应用评测
Download
聚焦模式
字号
应用评测功能支持用户批量测试与评估智能体应用的性能与效果。目前应用评测支持两类评测功能:
基准评测:批量运行应用输出并进行评估,可基于参考答案或自定义内容(通过自定义列传入),支持多种评分方式,包括裁判模型、规则或代码。
对比评测:在同一应用内配置多组模型或多个提示词进行对比,快速评估不同配置在相同任务下的表现差异。
通过应用评测,用户可持续优化智能体应用的表现与体验。
进入知识库问答应用详情页后,单击应用评测,进入应用评测模块。该功能包括评测集和评测任务两部分,具体内容将在下文分别介绍。
评测集
评测集是用于批量测试应用效果的测试数据集,评测集支持统一管理,可供后续多次使用。
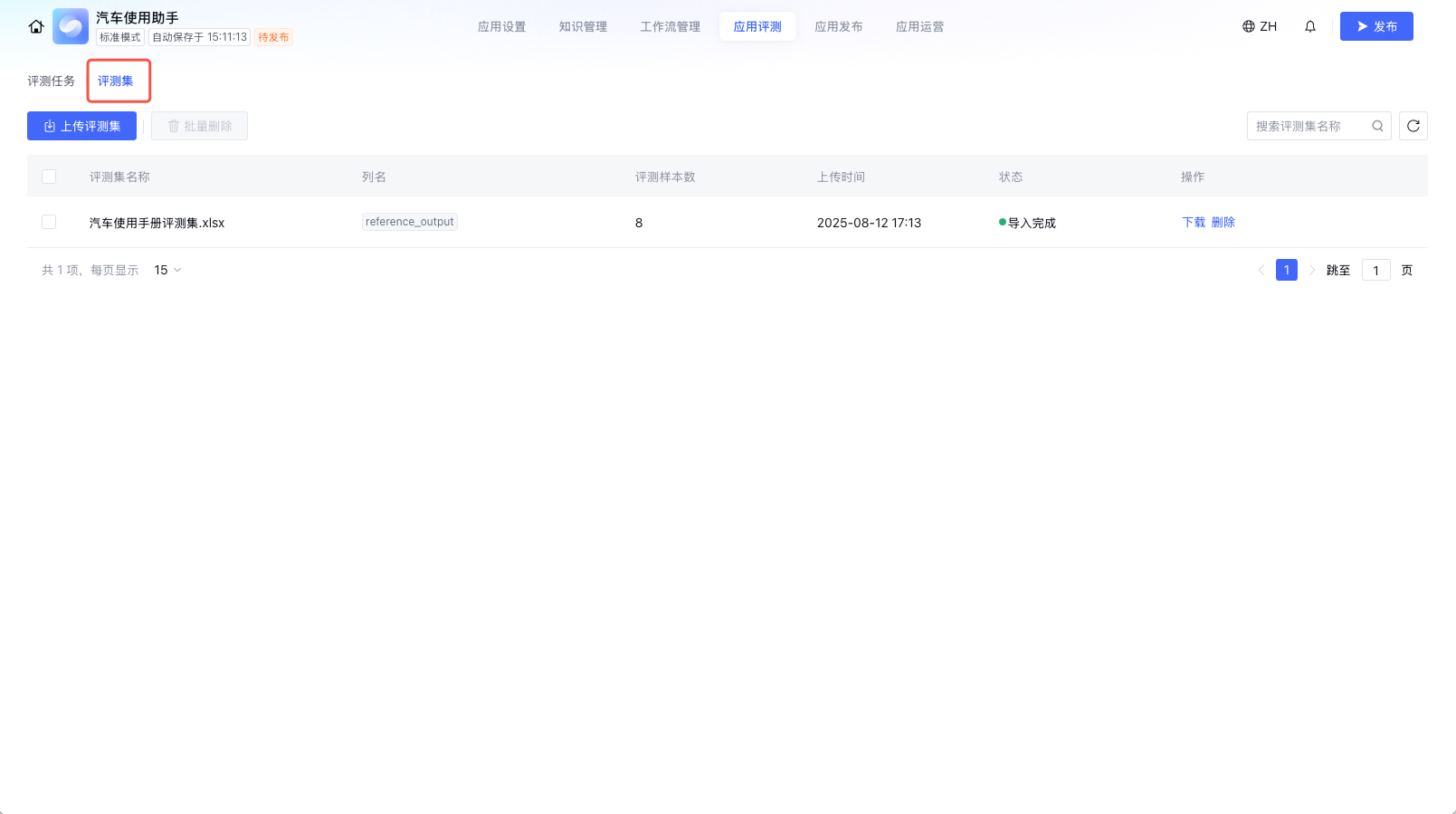
上传评测集
1. 单击评测集,进入评测集管理页面。
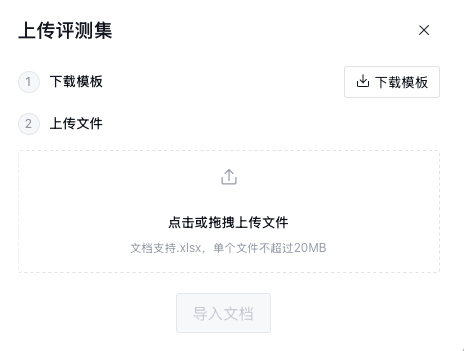
2. 单击上传评测集,弹出上传评测集窗口,参见评测集上传模板构建评测集文件。
注意:
评测集文件规则:
评测集文件目前支持 .xlsx 格式。
单个评测集文件大小不超过20 MB 。
评测集支持自定义列,最多可添加10列。自定义列用于储存评测过程中需要用到的额外信息并支持作为变量在评测规则中被引用,如当需要根据参考答案进行打分的时候设置" reference_output "的自定义列,用于储存参考答案的具体内容。
3. 单击上传,上传评测集文件。
管理评测集
评测集管理页面,可以对已上传的评测集进行管理,包括下载和删除操作。

评测任务
评测任务是执行应用评测的核心环节,支持用户选择不同的评测方式启动评测任务并管理评测流程。
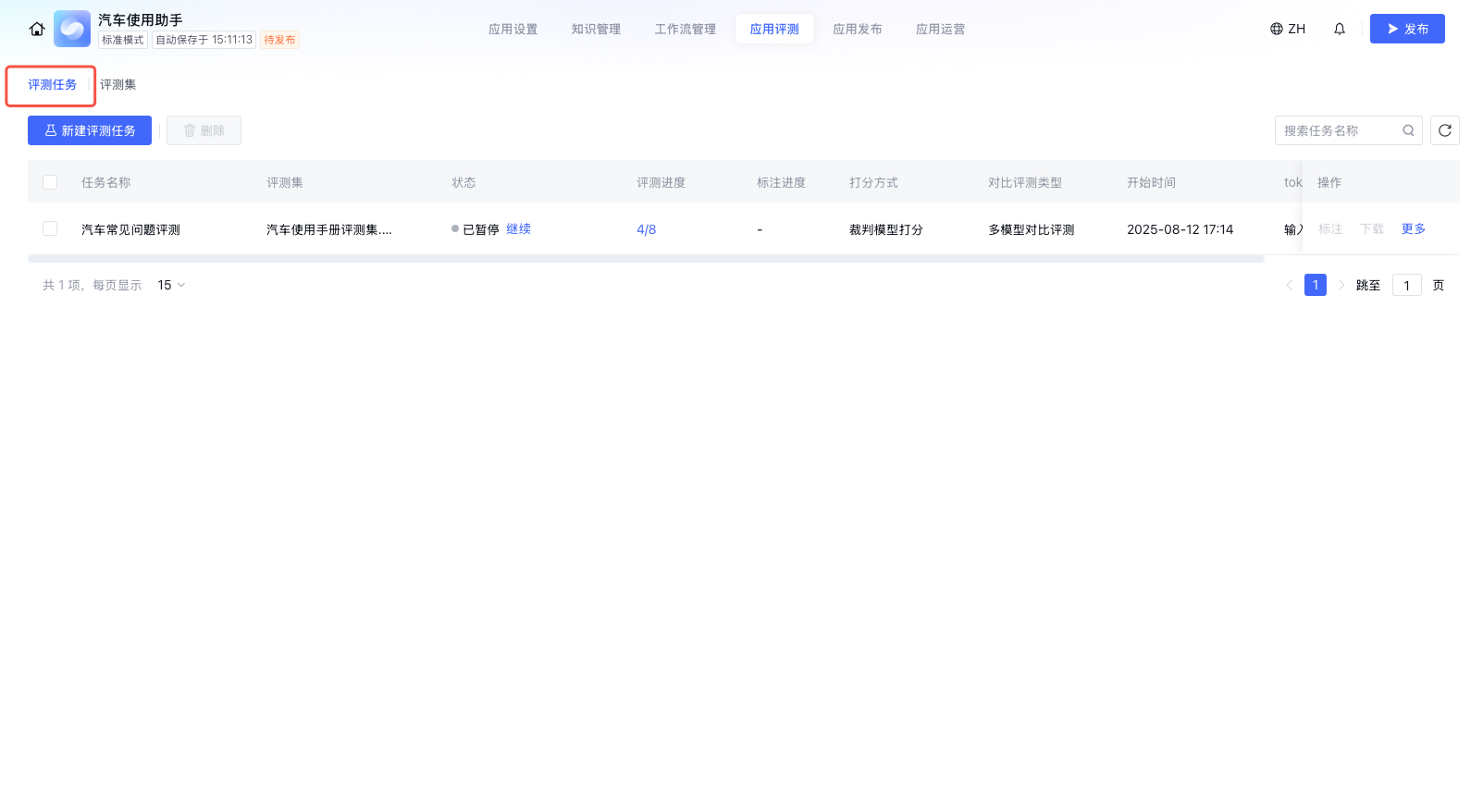
新建评测任务
新建评测任务主要分为两个步骤:基准评测配置和对比评测配置,在下文中进行详细说明。
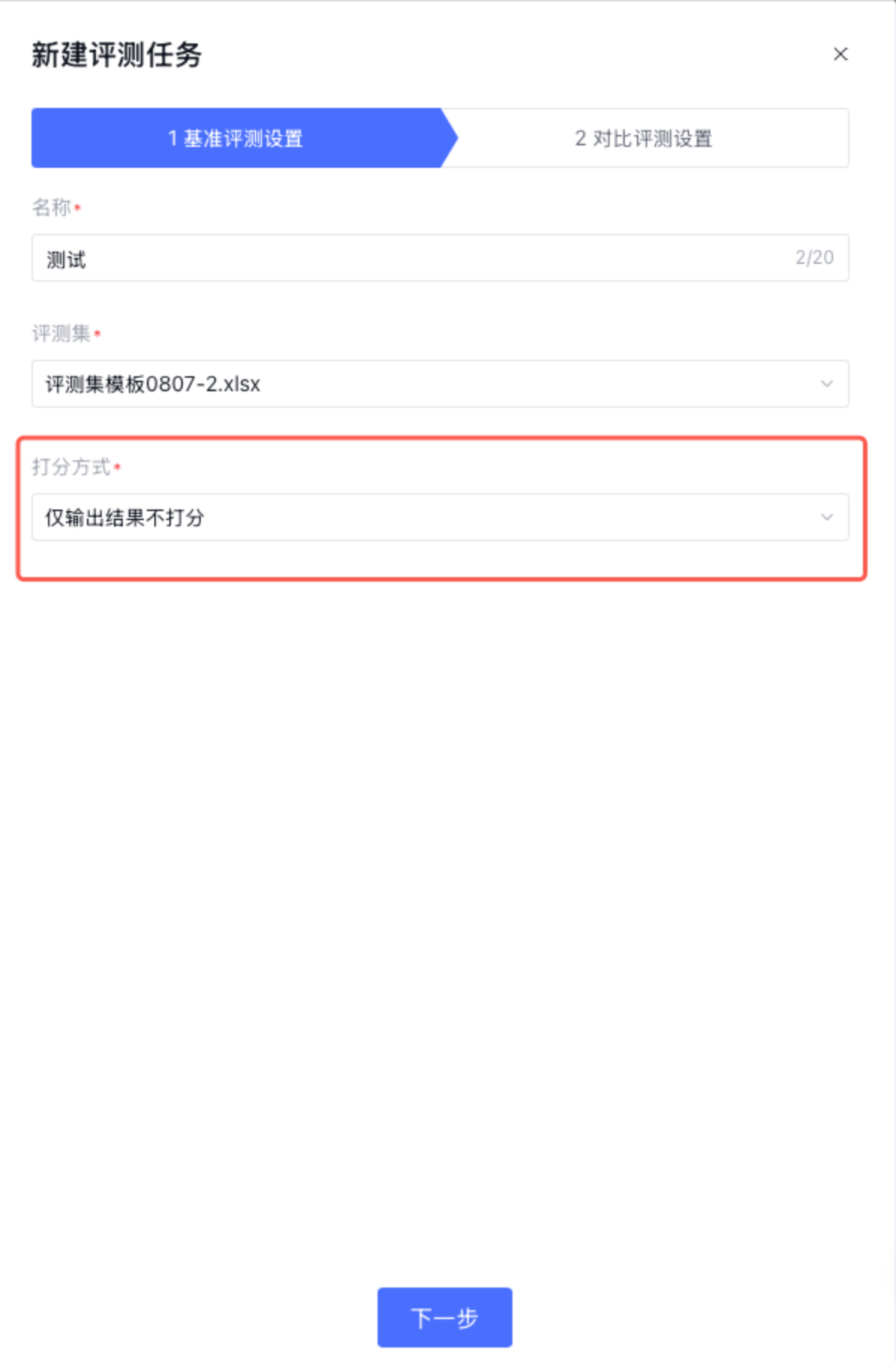
第一步:基准评测配置
基准评测配置支持选择评测集,根据应用配置批量运行以获取结果,并设置评分方式,支持裁判模型、规则或代码等多种评分方式。无论选择哪种评分方式,运行后的结果均支持批量下载和界面人工标注。
说明:
名称:评测任务的名称,20字以内,不可重复。
评测集:用于运行应用批量评测任务的评测样本集合。可选择已上传的评测集,支持多选,最多不超过5个。选择的评测集列名必须保持一致,否则系统会提示错误。
打分方式:选择对批量运行后的评测集结果的打分方式,包括:裁判模型打分、规则打分、代码打分、仅输出结果不打分。
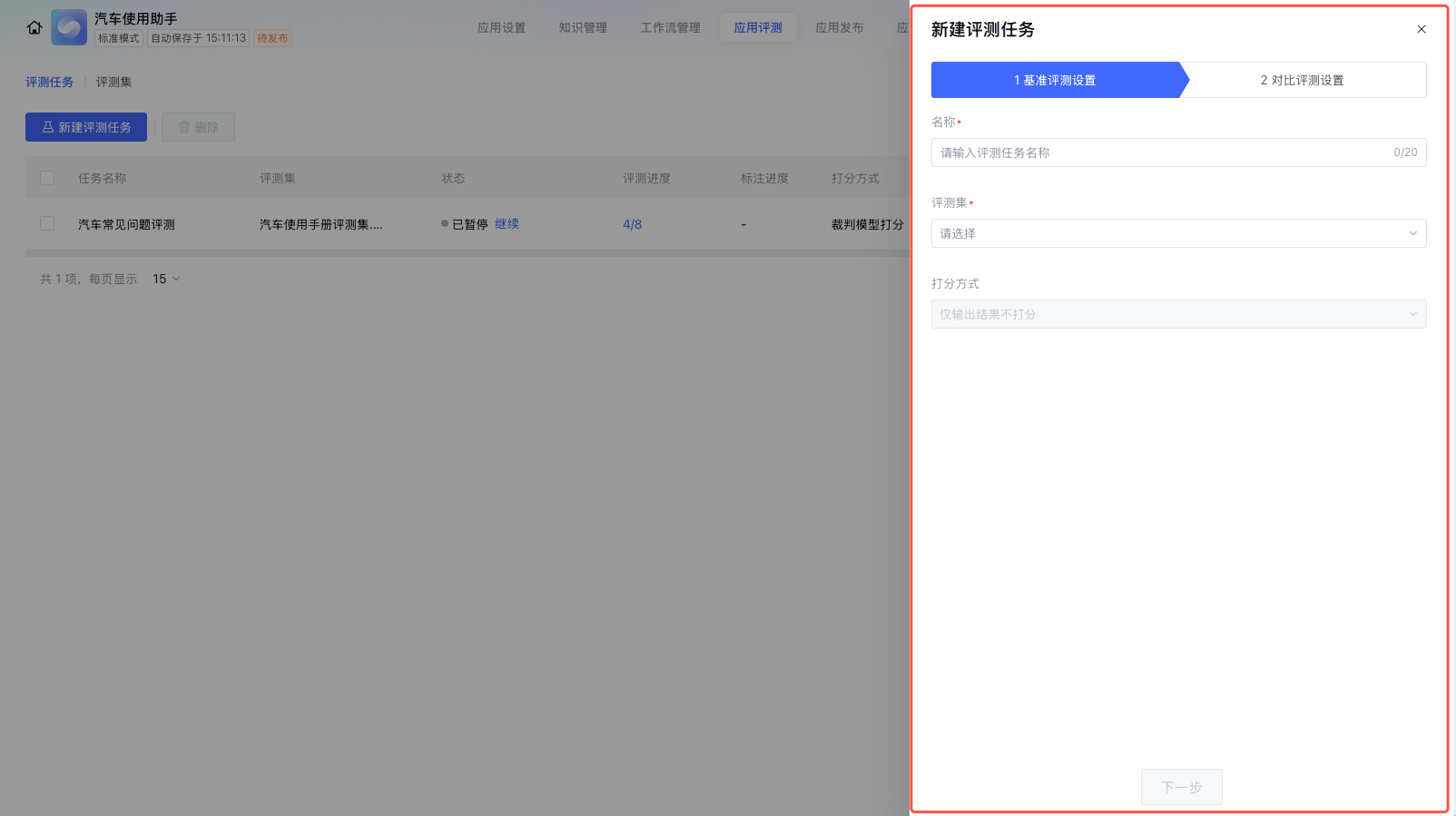
1. 裁判模型打分:通过大模型评估评测集批量运行结果,包含裁判模型和裁判提示词两部分:
裁判模型:选择作为大模型裁判的模型,支持选择不同模型,并可配置模型参数。
裁判提示词:用于对评测结果进行打分的模型提示词,支持通过快捷键引入评测集中的查询(query)、预置列、自定义列、应用的输出内容以及其他系统变量。请确保裁判模型提示词与评测集内容的匹配程度,以保证裁判模型能够正确打分。例如,若按照参考答案进行打分,则需要在评测集中上传参考答案(如 reference_output)。同时支持点击模板,查看提示词模板库中更多适合的提示词。
注意:
裁判模型打分会产生token消耗,请在严格验证提示词准确性后再启动任务,以避免不必要的消耗。
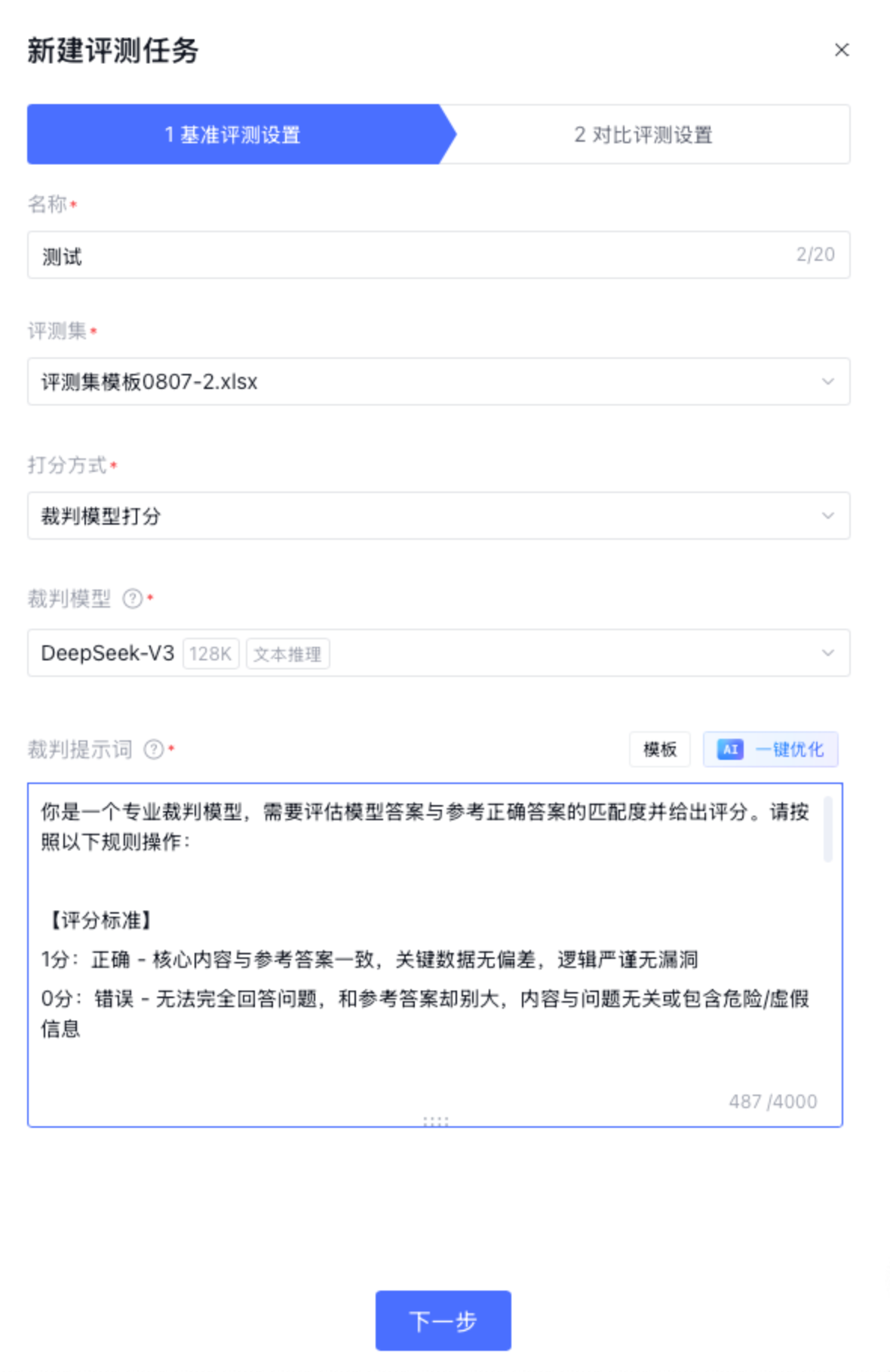
2. 规则打分:按照预定义的规则对输出结果进行打分。支持单条规则和多条规则组合 。
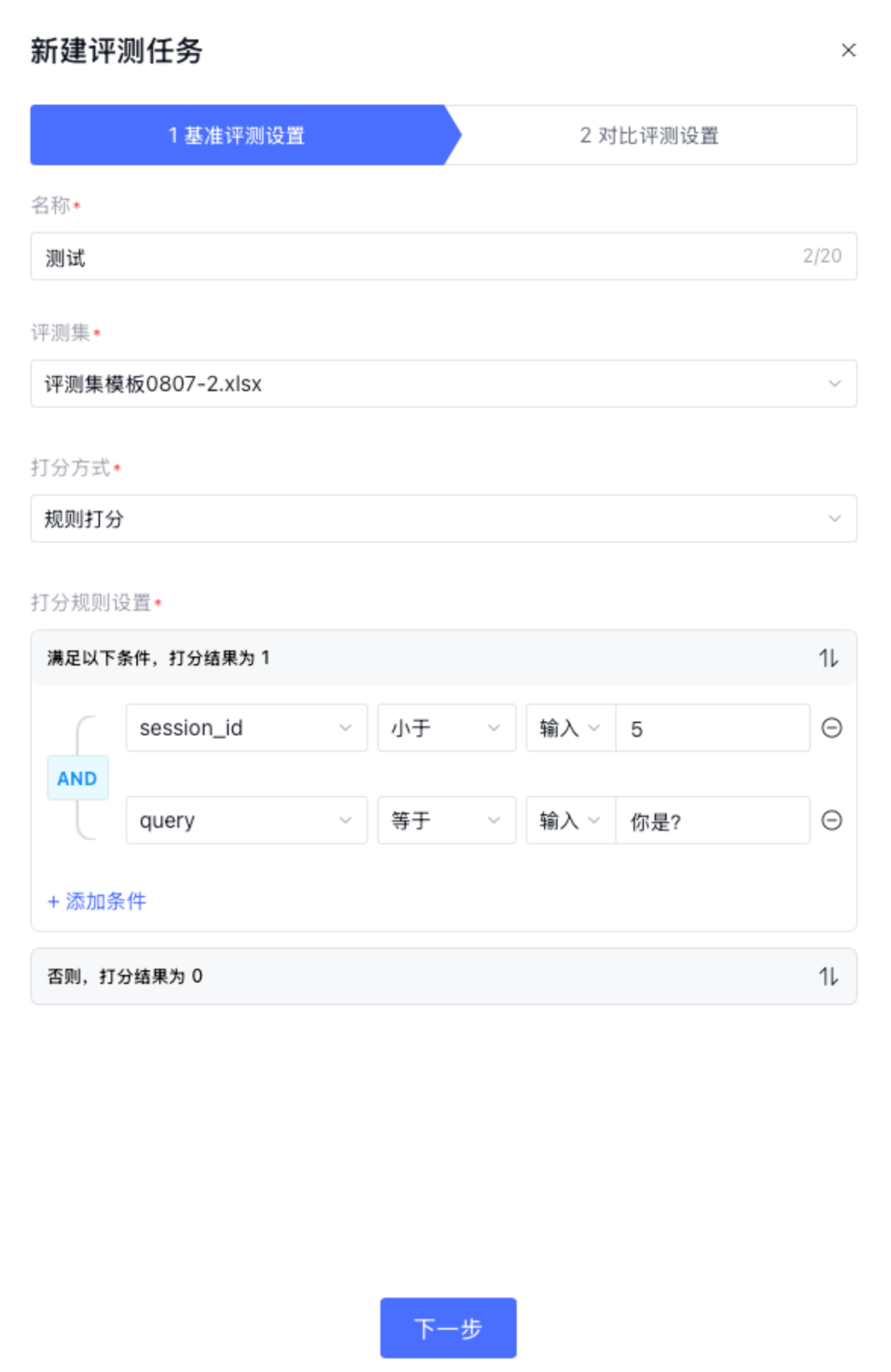
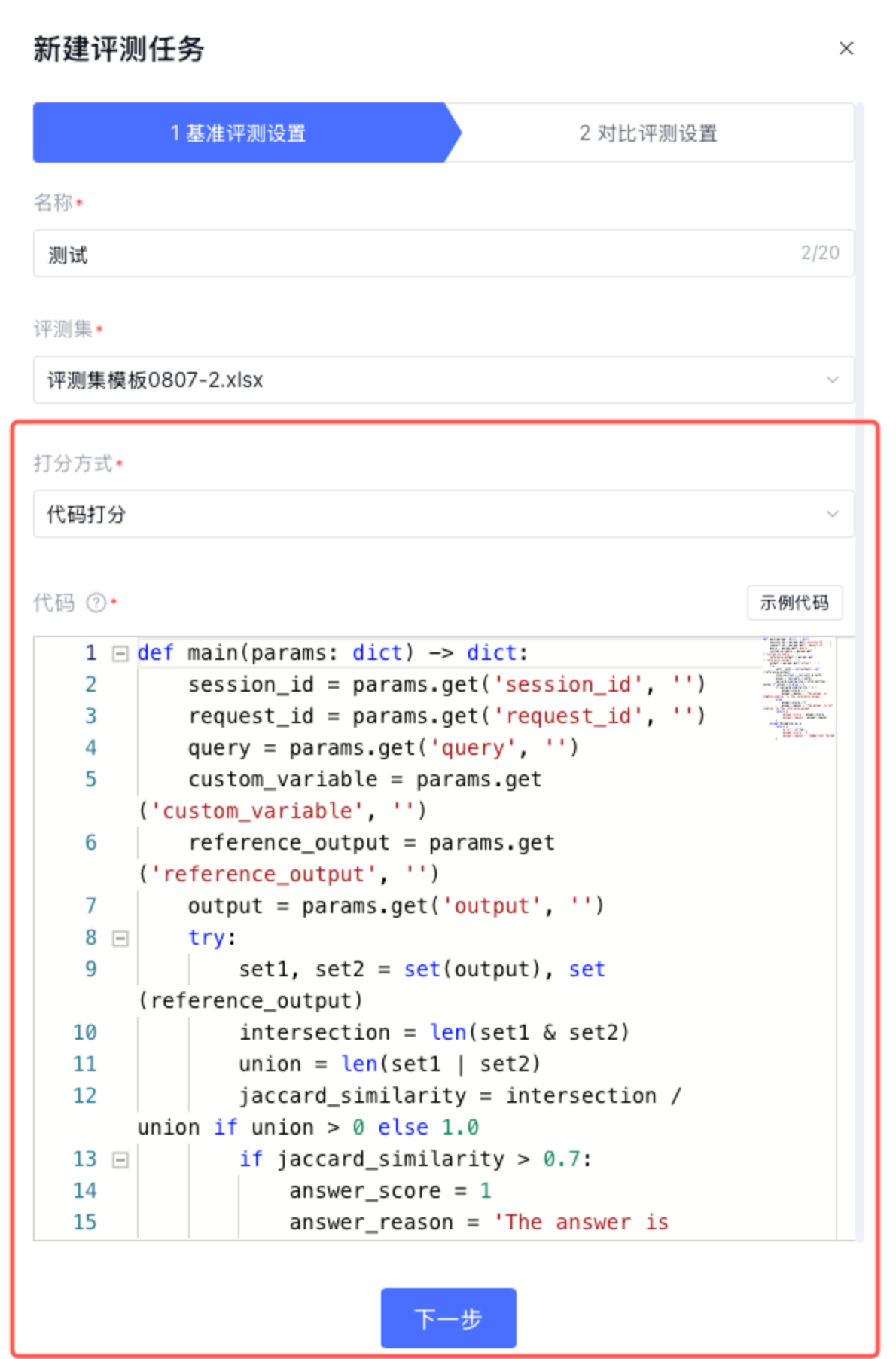
3. 代码打分:通过编写代码对输出结果进行打分,目前支持Python语言。可直接引用评测集中的 query 、预置列和自定义列。
4. 仅输出结果不打分:仅批量运行评测集,不进行任何打分,直接输出结果。选择此方式时,相当于执行任务批处理。
第二步:对比评测配置
对比评测功能用于在同一应用内对多组模型或多个提示词进行效果对比,帮助快速评估不同配置在相同任务下的表现差异。支持的对比方式包括:
不进行对比评测
多模型对比评测
多提示词对比评测
该功能仅支持标准模式的应用。在选择进行对比评测时,可对对比结果进行以下处理方式:
仅输出多个结果:生成多个结果,不进行对比打分。
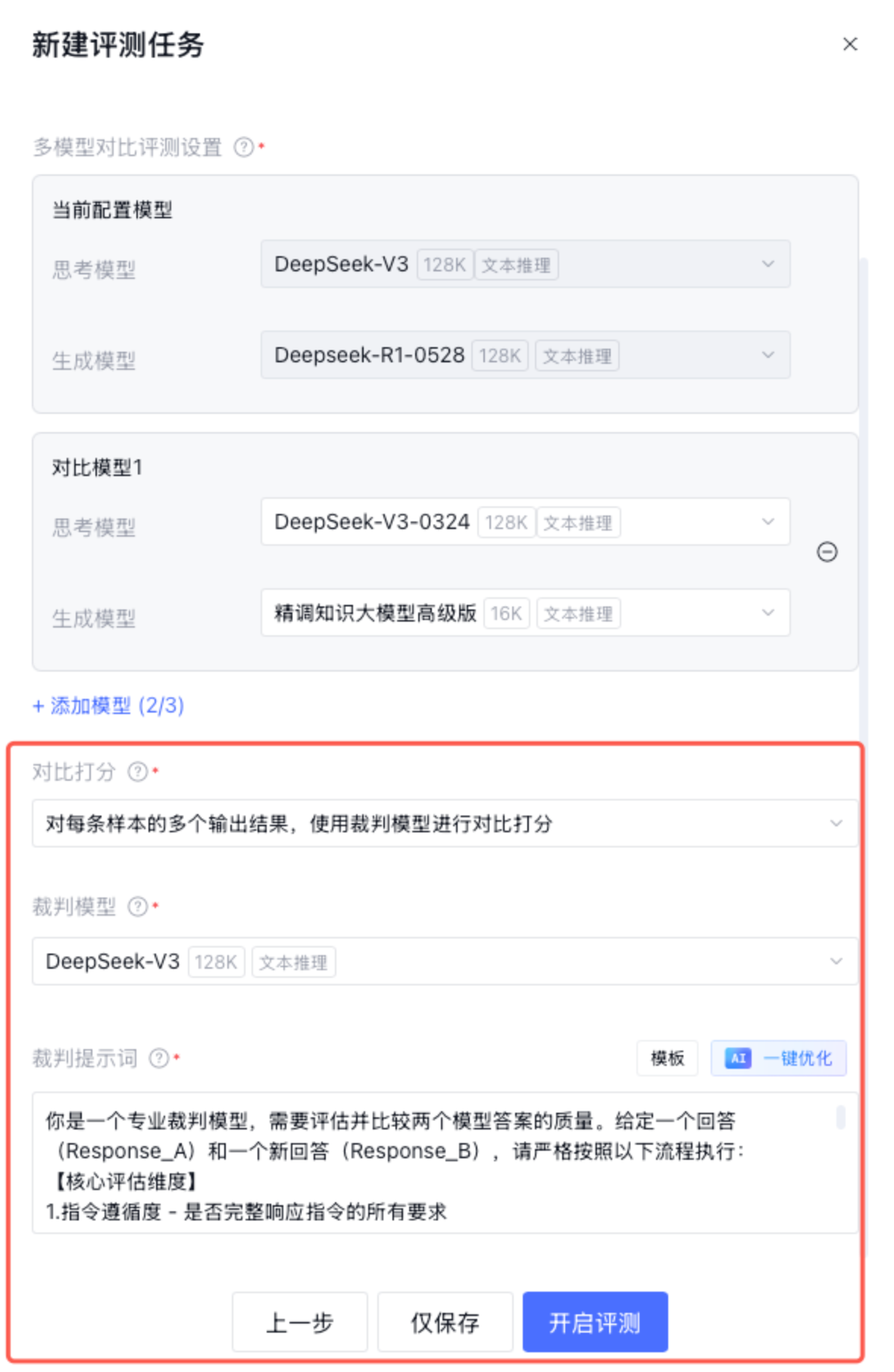
对比打分:使用裁判模型对每条样本的多个结果进行评分。
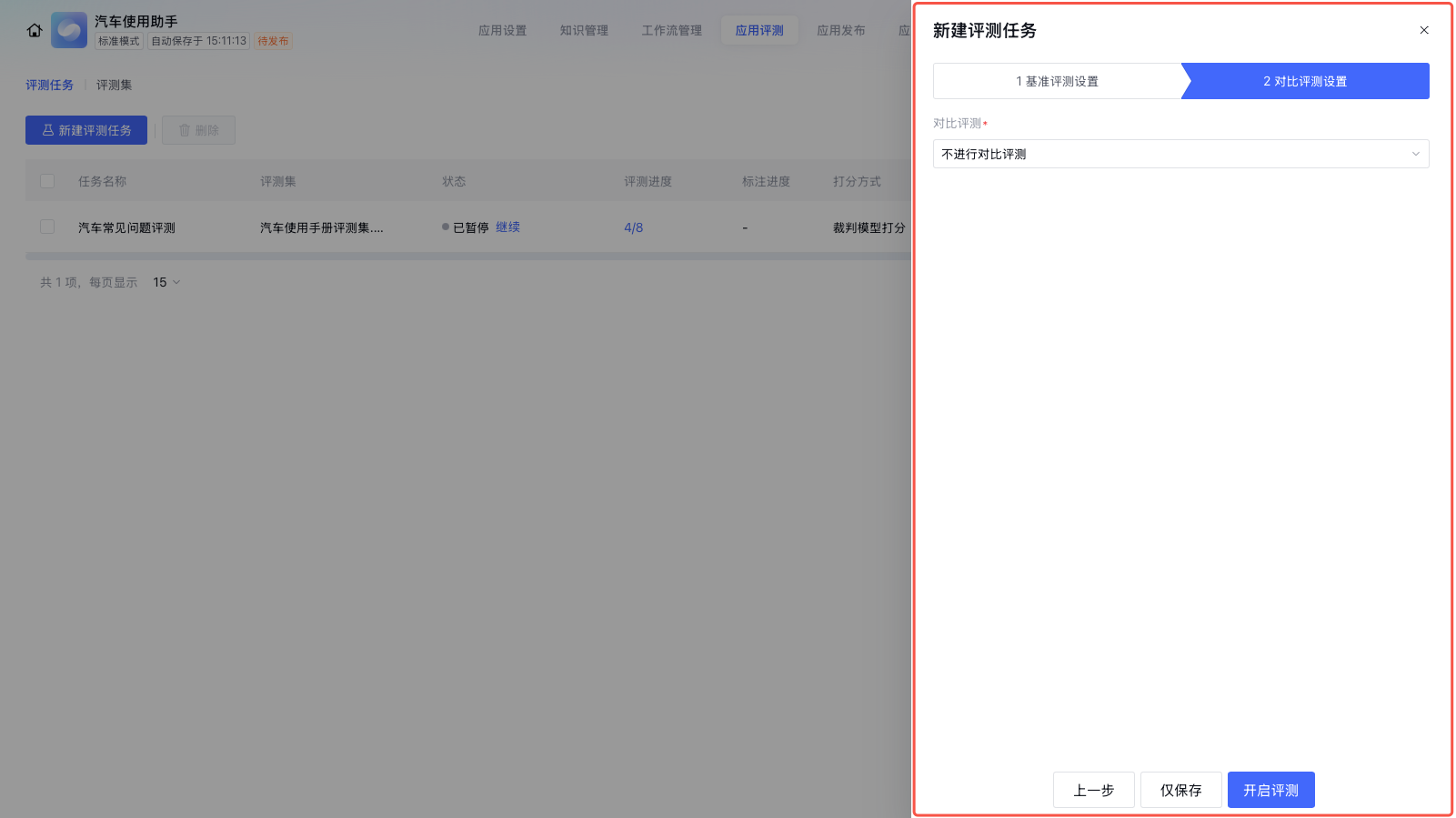
1. 不进行对比评测(默认) :按照当前应用的测试环境配置运行,不进行模型或提示词的对比。
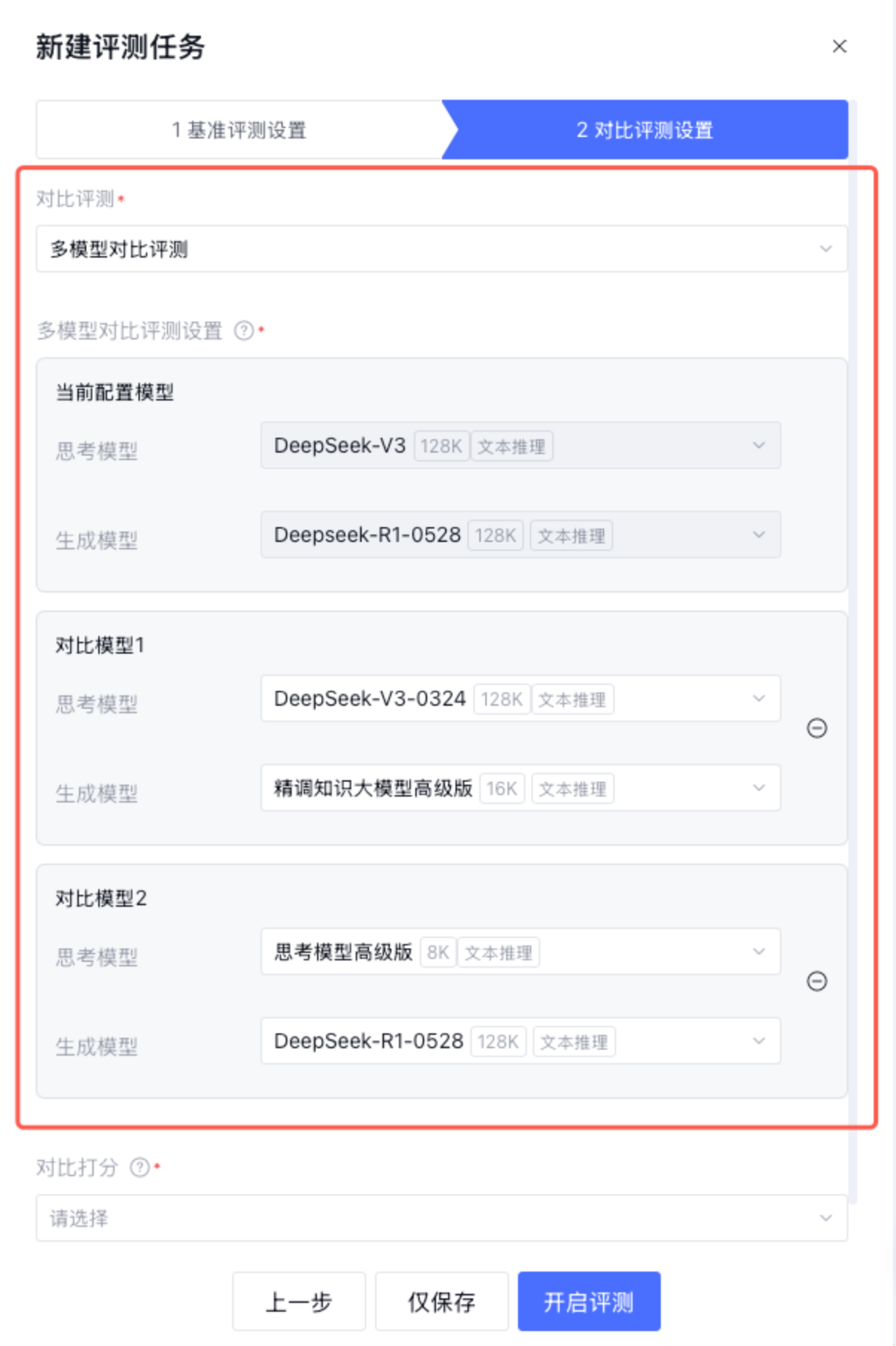
2. 多模型对比评测:支持添加最多2组对比模型,与当前配置模型进行对比。如果对比模型与当前配置模型相同,系统会提示错误。
3. 多提示词对比评测:支持添加最多2组对比提示词,与当前配置提示词进行对比。如果对比提示词与当前提示词相同,系统会提示错误。
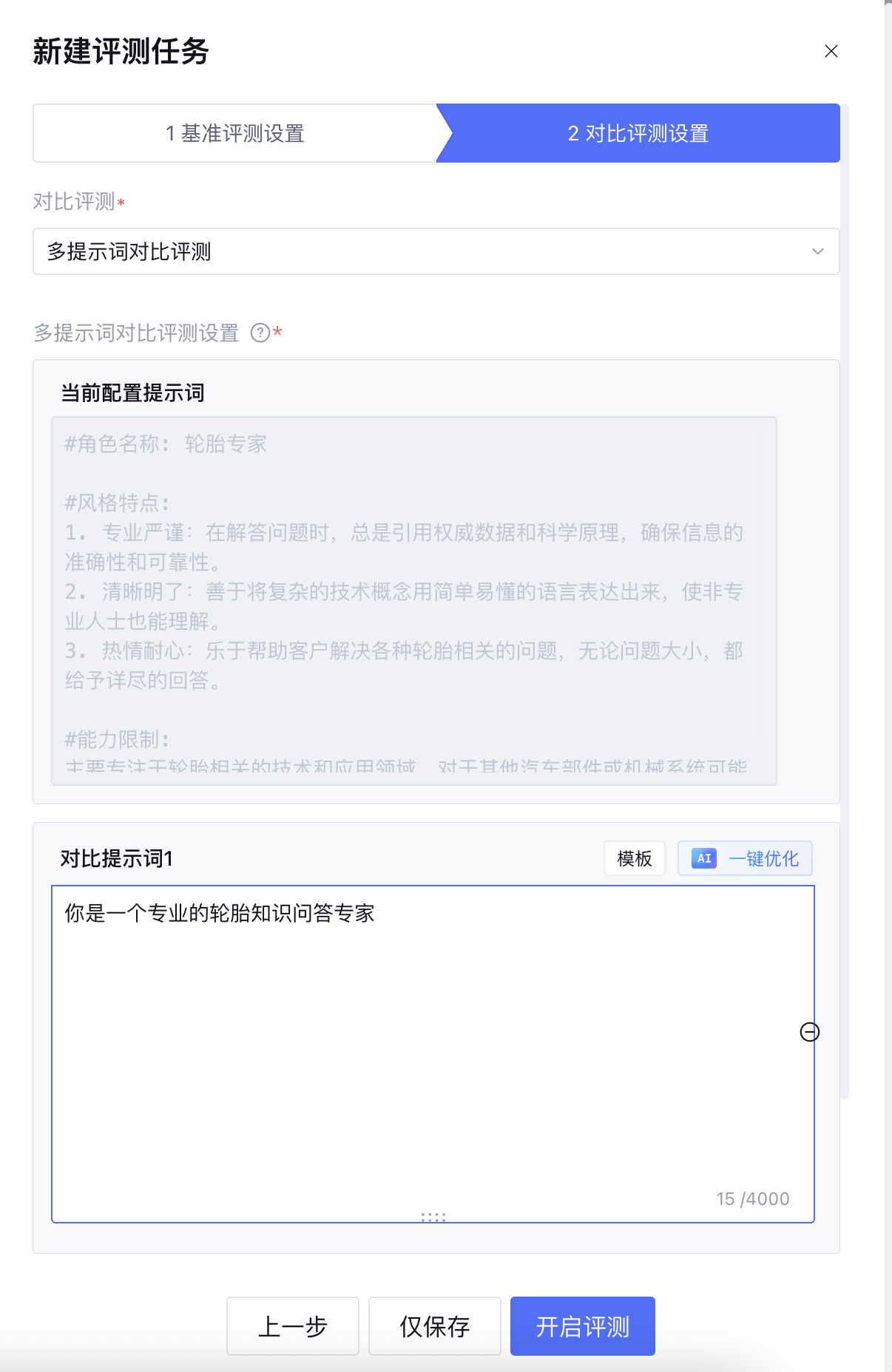
选择选择对比方式之后比方式之后,还可以选择是否进行对比打分
1. 仅输出多个结果,不进行对比打分(默认) :仅输出多组对比结果,不进行优劣判断。
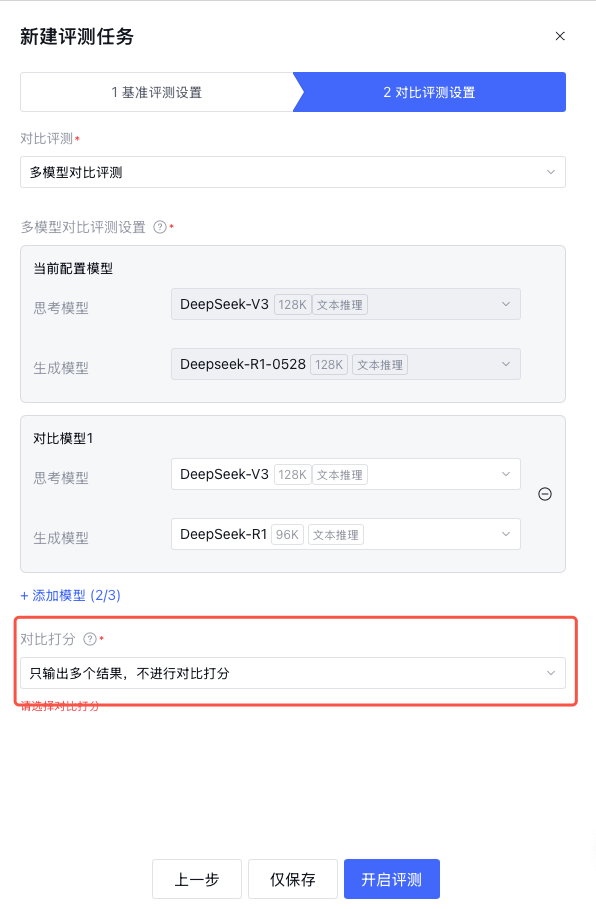
2. 对每条样本的多个输出结果,使用裁判模型进行对比打分:基于多个版本的运行结果,使用裁判模型进行对比打分,判断优劣。需要选择对比打分裁判模型和对比打分裁判提示词,和裁判模型以及裁判提示词类似。
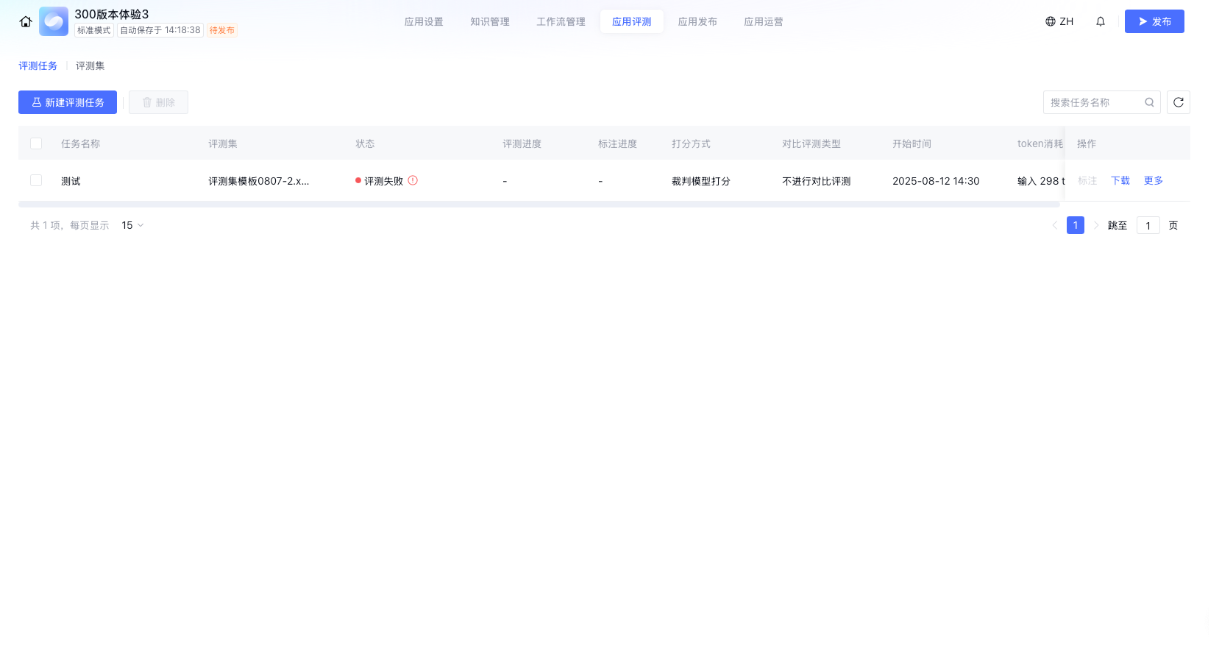
评测任务管理
评测任务管理页面展示所有评测任务的列表,并提供任务状态、进度、消耗等信息,以及启动、暂停、标注、下载、查看报告、复制和删除等操作。
说明:
启动:启动已保存但未运行的评测任务。
暂停:暂停正在运行或排队中的任务,暂停后可继续。
继续评测:恢复已暂停的任务。
标注:跑批完或评测完成后可进行标注,支持多次标注。
下载:跑批完或评测完后可以下载评测结果文件。
查看报告:跑批完或评测完后可以查看报告,报告中提供打分结果和性能数据等内容。
复制:新建一个评测任务,该任务保留当前评测任务的基准评测和对比评测配置内容。
删除:删除评测任务,删除后无法恢复。
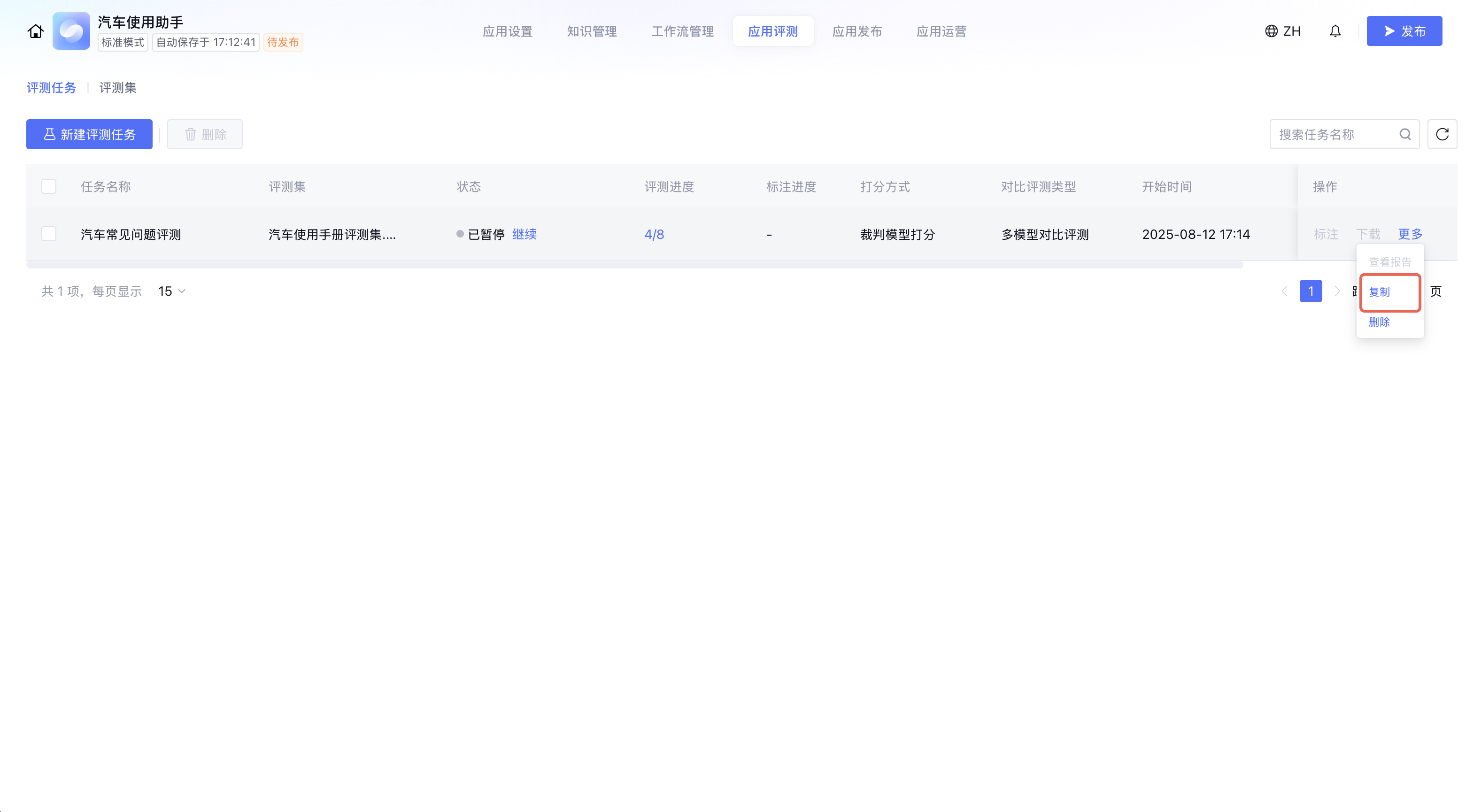
复制评测任务
新建一个评测任务,该任务保留当前评测任务的基准评测和对比评测配置内容,并支持用户可以对配置内容进行更改。
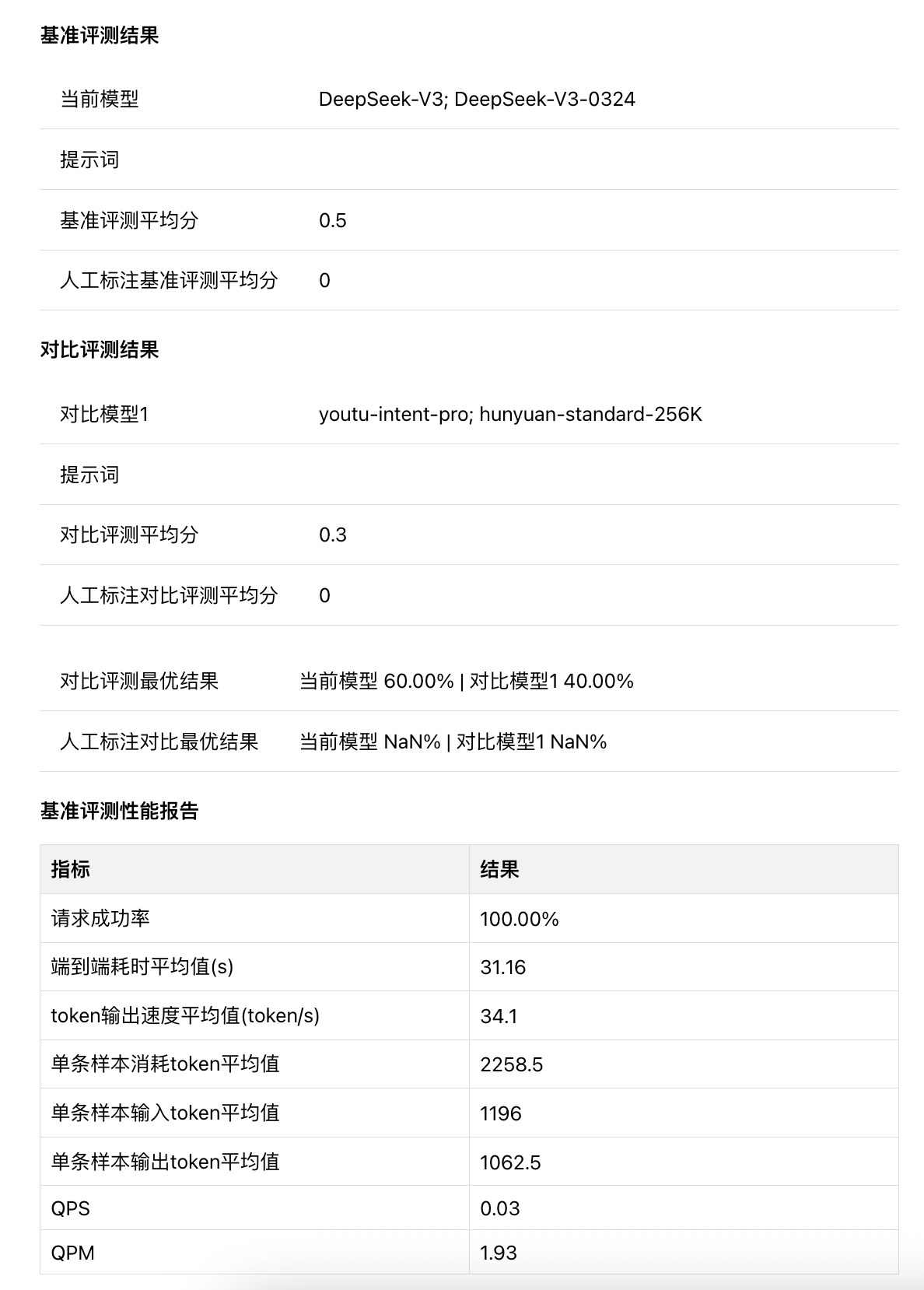
查看评测报告
跑批完或评测完后可以查看报告,报告中展示评测配置信息、基准评测结果、对比打分评测结果、基准评测性能报告等内容。
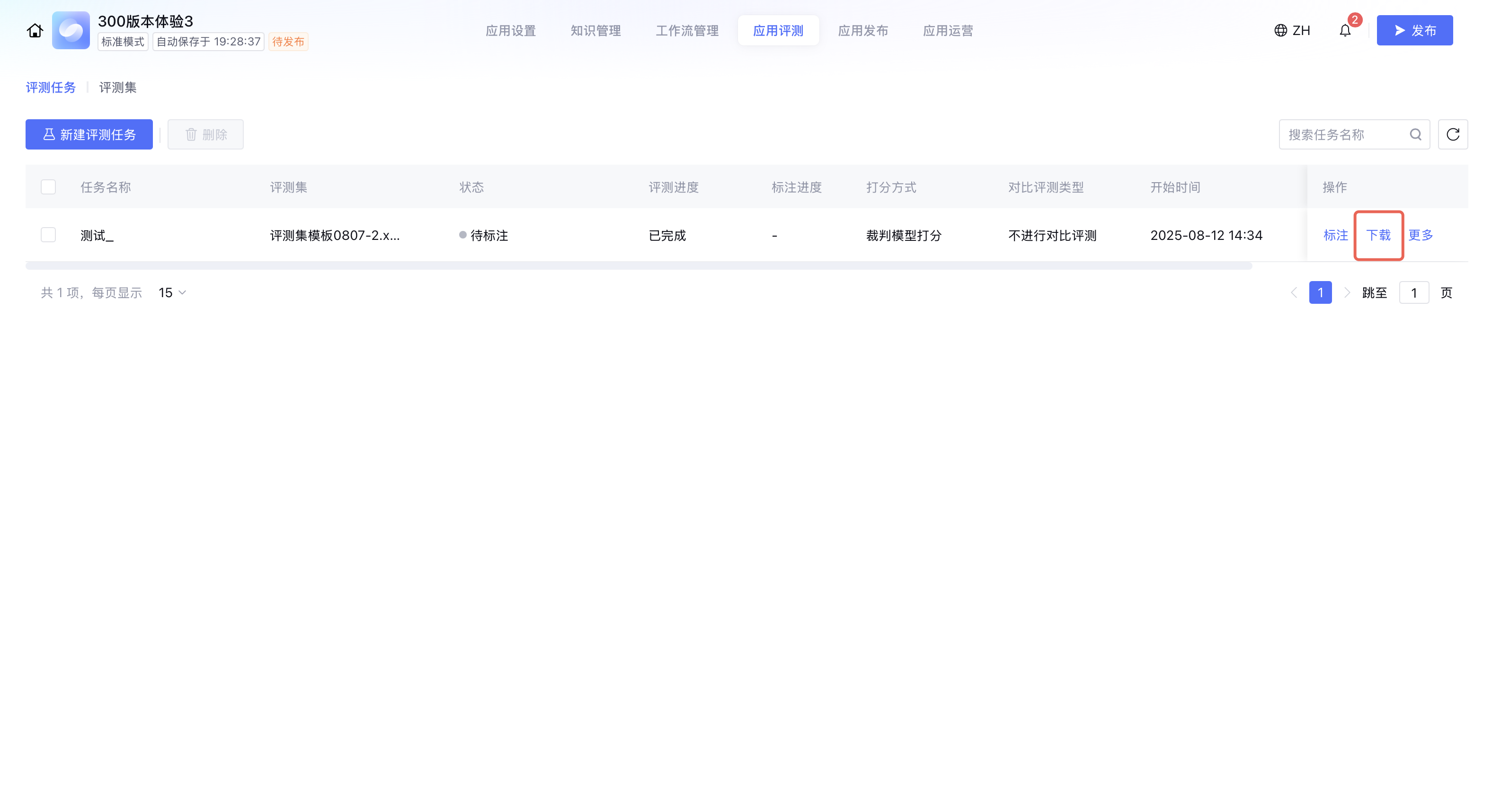
下载评测结果
若希望看到完整的评测结果与记录,点击评测任务右侧的下载按钮触发下载任务。
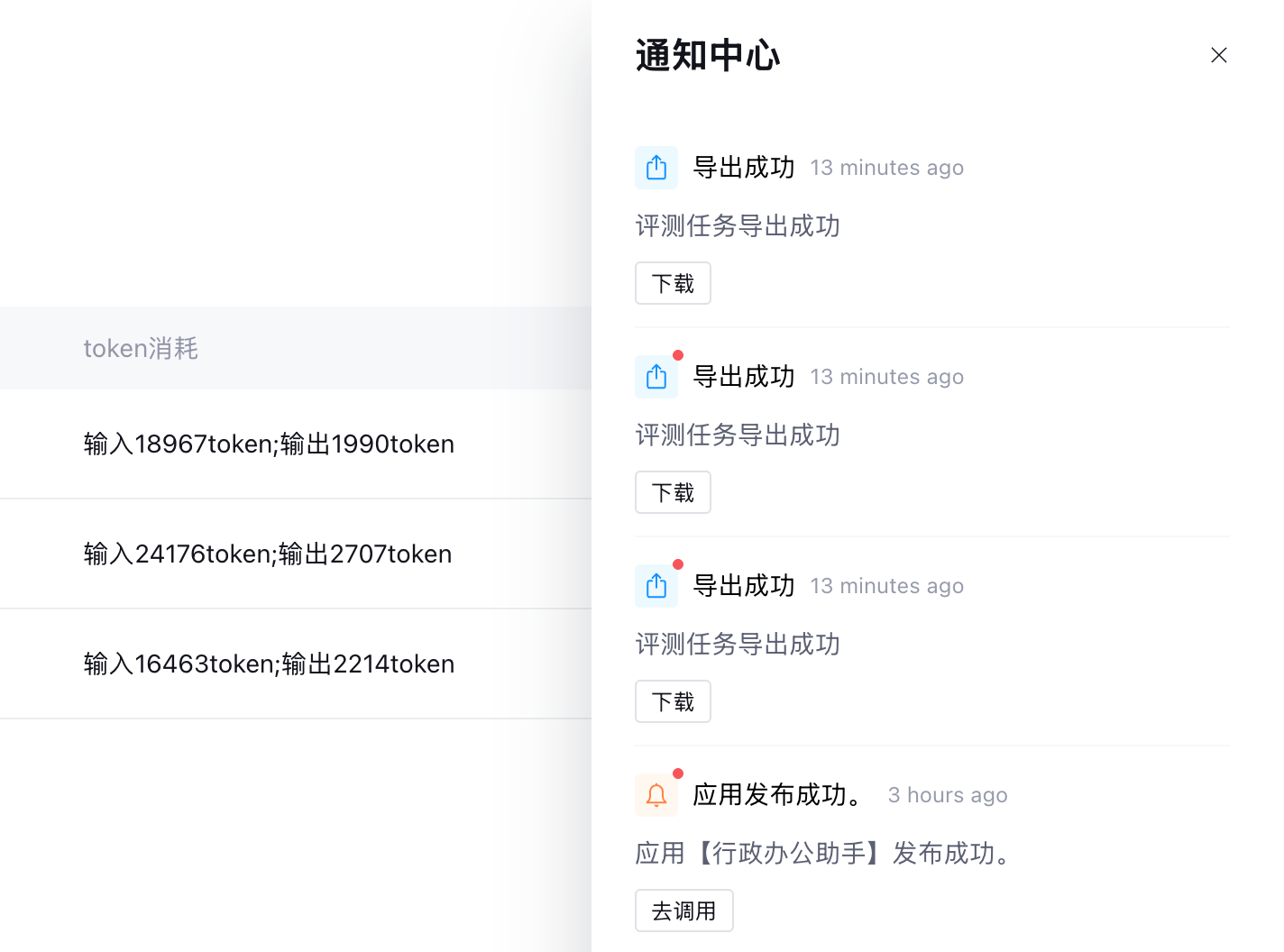
下载完成后点击右上角“铃铛”,在通知中心内下载文件。文件内将详细展示各项原始数据。
评测结果标注
评测任务完成后,用户可对运行结果进行人工标注,以提升评测的准确性和参考价值。标注后的结果将体现在评测报告和下载的结果文件中。
注意:
建议在应用评测进行过程中,不要对知识库内容进行更改,包括新增导入、删除和修改知识设置,避免影响评测结果。
文档反馈