在 Kubernetes 中使用 GooseFS 加速 Spark 数据访问
Download
聚焦模式
字号
概述
在 Kubernetes 上运行的 Spark 可以将 GooseFS 用作数据访问层。本文将讲解如何在 Kubernetes 环境中使用 GooseFS 加速 Spark 的数据访问。
实践部署
环境与依赖版本
CentOS 7.4+
Kubernetes version 1.18.0+
Docker 20.10.0
Spark version 2.4.8+
GooseFS 1.2.0+
Kubernetes 的部署
使用 GooseFS 加速 Spark 数据访问
目前,在 Kuberntes 中使用 GooseFS 加速 Spark 的数据访问主要有两种方式:
基于 Fluid 分布式数据编排与加速引擎(Fluid Operator 架构)部署运行 GooseFS Runtime Pods 和 Spark Runtime 加速 Spark 计算应用。
在 Kubernetes 中运行 Spark on GooseFS(Kubernetes Native 部署架构)。
在 Kubernetes 中运行 Spark on GooseFS
前置条件
1. Spark on Kubernetes 采用的是 Spark 官网推荐 Kubernetes Native 部署运行架构,详细的部署运行方法可参见 Spark 的官网文档。
2. 已部署 GooseFS 集群。GooseFS 的集群部署可参见 控制台快速入门。
注意:
部署 GooseFS Worker 的时候,需要配置 goosefs.worker.hostname=$(hostname -i),否则 Spark pod 中的 client 会无法解析 GooseFS 的 Worker 地址。
基本步骤
1. 首先,下载解压 spark-2.4.8-bin-hadoop2.7.tgz。
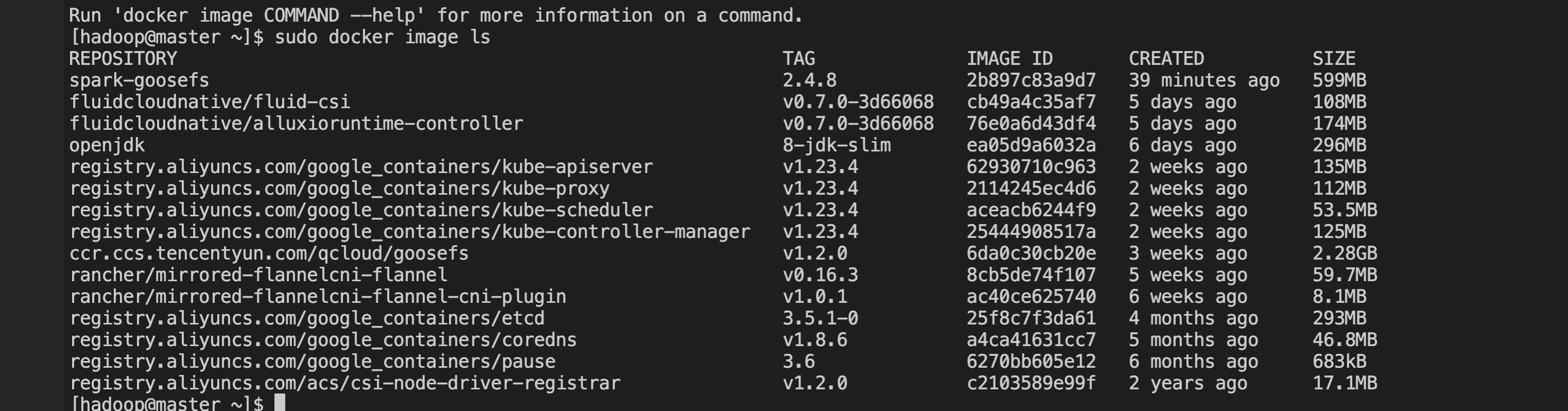
2. 将 GooseFS client 从 GooseFS 的 Docker 镜像中解压出来,然后编译到 Spark 镜像中,如下所示:
# 将 GooseFS client 从 GooseFS 的 Docker 镜像中解压出来$ id=$(docker create goosefs/goosefs:v1.2.0)$ docker cp $id:/opt/alluxio/client/goosefs-1.2.0-client.jar - > goosefs-1.2.0-client.jar$ docker rm -v $id 1>/dev/null# 然后,copy 到 spark 的目录中$ cp goosefs-1.2.0-client.jar /path/to/spark-2.4.8-bin-hadoop2.7/jars# 然后,重新编译 spark 的 docker 镜像$ docker build -t spark-goosefs:2.4.8 -f kubernetes/dockerfiles/spark/Dockerfile .# 查看编译好的 docker image$ docker image ls
测试步骤
首先,需要保证 GooseFS 集群已经启动运行,并且容器能够访问到 GooseFS Master/Worker 的 IP 和端口,然后按照以下步骤进行测试验证:
1. 在 GooseFS 中创建一个用于测试的 namespace,例如这里创建一个 /spark-cosntest 的namespace,并放入测试数据文件。
注意:
建议用户尽量避免在配置中使用永久密钥,采取配置子账号密钥或者临时密钥的方式有助于提升业务安全性。为子账号授权时建议按需授权子账号可执行的操作和资源,避免发生预期外的数据泄露。
如果您一定要使用永久密钥,建议对永久密钥的权限范围进行限制,可通过限制永久密钥的可执行操作、资源范围和条件(访问 IP 等),提升使用安全性。
# 建议使用子账号密钥或者临时密钥的方式完成配置,提升配置安全性。为子账号授权时建议按需授权子账号可执行的操作和资源$ goosefs ns create spark-cosntest cosn://goosefs-test-125000000/ --secret fs.cosn.userinfo.secretId=************************************ --secret fs.cosn.userinfo.secretKey=************************************ --attribute fs.cosn.bucket.region=ap-xxxx# 放入一个测试数据文件$ goosefs fs copyFromLocal LICENSE /spark-cosntest
2. (可选)创建一个用于运行 spark 作业的服务账号。
$ kubectl create serviceaccount spark$ kubectl create clusterrolebinding spark-role --clusterrole=edit \\--serviceaccount=default:spark --namespace=default
3. 提交一个 spark 作业。
--master k8s://http://127.0.0.1:8001 \\--deploy-mode cluster \\--name spark-goosefs \\--class org.apache.spark.examples.JavaWordCount \\--conf spark.executor.instance=2 \\--conf spark.kubernetes.container.image=spark-goosefs/spark:2.4.8 \\--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \\--conf spark.hadoop.fs.gfs.impl=com.qcloud.cos.goosefs.hadoop.GooseFileSystem \\--conf spark.driver.extraClassPath=local:///opt/spark/jars/goosefs-1.2.0-client.jar \\local:///opt/spark/examples/jars/spark-examples_2.11-2.4.8.jar \\gfs://172.16.64.32:9200/spark-cosntest/LICENSE
4. 等待执行完成即可。

kubectl logs spark-goosefs-1646905692480-driver 查看作业执行结果即可。
文档反馈