构建深度学习容器镜像
Download
Focus Mode
Font Size
操作场景
本系列文章将记录在 TKE Serverless 集群部署深度学习的一系列实践,从直接部署 TensorFlow 到后续实现 Kubeflow 的部署,旨在提供一个较完整的容器深度学习实践方案。本文着重介绍自建深度学习容器镜像的搭建,为后面深度学习部署任务提供更方便快捷的完成方式。
因为本文实践任务需要,公有镜像无法满足深度学习部署需求,因此本实践选择自建镜像。
除深度学习框架 TensorFlow-gpu ,该镜像还包含 GPU 训练需要的 cuda、cudnn ,并整合了 TensorFlow 官方提供的深度学习模型——包含了目前 CV、NLP、RS 等领域的 SOTA 模型。模型详情请参见 Model Garden for TensorFlow。
操作步骤
1. 本文示例通过 Docker 容器 构建镜像。准备 Dockerfile 文件,示例如下:
FROM nvidia/cuda:11.3.1-cudnn8-runtime-ubuntu20.04RUN apt-get update -y \\&& apt-get install -y python3 \\python3-pip \\git \\&& git clone git://github.com/tensorflow/models.git \\&& apt-get --purge remove -y git \\ #不需要的组件及时卸载(可选)&& rm -rf /var/lib/apt/lists/* #删除apt安装用的安装包(可选)&& mkdir /tf /tf/models /tf/data #新建存储模型和数据的路径,可作为挂载点(可选)ENV PYTHONPATH $PYTHONPATH:/modelsENV LD_LIBRARY_PATH $LD_LIBRARY_PATH:/usr/local/cuda-11.3/lib64:/usr/lib/x86_64-linux-gnu#RUN pip3 install --user -r models/official/requirements.txt \\&& pip3 install tensorflow
2. 执行以下命令进行部署。
docker build -t [name]:[tag] .
说明
必要的部件,例如 Python、TensorFlow、cuda、cudnn 以及模型库等安装步骤,本文不再赘述。
相关说明
镜像相关
关于基础镜像 nvidia/cuda,CUDA 容器镜像为 CUDA 支持的平台和架构提供了一个易于使用的分发版。此处选择的是 cuda 11.3.1、cudnn 8的组合。更多版本选择可参见 Supported tags。
环境变量
在进行本文最佳实践时,需要重点关注环境变量
LD_LIBRARY_PATH 。LD_LIBRARY_PATH是动态链接库的安装路径,通常为 libxxxx.so 的格式。在此处主要是为了链接 cuda 和 cudnn。例如 libcudart.so.[version]、ibcusolver.so.[version]、libcudnn.so.[version] 等。您可以执行 ll 命令进行查看,如下图所示:
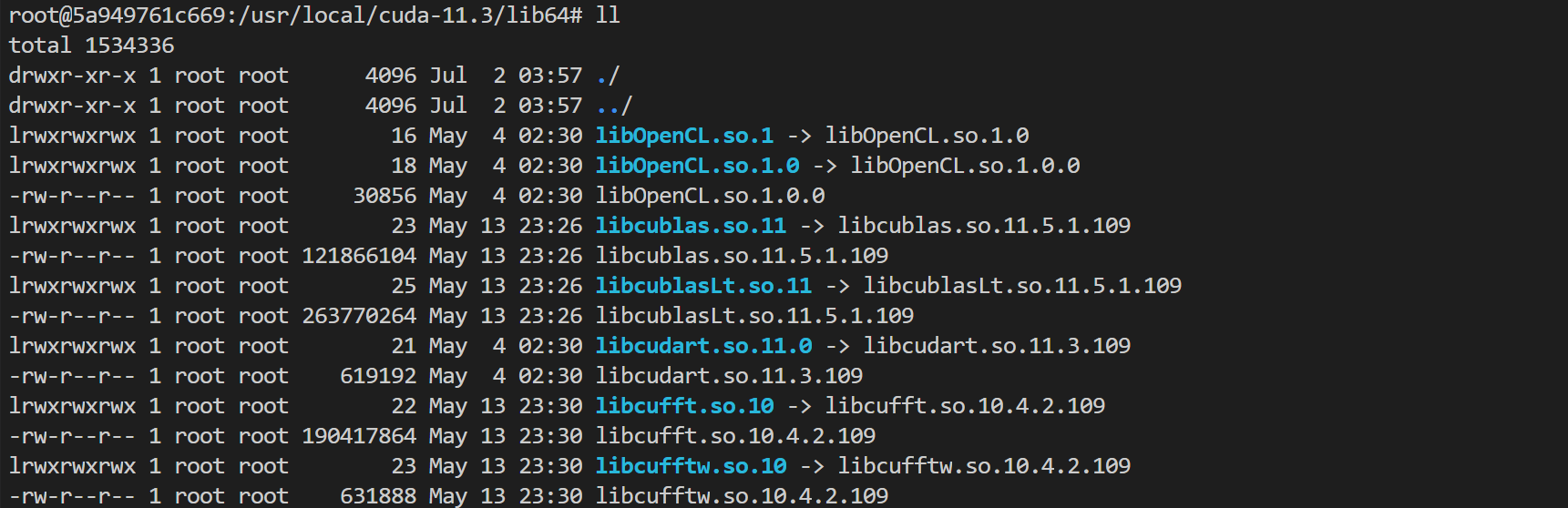
ENV LD_LIBRARY_PATH /usr/local/nvidia/lib:/usr/local/nvidia/lib64
其中
/usr/local/nvidia/lib 指向 cuda 路径的软连接,为 cuda 准备。而附带 cudnn 的版本只做到了安装 cudnn ,并没有为 cudnn 指定 LD_LIBRARY_PATH,因此可能会导致报错 Warning ,从而使用不了 GPU 资源,报错如下所示:Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directoryCannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU...
如果出现此类报错,可以尝试手动添加上 cudnn 路径。此处可以执行以下命令运行镜像,查看 libcudnn.so 所在的路径。
docker run -it nvidia/cuda:[tag] /bin/bash
由源码可知,cudnn 通过
apt-get install 命令安装,默认在 /usr/lib 下。本文例中 libcudnn.so.8 的实际路径则是在 /usr/lib/x86_64-linux-gnu# 下,用冒号在后面补充上。可能会因为版本系统不同等原因,实际路径有偏差,以源码和实际观察为准。
后续操作
常见问题
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback