模型服务
Download
Focus Mode
Font Size
模型服务概述
模型服务是实现 MLOps 全生命周期闭环的关键,通过将模型管理中的模型一键发布为 API 服务,支持实时预测及在线推理,并提供完善的服务监控与运维能力。此外,模型服务深度集成了数据科学的其他核心模块,支持将模型一键发布为标准 REST API,提供多维度的流量、资源监控及运行日志回溯能力。
功能操作指南
WeData 的模型服务提供新建服务、服务监控、服务调试等功能,可以更高效地管理服务,并确保它们在生产环境中的有效性。
新建模型服务
单击新建模型服务,填写如下信息:
服务类型:机器学习服务。
基本配置:服务名称、服务版本、服务名描述。
模型资源:选择模型、镜像资源。
高级设置:是否开启鉴权,开启服务日志投递,配置 COS 存储地址。
资源配置:选择按量计费、CVM 资源组。
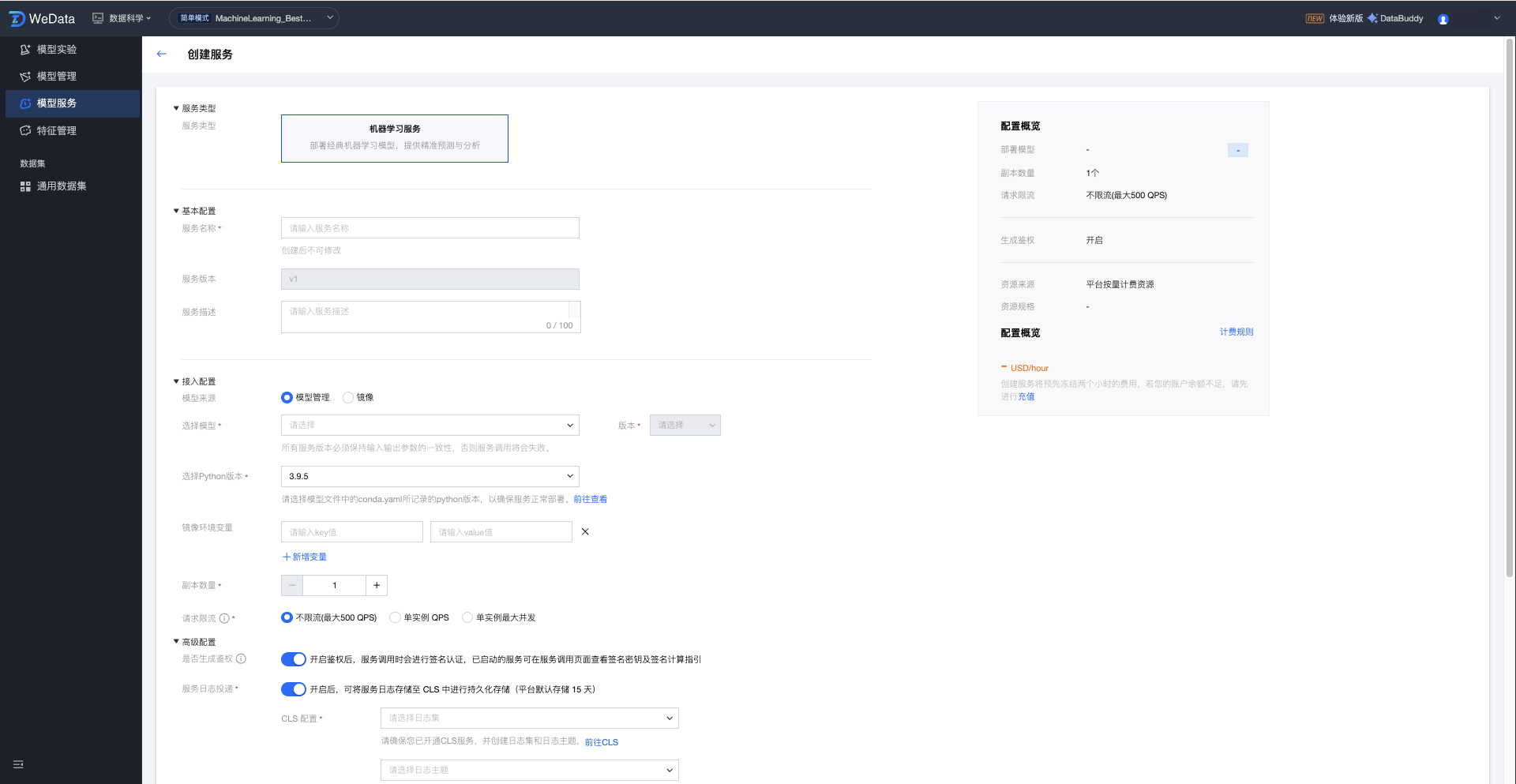
模型来源-模型管理
对于在本地开发环境或 WeData Notebook 中训练完成的模型,用户需先通过 MLflow 插件将其注册至模型管理模块中。注册成功后,该模型即转化为企业级的标准化模型资产,可供模型服务模块直接调用并一键发布为在线 API。
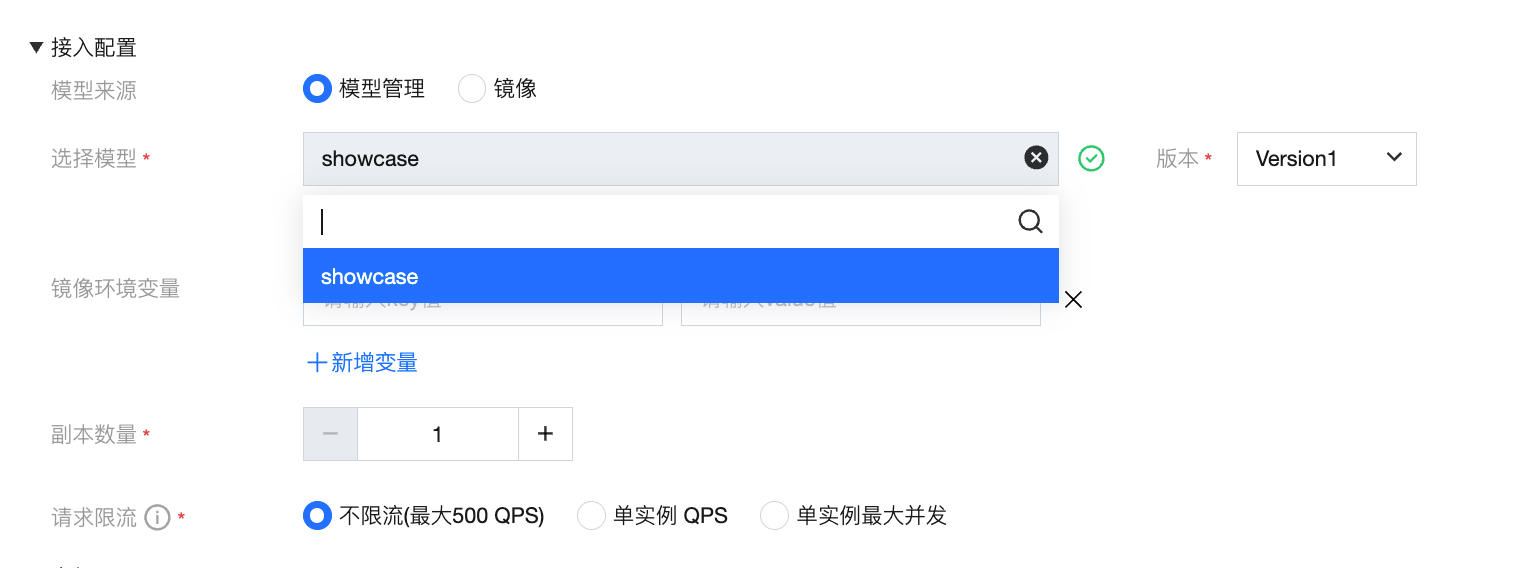
模型来源-自定义镜像
核心价值:
深度自定义环境:支持内置非标准的机器学习框架或特定版本的系统库。
预处理逻辑集成:允许在镜像中直接封装“数据拼接”或“特征在线访问”的代码,实现“特征 -> 模型 -> 推理”的端到端闭环。
代码挂载与灵活启动:通过自定义启动命令,可以覆盖镜像默认行为,灵活拉起不同的推理引擎。
导入方式:
容器镜像服务 (TCR) 企业版:适用于企业内部受控的镜像资产管理,支持按地域、实例筛选,可精确到命名空间与仓库地址。
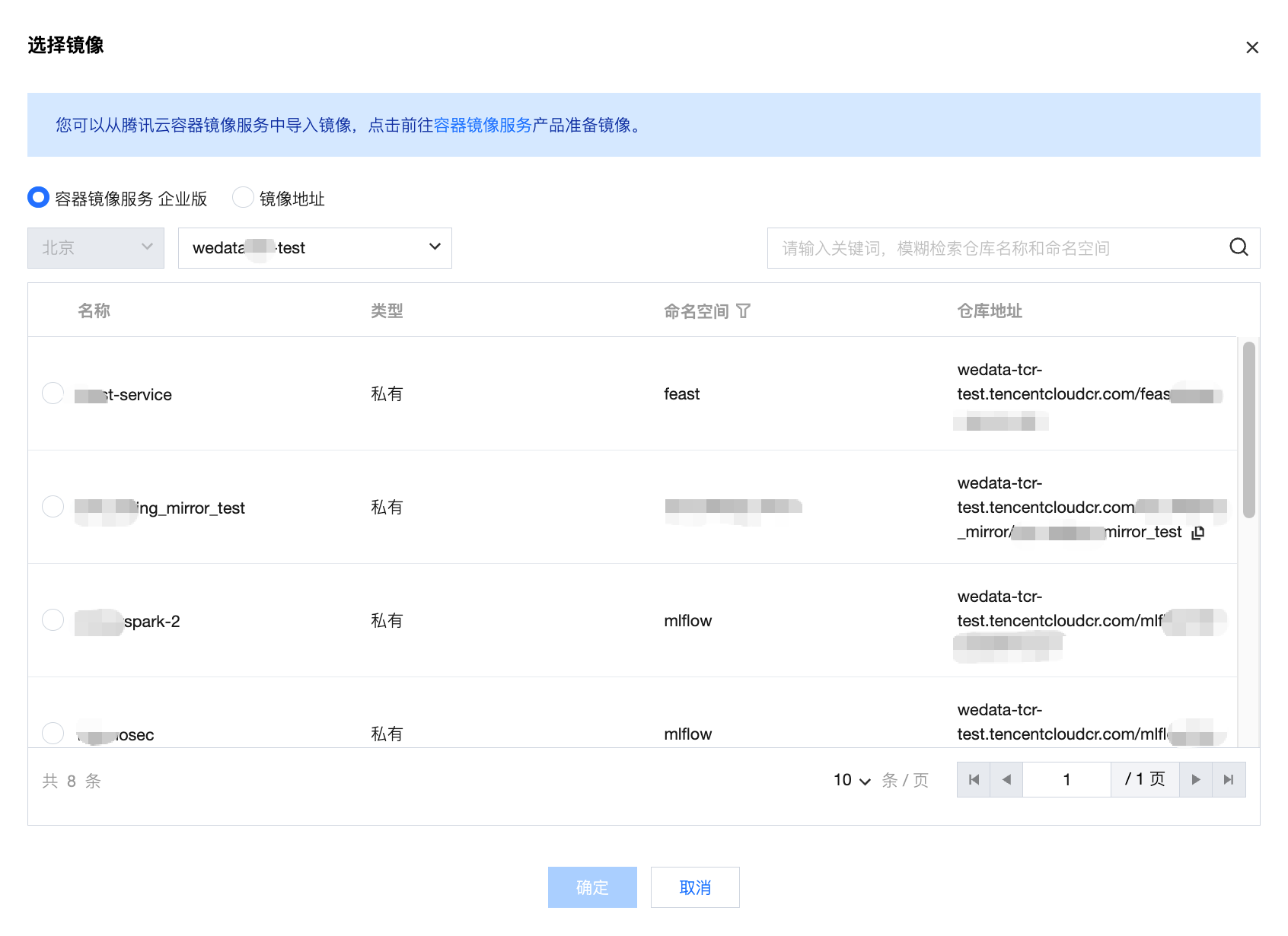
镜像地址:支持从腾讯云容器镜像服务中导入镜像。
说明:
支持开启授权私有镜像仓库,默认关闭,手动开启后,支持输入镜像仓库用户名、镜像仓库密码。
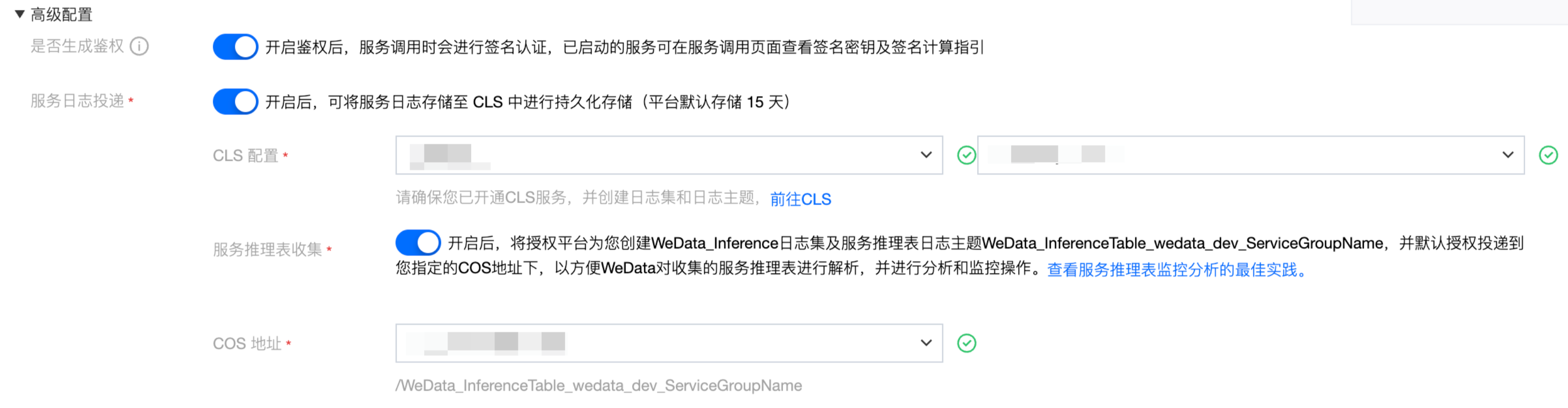
开启推理表收集(支持地域:北京、上海、重庆、国际-新加坡)
在创建模型服务时,可以通过高级配置选项启用完整的日志收集:
服务日志投递配置:首先需要开启服务日志投递功能,并指定目标日志集和对应的日志主题。一旦完成配置,模型服务产生的所有请求日志都会自动投递到指定的日志主题中。
推理表日志收集配置:同时开启服务推理表日志收集选项,并选择合适的 COS 存储桶作为数据存储目标。启用此功能后,系统会自动创建专门的日志加工任务,该任务负责对收集到的全量日志数据进行过滤和结构化处理并投递到预先指定的 COS 存储地址。
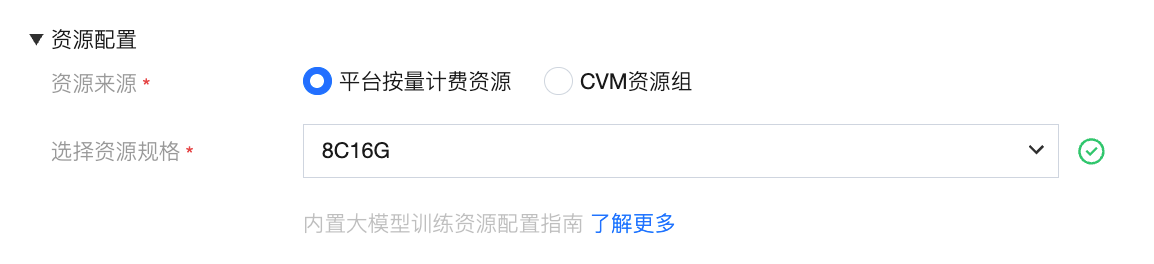
资源来源 - 平台按量计费
平台按量计费是 WeData 提供的托管式共享资源池,用户无需关心底层服务器的维护,只需按需申请算力规格。
操作指引:
在“资源来源”中勾选 “平台按量计费资源”。
在“选择资源规格”下拉框中,根据模型复杂度选择相应的规格
使用场景:
开发调试:快速拉起服务验证逻辑。
潮汐业务:流量波动剧烈且不定期,希望按实际使用时长结算以优化成本。
轻量推理:模型较小,不需要独占整台物理机资源。
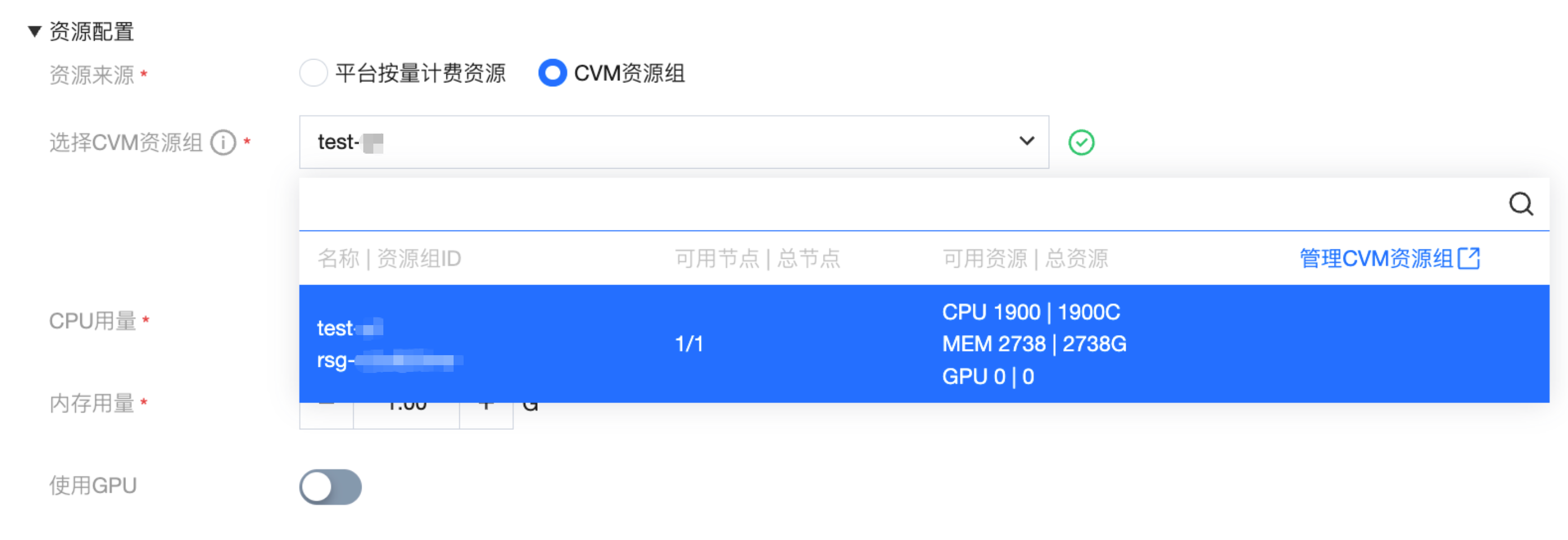
资源来源-CVM 资源组
CVM 资源组允许用户将自购的腾讯云服务器(CVM)导入 WeData 进行池化管理,实现计算资源的物理级隔离。
操作指引:
在“资源来源”中勾选 “CVM 资源组”。
在下拉列表中选择已创建并绑定的资源组。
注意:
一个资源组仅能被一个服务关联,以确保资源的绝对独占和稳定性。
适用场景:
核心生产业务:对延迟极其敏感,需规避共享环境下的“嘈杂邻居”干扰。
高并发推理:长期保持高 $QPS$ 运行,使用包年包月 CVM 成本更具优势。
GPU 专项任务:需要指定特定型号的 GPU 算力卡(如 T4、A100)进行高性能推理。
模型服务组列表
用户完成新建服务后,在服务列表中会显示全部已创建的模型服务,其显示内容包括:服务名称、服务状态、描述、创建人、创建时间、操作方式。
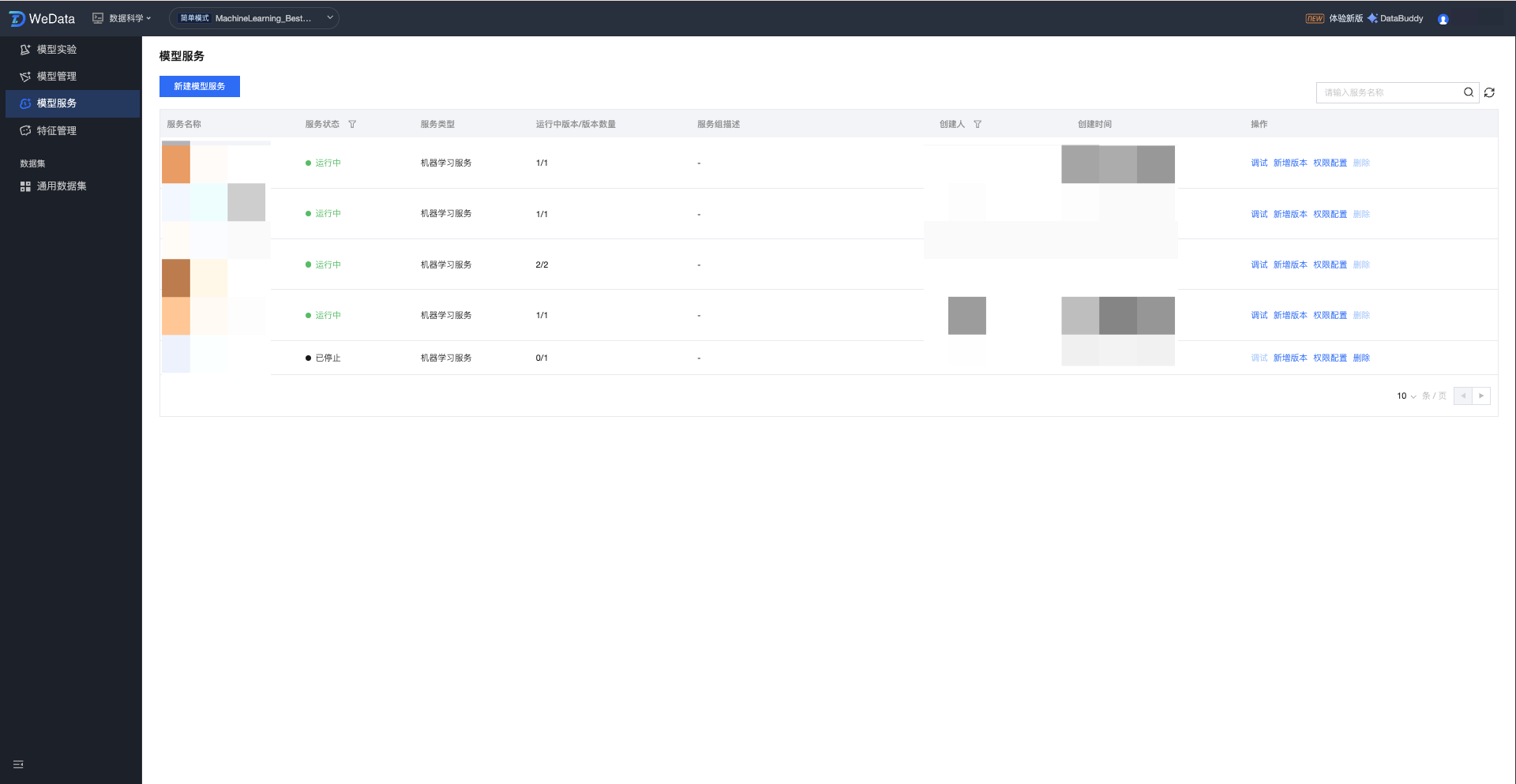
字段分类 | | 描述 | 说明 |
服务名称 | | 模型服务的唯一标识名称。 | 建议根据业务用途命名,支持单击进入服务详情页。 |
服务状态 | | 服务当前的运行生命周期状态。 | 常见状态包括:草稿(启动中)、运行中、已停止等。 |
服务类型 | | 标识服务所属的应用领域。 | 例如:机器学习服务 |
运行中版本/版本数量 | | 当下活跃服务版本/总版本数 | 展示服务组的多版本管理情况,如 0/1 表示总共 1 个版本但未启动。 |
服务组描述 | | 对该服务组的描述说明。 | 方便跨团队协作时,快速了解该服务组的用途 |
创建人 | | 创建该服务的用户账号。 | 用于审计及权限追溯。 |
创建时间 | | 服务首次被创建的时间。 | 可按时间顺序排列,方便快速查找近期服务。 |
操作 | 调试 | 进入在线调试界面测试模型接口。 | 提供标准化的 REST API 调用地址(要求服务组为运行状态) |
| 新增版本 | 在同一服务下部署新的模型版本。 | 实现模型的灰度发布或 A/B 测试场景,最多支持两个服务版本 |
| 权限配置 | 配置服务的权限。 | 支持配置可读、可写、可管理权限。(仅当开启实体权限管理模式后生效) |
| 删除 | 彻底移除模型服务资产及其关联资源。 | 操作不可逆,删除前需确认该服务组已停止运行。 |
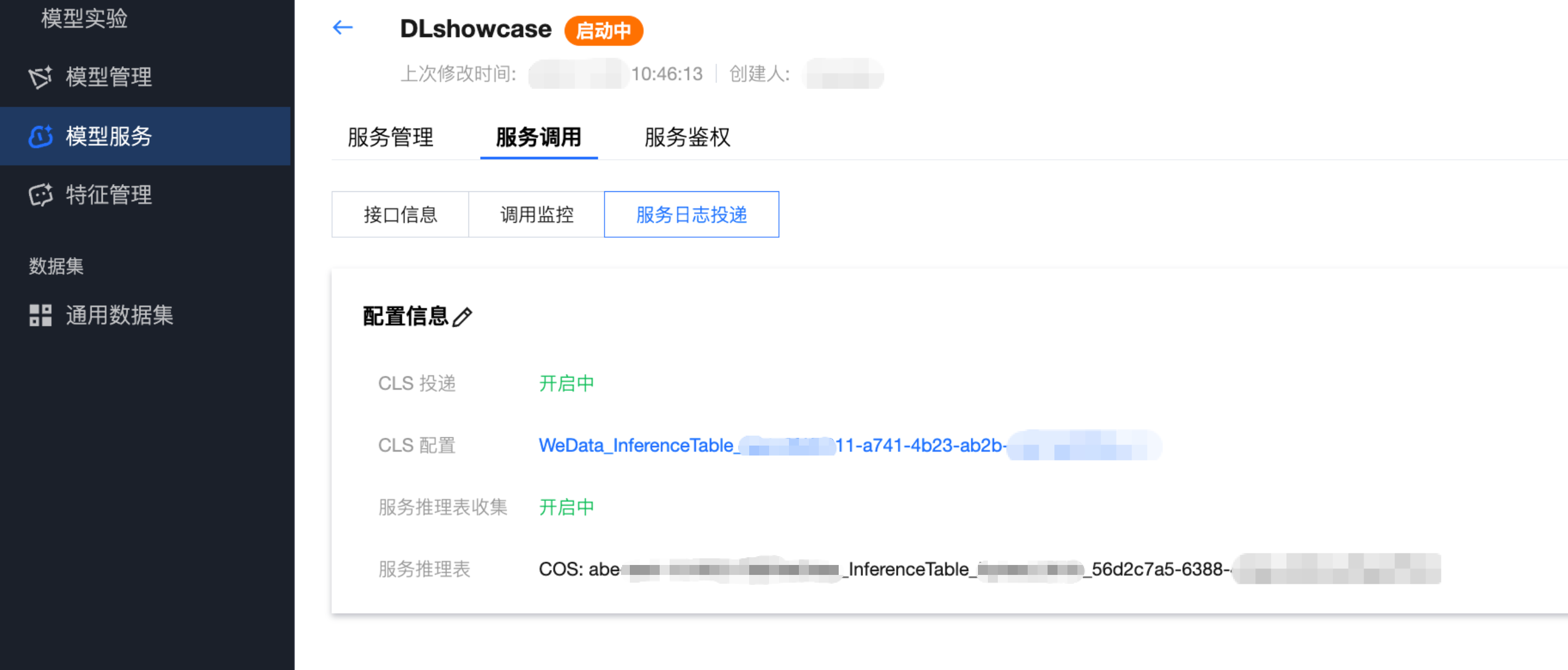
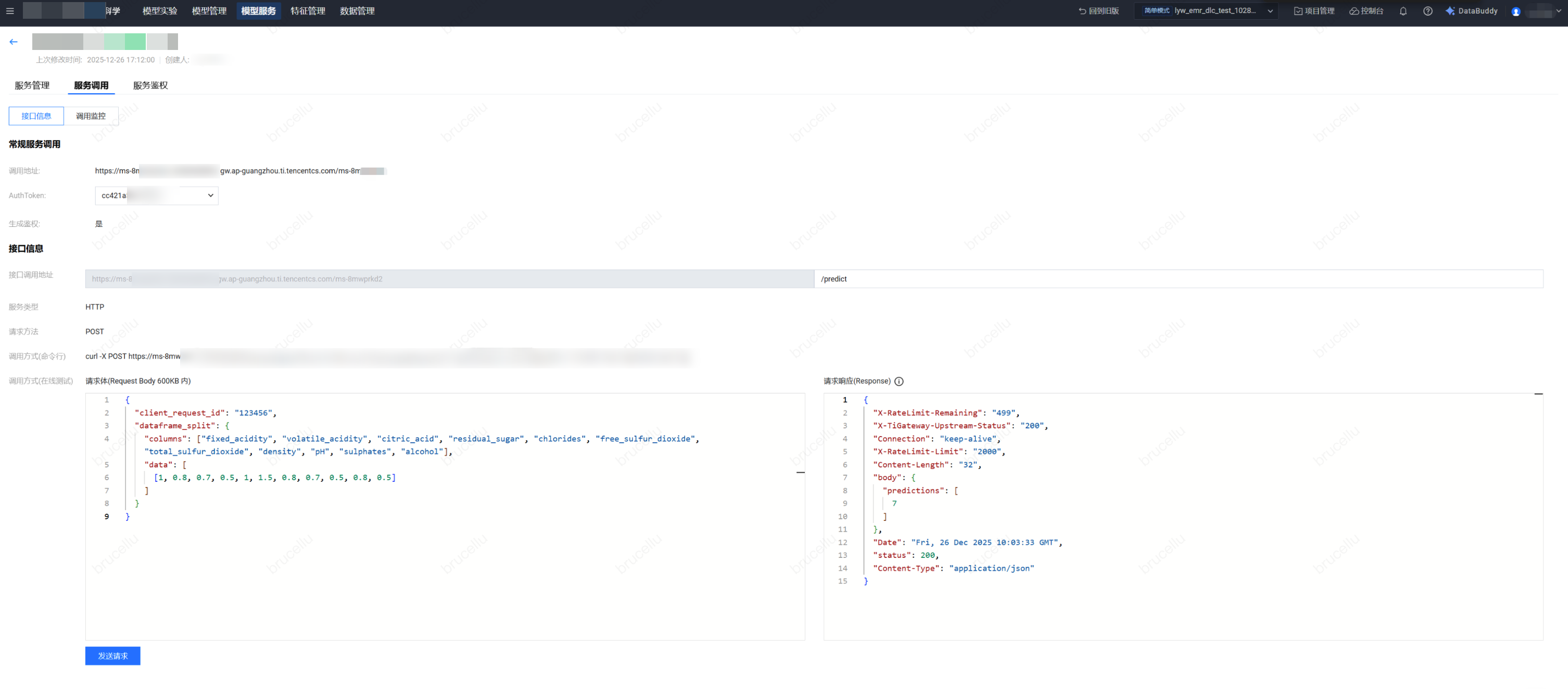
服务组在线调试
服务部署后,系统提供标准化的 REST API 信息:
接口基本信息
标准后缀地址:所有服务的调用地址后缀统一固定为 /predict。
请求方法:统一采用 POST 方式进行调用。
数据格式:请求与响应均采用 application/json 格式。
输入规范说明
在线测试与实际调用时,入参需遵循特定的 JSON 结构:
client_request_id:请求唯一标识字符串。
dataframe_split:固定键名,用于封装特征数据主体。
columns:字符串列表,包含模型训练时定义的特征字段名称(其内容与具体模型强相关)。
data:嵌套列表结构。内层列表代表一次推理的特征值(需与 columns 顺序对应);通过在内层并行放置多个列表,可实现单次请求多次推理。
在线调试请求示例
以“红酒质量预测”模型为例,其输入 JSON 示例如下:
单次推理请求体:
{"client_request_id": "123456","dataframe_split": {"columns": ["fixed_acidity", "volatile_acidity", "citric_acid", "residual_sugar", "chlorides", "free_sulfur_dioxide", "total_sulfur_dioxide", "density", "pH", "sulphates", "alcohol"],"data": [[1, 0.8, 0.7, 0.5, 1, 1.5, 0.8, 0.7, 0.5, 0.8, 0.5]]}}
多次推理(批量)请求体: 若需同时预测两组数据,只需在 data 数组中追加特征值列表即可:
{"client_request_id": "123456","dataframe_split": {"columns": ["fixed_acidity", "volatile_acidity", "citric_acid", "residual_sugar", "chlorides", "free_sulfur_dioxide", "total_sulfur_dioxide", "density", "pH", "sulphates", "alcohol"],"data": [[1, 0.8, 0.7, 0.5, 1, 1.5, 0.8, 0.7, 0.5, 0.8, 0.5],[0.9, 0.7, 0.6, 0.4, 0.9, 1.2, 0.7, 0.6, 0.4, 0.7, 0.4]]}}
调用 curl 指令
利用 curl 语句进行输入,包含调用地址、鉴权信息(如有)、内容类型、输入内容如下:
curl -X POST https://[服务调用地址]/predict \\-H 'Authorization: [鉴权Token]' \\-H 'Content-Type: application/json' \\-d '{"client_request_id":"123456","dataframe_split":{"columns":["fixed_acidity","volatile_acidity","citric_acid","residual_sugar","chlorides","free_sulfur_dioxide","total_sulfur_dioxide","density","pH","sulphates","alcohol"],"data":[[1,0.8,0.7,0.5,1,1.5,0.8,0.7,0.5,0.8,0.5]]}}'
调用演示:
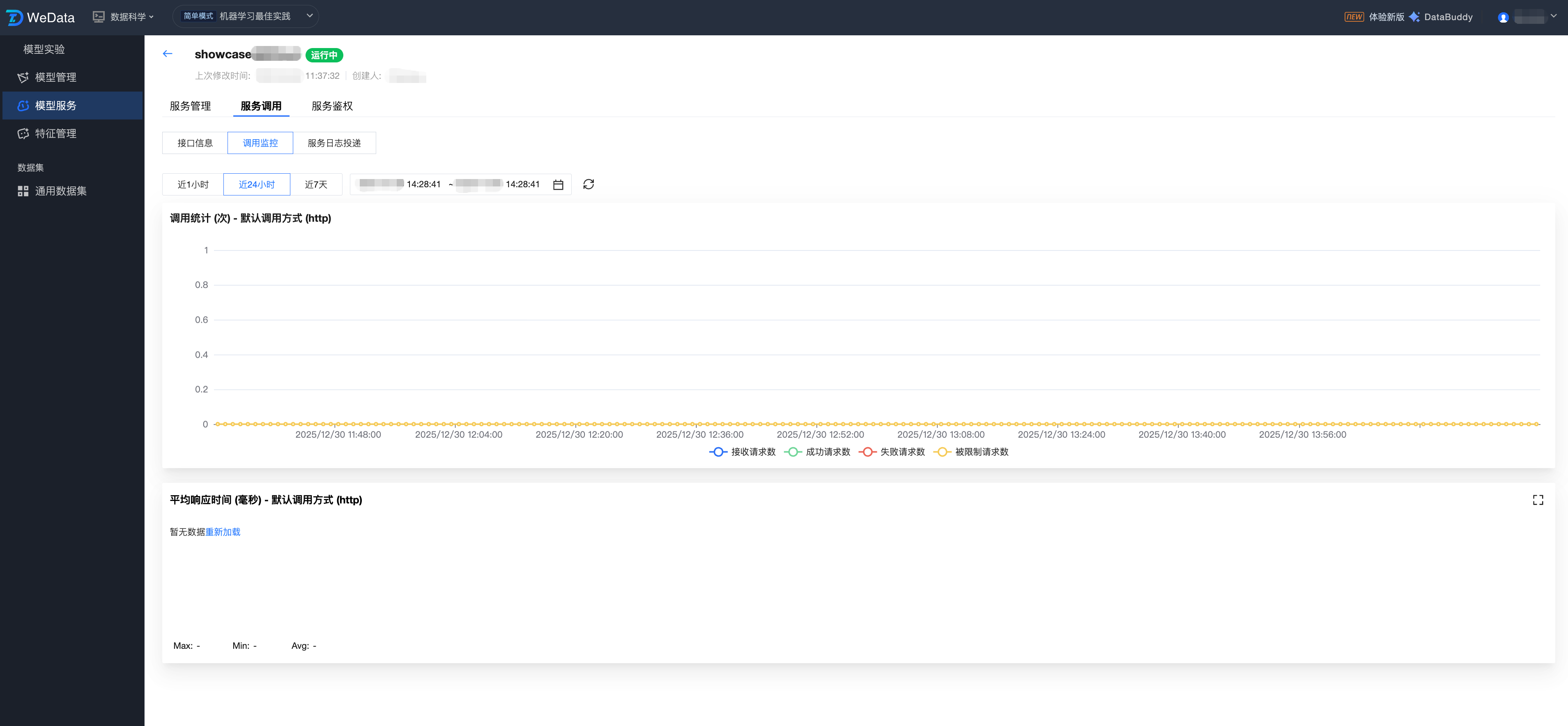
服务组性能监控与运维
模型服务提供多维度的监控视图,支持查看监控信息(1小时、24小时、7天、自选时间段),并支持调整时间粒度(1分钟、5分钟):
流量监控:网络流量、QPS、QPS 限流、并发请求数。
资源监控:CPU 使用率、MEM 使用率、显存使用率、GPU 使用率。
实例管理:实例数量、运行中实例数量。
服务事件:记录 Pod 调度、镜像拉取等系统事件,便于排查启动失败。
运行日志:支持实时刷新和搜索模型代码输出的日志信息。
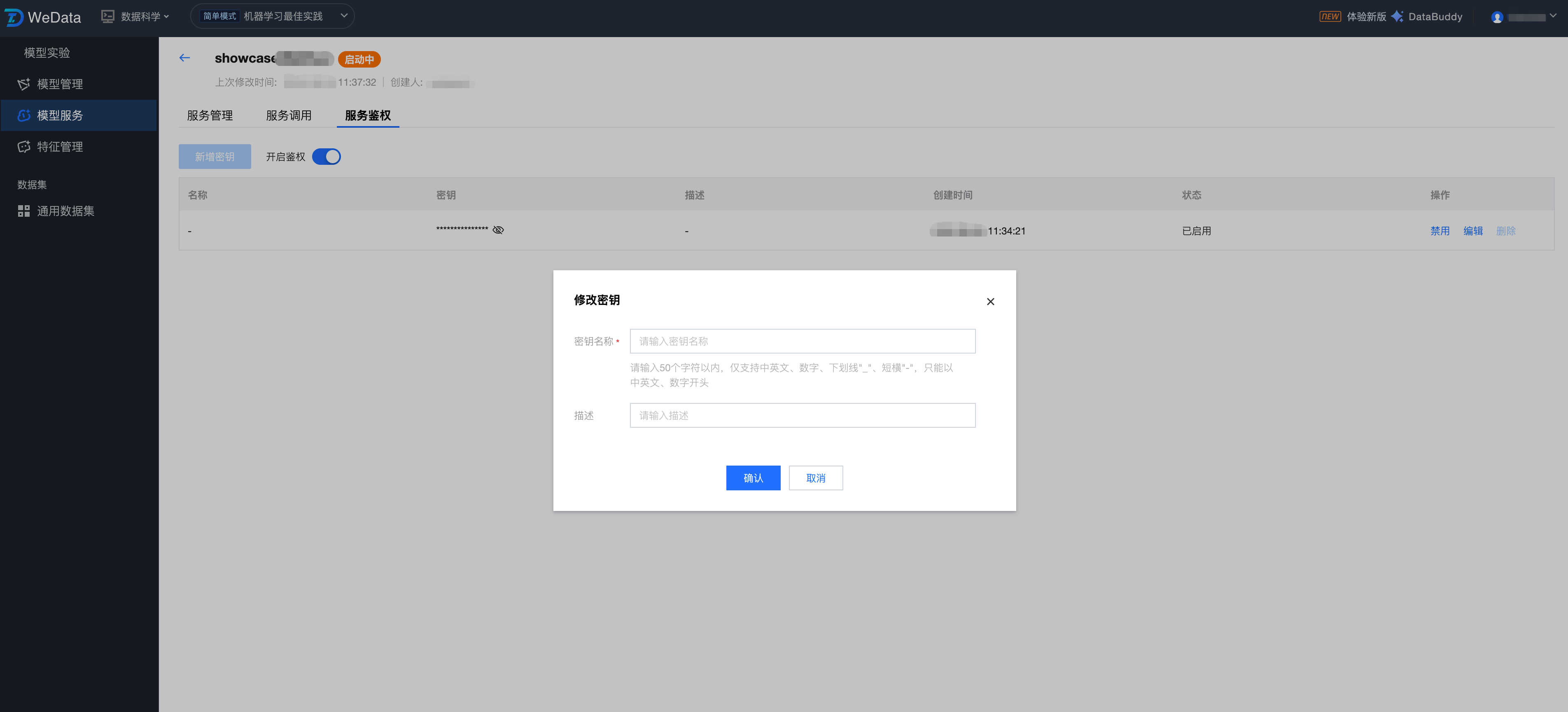
服务组开启鉴权配置
服务鉴权是保障模型服务调用安全的核心机制。开启鉴权后,系统将对所有进入该模型服务接入点(Endpoint)的请求进行身份验证。只有携带有效密钥(API Key)的请求才会被允许访问模型,从而防止模型接口被非法调用或恶意攻击。在服务版本详情页,切换至 “服务鉴权” 选项卡即可进行配置:
开启鉴权后:所有 REST API 请求必须在 Header 中包含密钥。
关闭鉴权后:接口处于公开状态,任何拥有调用地址的用户均可直接访问。
服务版本操作配置
单击服务组名称,进入服务版本列表,展示该服务组下全部版本信息:ID、服务名称、服务版本、状态、描述、模型来源、资源来源、流量分配、创建人、创建时间、更新时间、操作(更新/监控/日志/启动/删除等)。
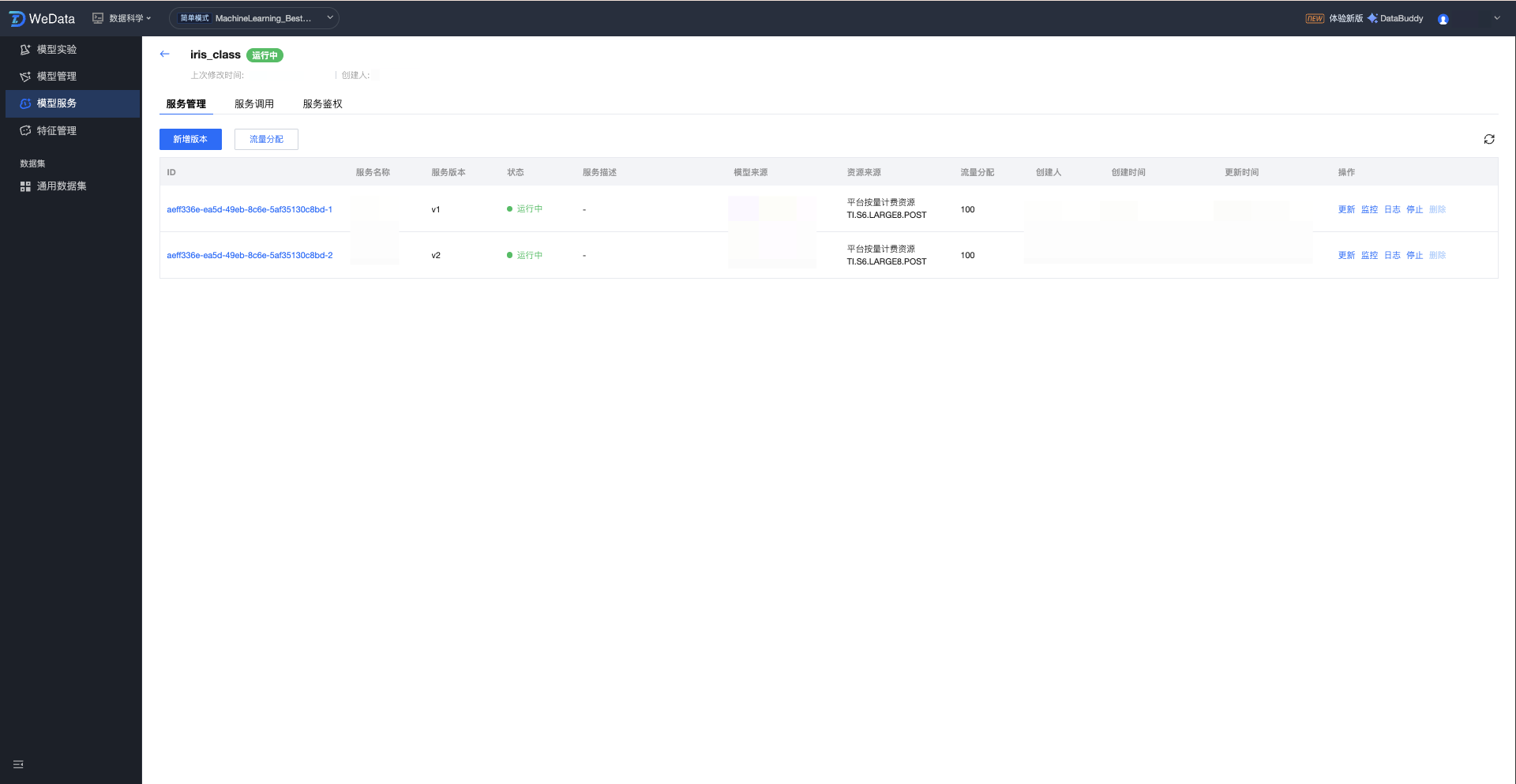
字段分类 | 描述 | 说明 | |
ID | | 服务版本实例的唯一标识符。 | 由系统自动生成的唯一字符串,用于精准定位和区分不同的服务版本。 |
服务名称 | | 该服务的具体名称。 | 方便进行多版本管理和灰度发布。 |
服务版本 | 该服务 | 该服务的版本号。 | 方便进行多版本管理和灰度发布。 |
状态 | | 服务版本当前的运行生命周期状态。 | 展示该版本运行状态:草稿 /运行中/已停止等。 |
服务描述 | | 对该服务版本的用途或特性进行说明。 | 帮助团队协作时理解各服务版本差异。 |
模型来源 | | 发布该服务所关联的底层模型资产。 | 展示该服务使用的是模型管理模块中哪个具体模型名称(如 ml_wine_db_wine_model)。 |
资源来源 | | 该版本运行所消耗的计算资源类型。 | 标识资源来自“平台按量计费资源”或“CVM 资源组”。 |
流量分配 | | 在多版本并存时,该版本接收的流量权重。 | 展示在 A/B 测试或灰度发布场景下,该版本所分配流量的百分比。 |
创建人 | | 初始化该服务版本的用户账号。 | 记录该版本的创建者,用于权限管理和操作审计。 |
创建时间 | | 该服务版本首次被创建的时间。 | 系统自动记录,方便按时间维度追踪模型迭代过程。 |
更新时间 | | 该服务版本最近一次更新的时间。 | 系统自动记录,方便按时间维度追踪模型迭代过程。 |
操作 | 更新 | 修改当前服务版本的配置信息。 | 查看服务版本详情,支持更新服务版本描述、资源配置等参数。 |
| 监控 | 查看该版本的实时性能指标。 | 访问 QPS、调用延迟、CPU/GPU 占用率等可视化监控视图。 |
| 日志 | 检索该服务实例的运行日志。 | 用于排查模型代码报错、输入输出异常等运行期问题。 |
| 启动/停止 | 手动控制服务实例的运行状态。 | 单击启动使服务组变更为运行状态,停止则释放服务资源。 |
| 删除 | 永久移除该服务版本。 | 操作不可逆,删除前需确认该版本已停止运行。 |
服务版本详情
服务版本详情页提供了该特定版本模型服务的全方位视图,涵盖了从基础配置、接入参数到底层容器实例的运行状态。用户可以通过此页面进行服务的生命周期管理(启动/停止)、实时监控查阅以及底层问题的深度排查。
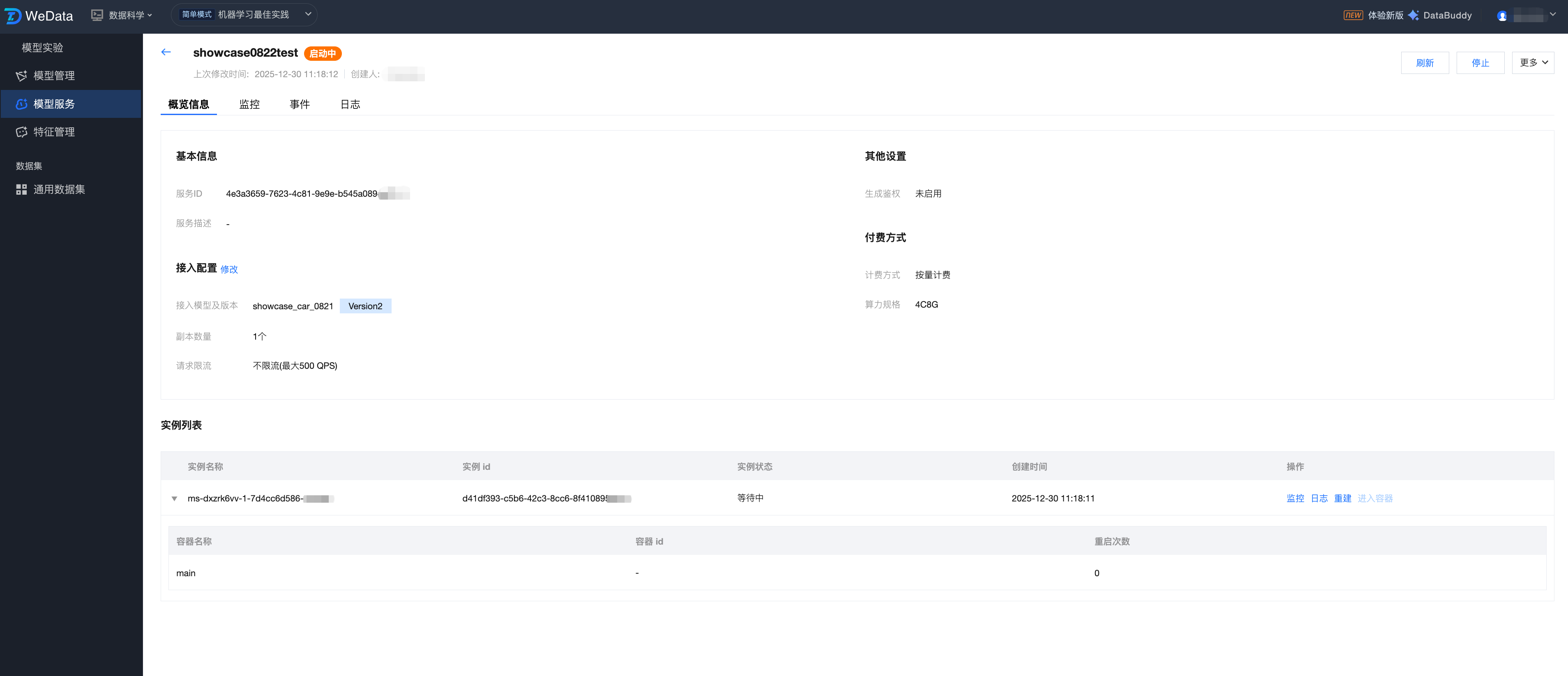
服务版本详情:
字段名称 | 描述 | 说明 |
服务名称 | 该服务的具体版本标识。 | 方便进行多版本管理和灰度发布。 |
服务 ID | 服务版本实例的唯一标识符。 | 由系统自动生成的唯一字符串,用于精准定位和区分不同的服务版本。 |
服务描述 | 对该服务版本的用途或特性进行说明。 | 帮助团队协作时理解各服务版本差异。 |
计费模式 | 资源的结算方式 | 如 Pay-as-you-go(按量计费),展示了模型运行的成本结构。 |
资源规格 | 分配给该版本的算力大小。 | 如 4C8G,决定了该版本能承载的模型复杂度及并发上限。 |
接入模型和版本 | 关联的模型资产详情。 | 显示模型管理中的模型名及具体 MLflow 版本号(如 Version2)。 |
副本数量 | 运行中的容器实例总数。 | 决定了服务的高可用性。多副本可分担流量并提供容灾保护。 |
请求限流 | 流量防护阈值。 | 展示 $QPS$ 上限。若达到阈值,系统将触发丢包或排队保护。 |
生成鉴权 | 服务安全控制开关。 | 显示是否开启了签名认证(API Key)。未开启则地址可直接访问。 |
运行实例详情:
字段/操作 | 描述 | 运维指导 |
实例名称 | 底层计算单元 (Pod) 的标识。 | 唯一标识一个运行中的微服务节点。 |
实例状态 | 实例的物理状态。 | Waiting 表示正在拉取镜像或等待调度;Running 表示服务已就绪。 |
重启次数 | 容器异常退出的频率。 | 核心排障指标。若次数不断增加,说明模型可能存在内存泄漏或代码报错。 |
监控 | 实例级监控入口。 | 查看单个实例的 $CPU/MEM$ 消耗,判断是否存在资源倾斜。 |
日志 | 容器标准输出流。 | 查看模型加载逻辑、预测报错堆栈的最直接手段。 |
重启 | 强制重启实例。 | 当实例出现僵死或响应极慢时,用于快速恢复服务的紧急手段。 |
访问容器 | 交互式终端。 | 允许进入容器内部执行命令,检查文件路径、权限或环境依赖。 |
服务版本监控
监控页面提供对模型服务运行状态的实时感知能力,从业务流量、系统资源、底层实例三个维度追踪服务表现。通过可视化图表帮助算法工程师和运维人员快速定位性能瓶颈、验证扩缩容效果并评估模型响应质量。
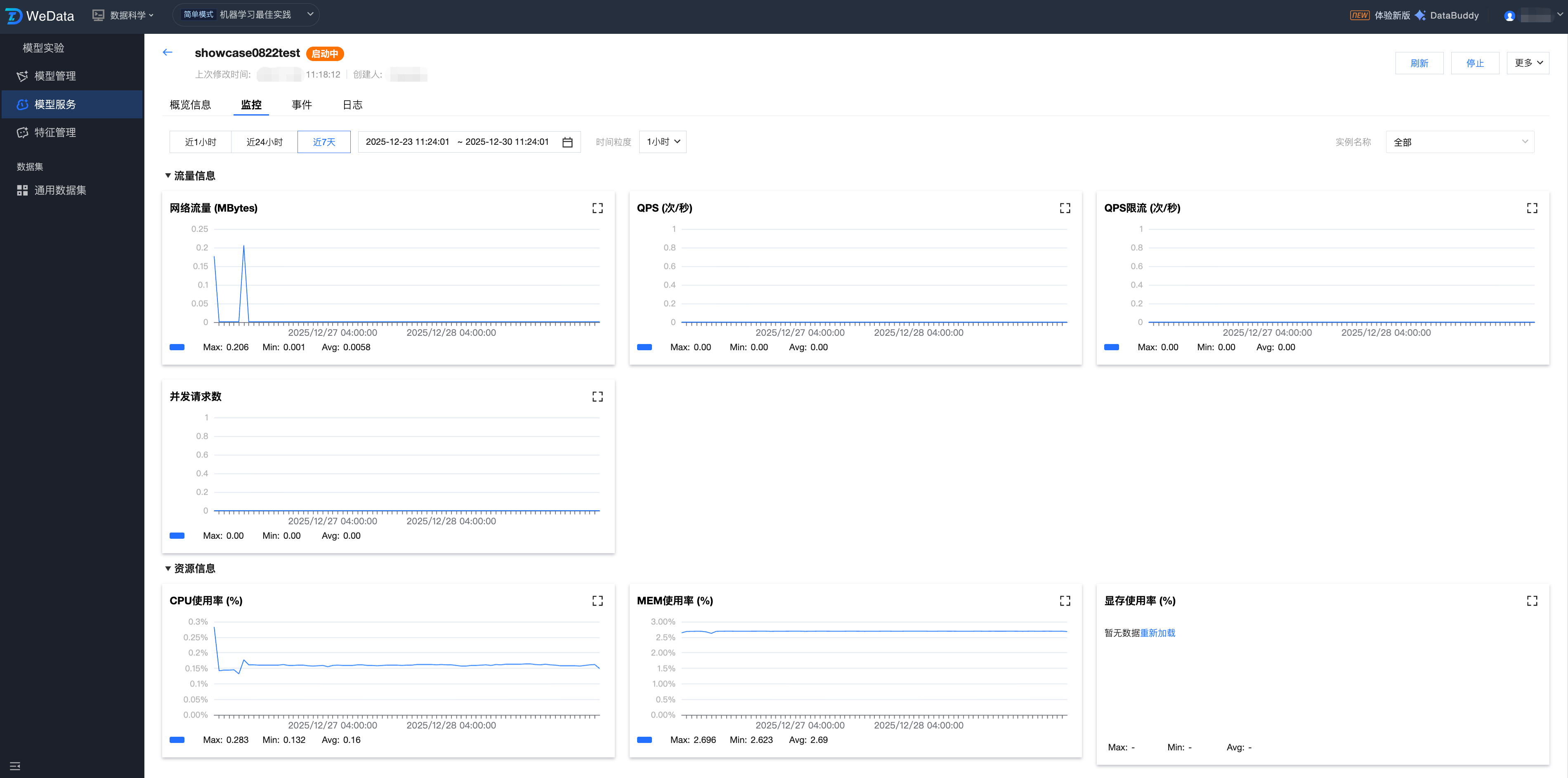
指标分类 | 核心指标项 | 业务价值说明 |
流量信息 | 网络流量、QPS、QPS 限流次数、并发请求数 | 评估 API 调用压力;并发请求数与限流次数是判断是否需要增加副本数量的关键信号。 |
资源信息 | CPU 使用率、MEM 使用率、显存使用率、GPU 使用率 | 监控底层硬件负载;包括显存使用率和 GPU 使用率 |
实例信息 | 实例总数量、运行中实例数量 | 直观展示服务的可用性,确认实际运行的容器数是否符合配置预期。 |
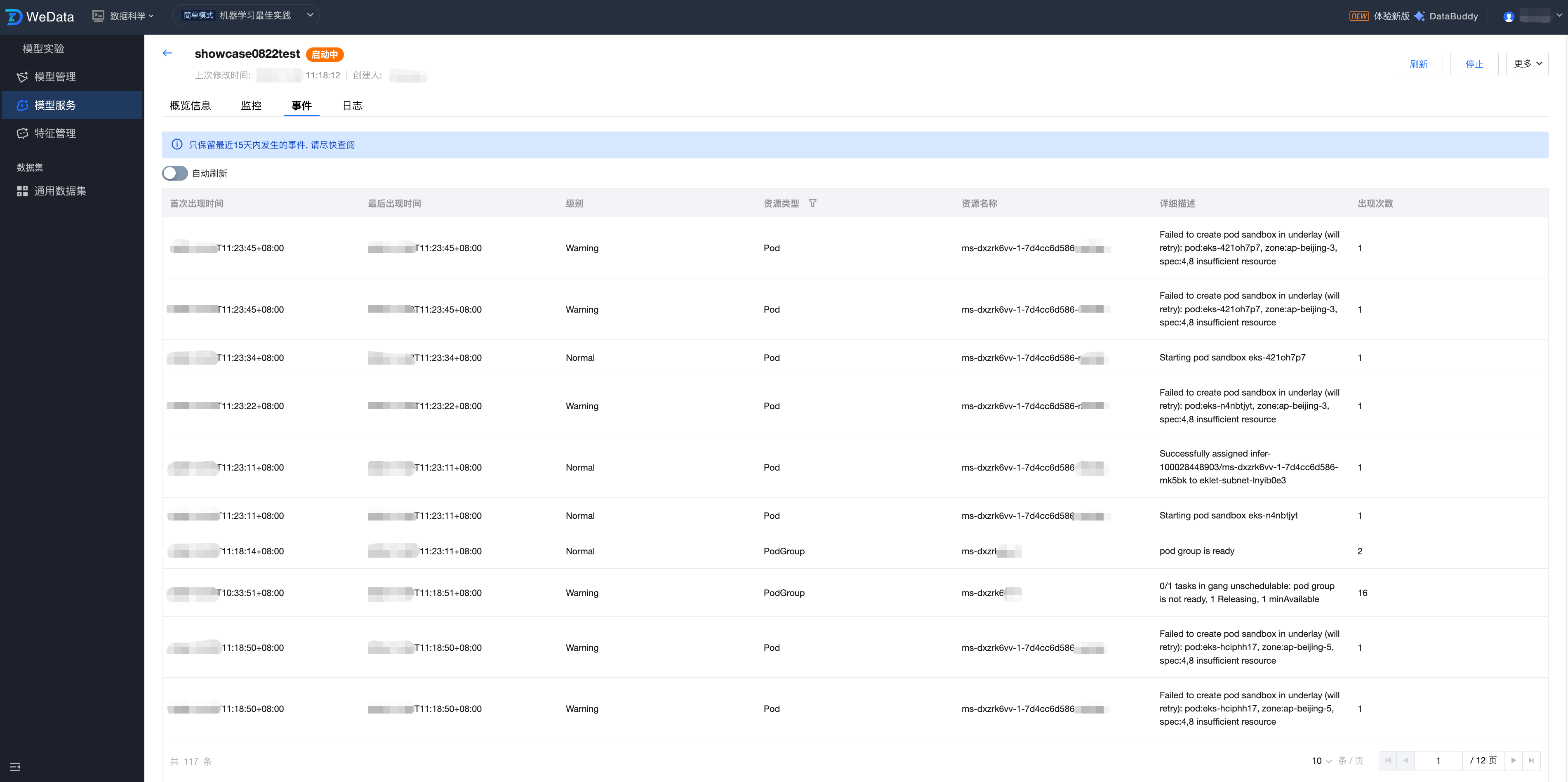
服务版本事件及日志
服务运行事件:
支持查看服务运行中的事件,包括首次出现时间、最后出现事件、级别、资源类型、资源名称、详细描述、出现次数等信息。
服务运行日志:
支持查看服务日志,并支持筛选实例、时间范围(1小时、24小时、7天、15天、自选时间段),支持自动刷新、搜索、日志换行等。
附录
模型监控最佳实践
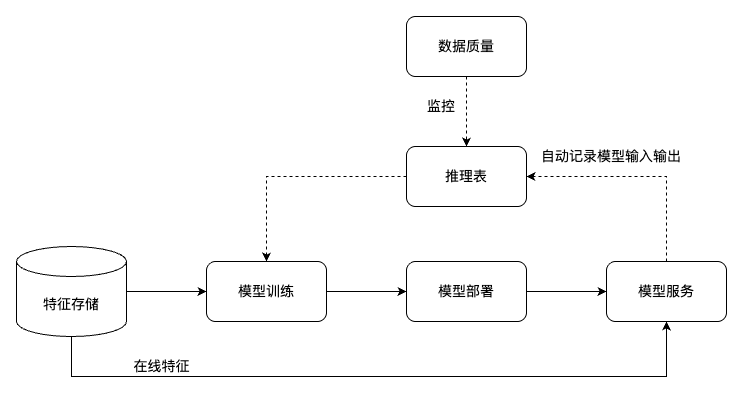
什么是推理表?
推理表是机器学习模型质量监控的重要工具,能够帮助运维团队实时掌握线上模型的运行状态和性能表现。如图所示的典型工作流程中,当在模型服务中开启推理表监控功能后,系统会自动捕获并记录模型推理过程中的关键信息,包括输入特征数据、模型输出结果、推理耗时等重要指标。
这些记录的数据会实时写入推理表中,为后续的质量分析提供数据基础。通过配合数据质量监控模块,可以对推理表中的数据进行多维度的质量检查,包括数据分布变化检测、模型预测准确率监控、异常值识别等。当监控系统发现模型质量出现下降趋势或异常情况时,会及时触发告警机制,提醒相关人员采取相应的优化措施,比如调整模型参数、更新训练数据集或重新训练模型。
整个流程形成了从数据采集、质量监控到问题响应的完整闭环,确保线上模型能够持续稳定地提供高质量的服务,同时为模型的持续优化和迭代提供了数据支撑。
推理表监控流程:
下图展示了推理表数据监控的完整技术流程。整个流程分为数据采集、数据处理和质量监控三个核心阶段:
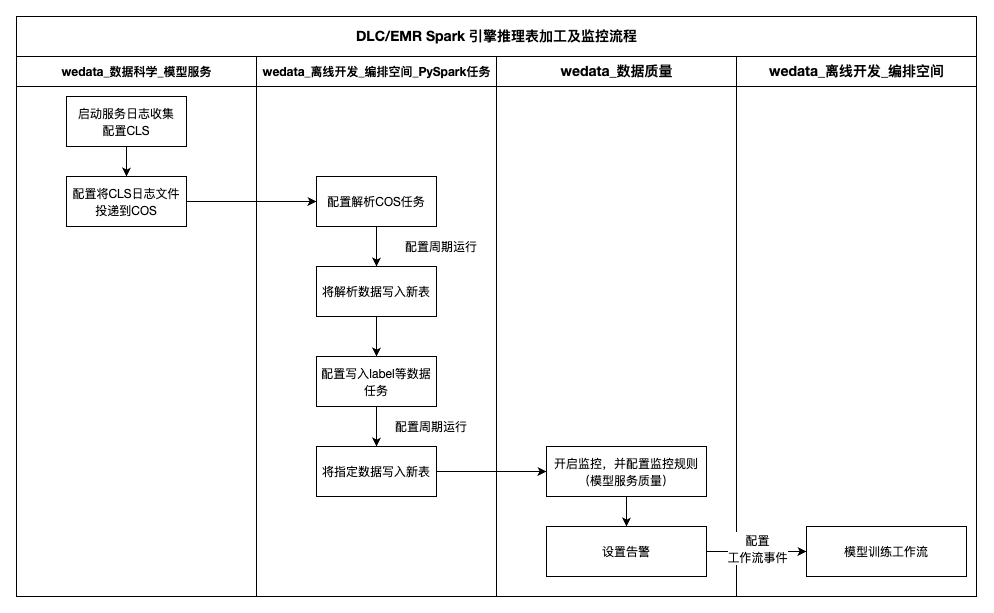
数据采集阶段:在模型服务部署时,需要开启服务日志收集功能和日志投递机制。系统会自动收集模型推理过程中产生的各类日志信息,并通过配置的投递策略将这些原始日志数据安全地传输到 COS 对象存储中。
数据处理阶段:当日志数据成功投递到 COS 后,可以在 WeData 离线开发的编排空间中配置 PySpark 数据加工任务。通过编写相应的数据处理逻辑,对原始推理日志进行清洗、转换和结构化处理,提取出模型输入特征、预测结果、响应时间、错误信息等关键指标,最终将经过标准化处理的推理数据写入到专门的推理表中。
质量监控阶段:基于推理表中的结构化数据,在 WeData 数据质量模块中配置模型服务质量监控规则,设置多层级的监控指标和告警阈值。当检测到模型性能异常、数据漂移或服务质量下降等问题时,系统会自动触发告警通知。更进一步,还可以根据告警事件的严重程度和类型,自动触发相应的模型重训练工作流,实现从问题发现到自动修复的智能化运维闭环。
数据采集:
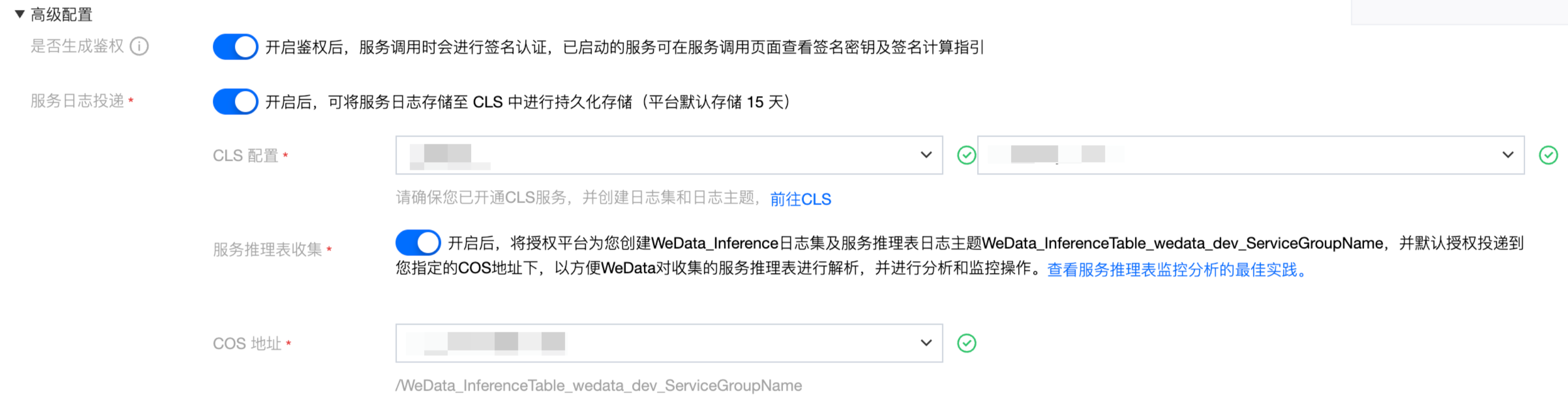
在创建模型服务时,可以通过高级配置选项启用完整的日志收集:
服务日志投递配置:首先需要开启服务日志投递功能,并指定目标日志集和对应的日志主题。一旦完成配置,模型服务产生的所有请求日志都会自动投递到指定的日志主题中。
推理表日志收集配置:同时开启服务推理表日志收集选项,并选择合适的 COS 存储桶作为数据存储目标。启用此功能后,系统会自动创建专门的日志加工任务,该任务负责对收集到的全量日志数据进行过滤和结构化处理并投递到预先指定的 COS 存储地址。
数据加工:
加工 COS 推理日志数据
这一步的目的是解析原始的模型输入输出信息,将非结构化的日志数据转换为标准化的特征数据和预测结果,并将处理后的数据写入到专门的推理表中,为后续的数据分析和标签关联工作提供结构化的数据基础。
技术实现方案:
流式处理架构:推荐采用 Spark Streaming 进行实时流式数据处理,这种方式能够持续监控 COS 桶中的新增日志文件,并实时进行数据解析和转换,确保推理数据的时效性。
增量处理机制:在数据写入过程中配置 Checkpoint 检查点机制,用于记录处理进度和状态信息。通过设置定时运行策略,系统可以自动识别和处理增量数据,避免重复处理已有数据,同时保证数据处理的完整性和一致性。
容错保障:Checkpoint 机制还提供了故障恢复能力,当处理任务因异常中断时,可以从最近的检查点恢复执行,确保数据处理的可靠性。
可根据不同引擎参考如下实现代码:
DLC Spark 引擎
"""该样例演示了如何使用 Spark Streaming 流式读取 COS 存储中的推理表,并对关键字段(特征、预测值)进行加工处理后写入 DLC 内表的处理过程。## 前提条件1. 确保该 DLC 引擎关联的 COS 访问凭证有访问推理表存储桶的权限。2. 确保模型服务开启了推理表监控。## 如何运行在修改教程中的参数后,在离线开发->编排空间中选择DLC PySpark任务运行。## 定时调度修改相应参数并调试完成后,您可以将该任务配置为定时执行,以便持续加工推理表数据。您还可以将加工后推理表数据与标签数据进行关联,生成包含标签数据的推理表,并在数据质量模块为推理表配置机器学习相关监控指标,持续监控模型质量。"""from pyspark.sql import DataFrame, SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql import types as Tfrom typing import Union, List, Dict, Optional, Sequence, Anyfrom pyspark.sql.streaming import StreamingQueryfrom pyspark.sql.types import (StructType, StructField, StringType, LongType, DoubleType,ArrayType, TimestampType)"""### 定义原始推理表数据格式原始推理表数据按照特定结构以JSON格式存储在用户指定的COS桶中,request_schema代表用户输入请求结构,response_schema代表模型输出结构,请根据模型服务对应的实际输入输出格式进行调整,其余字段为推理表固定结构,一般不需要调整。"""request_schema = StructType([StructField("client_request_id", StringType(), True),StructField("dataframe_split", StructType([StructField("columns", ArrayType(StringType()), True),StructField("data", ArrayType(ArrayType(DoubleType())), True),]), True),])request_metadata_schema = StructType([StructField("model_name", StringType(), True),StructField("model_version", StringType(), True),StructField("service_id", StringType(), True),])response_schema = StructType([StructField("predictions", ArrayType(LongType()), True),])schema = StructType([StructField("client_request_id", StringType(), True),StructField("execution_duration_ms", LongType(), True),StructField("request", request_schema, True),StructField("request_date", StringType(), True),StructField("request_metadata", request_metadata_schema, True),StructField("request_time", TimestampType(), True),StructField("requester", StringType(), True),StructField("response", response_schema, True),StructField("sampling_fraction", DoubleType(), True),StructField("status_code", LongType(), True),StructField("wedata_request_id", StringType(), True),])# 数据源参数SOURCE_PATH = "cosn://存储桶路径/" # 推理表存储路径CHECKPOINT_PATH = "cosn://存储桶路径/checkpoint" # check_point存储路径,建议与推理表存储路径一致# 结果表参数UNPACKED_TABLE_NAME = "DataLakeCatalog.test.unpacked_test_inference_table" # 结果表表名,需要为DLC内表的三段式表名称:<数据目录>.<数据库>.<数据表>MODEL_ID_COL = "model_id" # 结果表模型ID列,用于标识模型EXAMPLE_ID_COL = "example_id" # 结果表记录的唯一ID列,用户更新操作PREDICTION_COL = "prediction" # 预测值列名称FEATURE_COLUMNS = ["sepal_length", "sepal_width", "petal_length", "petal_width"] # 特征列名称,根据模型特征调整def process_requests(requests_raw: DataFrame) -> DataFrame:"""将请求特征展开为单独列,并与对应的预测结果配对Args:requests_raw: 待处理数据Return:处理后数据"""# 过滤成功请求requests_success = requests_raw.filter(F.col("status_code") == 200).drop("status_code")# 生成模型标识requests_identified = requests_success \\.withColumn(MODEL_ID_COL, F.concat(F.col("request_metadata").getItem("model_name"), F.lit("_"), F.col("request_metadata").getItem("model_version"))) \\.drop("request_metadata")# 展开特征列和预测结果# 1. 获取特征列名、特征数据、预测值requests_with_features = (requests_identified.withColumn("feature_columns", F.col("request.dataframe_split.columns")).withColumn("feature_data", F.col("request.dataframe_split.data")).withColumn("predictions", F.col("response.predictions")))# 2. 将每个数据行与对应的预测结果配对requests_exploded = (requests_with_features.withColumn("feature_prediction_pairs",F.arrays_zip(F.col("feature_data"), F.col("predictions"))).withColumn("feature_prediction_pairs",F.explode(F.col("feature_prediction_pairs"))).withColumn("feature_row", F.col("feature_prediction_pairs.feature_data")).withColumn(PREDICTION_COL, F.col("feature_prediction_pairs.predictions")))# 3. 动态创建特征列requests_with_feature_cols = requests_explodedfor i, col_name in enumerate(FEATURE_COLUMNS):requests_with_feature_cols = (requests_with_feature_cols.withColumn(col_name, F.col("feature_row")[i]))# 4. 添加记录唯一ID,便于后续进行upsert操作requests_with_example_id = requests_with_feature_cols \\.withColumn(EXAMPLE_ID_COL, F.expr("uuid()"))# 5. 清理临时列requests_processed = (requests_with_example_id.drop("feature_columns", "feature_data", "feature_prediction_pairs", "feature_row", "predictions", "request", "response"))return requests_processeddef create_table(spark: SparkSession,table_name: str,df: Optional[DataFrame] = None,partition_expr: str = None,description: Optional[str] = None,):"""创建dlc内表Args:spark: SparkSession 实例table_name: 表全称(格式:数据目录.数据库.数据表)df: 初始数据(用于推断schema)partition_expr: 分区列(优化存储查询)description: 表描述Raises:ValueError: 创建异常时抛出"""# 推断表schematable_schema = df.schema# 构建列定义columns_ddl = []for field in table_schema.fields:data_type = field.dataType.simpleString().upper()col_def = f"`{field.name}` {data_type}"if not field.nullable:col_def += " NOT NULL"columns_ddl.append(col_def)# 构建建表语句ddl = f"""CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(columns_ddl)})USING icebergPARTITIONED BY ({partition_expr})TBLPROPERTIES ('comment'= '{description or ''}','format-version'= '2','write.metadata.previous-versions-max'= '100','write.metadata.delete-after-commit.enabled'= 'true','smart-optimizer.inherit' = 'none','smart-optimizer.written.enable' = 'enable')"""# 打印sqlprint(f"create table ddl: {ddl}\\n")# 执行DDLtry:spark.sql(ddl)except Exception as e:raise ValueError(f"Failed to create table: {str(e)}") from eprint(f"create table {table_name} done")spark = SparkSession.builder.appName("Operate DB Example").getOrCreate()# 构建流式 DataFramedf = (spark.readStream.format("json").schema(schema).load(SOURCE_PATH))# 处理流式数据unpacked_df = process_requests(df)# 创建结果表,以request_time作为分区字段,按天分区,可以按照模型服务请求量进行调整create_table(spark, UNPACKED_TABLE_NAME, unpacked_df, 'days(request_time)')# 写入数据query = unpacked_df.writeStream \\.format("parquet") \\.outputMode("append") \\.option("checkpointLocation", CHECKPOINT_PATH) \\.trigger(once=True) \\.toTable(UNPACKED_TABLE_NAME)query.awaitTermination()spark.sql(f"select * from {UNPACKED_TABLE_NAME}").show(10)
EMR Spark 引擎
"""该样例演示了如何使用 Spark Streaming 流式读取 COS 存储中的推理表,并对关键字段(特征、预测值)进行加工处理后写入 EMR Hive 表的处理过程。## 前提条件1. 确保该 DLC 引擎关联的 COS 访问凭证有访问推理表存储桶的权限。2. 确保模型服务开启了推理表监控。## 如何运行在修改教程中的参数后,在离线开发->编排空间中选择EMR PySpark任务运行。## 定时调度修改相应参数并调试完成后,您可以将该任务配置为定时执行,以便持续加工推理表数据。您还可以将加工后推理表数据与标签数据进行关联,生成包含标签数据的推理表,并在数据质量模块为推理表配置机器学习相关监控指标,持续监控模型质量。"""from pyspark.sql import DataFrame, SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql import types as Tfrom typing import Union, List, Dict, Optional, Sequence, Anyfrom pyspark.sql.streaming import StreamingQueryfrom pyspark.sql.types import (StructType, StructField, StringType, LongType, DoubleType,ArrayType, TimestampType)"""### 定义原始推理表数据格式原始推理表数据按照特定结构以JSON格式存储在用户指定的COS桶中,request_schema代表用户输入请求结构,response_schema代表模型输出结构,请根据模型服务对应的实际输入输出格式进行调整,其余字段为推理表固定结构,一般不需要调整。"""request_schema = StructType([StructField("client_request_id", StringType(), True),StructField("dataframe_split", StructType([StructField("columns", ArrayType(StringType()), True),StructField("data", ArrayType(ArrayType(DoubleType())), True),]), True),])request_metadata_schema = StructType([StructField("model_name", StringType(), True),StructField("model_version", StringType(), True),StructField("service_id", StringType(), True),])response_schema = StructType([StructField("predictions", ArrayType(LongType()), True),])schema = StructType([StructField("client_request_id", StringType(), True),StructField("execution_duration_ms", LongType(), True),StructField("request", request_schema, True),StructField("request_date", StringType(), True),StructField("request_metadata", request_metadata_schema, True),StructField("request_time", TimestampType(), True),StructField("requester", StringType(), True),StructField("response", response_schema, True),StructField("sampling_fraction", DoubleType(), True),StructField("status_code", LongType(), True),StructField("wedata_request_id", StringType(), True),])# 数据源参数SOURCE_PATH = "cosn://存储桶路径/" # 推理表存储路径CHECKPOINT_PATH = "cosn://存储桶路径/checkpoint" # check_point存储路径,建议与推理表存储路径一致# 结果表参数UNPACKED_TABLE_NAME = "testdb.unpacked_test_inference_table" # 结果表表名,需要为hive表名称:<数据库>.<数据表>MODEL_ID_COL = "model_id" # 结果表模型ID列,用于标识模型EXAMPLE_ID_COL = "example_id" # 结果表记录的唯一ID列,用户更新操作PREDICTION_COL = "prediction" # 预测值列名称FEATURE_COLUMNS = ["sepal_length", "sepal_width", "petal_length", "petal_width"] # 特征列名称,根据模型特征调整def process_requests(requests_raw: DataFrame) -> DataFrame:"""将请求特征展开为单独列,并与对应的预测结果配对Args:requests_raw: 待处理数据Return:处理后数据"""# 过滤成功请求requests_success = requests_raw.filter(F.col("status_code") == 200).drop("status_code")# 生成模型标识requests_identified = requests_success \\.withColumn(MODEL_ID_COL, F.concat(F.col("request_metadata").getItem("model_name"), F.lit("_"), F.col("request_metadata").getItem("model_version"))) \\.drop("request_metadata")# 展开特征列和预测结果# 1. 获取特征列名、特征数据、预测值requests_with_features = (requests_identified.withColumn("feature_columns", F.col("request.dataframe_split.columns")).withColumn("feature_data", F.col("request.dataframe_split.data")).withColumn("predictions", F.col("response.predictions")))# 2. 将每个数据行与对应的预测结果配对requests_exploded = (requests_with_features.withColumn("feature_prediction_pairs",F.arrays_zip(F.col("feature_data"), F.col("predictions"))).withColumn("feature_prediction_pairs",F.explode(F.col("feature_prediction_pairs"))).withColumn("feature_row", F.col("feature_prediction_pairs.feature_data")).withColumn(PREDICTION_COL, F.col("feature_prediction_pairs.predictions")))# 3. 动态创建特征列requests_with_feature_cols = requests_explodedfor i, col_name in enumerate(FEATURE_COLUMNS):requests_with_feature_cols = (requests_with_feature_cols.withColumn(col_name, F.col("feature_row")[i]))# 4. 添加记录唯一ID,便于后续进行upsert操作requests_with_example_id = requests_with_feature_cols \\.withColumn(EXAMPLE_ID_COL, F.expr("uuid()"))# 5. 清理临时列requests_processed = (requests_with_example_id.drop("feature_columns", "feature_data", "feature_prediction_pairs", "feature_row", "predictions", "request", "response"))return requests_processeddef create_table(spark: SparkSession,table_name: str,df: Optional[DataFrame] = None,partition_expr: str = None,description: Optional[str] = None,):"""创建hive表Args:spark: SparkSession 实例table_name: hive表全称(格式:数据库.数据表)df: 初始数据(可选,用于推断schema)partition_expr: 分区列(优化存储查询)description: 表描述Raises:ValueError: 创建异常时抛出"""# 推断表schematable_schema = df.schemapart_col_nam = partition_expr.split(' ')[0]# 构建列定义columns_ddl = []for field in table_schema.fields:# 建表时过滤掉分区列if field.name == part_col_nam:continuedata_type = field.dataType.simpleString().upper()col_def = f"`{field.name}` {data_type}"if not field.nullable:col_def += " NOT NULL"columns_ddl.append(col_def)# 构建建表语句ddl = f"""CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(columns_ddl)})PARTITIONED BY ({partition_expr})TBLPROPERTIES ('comment'= '{description or ''}')"""# 打印sqlprint(f"create table ddl: {ddl}\\n")# 执行DDLtry:spark.sql(ddl)except Exception as e:raise ValueError(f"Failed to create table: {str(e)}") from eprint(f"create table {table_name} done")def write_batch_to_hive(batch_df: DataFrame, batch_id: int, table_name: str):# 控制小文件:按分区列重分区out_df = batch_df.repartition(8, "dt")out_df.write.mode("append").format("hive").saveAsTable(table_name,partitionBy="dt")spark = SparkSession.builder.appName("Operate DB Example").enableHiveSupport().getOrCreate()# 构建流式 DataFramedf = (spark.readStream.format("json").schema(schema).load(SOURCE_PATH))# 处理流式数据unpacked_df = process_requests(df)# 插入分区列requests_with_dt = (unpacked_df.withColumn("dt", F.substring(F.col("request_date"), 1, 10)) # 提取 YYYY-MM-DD 格式的日期)# 创建结果表create_table(spark, UNPACKED_TABLE_NAME, unpacked_df, 'dt STRING')# 设置Hive动态分区spark.sql("SET hive.exec.dynamic.partition=true")spark.sql("SET hive.exec.dynamic.partition.mode=nonstrict")# 分批写入结果表query = (requests_with_dt.writeStream.outputMode("append").option("checkpointLocation", CHECKPOINT_PATH).trigger(once=True).foreachBatch(lambda df, id: write_batch_to_hive(df, id, UNPACKED_TABLE_NAME)).start())query.awaitTermination()# 查询结果数据spark.sql(f"select * from {UNPACKED_TABLE_NAME}").show(10)
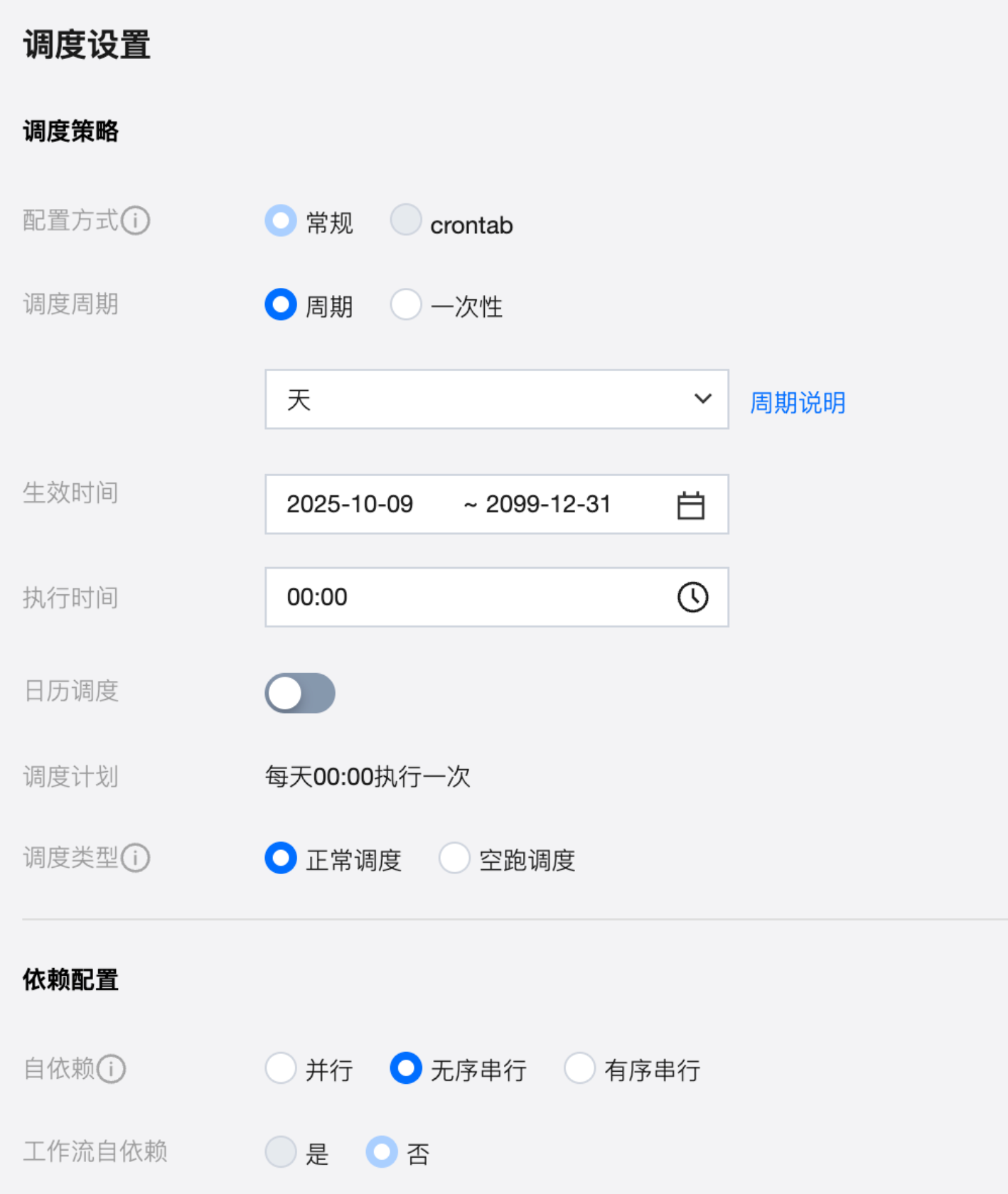
配置任务周期运行
调试好任务,确保手动执行成功并写入处理好的数据后,可以在调度设置中配置任务为定期执行,建议配置为至少一周一次,以持续监控模型质量。
配置关联标签数据任务
为了构建完整的模型监控和评估体系,需要进一步将这些推理数据与真实的标签数据进行关联,从而获得包含输入特征、模型预测结果和实际标签的完整推理表数据集。这种标签关联过程是模型效果评估的关键步骤,通过对比预测值与真实标签,可以计算模型的准确率、召回率等核心性能指标,进而实现对模型质量的量化监控和趋势分析。标签数据的获取通常需要结合业务系统的反馈机制或人工标注流程。根据您使用的数据处理引擎和具体业务场景的不同,可以参考相应的数据加工代码实现来完成标签数据的关联操作,形成支持全面模型监控的完整数据基础。
DLC Spark 引擎
from pyspark.sql import DataFrame, SparkSessionfrom typing import Union, List, Dict, Optional, Sequence, Any# 待关联标签的推理表表名:需要为DLC内表的三段式表名称:<数据目录>.<数据库>.<数据表>UNPACKED_TABLE_NAME = "DataLakeCatalog.test.unpacked_test_inference_table"# 标签数据表配置:可以为多个,每个表中必须包含结构(<表名>, <join是需要保留的字段名列表>, <join时用于等值条件连接的字段列表>)JOIN_TABLES = [('DataLakeCatalog.test.test_label_table', ['label', 'example_id'], ['example_id'])]# 关联标签数据后的推理表表名FULLY_QUALIFIED_TABLE_NAME = "DataLakeCatalog.test.test_fully_qualified_table_name"# 窗口大小: 限制每次运行此Notebook脚本最多处理多长时间的数据,早于此窗口的数据如果尚未被处理,将被忽略,为了保证所有数据都被处理,调度周期应该小于此窗口大小PROCESSING_WINDOW_DAYS = 10# 插入结果表时的主键字段MERGE_COLS = ["request_time", "example_id"]def create_table(spark: SparkSession,table_name: str,df: Optional[DataFrame] = None,partition_expr: str = None,description: Optional[str] = None,):"""创建dlc内表Args:spark: SparkSession 实例table_name: 表全称(格式:数据目录.数据库.数据表)df: 初始数据(用于推断schema)partition_expr: 分区列(优化存储查询)description: 表描述Raises:ValueError: 创建异常时抛出"""# 推断表schematable_schema = df.schema# 构建列定义columns_ddl = []for field in table_schema.fields:data_type = field.dataType.simpleString().upper()col_def = f"`{field.name}` {data_type}"if not field.nullable:col_def += " NOT NULL"columns_ddl.append(col_def)# 构建建表语句ddl = f"""CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(columns_ddl)})USING icebergPARTITIONED BY ({partition_expr})TBLPROPERTIES ('comment'= '{description or ''}','format-version'= '2','write.metadata.previous-versions-max'= '100','write.metadata.delete-after-commit.enabled'= 'true','smart-optimizer.inherit' = 'none','smart-optimizer.written.enable' = 'enable')"""# 打印sqlprint(f"create table ddl: {ddl}\\n")# 执行DDLtry:spark.sql(ddl)except Exception as e:raise ValueError(f"Failed to create table: {str(e)}") from eprint(f"create table {table_name} done")def upsert_table(spark: SparkSession,target_table_name: str,merge_cols: list,df: DataFrame,):"""使用upsert方式向目标表写入数据Args:spark: SparkSession 实例target_table_name: 结果表全称(格式:数据目录.数据库.数据表)merge_cols: 更新时的主键df: 待更新数据Raises:ValueError: 写入异常时抛出"""merge_condition = " AND ".join([f"target.{col} = source.{col}" for col in merge_cols])# 创建临时视图df.createOrReplaceTempView("source_data")# 执行MERGE操作merge_sql = f"""MERGE INTO {target_table_name} AS targetUSING source_data AS sourceON {merge_condition}WHEN MATCHED THEN UPDATE SET *WHEN NOT MATCHED THEN INSERT *"""# 执行DMLtry:spark.sql(merge_sql)except Exception as e:raise ValueError(f"Failed to create table: {str(e)}") from eprint(f"upsert table {target_table_name} done")spark = SparkSession.builder.appName("Operate DB Example").getOrCreate()# 每次读取 PROCESSING_WINDOW_DAYS的数据requests_processed = spark.table(UNPACKED_TABLE_NAME) \\.filter(f"CAST(request_time AS DATE) >= current_date() - (INTERVAL {PROCESSING_WINDOW_DAYS} DAYS)")if requests_processed.count() > 0:# 关联标签表for table_name, preserve_cols, join_cols in JOIN_TABLES:join_data = spark.table(table_name)requests_processed = requests_processed.join(join_data.select(preserve_cols), on=join_cols, how="left")# 创建结果表create_table(spark, FULLY_QUALIFIED_TABLE_NAME, requests_processed, 'days(request_time)')# 写入结果表upsert_table(spark, FULLY_QUALIFIED_TABLE_NAME, MERGE_COLS, requests_processed)spark.sql(f"select * from {FULLY_QUALIFIED_TABLE_NAME}").show(10)
EMR Spark 引擎
from pyspark.sql import DataFrame, SparkSessionfrom typing import Union, List, Dict, Optional, Sequence, Any# 待关联标签的推理表表名:需要为Hive表名称:<数据库>.<数据表>UNPACKED_TABLE_NAME = "testdb.unpacked_test_inference_table"# 标签数据表配置:可以为多个,每个表中必须包含结构(<表名>, <join是需要保留的字段名列表>, <join时用于等值条件连接的字段列表>)JOIN_TABLES = [('testdb.test_label_table', ['label', 'example_id'], ['example_id'])]# 关联标签数据后的推理表表名FULLY_QUALIFIED_TABLE_NAME = "testdb.test_fully_qualified_table_name"# 窗口大小: 限制每次运行此Notebook脚本最多处理多长时间的数据,早于此窗口的数据如果尚未被处理,将被忽略,为了保证所有数据都被处理,调度周期应该小于此窗口大小PROCESSING_WINDOW_DAYS = 10def create_table(spark: SparkSession,table_name: str,df: Optional[DataFrame] = None,partition_expr: str = None,description: Optional[str] = None,):"""创建hive表Args:spark: SparkSession 实例table_name: hive表全称(格式:数据库.数据表)df: 初始数据(可选,用于推断schema)partition_expr: 分区列(优化存储查询)description: 表描述Raises:ValueError: 创建异常时抛出"""# 推断表schematable_schema = df.schemapart_col_nam = partition_expr.split(' ')[0]# 构建列定义columns_ddl = []for field in table_schema.fields:# 建表时过滤掉分区列if field.name == part_col_nam:continuedata_type = field.dataType.simpleString().upper()col_def = f"`{field.name}` {data_type}"if not field.nullable:col_def += " NOT NULL"columns_ddl.append(col_def)# 构建建表语句ddl = f"""CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(columns_ddl)})PARTITIONED BY ({partition_expr})TBLPROPERTIES ('comment'= '{description or ''}')"""# 打印sqlprint(f"create table ddl: {ddl}\\n")# 执行DDLtry:spark.sql(ddl)except Exception as e:raise ValueError(f"Failed to create table: {str(e)}") from eprint(f"create table {table_name} done")def partition_overwrite(spark, source_df, target_table):""""""try:# 检查数据是否为空if source_df.count() == 0:print(f"警告: 没有数据需要写入到 {target_table}")return# 显示要覆盖的分区partitions = source_df.select("dt").distinct().collect()partition_list = [row.dt for row in partitions]print(f"将要覆盖的分区: {partition_list}")# 设置参数并写入spark.sql("SET hive.exec.dynamic.partition=true")spark.sql("SET hive.exec.dynamic.partition.mode=nonstrict")spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")source_df.repartition(8, "dt") \\.write \\.mode("overwrite") \\.format("hive") \\.saveAsTable(target_table)print(f"成功覆盖 {len(partition_list)} 个分区到表 {target_table}")except Exception as e:print(f"写入表 {target_table} 时出错: {str(e)}")raisespark = SparkSession.builder.appName("Operate DB Example").getOrCreate()# 每次读取 PROCESSING_WINDOW_DAYS分区的数据,处理后进行覆盖写入requests_processed = spark.table(UNPACKED_TABLE_NAME) \\.filter(f"dt >= date_format(current_date() - INTERVAL {PROCESSING_WINDOW_DAYS} DAYS, 'yyyy-MM-dd')")for table_name, preserve_cols, join_cols in JOIN_TABLES:join_data = spark.table(table_name)requests_processed = requests_processed.join(join_data.select(preserve_cols), on=join_cols, how="left")create_table(spark, FULLY_QUALIFIED_TABLE_NAME, requests_processed, 'dt STRING')partition_overwrite(spark, requests_processed, FULLY_QUALIFIED_TABLE_NAME)spark.sql(f"select * from {FULLY_QUALIFIED_TABLE_NAME}").show(10)
配置任务周期运行
确保关联标签任务手动执行成功并写入数据后,可以配置任务为周期执行,配置方式参考步骤2,建议执行周期大于等于步骤2配置的 COS 数据加工任务周期。
模型服务资源组创建(CVM 资源组)
我们在部署模型服务时,需要配置资源来源,选择 CVM 资源组下拉列表会展示当前项目的可用资源组,可以自由配置 CPU 和内存的用量,是否使用 GPU 开关。
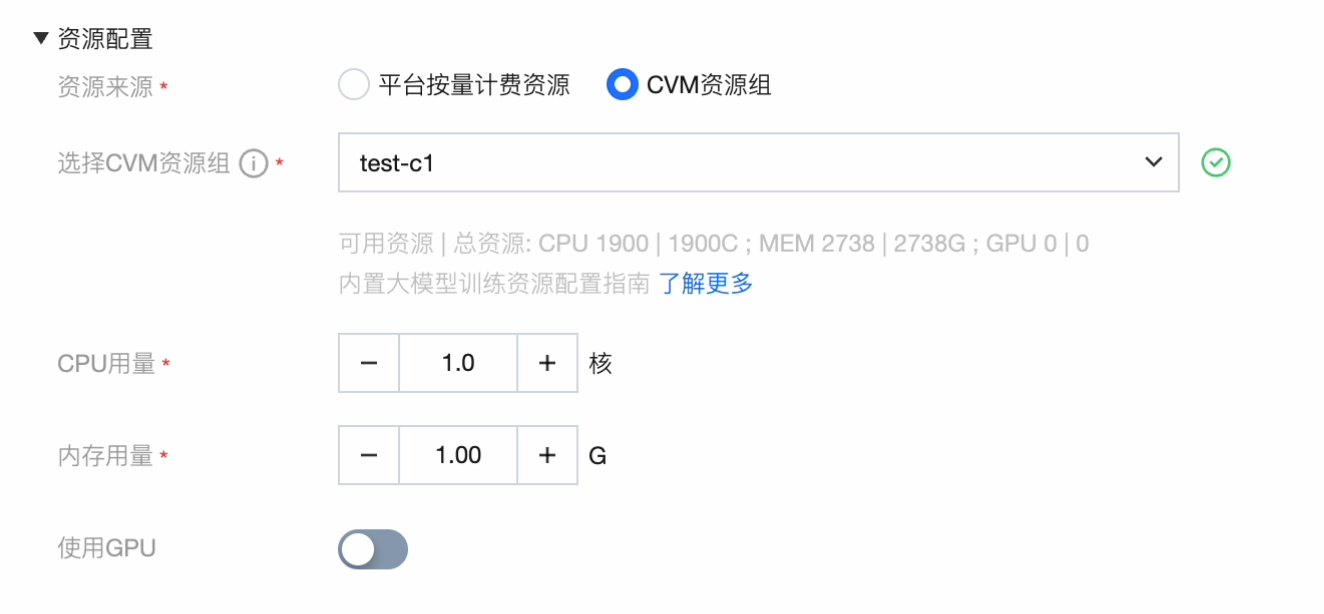
单击管理 CVM 资源组,跳转到资源组列表页:
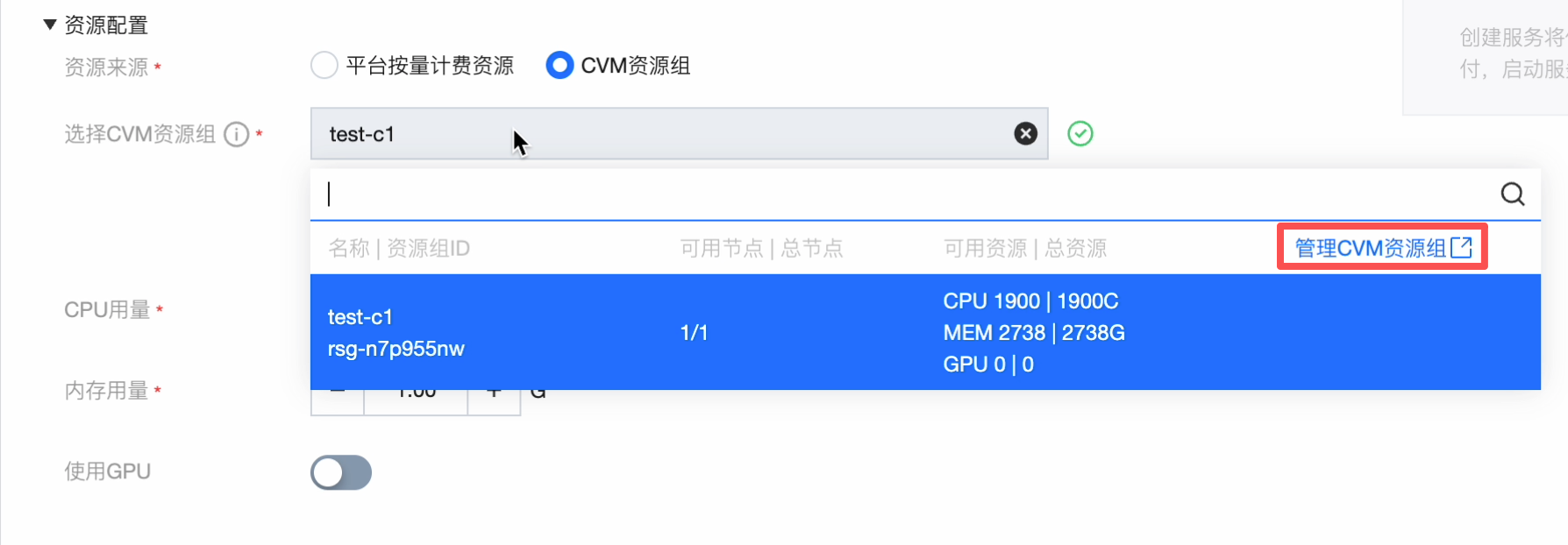
查看模型服务 > 资源组列表,单击操作可以关联项目:
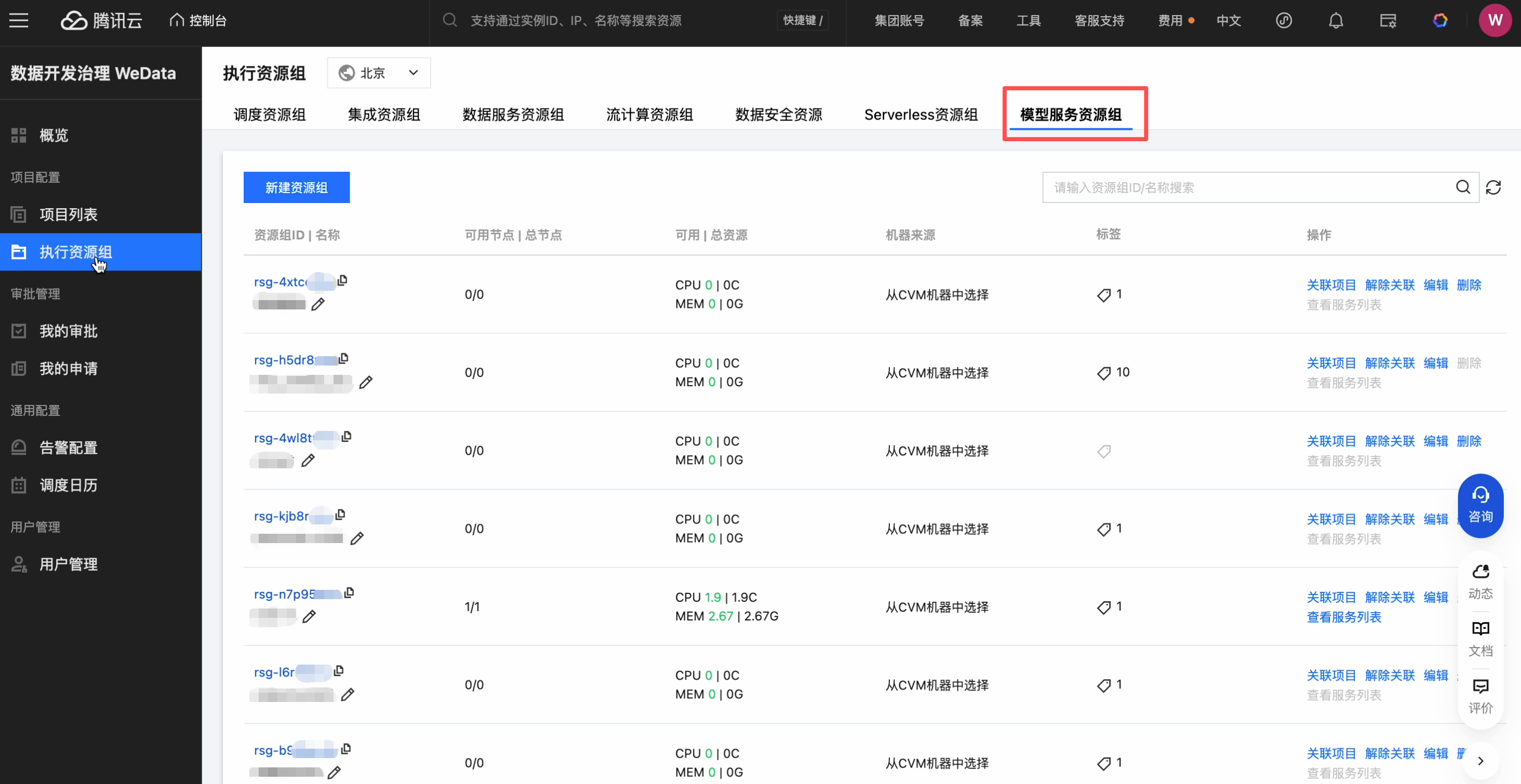
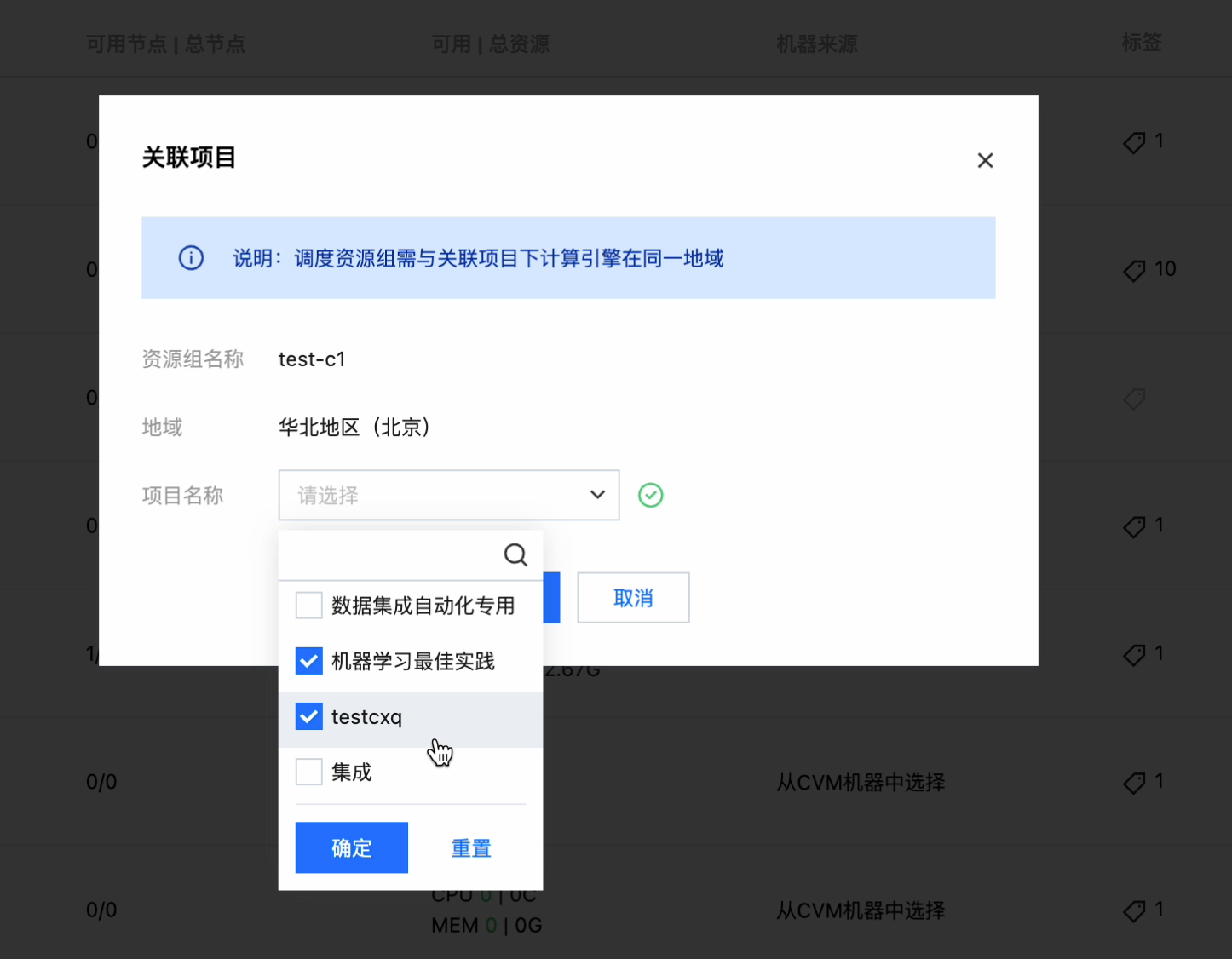
选择操作 > 关联项目,可以下拉筛选项目名称,并完成关联:
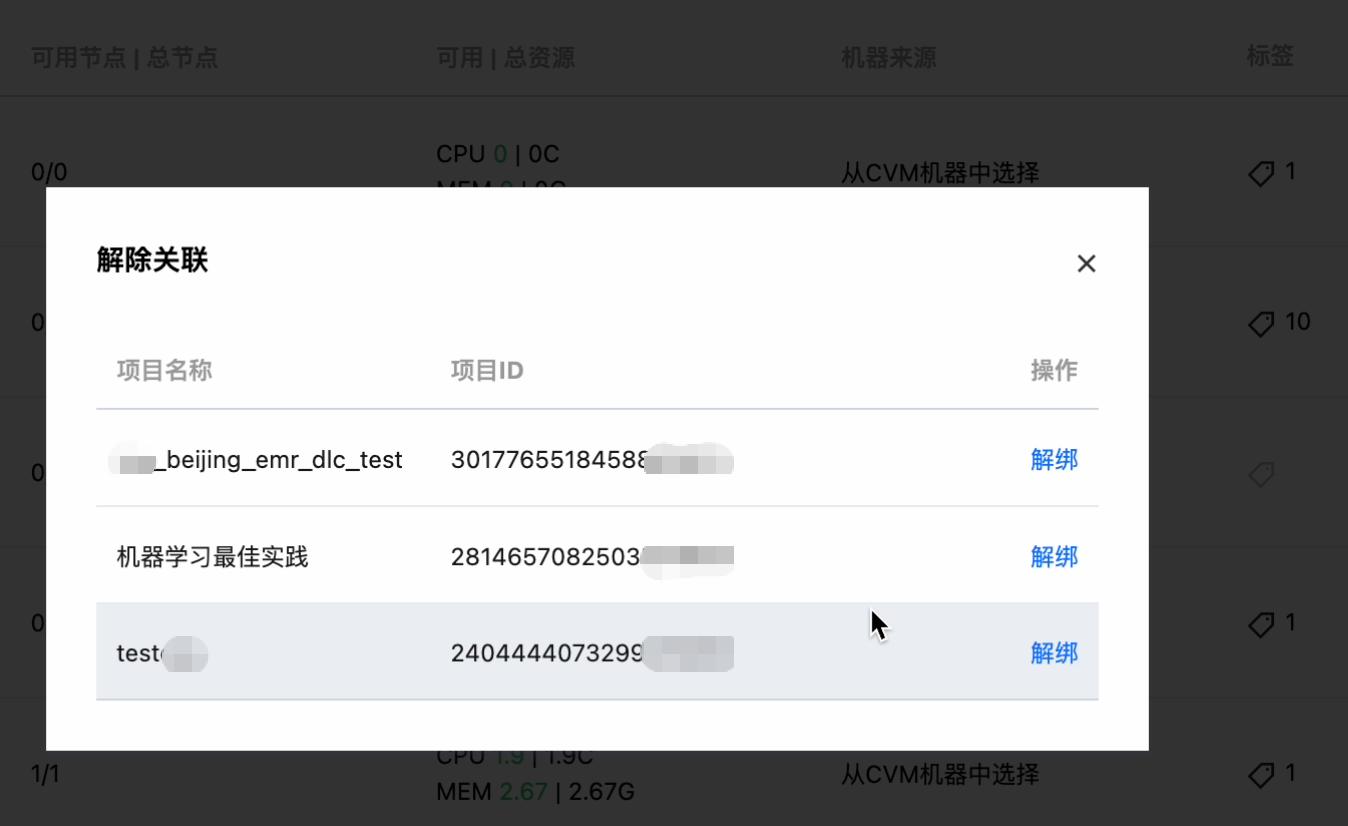
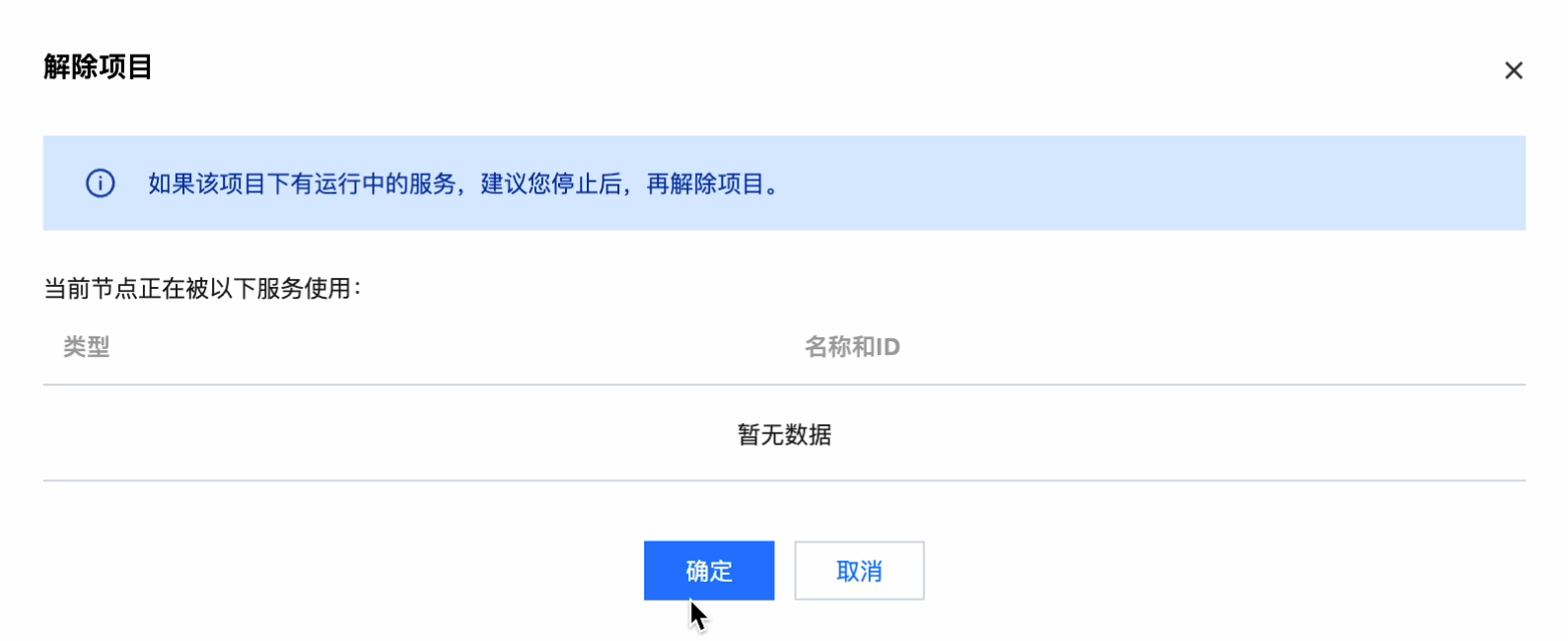
单击操作 > 解除绑定,可以对该资源组的关联项目进行解绑:
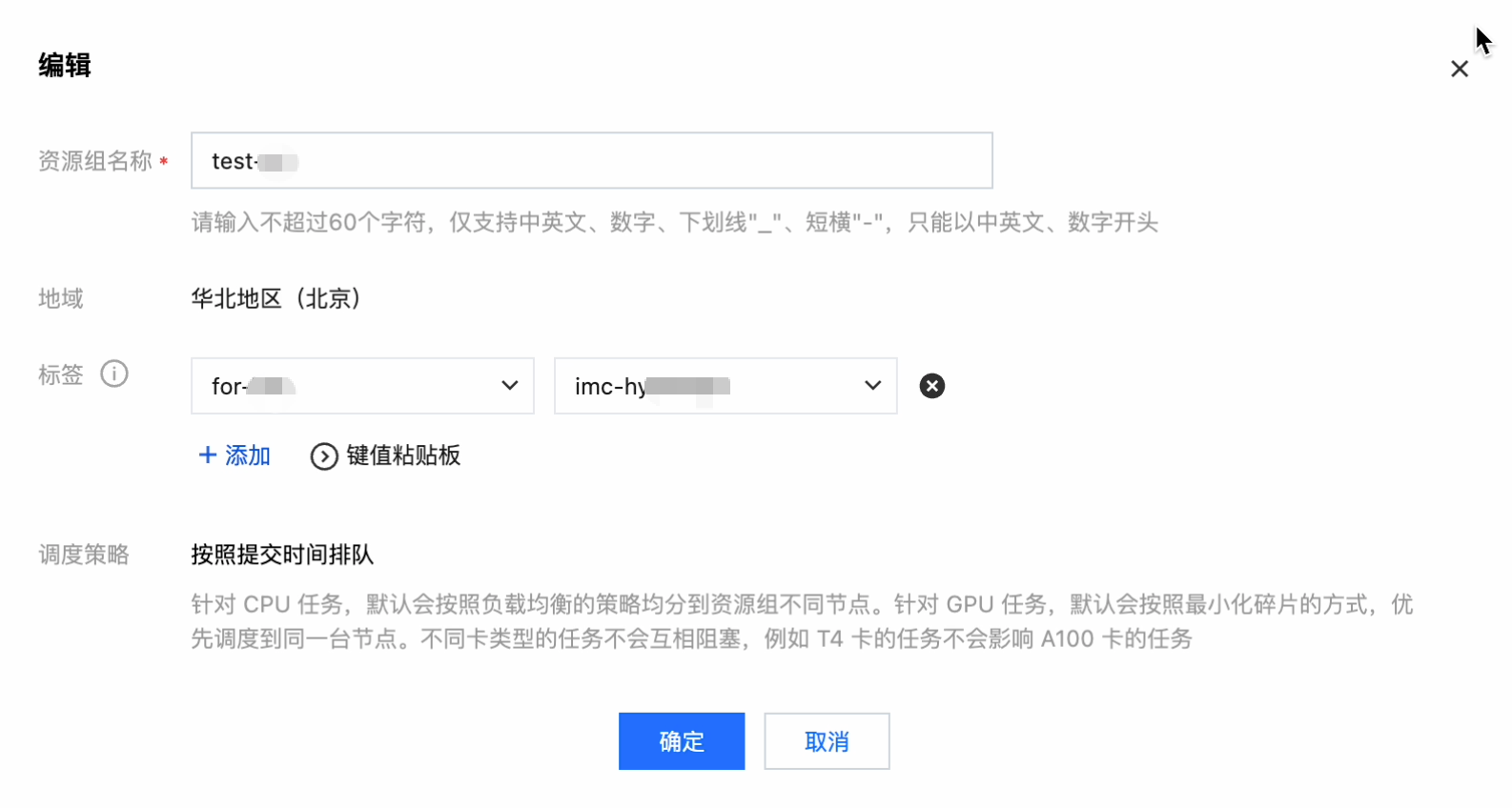
单击操作 > 编辑,可以对该资源组的标签、名称等字段进行修改:
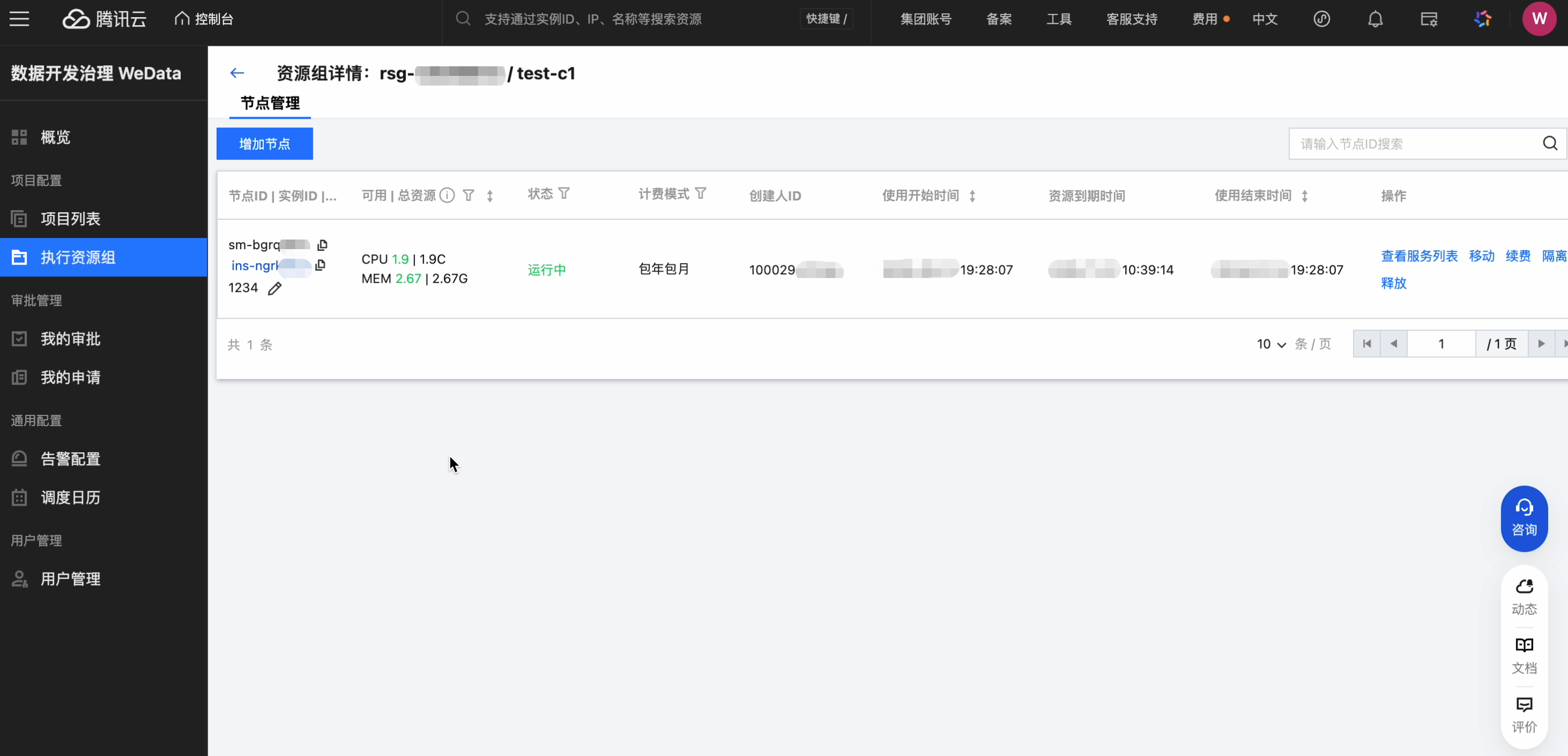
单击资源组名称,进入该资源组详情页:
可以查看节点 ID,可用资源,运行状态,计费模式,时间等信息,支持查看服务列表、移动、续费、隔离、释放等操作。
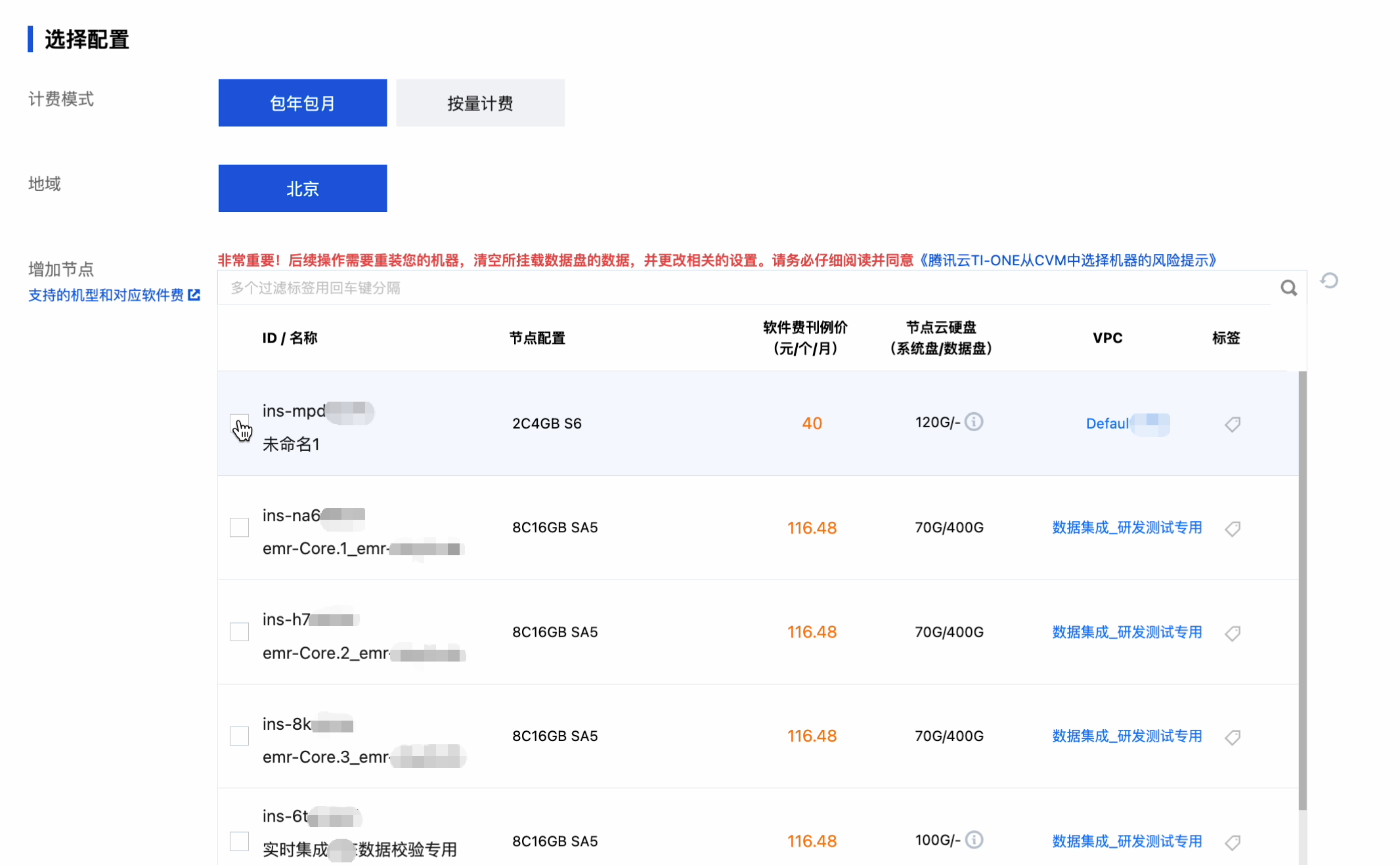
单击新增节点,跳转到付费购买页面:
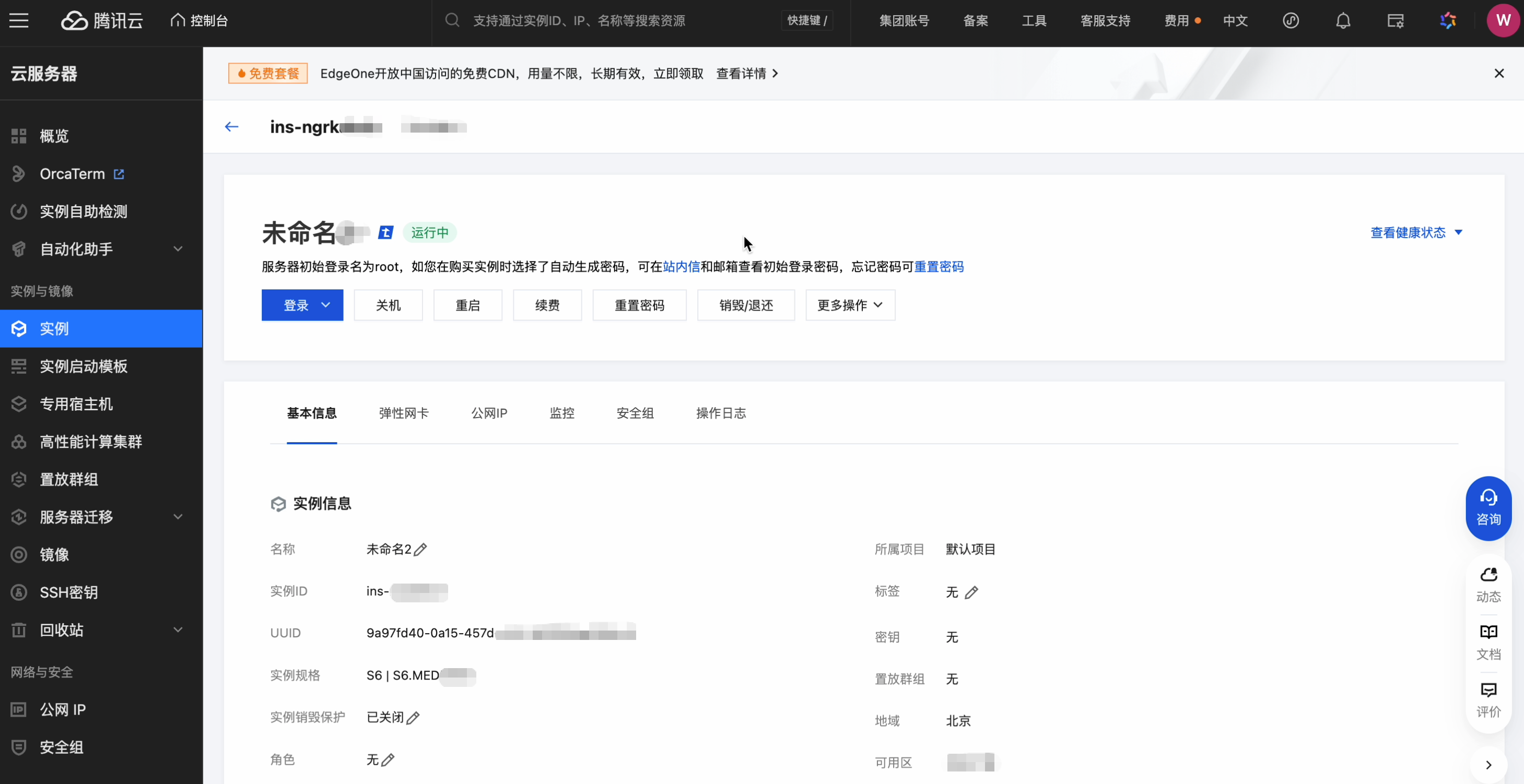
单击实例 ID 跳转到实例详情页,支持对该实例进行登录,关机,重启,续费,重置密码,销毁/退还等操作,展示该实例相关信息
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback