HBase sequential write may suffer from region server hotspotting if your row key is monotonically increasing. Phoenix provides a way to transparently salt the row key with a salting byte for a particular table. You need to specify this in table creation time by specifying a table property "SALT_BUCKETS" with a value from 1 to 256. Like this:
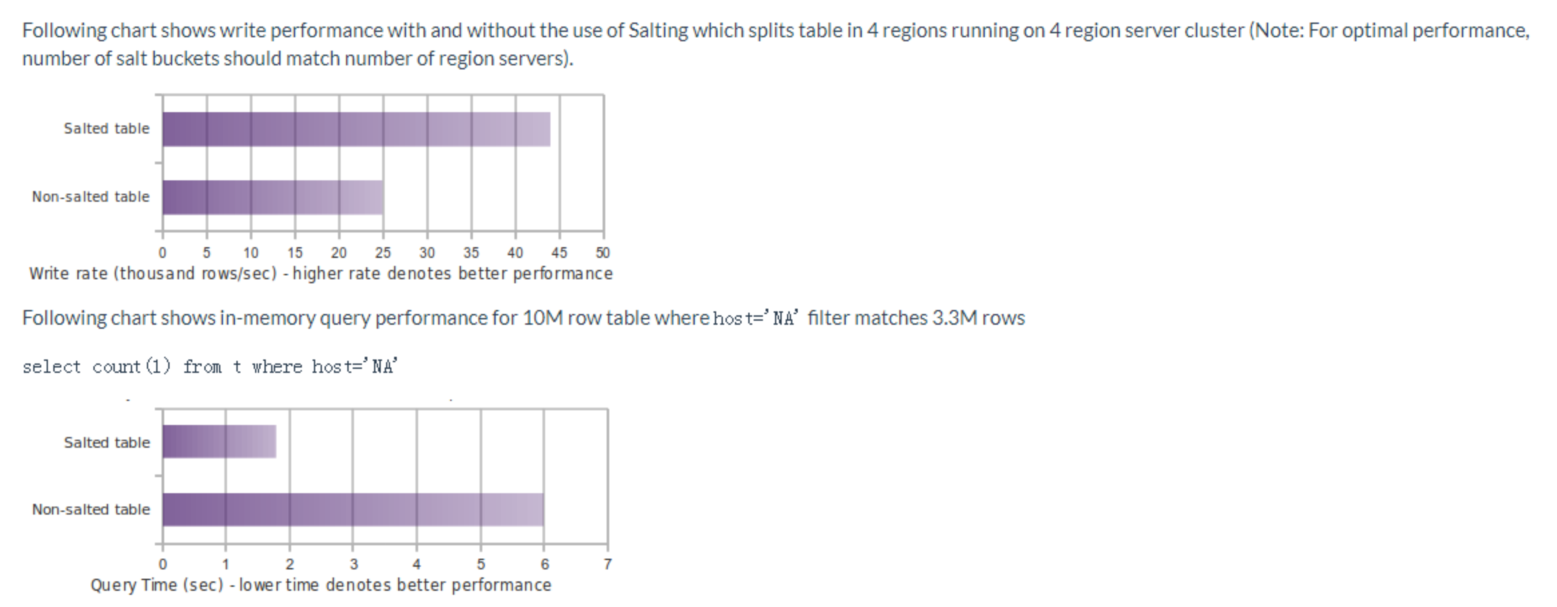
Salting the row key provides a way to mitigate the problem caused by HBase sequential write. With salted tables, you don't need to be knowledgeable about the row key design in HBase. Below is Phoenix's official performance comparison of read and write performance between salted and non-salted tables:
Secondary indexes are an orthogonal way to access data from its primary access path. In HBase, you have a single index that is lexicographically sorted on the primary row key. Access to records in any way other than through the primary row requires scanning over potentially all the rows in the table to test them against your filter. With secondary indexing, the columns or expressions you index form an alternate row key to allow point lookups and range scans along this new axis.
Configuring Secondary Indexing in Phoenix
Phoenix on EMR supports Phoenix's secondary indexing. If you need to use non-transactional, variable indexing, just follow the steps below to configure it. Go to the component management page in the EMR console, click HBase, select Configuration > Configuration Management, and add three configuration items in hbase-site.xml: hbase.regionserver.wal.codec, hbase.region.server.rpc.scheduler.factory.class, and hbase.rpc.controllerfactory.class. The detailed configuration is as follows: