容器服务(TKE) 日志
Download
聚焦模式
字号
操作场景
日志采集功能是容器服务 TKE 为用户提供的集群内日志采集工具,可以将集群内服务或集群节点特定路径文件的日志发送至 腾讯云日志服务 CLS消息队列 CKafka 版。日志采集功能适用于需要对 Kubernetes 集群内服务日志进行存储和分析的用户。
日志采集功能需要为每个集群手动开启并配置采集规则。日志采集功能开启后,日志采集 Agent 会在集群内以 DaemonSet 的形式运行,并根据用户通过日志采集规则配置的采集源、CLS 日志主题和日志解析方式,从采集源进行日志采集,将日志内容发送到日志消费端。开启日志采集功能操作步骤可参见文档。
前提条件
请在开启前保证集群节点上有足够资源。开启日志采集功能会占用您集群的部分资源。
占用 CPU 资源:0.11 - 1.1核,日志量过大时可根据情况自行调大。
占用内存资源:24 - 560MB,日志量过大时可根据情况自行调大。
日志长度限制:单条512K,如超过会截断。
若使用日志采集功能,请确认 Kubernetes 集群内节点能够访问日志消费端。且以下日志采集功能仅支持 Kubernetes 1.10 及以上版本集群。
概念
日志采集 Agent:TKE 用于采集日志信息的 Agent,采用 Loglistener,在集群内以 DaemonSet 的方式运行。
日志规则:用户可以使用日志规则指定日志的采集源、日志主题、日志解析方式和配置过滤器。
日志采集 Agent 会监测日志采集规则的变化,变化的规则会在最多 10s 内生效。
多条日志采集规则不会创建多个 DaemonSet,但过多的日志采集规则会使得日志采集 Agent 占用的资源增加。
日志源:包含指定容器标准输出、容器内文件以及节点文件。
在采集容器标准输出日志时,用户可选择所有容器、或指定工作负载和指定 Pod Labels 内的容器服务日志作为日志的采集源。
在采集容器文件路径日志时,用户可指定工作负载或 Pod Labels 内容器的文件路径日志作为采集源。
在采集节点文件路径日志时,用户可设定日志的采集源为节点文件路径日志。
消费端:用户选择日志服务 CKafka 主题作为消费端。
操作步骤
开启日志采集
1. 登录 容器服务控制台。
2. 选择左侧导航栏中的集群,单击目标集群的“ID”进入集群基本信息页面。
3. 在左侧导航栏选择日志页签,在业务日志模块右上角开启日志采集。
配置日志规则
1. 在日志采集页面顶部选择业务日志,单击前往配置。
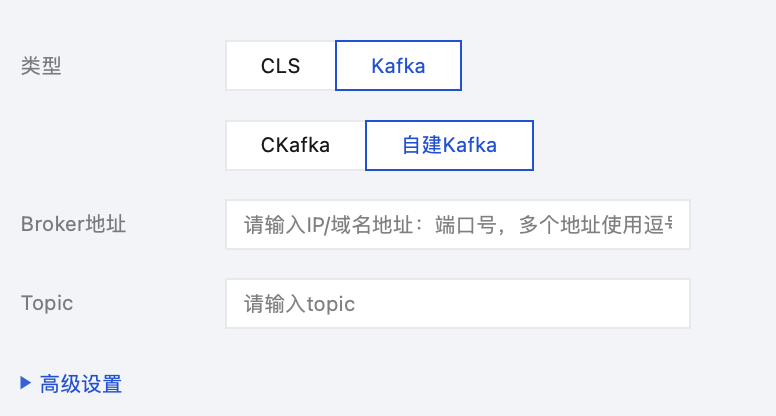
2. 在新建日志采集规则页面中配置日志服务消费端,在消费端 > 类型中选择 Kafka 。
支持用户选择写入 CKafka 或用户自建 Kafka ,当选择 CKafka 时,需要填写实例 ID 和实例 Topic ;当选择自建 Kafka 时,需按要求填写 Broker 地址和 Topic。
说明:
如果 Kafka 实例与节点不在同一个 VPC 下,会提示创建 Kafka 实例接入点后再进行日志投递。
在集群的 daemonSet 资源中,选择 kube-system 命名空间,找到 tke-log-agent pod 下的 kafkalistener 容器,可以查询 kafka 采集器的日志。
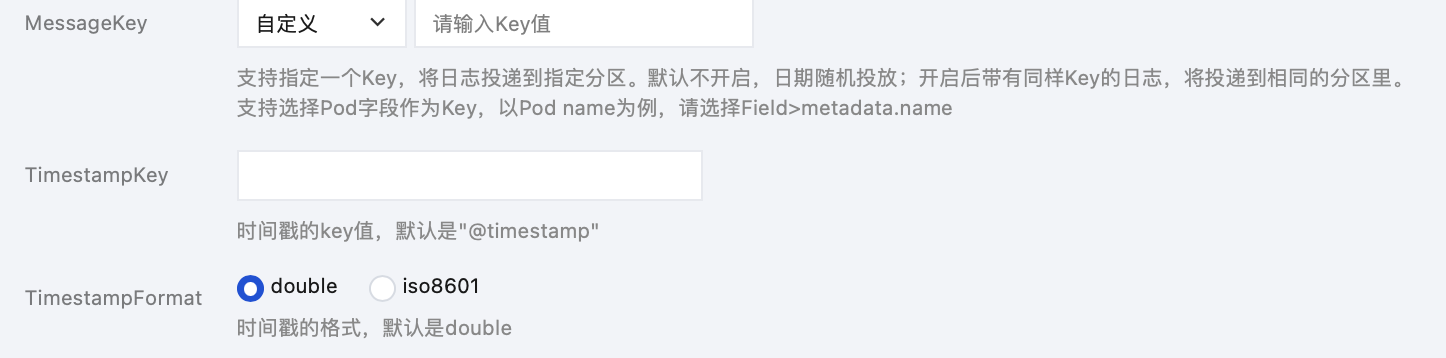
支持在高级设置内通过指定 Key 值将日志投递到指定分区,该功能默认不开启,日志随机投放,当开启后,带有同样 Key 值的日志,将投递到相同的分区。支持输入 TimestampKey(默认@timestamp)和指定时间戳格式。
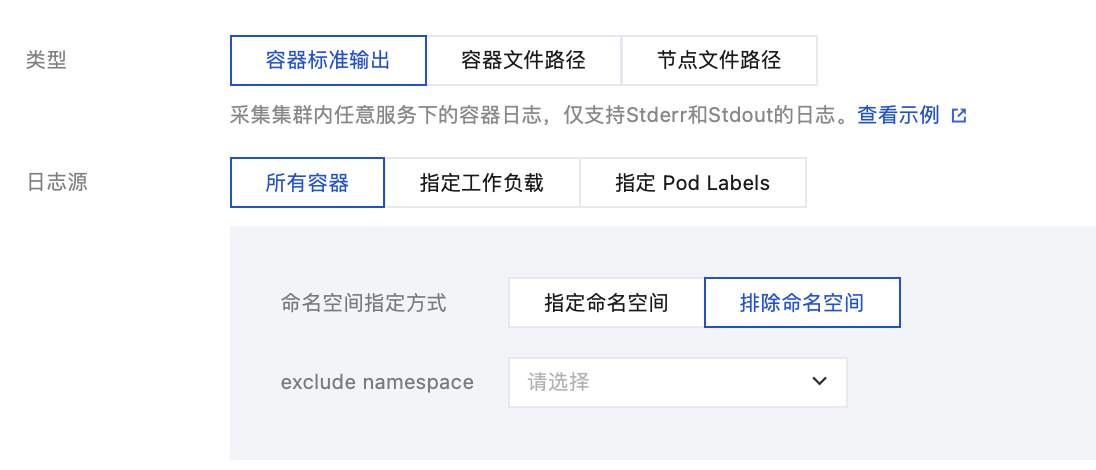
3. 在“新建日志采集规则”页面中,选择采集类型,并配置日志源。目前采集类型支持容器标准输出、容器文件路径和节点文件路径。
选择容器标准输出采集类型,并根据需求配置日志源。该类型日志源支持一次选择多个 Namespace 的工作负载。
选择容器文件路径采集类型,并配置日志源。
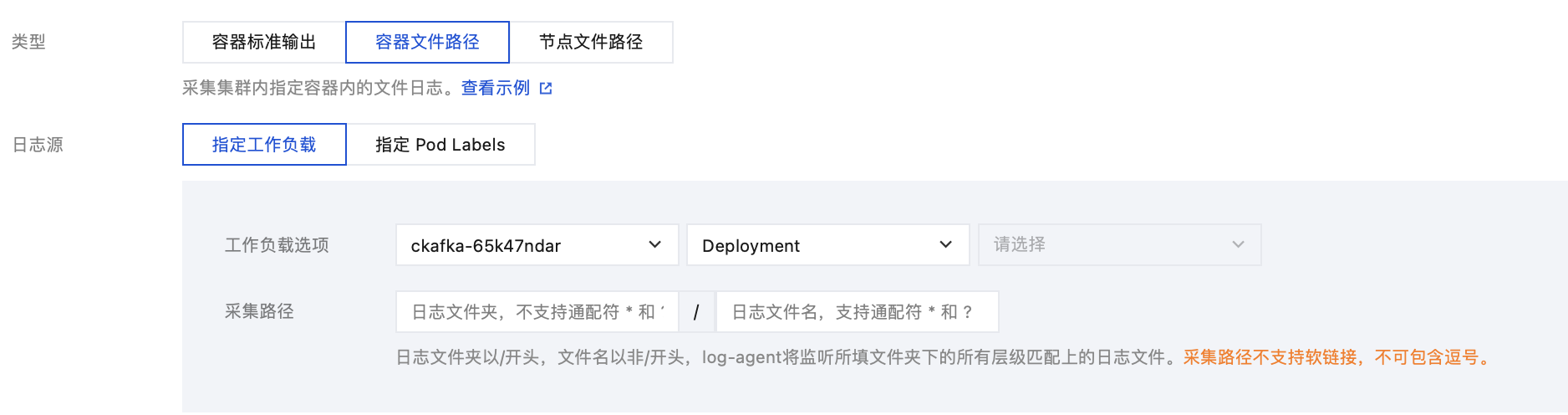
采集文件路径支持文件路径和通配规则,例如当容器文件路径为
/opt/logs/*.log,可以指定采集路径为 /opt/logs,文件名为 *.log。注意
“容器文件路径” 不能为符号链接或硬链接,否则会导致软链接的实际路径在采集器的容器内不存在,采集日志失败。
选择节点文件路径采集类型。
采集路径支持以文件路径和通配规则的方式填写,例如当需要采集所有文件路径形式为
/opt/logs/service1/*.log,/opt/logs/service2/*.log,可以指定采集路径的文件夹为 /opt/logs/service*,文件名为 *.log。您可根据实际需求自定义添加 Key-Value 形式的 metadata,metadata 将会添加到日志记录中。

注意:
“节点文件路径” 不能为软链接或硬链接,否则会导致软链接的实际路径在采集器不存在,采集日志失败。
一个节点日志文件只能被一个日志主题采集。
说明:
请确保 Pod 的 label 配置正确,即 Pod 的 label,而非工作负载的 label。您可以按照以下步骤查询:
1.1 登录 容器服务控制台,选择左侧导航栏中的集群。
1.2 在集群管理页面,选择集群 ID,进入集群的基本信息页面。
1.3 在工作负载中,选择具体的工作负载名称,进入工作负载详情页。
1.4 在 YAML 页签中,查看 template 下的 labels。如下图所示:
对于“容器的标准输出”及“容器内文件”(不包含“节点文件路径”即 hostPath 挂载),除了原始的日志内容, 还会带上容器或 kubernetes 相关的元数据(例如:产生日志的容器 ID)一起上报到 CLS,方便用户查看日志时追溯来源或根据容器标识、特征(例如:容器名、labels)进行检索。
容器或 kubernetes 相关的元数据请参考下方表格:
字段名 | 含义 |
container_id | 日志所属的容器 ID。 |
container_name | 日志所属的容器名称。 |
image_name | 日志所属容器的镜像名称 IP。 |
namespace | 日志所属 pod 的 namespace。 |
pod_uid | 日志所属 pod 的 UID。 |
pod_name | 日志所属 pod 的名字。 |
pod_lable_{label name} | 日志所属 pod 的 label(例如一个 pod 带有两个 label:app=nginx,env=prod,则在上传的日志会附带两个 metedata:pod_label_app:nginx,pod_label_env:prod)。 |
4. 配置采集策略。您可以选择全量或者增量。
全量:全量采集指从日志文件的开头开始采集。
增量:增量采集指从距离文件末尾1M处开始采集(若日志文件小于1M,则等同于全量采集)。
注意:
全量采集场景:采集规则生效延时:为确保采集到 Pod 启动过程中的所有关键日志,请配置全量采集策略。全量采集策略能够在采集规则完全生效前,无差别地收集所有日志数据,有效避免日志丢失现象。
增量采集场景:采集路径为云硬盘 CBS:采集路径为云硬盘时建议配置增量采集策略,以免 Pod 重建产生重采。
异常场景:采集路径为文件存储 CFS:配置全量采集会造成重采,且多个 Pod 可能同时上报相同日志,造成日志服务重复计费,建议日志源不要使用 CFS。
5. 单击下一步,选择日志解析方式。
编码模式:支持 UTF-8 和 GBK。
提取模式:支持多种类型的提取模式,详情如下:
解析模式 | 说明 | 相关文档 |
单行全文 | 一条日志仅包含一行的内容,以换行符 \\n 作为一条日志的结束标记,每条日志将被解析为键值为 CONTENT 的一行完全字符串,开启索引后可通过全文检索搜索日志内容。日志时间以采集时间为准。 | |
多行全文 | 指一条完整的日志跨占多行,采用首行正则的方式进行匹配,当某行日志匹配上预先设置的正则表达式,就认为是一条日志的开头,而下一个行首出现作为该条日志的结束标识符,也会设置一个默认的键值 CONTENT,日志时间以采集时间为准。支持自动生成正则表达式。 | |
单行 - 完全正则 | 指将一条完整日志按正则方式提取多个 key-value 的日志解析模式,您需先输入日志样例,其次输入自定义正则表达式,系统将根据正则表达式里的捕获组提取对应的 key-value。支持自动生成正则表达式。 | |
多行 - 完全正则 | 适用于日志文本中一条完整的日志数据跨占多行(例如 Java 程序日志),可按正则表达式提取为多个 key-value 键值的日志解析模式,您需先输入日志样例,其次输入自定义正则表达式,系统将根据正则表达式里的捕获组提取对应的 key-value。支持自动生成正则表达式。 | |
JSON | JSON 格式日志会自动提取首层的 key 作为对应字段名,首层的 value 作为对应的字段值,以该方式将整条日志进行结构化处理,每条完整的日志以换行符 \\n 为结束标识符。 | |
分隔符 | 指一条日志数据可以根据指定的分隔符将整条日志进行结构化处理,每条完整的日志以换行符 \\n 为结束标识符。日志服务在进行分隔符格式日志处理时,您需要为每个分开的字段定义唯一的 key,无效字段即无需采集的字段可填空,不支持所有字段均为空。 | |
组合解析 | 当您的日志结构太过复杂,涉及多种解析模式,单种解析模式(如 Nginx 模式、完整正则模式、JSON 模式等)无法满足日志解析需求时,您可以使用 Loglistener 组合解析格式解析日志,此模式支持用户在控制台输入代码(json 格式)用来定义日志解析的流水线逻辑。您可添加一个或多个 Loglistener 插件处理配置,Loglistener 会根据处理配置顺序逐一执行。 |
过滤器:LogListener 仅采集符合过滤器规则的日志,Key 支持完全匹配,过滤规则支持正则匹配,如仅采集 ErrorCode = 404 的日志。您可以根据需求开启过滤器并配置规则。
说明:
一个日志主题目前仅支持一个采集配置,请保证选用该日志主题的所有容器的日志都可以接受采用所选的日志解析方式。若在同一日志主题下新建了不同的采集配置,旧的采集配置会被覆盖。
6. 单击完成,完成投递到 CKafka 的日志采集规则创建。
文档反馈