在 TKE 上使用 AIBrix 进行多节点分布式推理
Download
聚焦模式
字号
概述
AIBrix 是在2025年2月开源的云原生大模型推理控制平面项目,专为优化大规模语言模型(LLM)的生产化部署设计。作为首个深度集成 vLLM 的 Kubernetes 全栈方案,它提供了 LoRA 动态加载、多节点推理、异构 GPU 调度、分布式 KV 缓存等多种核心特性。
分布式推理是指在多个节点或设备上拆分和处理 LLM 模型的技术,这种方法对于单台机器内存无法容纳的大型模型尤其有用。AIBrix 采用 Ray 作为其分布式计算框架,结合 KubeRay 来协调 Ray 集群实现了分布式推理技术。
AIBrix 为管理 RayCluster 引入了两个关键 API,即 RayClusterReplicaSet 和 RayClusterFleet。RayClusterFleet 管理 RayClusterReplicaSet,RayClusterReplicaSet 管理 RayCluster,三者之间的关系与 Kubernetes 的核心概念 Deployment、ReplicaSet、Pod 之间类似,大部分情况下,用户只需要使用 RayClusterFleet。
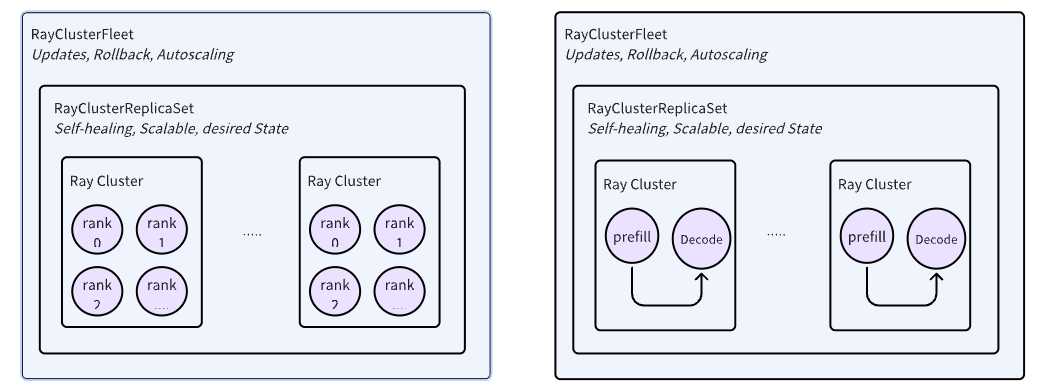
在本文中,我们将介绍如何在 TKE 集群上使用 AIBrix 进行分布式推理。
镜像说明:
在 TKE 环境中,默认会提供免费的 DockerHub 镜像加速服务,因此中国大陆用户也可以直接拉取到镜像,但速度可能较慢。建议将镜像同步至 容器镜像服务 TCR 中提高镜像拉取速度,并在 YAML 文件中替换相应的镜像地址。
操作步骤
1. 创建 TKE 集群
集群类型:TKE 标准集群。
Kubernetes 版本:需要大于等于 1.28,建议选择最新版本。本文使用的是 1.30。
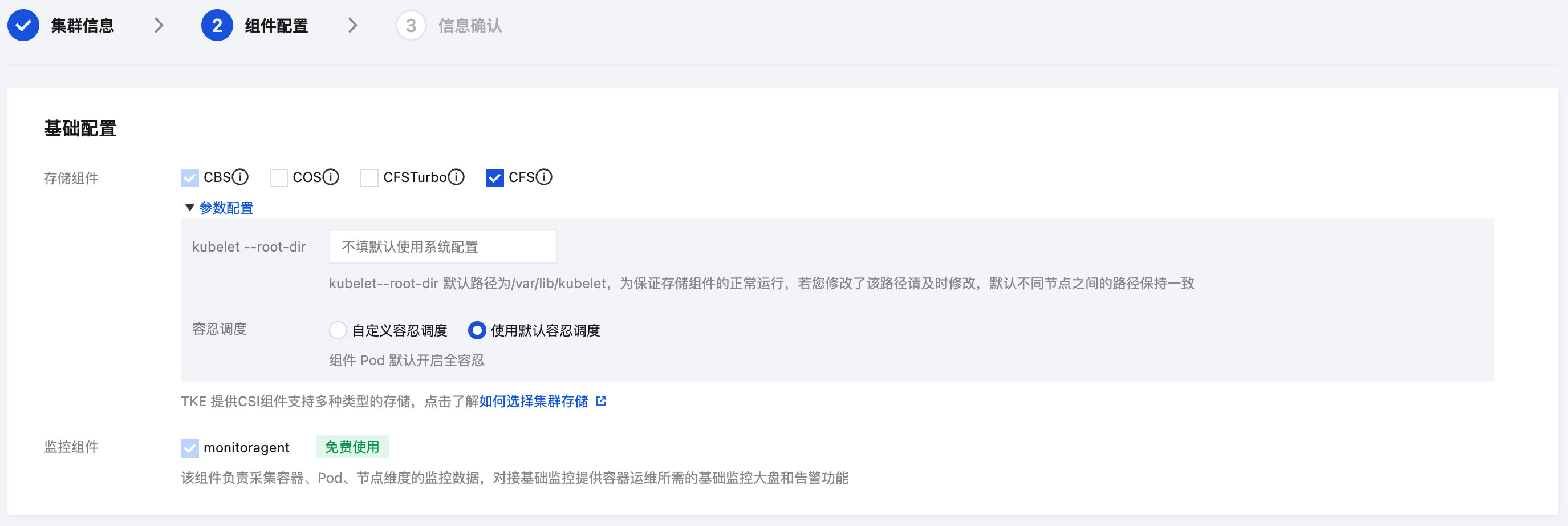
基础配置:存储组件需勾选 CFS,如下图所示:
2. 创建超级节点
3. 下载模型
3.1 创建 StorageClass
通过控制台创建 StorageClass:
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧导航中的存储,在 StorageClass 页面单击新建。
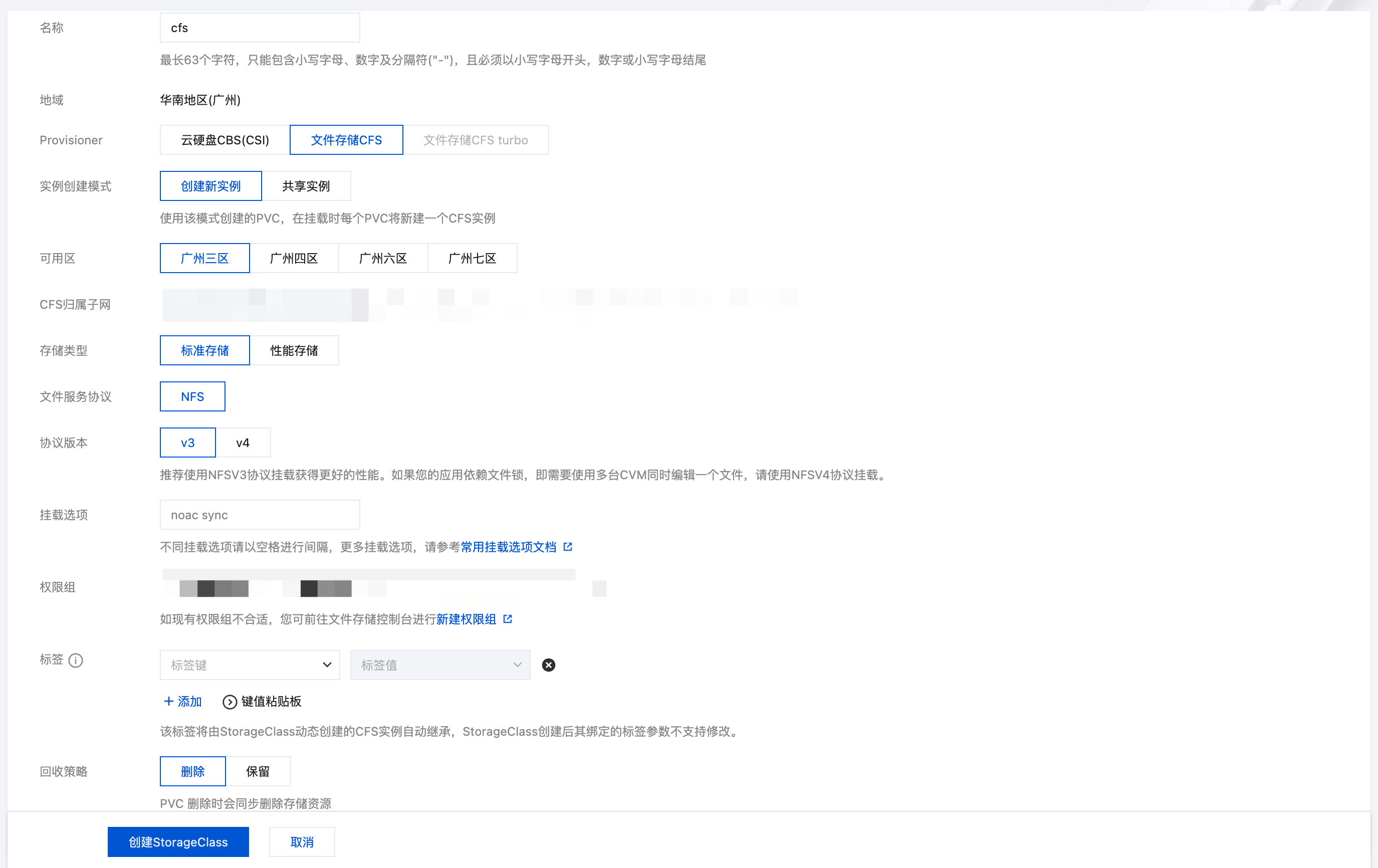
3. 在新建存储页面,根据实际需求,创建 CFS 类型的 StorageClass。如下图所示:
3.2 创建 PVC
通过控制台创建 PVC:
1. 在集群列表中,单击集群 ID,进入集群详情页。
2. 选择左侧导航中的存储,在 PersistentVolumeClaim 页面单击新建。
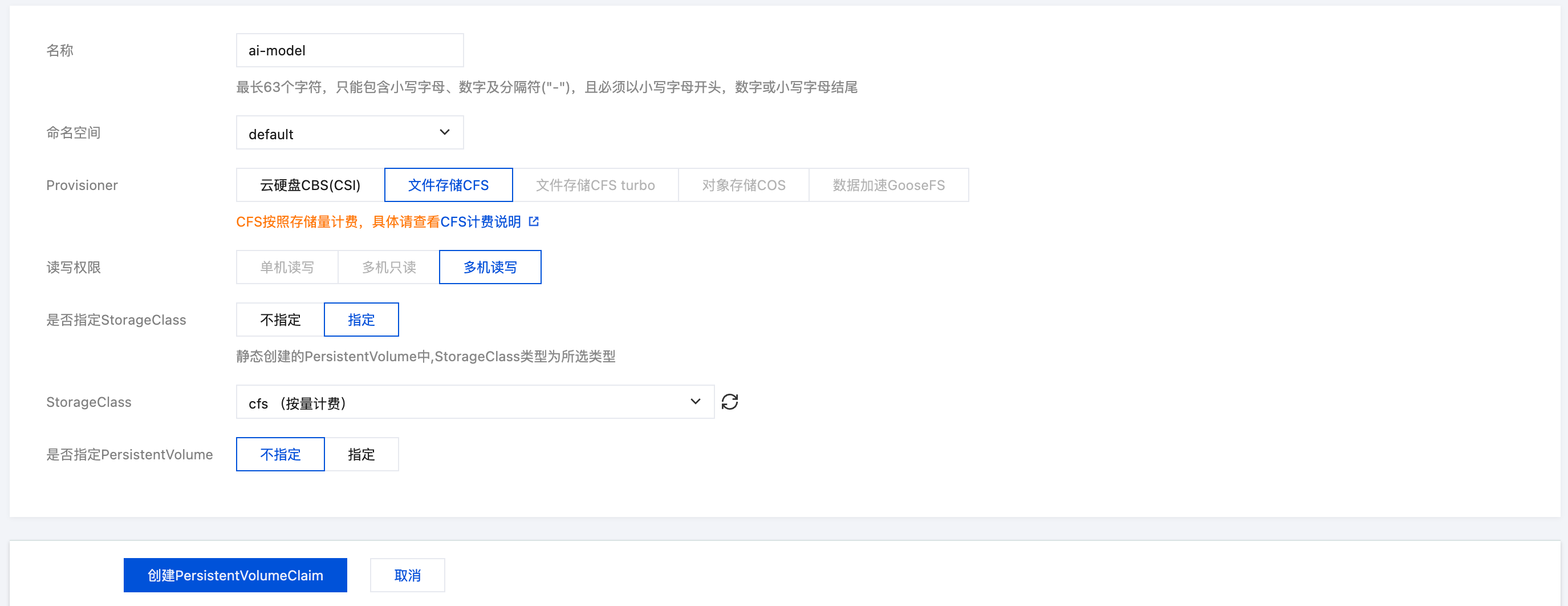
3. 在新建存储页面,根据实际需求,创建存储模型文件的 PVC。如下图所示:
3.3 使用 Job 下载模型文件
创建一个 Job 用于下载大模型文件到 CFS。
说明:
本文示例中所用模型为 Qwen2.5-Coder 的 7B 版本。
apiVersion: batch/v1kind: Jobmetadata:name: download-modellabels:app: download-modelspec:template:metadata:name: download-modellabels:app: download-modelannotations:eks.tke.cloud.tencent.com/root-cbs-size: "100" # 超级节点系统盘默认只有 20Gi,vllm 镜像解压后会撑爆磁盘,用这个注解自定义一下系统盘容量(超过20Gi的部分会收费)。spec:containers:- name: vllmimage: vllm/vllm-openai:v0.7.1command:- modelscope- download- --local_dir=/data/model/Qwen2.5-Coder-7B-Instruct- --model=Qwen/Qwen2.5-Coder-7B-InstructvolumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-model # 此处为创建的 PVC 名称restartPolicy: OnFailure
4. 安装 AIBrix
# Install component dependencieskubectl create -f https://github.com/vllm-project/aibrix/releases/download/v0.2.1/aibrix-dependency-v0.2.1.yaml# Install aibrix componentskubectl create -f https://github.com/vllm-project/aibrix/releases/download/v0.2.1/aibrix-core-v0.2.1.yaml
检查 AIBrix 安装情况,确认所有 Pod 都处于 Running 状态。
kubectl -n aibrix-system get pods
5. 部署模型
创建 RayClusterFleet 部署 Qwen2.5-Coder-7B-Instruct 模型。
apiVersion: orchestration.aibrix.ai/v1alpha1kind: RayClusterFleetmetadata:labels:app.kubernetes.io/name: aibrixapp.kubernetes.io/managed-by: kustomizename: qwen-coder-7b-instructspec:replicas: 1selector:matchLabels:model.aibrix.ai/name: qwen-coder-7b-instructstrategy:rollingUpdate:maxSurge: 25%maxUnavailable: 25%type: RollingUpdatetemplate:metadata:labels:model.aibrix.ai/name: qwen-coder-7b-instructannotations:ray.io/overwrite-container-cmd: "true"spec:rayVersion: "2.10.0" # 必须匹配容器内的 Ray 版本headGroupSpec:rayStartParams:dashboard-host: "0.0.0.0"template:metadata:annotations:eks.tke.cloud.tencent.com/gpu-type: V100 # 指定 GPU 卡型号eks.tke.cloud.tencent.com/root-cbs-size: '100' # 超级节点系统盘默认只有 20Gi,vllm 镜像解压后会撑爆磁盘,用这个注解自定义一下系统盘容量(超过20Gi的部分会收费)。spec:containers:- name: ray-headimage: vllm/vllm-openai:v0.7.1ports:- containerPort: 6379name: gcs-server- containerPort: 8265name: dashboard- containerPort: 10001name: client- containerPort: 8000name: servicecommand: ["/bin/bash", "-lc", "--"]args:- |ulimit -n 65536;echo head;$KUBERAY_GEN_RAY_START_CMD & KUBERAY_GEN_WAIT_FOR_RAY_NODES_CMDS;vllm serve /data/model/Qwen2.5-Coder-7B-Instruct \\--served-model-name Qwen/Qwen2.5-Coder-7B-Instruct \\--tensor-parallel-size 2 \\--distributed-executor-backend ray \\--dtype=halfresources:limits:cpu: "4"nvidia.com/gpu: 1requests:cpu: "4"nvidia.com/gpu: 1volumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-model # 此处为创建的 PVC 名称workerGroupSpecs:- replicas: 1minReplicas: 1maxReplicas: 5groupName: small-grouprayStartParams: {}template:metadata:annotations:eks.tke.cloud.tencent.com/gpu-type: V100 # 指定 GPU 卡型号eks.tke.cloud.tencent.com/root-cbs-size: '100' # 超级节点系统盘默认只有 20Gi,vllm 镜像解压后会撑爆磁盘,用这个注解自定义一下系统盘容量(超过20Gi的部分会收费)。spec:containers:- name: ray-workerimage: vllm/vllm-openai:v0.7.1command: ["/bin/bash", "-lc", "--"]args:["ulimit -n 65536; echo worker; $KUBERAY_GEN_RAY_START_CMD"]lifecycle:preStop:exec:command: ["/bin/sh", "-c", "ray stop"]resources:limits:cpu: "4"nvidia.com/gpu: 1requests:cpu: "4"nvidia.com/gpu: 1volumeMounts:- name: datamountPath: /data/modelvolumes:- name: datapersistentVolumeClaim:claimName: ai-model # 此处为创建的 PVC 名称
6. 验证 API
当 RayClusterFleet 部署的 Pod 成功运行以后,可以通过 kubectl port-forward 快速验证 API。
# 获取 service 名称svc=$(kubectl get svc -o name | grep qwen-coder-7b-instruct)# 使用 port-forward 功能暴露 API 到本地的 18000 端口kubectl port-forward $svc 18000:8000# 启动另外一个终端,运行如下命令测试 APIcurl -X POST "http://localhost:18000/v1/chat/completions" \\-H "Content-Type: application/json" \\-d '{"model": "Qwen/Qwen2.5-Coder-7B-Instruct","messages": [{"role": "system", "content": "你是一个AI编程助手"},{"role": "user", "content": "用 Python 实现快速排序算法"}],"temperature": 0.3,"max_tokens": 512,"top_p": 0.9}'
常见问题
aibrix-kuberay-operator 无法启动,报错 runtime/cgo: pthread_create failed: Operation not permitted
检查 aibrix-kuberay-operator 是否部署在超级节点上,如果 aibrix-kuberay-operator 部署在超级节点上,参见如下两种解决方法:
1. 修改 aibrix-kuberay-operator 的 Deployment,在 Pod Template 中增加以下注解:
eks.tke.cloud.tencent.com/cpu-type: intel # 指定 CPU 类型为 intel
2. 参考 设置工作负载的调度规则,将 aibrix-kuberay-operator 调度到普通节点上。
如何设置 API 密钥限制访问?
vLLM 提供了以下两种方式设置 API 密钥:
1. 设置
--api-key 参数。2. 设置环境变量
VLLM_API_KEY。修改 RayClusterFleet 的定义,在 headGroupSpec 中按上面任意一种方式设置 API 密钥之后,就需要在请求中带上以下 Header 进行访问:
Authorization: Bearer <VLLM_API_KEY>
文档反馈