Architecture Overview
Download
フォーカスモード
フォントサイズ
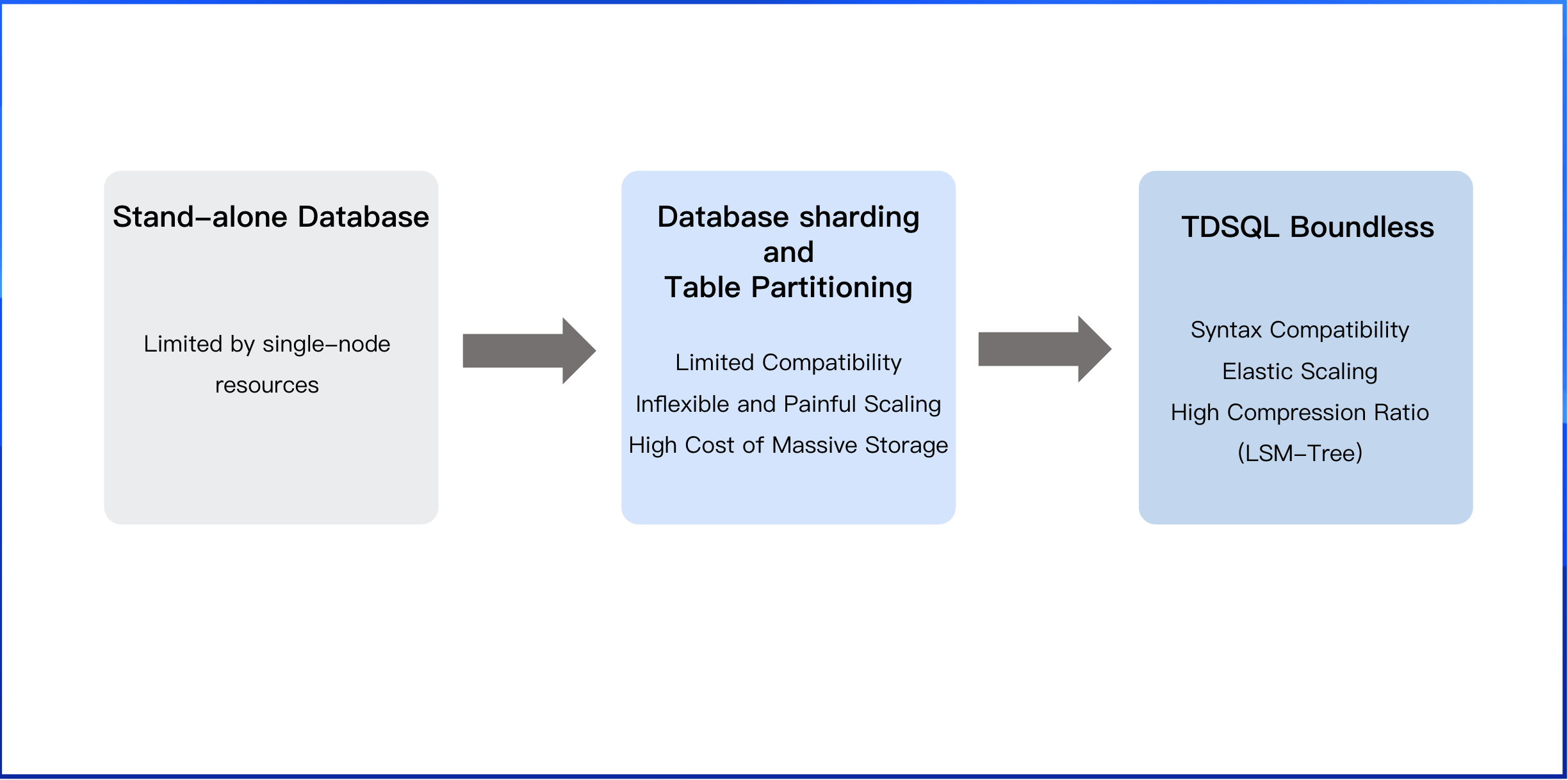
Why we built TDSQL Boundless?
Tencent Cloud built TDSQL Boundless to address the performance bottlenecks of single-instance databases and the inherent limitations of sharding solutions that arise with business growth. Here are the core considerations that drove its development.
1. Breaking free from the single-instance performance ceiling
As business grows and data volume increases, a single MySQL instance inevitably hits a hardware ceiling - limited by its disk, memory, and CPU. While you can always "scale up" by buying bigger and more expensive hardware, this approach is costly and only kicks the can down the road. It's a temporary fix, not a long-term scaling strategy.
2. Tackling the common challenges of database sharding
Sharding is a common next step, but it's far from a perfect solution. It comes with significant drawbacks:
Limited Compatibility: Sharding often breaks full MySQL conpatibility. Features developers take for granted—like global indexes, cross-shard range queries, cross-table joins, and distributed transactions—become difficult, if not impossible. This forces developers to code around the sharding logic, dramatically increasing application complexity. For established companies with complex legacy systems, the cost and risk of such a migration are often prohibitive.
Inflexible and Painful Scaling: With sharding, you have to decide on your sharding strategy upfront, essentially guessing your future needs. Changing this later is a massive headache. Scaling out or in isn't a simple, online operation; it often requires a complex data redistribution and migration. Imagine an e-commerce site trying to consolidate database instances after a big holiday sale—it becomes a slow, manual process of exporting and importing data.
High Costs of Massive Storage: Traditional B+Tree storage engines like InnoDB aren't very space-efficient. As your dataset grows into terabytes and petabytes - especially with a high volume of "cold" or infrequently accessed data - your storage costs can spiral out of control.
The TDSQL Boundless solution
We built TDSQL Boundless from the ground up to overcome these shortcomings of tranditional sharding. It offers deep MySQL compatibility and seamless, elastic scaling, freeing developers from the operational burden of managing shards. Under the hood, TDSQL Boundless uses an LSM-Tree storage engine to deliver exceptional data compression, making it the perfect solution for managing enormous datasets while reining in your storage costs.
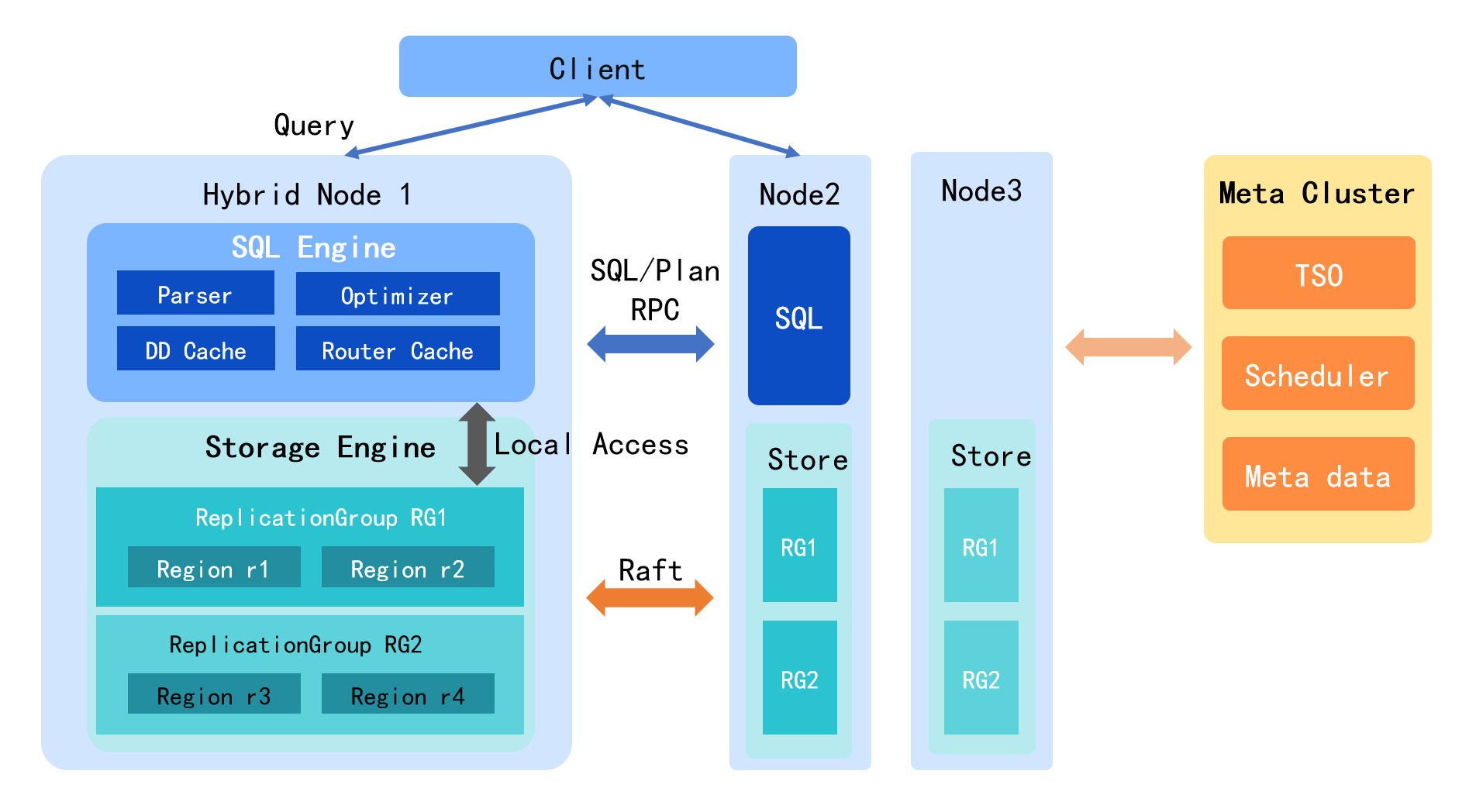
System Architecture
TDSQL Boundless employs a decoupled compute and storage architecture that allows for independent, elastic scaling of resources. The system is composed of 3 core components:
Component | Roles and Features |
SQLEngine (Compute Layer) | Responsible for SQL parsing, query optimization, and execution plan generation. Provides distributed capabilities such as routing management, MPP (massively parallel processing), and Online DDL. Features stateless design, enabling rapid and seamless scaling of compute layer. |
Storage Engine (Storage Layer) | Manages the persistent storage of all data. Uses the Raft consensus protocol to ensure data consistency across multiple replicas. Automatically handles data splitting, merging, and migration based on node load. |
MetaCluster | Assigns global transaction timestamps to ensure data consistency. Coordinates data scheduling and management tasks within the storage layer. Ensures consistency of distributed transactions and synchronization of system states. |
Workflow: Clients connect to the SQLEngine (compute layer), which accesses data from the Storage Engine (storage layer) via RPC calls. The MetaCluster centrally coordinates timestamp allocation and task scheduling to enable independent AS of resources at each tier.
フィードバック