查看系统内置模版
Download
聚焦模式
字号
系统内置了76个规则模板,可直接使用,使用前请仔细了解各模板的适用场景。
查看模板列表
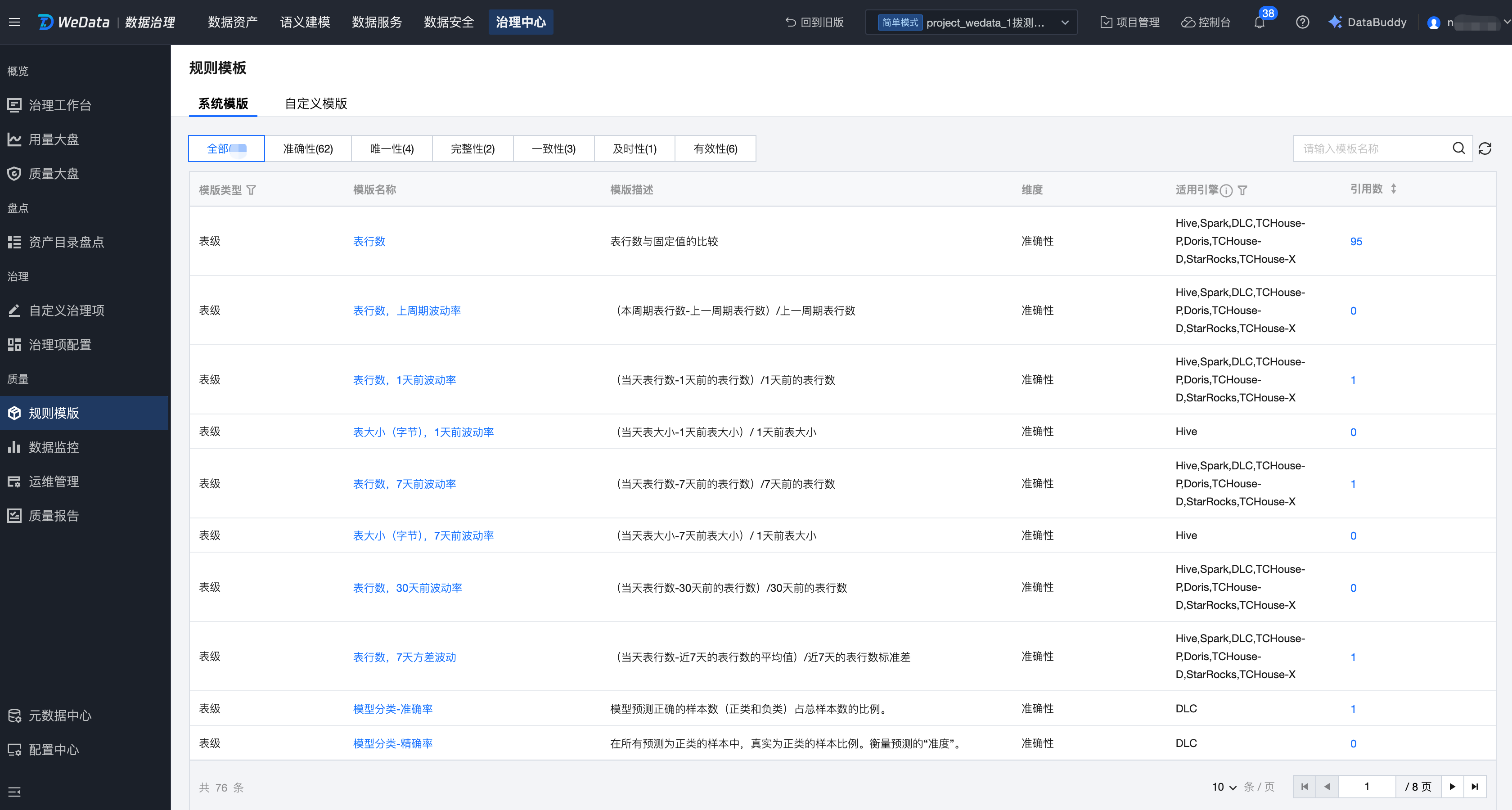
在规则模板管理页面,可以查看系统模板列表。
用户可基于模板名称、描述关键词、类型、维度、适用引擎进行搜索/筛选查询。同时用户可在自定义模板界面进行创建和批量管理操作。
字段 | 详情 |
模板类型 | 当前支持表级、字段级2种模板类型,支持筛选 |
模板名称 | 模板的命名 |
模板描述 | 对该模板规则具体执行逻辑、公式的详细描述 |
维度 | 准确性、唯一性、完整性、一致性、及时性、有效性,支持筛选 |
适用引擎 | 该模板适用的引擎类型,有: Hive、Spark、DLC、TCHouse-D、 TCHouse-P、TCHouse- X、Doris 、StarRocks,支持筛选引擎 |
引用数 | 当前被引用关联的规则数量,支持排序 |
模板分布
从准确性、唯一性、完整性、一致性、及时性、有效性等维度提供了76个模板,如下:
普通表模板
监控对象 | 规则维度 | 计算项 | 计算子项 | 描述 | 数值型 | 数值-波动率型 | 数值-标准分型 | 其他 | ||||||||
| | | | | 固定值 | 数值范围 | 上周期 | 1天前 | 7天前 | 30天前 | 7天 | 30天 | 空/唯一/重复 | 格式匹配 | 枚举范围 | 值大小 |
表级 | 准确性 | 表行数 | | 计算数据行数 | ✅ | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | - | - | - | - |
| | 表大小(字节) | | 计算数据表大小(仅支持Hive表) | ✅ | - | - | ✅ | ✅ | - | - | - | - | - | - | - |
| 及时性 | 数据产出及时性 | | 计算数据行数,如果行数=0,则认为没有产出数据 | ✅ = 0 | - | - | - | - | - | - | - | - | - | - | - |
字段级 | 准确性 | 字段数值 | 平均值 | 计算数值平均值 | ✅ | - | - | ✅ | ✅ | ✅ | ✅ | ✅ | - | - | - | - |
| | | 汇总值 | 计算数值汇总值 | ✅ | - | - | ✅ | ✅ | ✅ | ✅ | ✅ | - | - | - | - |
| | | 中位数 | 计算数值中位数 | ✅ | - | - | ✅ | ✅ | ✅ | ✅ | ✅ | - | - | - | - |
| | | 最小值 | 计算数值最小值 | ✅ | - | - | ✅ | ✅ | ✅ | ✅ | ✅ | - | - | - | - |
| | | 最大值 | 计算数值最大值 | ✅ | - | - | ✅ | ✅ | ✅ | ✅ | ✅ | - | - | - | - |
| 唯一性 | 字段唯一值 | 唯一值个数 | 校验唯一值 | - | - | - | - | - | - | - | - | ✅ | - | - | - |
| | | 唯一值个数/总行数 | | - | - | - | - | - | - | - | - | ✅ | - | - | - |
| | 字段重复值 | 重复值个数 | 校验重复值 | - | - | - | - | - | - | - | - | ✅ | - | - | - |
| | | 重复值个数/总行数 | | - | - | - | - | - | - | - | - | ✅ | - | - | - |
| 完整性 | 字段空值 | 空值个数 | 校验空值 | - | - | - | - | - | - | - | - | ✅ | - | - | - |
| | | 空值个数/总行数 | | - | - | - | - | - | - | - | - | ✅ | - | - | - |
| 有效性 | 手机号格式 | 不合法个数 | 正则校验,符合中国大陆手机号格式 | - | - | - | - | - | - | - | - | - | ✅ | - | - |
| | | 不合法个数/总行数 | | - | - | - | - | - | - | - | - | - | ✅ | - | - |
| | 邮箱格式 | 不合法个数 | 正则校验,符合邮箱格式 | - | - | - | - | - | - | - | - | - | ✅ | - | - |
| | | 不合法个数/总行数 | | - | - | - | - | - | - | - | - | - | ✅ | - | - |
| | 身份证格式 | 不合法个数 | 正则校验,符合中国大陆身份证格式 | - | - | - | - | - | - | - | - | - | ✅ | - | - |
| | | 不合法个数/总行数 | | - | - | - | - | - | - | - | - | - | ✅ | - | - |
| 一致性 | 字段数据范围 | 数值范围 | 检测数值是否在数值范围内 | - | ✅ | - | - | - | - | - | - | - | - | - | - |
| | | 枚举范围 | 检测字符值是否在枚举值内 | - | - | - | - | - | - | - | - | - | - | ✅ | - |
| | 字段数据相关性 | | 与另一个库表的某个字段比较大小 | - | - | - | - | - | - | - | - | - | - | - | ✅ |
推理表模板
针对模型推理表,从准确性维度,提供了模型漂移、模型分类、模型回归三种类型20个模板,如下:
说明:
目前仅适用于DLC引擎。
监控对象 | 维度 | 指标名称 | 适用特征类型 | 含义&计算方法 |
模型推理表 | 分类模型 | 准确率 | - | 正确预测的比例, True Positive(TP,真正):实际为i类且预测为i类。如:label为A类,且predict为A类。  |
| | 精确率 | - | 预测为正类的样本中实际为正类的比例,TP/(TP+FP) True Positive(TP,真正):实际为正类且预测为正类。如:label为A类,且predict为A类。 False Positive(FP,假正):实际为负类但预测为正类。如:label不为A类,且predict为A类。 False Negative(FN,假负):实际为正类但预测为负类。如:label为A类,且predict不为A类。 True Negative(TN,真负):实际为负类且预测为负类。如:label不为A类,且predict不为A类。  |
| | 召回率 | - | 为正类的样本中被正确预测的比例,TP/(TP+FN) True Positive(TP,真正):实际为正类且预测为正类。如:label为A类,且predict为A类。 False Positive(FP,假正):实际为负类但预测为正类。如:label不为A类,且predict为A类。 False Negative(FN,假负):实际为正类但预测为负类。如: label为A类,且predict不为A类。 True Negative(TN,真负):实际为负类且预测为负类。如:label不为A类,且predict不为A类。 如果是多分类:   |
| | F1分数 | - | 精确率和召回率的调和平均数。2*(precision*recall)/(precision+recall)= 等价于 F1-Score = 2 * TP / (2 * TP + FP + FN) |
| | 预测奇偶性 | - | 要求模型在不同群体(如性别、种族)中,预测为正类的样本里真实正类的比例(即正预测值,PPV)应相等。其核心思想是:模型在预测正类时,对不同群体的正确率应相同,即被正确预测为正类的正样本比例应一致。 测算指定群体属性的PPV,比如分别抽取出所有白人、黑人的信贷审批结果进行计算ppv: 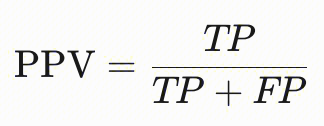 |
| | 预测平等性 | - | 用于衡量模型在不同群体(如性别、种族等敏感属性划分的群体)中假正例率(FPR)的一致性。其核心思想是:模型在预测负类时,对不同群体的误判率应相同,即被错误预测为正类的负样本比例应一致。 测算指定群体属性的FPR,比如分别抽取出所有白人、黑人的信贷审批结果进行计算FPR: 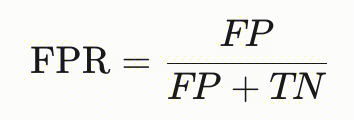 |
| | 机会均等性 | - | 用于衡量模型在不同群体(如性别、种族等敏感属性划分的群体)中真正例率(TPR)的一致性。其核心思想是:模型对“实际为正类”的样本,在不同群体中的预测正类概率应相同,确保优势群体和弱势群体获得同等机会。 测算指定群体属性的TPR,比如分别抽取出所有白人、黑人的信贷审批结果进行计算TPR: 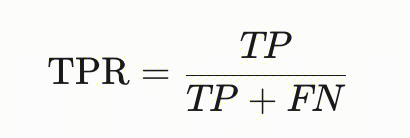 |
| | 统计奇偶性 | - | 用于衡量模型在不同群体(如性别、种族等敏感属性划分的群体)中预测结果的分布均衡性。其核心思想是:模型对不同群体的预测为正类的概率应相同,即无论群体属性如何,获得正向预测的机会均等。 测算指定群体属性的统计奇偶性,比如分别抽取出所有白人、黑人的信贷审批结果进行计算selection rate:  如白人的selection rate=白人被预测为正类的样本数/白人总数 |
| 回归模型 | 均方误差(MSE) | - | 取值为0到无穷,数值越低越好。反映预测值与真实值的偏离程度,值越小精度越高。yi为 label值,另一个带上三角的为predict值。 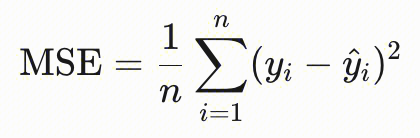 |
| | 均方根误差(RMSE) | - | 取值为0到无穷,数值越低越好。MSE的平方根,对异常值敏感,值越小精度越高。yi为label值,另一个带上三角的为predict值。 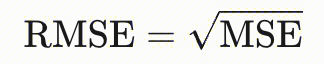 |
| | 平均绝对误差(MAE) | - | 取值为0到无穷,数值越低越好,直接衡量预测误差的绝对值。yi为 label值,另一个带上三角的为predict值。 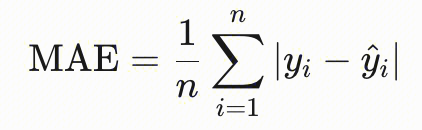 |
| | 平均绝对百分比误差(MAPE) | - | 取值为0到无穷,数值越低越好,对低估误差(预测值 < 真实值)的惩罚高于高估误差。yi为 label值,另一个带上三角的为predict值。 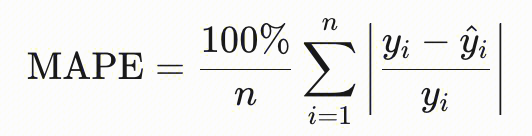 |
| | 决定系数r2分数 | - | r2分数介于0和1之间,越接近于1,回归拟合效果越好。yi为 label值,另一个带上三角的为predict值。 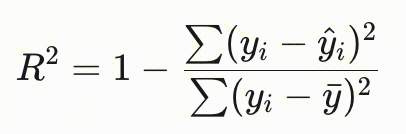 |
| 模型漂移 | 卡方检验 | 类别 | 是一种用于检测数据分布是否发生显著变化的统计方法,尤其适用于分类变量或离散数据的分布比较。其核心思想是通过比较实际观测频数与理论期望频数之间的差异,判断这种差异是否由随机波动引起,还是反映了真实的分布偏移。 Oi:第i类别的观测频数。 Ei:第i类别的期望频数(基于基准分布) 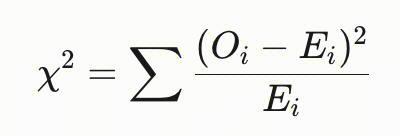 |
| | KS检验 | 数值 | 是一种非参数统计方法,用于检测两组数据的分布是否存在显著差异。 KS检验通过比较两组数据的累积分布函数(CDF),计算其最大垂直距离(D值)作为统计量,判断分布是否一致: F1(x) 和 F2(x) 分别为两组数据的CDF。 D值越大,分布差异越显著;p值<0.05时拒绝原假设(即认为存在分布偏移) 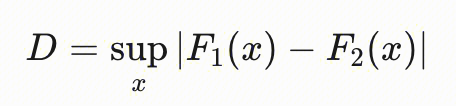 |
| | 总变差距离 | 类别 | 是衡量两个概率分布差异的核心指标,尤其适用于检测数据分布偏移。  |
| | 切比雪夫距离 | 类别 | 是一种用于衡量两个概率分布或数据样本间最大单维差异的度量方法,尤其适用于检测极端值或局部显著偏移。  |
| | 詹森-香浓散度 | 类别 | 是衡量两个概率分布之间差异的对称化度量,基于Kullback-Leibler(KL)散度构建。它在分布偏移检测中常用于量化数据分布的变化程度,尤其在机器学习模型监控和数据漂移分析中具有重要应用。  |
| | 瓦瑟斯坦距离 | 数值 | 计算两个数值分布之间的偏移。  |
| | 群体稳定性指数 | 数值 | 是衡量两个群体(如训练集与测试集、不同时间段的样本)分布差异的指标,广泛应用于风控模型监控和特征稳定性评估。  |
使用说明
名词 | 解释 | |
监控对象 | 表级 | 当监控对象为普通表时,可以监控表行数、表大小、表数据产出及时性(等同于表行数)。 当监控对象为模型推理表时,可以从模型漂移、模型分类、模型回归三个维度监控表的多个特征。 |
| 字段级 | 当监控对象为字段级时,可以监控字段的数值(包含平均值、最大值、最小值、中位数、汇总值),字段的值格式(手机号、邮箱、身份证号)、字段是否为空。 |
规则维度 | - | 规则维度是为了计算质量分,体现不同类型的规则的质量占比。 在系统中内置了6个规则维度:准确性、唯一性、完整性、一致性、及时性、有效性。 |
校验方式 | 数值型 | 主要包括数值大小比较,数值范围比较。 |
| 波动率型 | 名词解释: 波动率型用于体现数值的波动,即相比某个时间点,本次上升/下降幅度。 计算公式: 波动率 = 本次扫描结果/某时间点扫描结果 * 100%。 说明: 波动率的计算结果为百分比,使用波动率模板时必须指定分区。 示例1:7天前周期波动 当指定分区后,基准值选择7天前的数据时,如果计算结果为:100%, 则表示本次分区数据,相比7天前那一次的分区数据增加了1倍。 示例2:上周期波动: 当指定分区后,基准值选择上次运行周期,并将规则关联生产调度任务(例如:某个离线开发任务),当计算结果为:100% 则表示本次离线开发任务运行结束后的统计数据,相比上一次运行结束后的统计数据增加了1倍。 示例3:周期波动率+默认周期: 在使用周期波动率模板设置质量规则时,并设置了默认周期,如7天前。如果此规则未关联生产调度任务,当计算结果为:100%。 则表示本次分区数据,相比7天前那一次的分区数据增加了1倍。即:当期数据,与7天前的数据做对比。 |
| 标准分型 (方差波动) | 名词解释: 标准分是一个重要的统计概念,可以体现某个值是否处于可信的区间范围内。 如果计算结果过大或过小,则有极大的概率说明此数据是异常值。 计算公式: 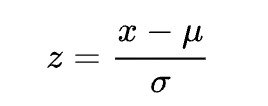 说明: 标准分的计算结果为无单位小数,可体现数据在数据集中是否异常。 一般认为标准分绝对值大于3时,则为异常值,此时正常可能性仅为0.28% [-1,1]:正常可能性:68.26% [-2,2]:正常可能性:95.44% [-3,3]:正常可能性:99.72% 不属于[-3,3]:正常可能性:0.28% |
| 其他 | 不限制校验字段类型。 空/唯一/重复:统计空值/唯一值/重复值的个数或比例; 格式匹配:统计不符合格式的个数或比例; 枚举范围:统计不在枚举值内的个数; 说明: 此处填写的是预期值,当字段不在范围内时,会触发告警。 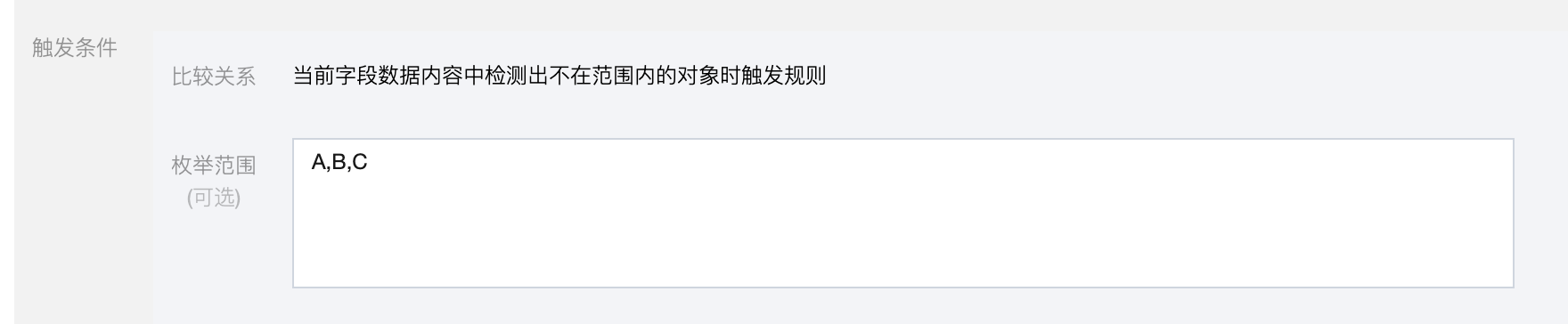 字段相关性:统计与另一个库表字段值是否相同。 比较关系:大于、小于、等于; 目标数据:库表、字段、过滤条件; 关联条件:两表的关联字段。 说明: 对比表需要与检测表数据一一对应。 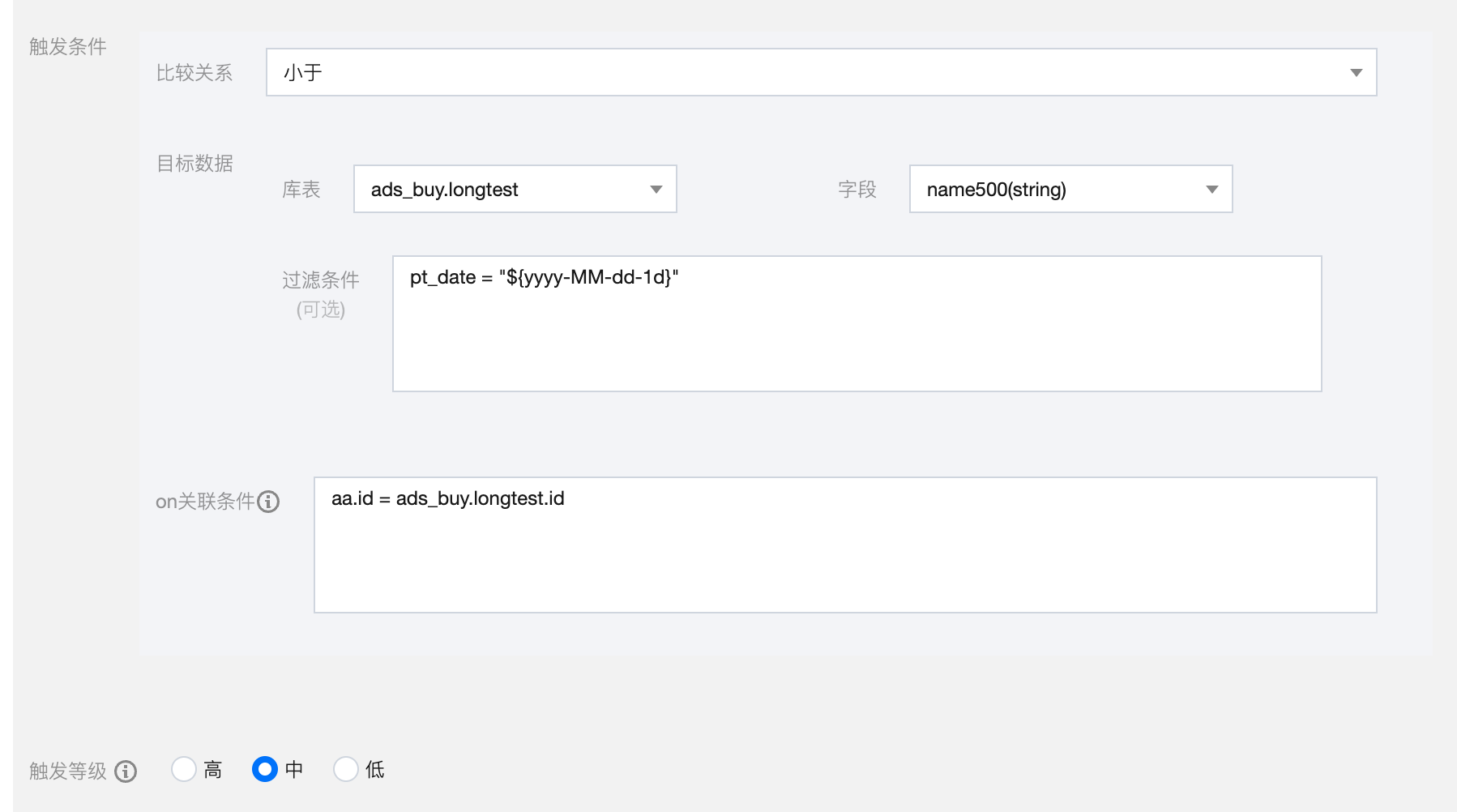 |
文档反馈