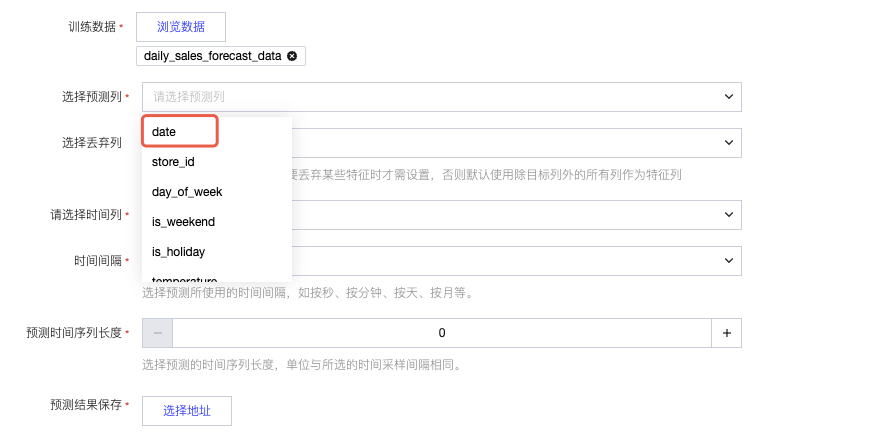
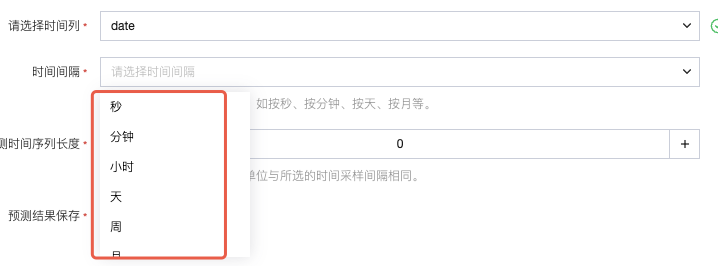
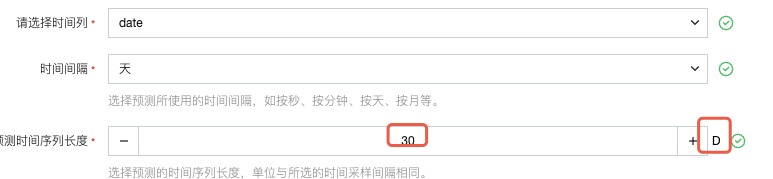
时间间隔:下拉选择数据的时间频率(如 “天”“小时”“月”,需与实际数据频率一致)。
预测时间序列长度:输入数字(如 “30”,表示预测未来 30 个时间间隔的数值)。
选择预测列:单选 “预测列”(如 “销量”);

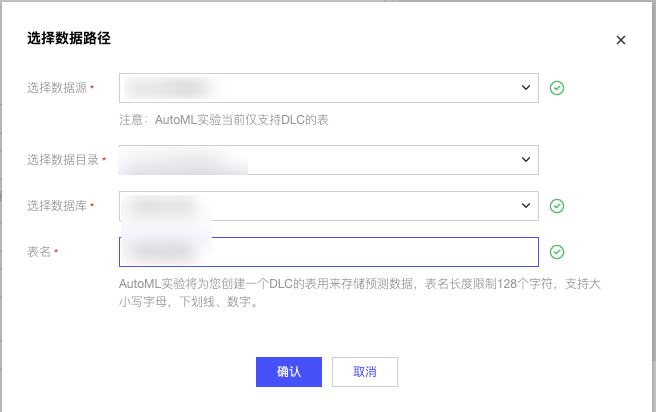
预测结果保存:
单击 “选择数据路径”,选择结果存储的 DLC 数据库;
填写表名(限制 128 字符,支持字母、数字、下划线),系统将自动创建该表存储预测结果。
步骤 3:训练配置(差异点)
评估指标:默认 “smape”,可选 “mse”“rmse”“mae”“mdape”;

搜索空间:默认全选,可选 “Facebook Prophet”“ARIMA”“SARIMAX”“Deep-AR”“XGBoost” “LightGBM”“Holt-Winters”等
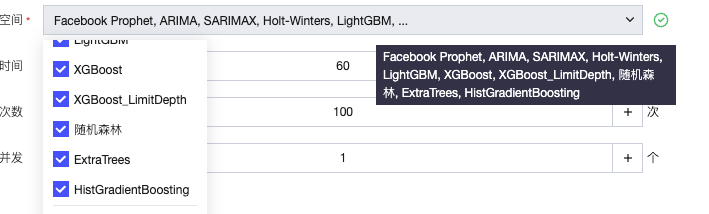
其他配置(运行时间、次数、并发)与分类实验一致。
步骤 4:提交与查看结果
1. 提交实验后,在 “实验列表” 中查看状态;
2. 单击 “最佳运行” 查看最优预测模型。
AutoML 实验对比
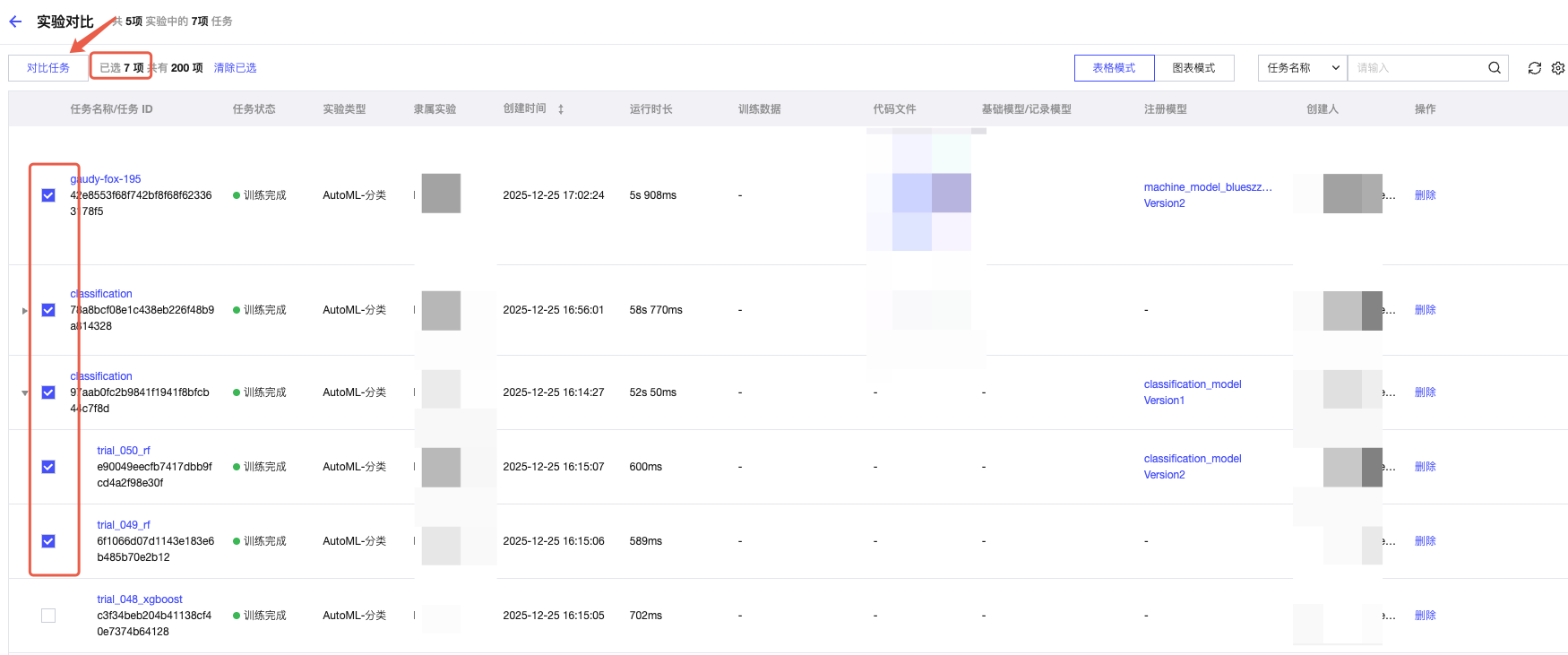
1. 相同类型的实验可以横向进行对比,在实验列表勾选相同类型的实验,单击对比实验按钮。
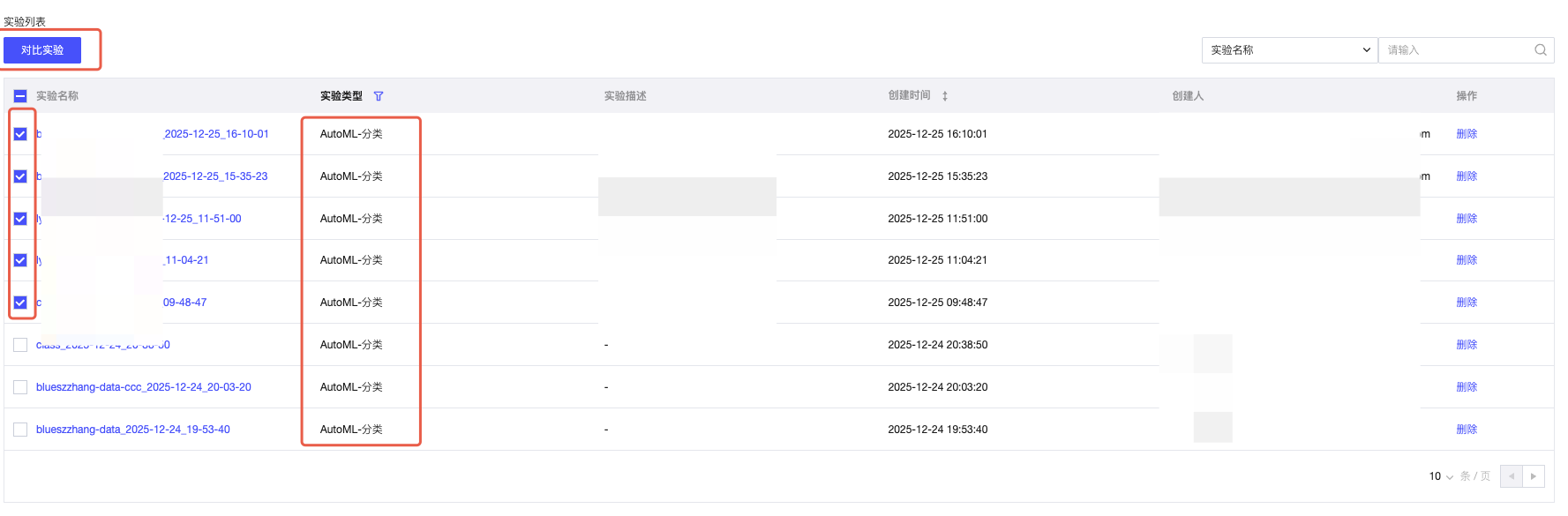
2. 勾选不同实验中的任务,单击对比任务。
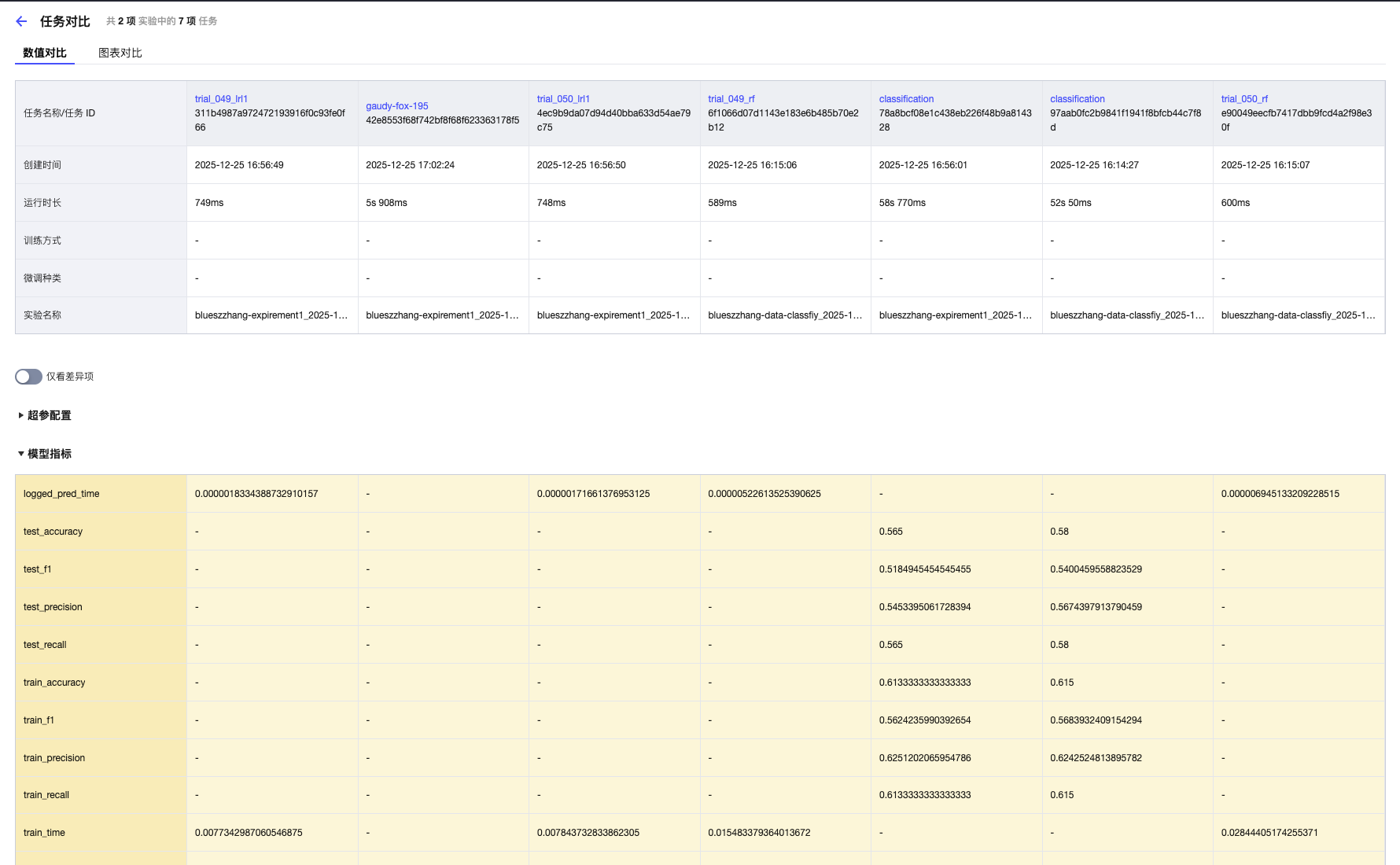
任务对比详情与单个实验中的任务对比页面相同。
常见问题
1. 预测表中的 “标签列”“预测列” 代表什么?
即 “目标列”,不同任务类型下含义不同:
分类实验:代表 “真实类别标签”(如 “高风险”“低风险”),用于与模型预测的 “prediction” 列对比,评估准确性;
回归实验:代表 “真实连续数值”(如 “实际销售额 500 万”),用于计算预测值与真实值的误差;
时序预测实验:部分场景下 “预测列” 即 “历史真实值”,与 “预测值” 列共同构成时间序列,便于观察预测趋势。
2. 如何计算预测准确性?
准确性通过 “训练配置” 中选择的 “评估指标” 计算,不同任务对应指标及逻辑如下:
任务类型 | 常用指标 | 计算逻辑 |
分类 | accuracy(准确率) | (预测正确的样本数 / 总样本数)× 100% |
分类 | f1 分数 | 综合 “精确率” 和 “召回率” 的调和平均数,取值 0-1(越接近 1 越好) |
回归 | R2(决定系数) | 衡量模型解释数据变异的能力,取值 0-1(越接近 1 说明预测越准) |
回归 | MAE(平均绝对误差) | 所有样本 “真实值 - 预测值” 的绝对值的平均值(越小越好) |
时序预测 | smape(对称平均绝对百分比误差) | 衡量预测值与真实值的百分比误差,取值 0-100%(越小越好) |
文档反馈