Apache Druid is a distributed data processing system supporting real-time and multi-dimensional online analytical processing (OLAP). It is used to implement quick and interactive query and analysis for large data sets.
Basic Characteristics
Characteristics of Apache Druid:
It supports interactive queries with a subsecond response time and has various features such as multi-dimensional filtering, ad hoc attribute grouping, and quick data aggregation.
It supports highly concurrent and real-time data ingestion to ensure real-timeliness for data ingestion and query.
It features high scalability. With the distributed shared-nothing architecture, it supports quick processing of petabytes of data with hundreds of billions of events and sustains thousands of concurrent queries per second.
It allows simultaneous online queries by multiple tenants.
It supports high availability (HA) and rolling update.
Use Cases
Druid is most frequently used for flexible, quick, multi-dimensional OLAP analysis on big data. In addition, as it supports ingestion of pre-aggregated data and analysis of aggregated data based on timestamps, it is usually used in time-series data processing and analysis, such as ad platform, real-time metric monitoring, recommendation model, and search model.
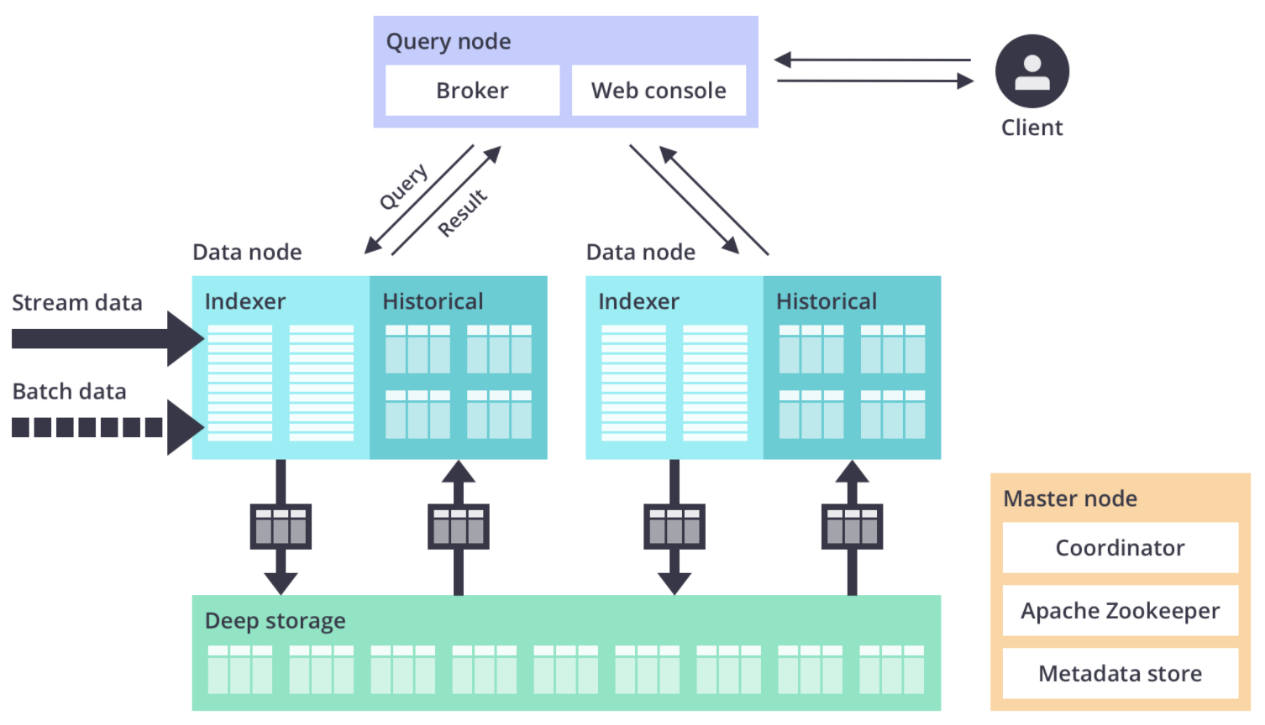
System and Architecture
Druid uses a microservice-based architecture. All core services in it can be deployed on different hardware devices either separately or jointly.
Enhanced EMR Druid
A lot of improvements have been made on EMR Druid based on Apache Druid, including integration with EMR Hadoop and relevant Tencent Cloud ecosystem, convenient monitoring and OPS, and easy-to-use product APIs, so that you can use it out of the box in an OPS-free manner.
Currently, EMR Druid supports the following features: