Practice Tutorial on Switching HDFS DataNode Maintenance Status
Download
포커스 모드
폰트 크기
마지막 업데이트 시간: 2025-01-03 15:05:10
The DataNode maintenance status (IN_MAINTENANCE) is applicable for scenes where the DataNode is temporarily offline but does not require data migration, such as quick service repairs or disk replacement. In the DataNode maintenance mode, the operation entry is not enabled by default in the console and requires manual configuration by the user for support.
Note:
1. This operation is only supported for Hadoop 3.x and later versions.
2. DataNodes in a paused status do not support maintenance operations.
Enabling Console Switching Management Status Operation Entry
1. Modify the contents of hdfshosts to JSON format.
Use the console cluster script feature to execute the script files hdfshosts_txt_to_json.sh and hdfshosts_txt_to_json_rollback.sh on the Master node. The contents of the script files are as follows:
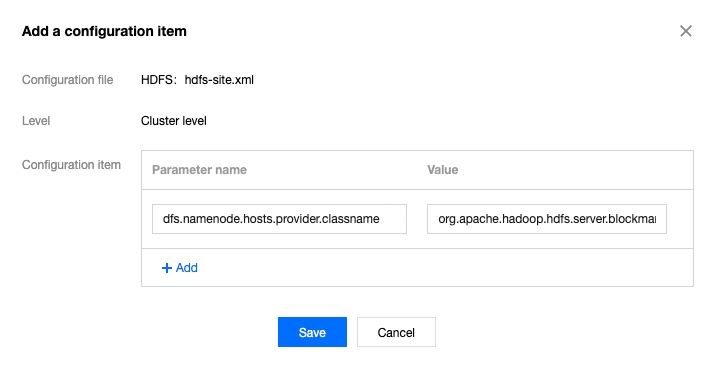
Add the configuration parameter dfs.namenode.hosts.provider.classname with the value org.apache.hadoop.hdfs.server.blockmanagement.CombinedHostFileManager.
3. After the configuration is saved and applied, restart NameNode.
4. Check via WebUI or by running hdfs dfsadmin -report.
5. (Recommended) Perform a scale-in and scale-out operation on the core nodes once, as the above operations will modify the hdfshosts file, preventing potential issues in the future.
6.The Switch Management Status button will appear in the HDFS Role Management section.
DataNode Entering Maintenance Status
1. Log in to the EMR console and click the corresponding Cluster ID/Nam in the cluster list to enter the cluster details page.
2. On the cluster details page, click Cluster Services, and then select HDFS component and go to Operations > Role Management in the top right corner.
3. After checking the DataNode role whose operation status is started in role management, switch the status and put DataNode into maintenance status operation.
4. When you choose to enter maintenance status, you can set the maintenance duration. During the ma4.intenance period, the DataNode will cease to provide external services and no data migration will occur. If the service is not recovered after the configured maintenance period expires, data migration will start.
DataNode Exiting Maintenance Status
1. If the node repair is completed within the maintenance period, the DataNode will automatically resume providing external services after the timeout. However, the maintenance status should be manually exited by the user via the console.
2. Log in to the EMR console and click the corresponding Cluster ID/Name in the cluster list to enter the cluster details page.
3. After selecting the DataNode role with the operation status set to Started (Under Maintenance) in Role Management, change the status to take DataNode out of maintenance mode operation.