Overview of Scenario-Based Solutions
소셜 엔터테인먼트
이커머스 라이브 방송
Audio/Video Call
원거리 실시간 조작
스마트 고객 서비스
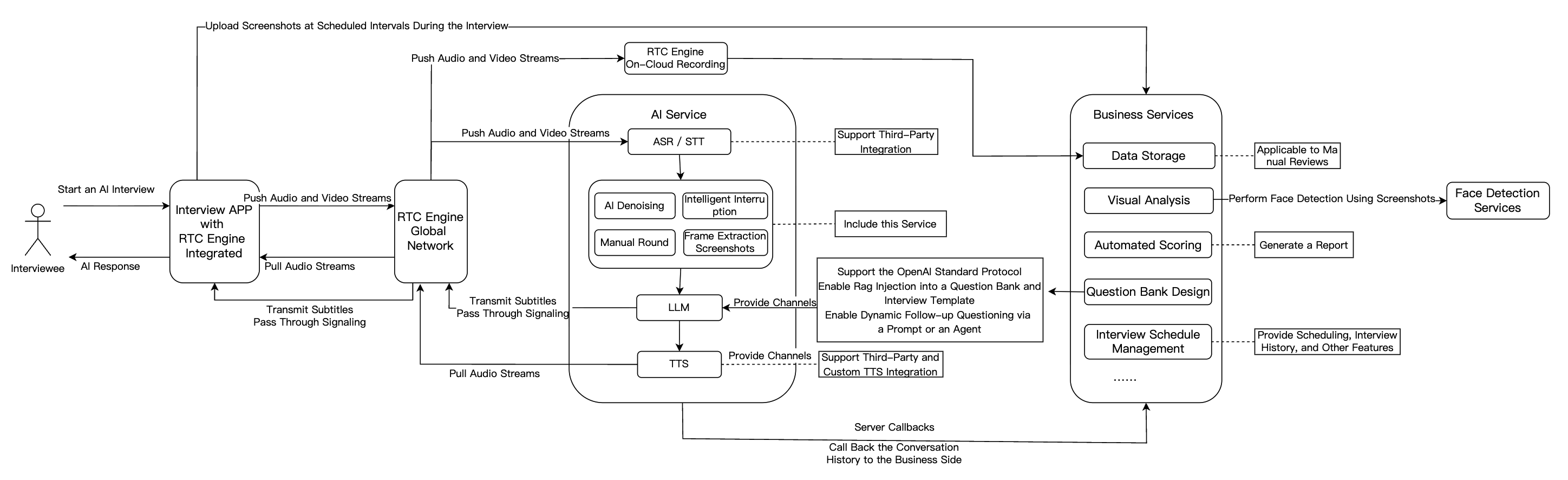
AI 인터뷰
기능 모듈 | AI 인터뷰 시나리오의 적용 |
RTC | RTC Engine 기반으로 고수준, 저지연 음성및 영상 연결을 제공하며 720P/1080P/2K 고화질 및 48kHz 고음질을 지원합니다. 네트워크 환경에 관계없이 원활한 연결을 보장하여 실감적인 면접을 시뮬레이션합니다. |
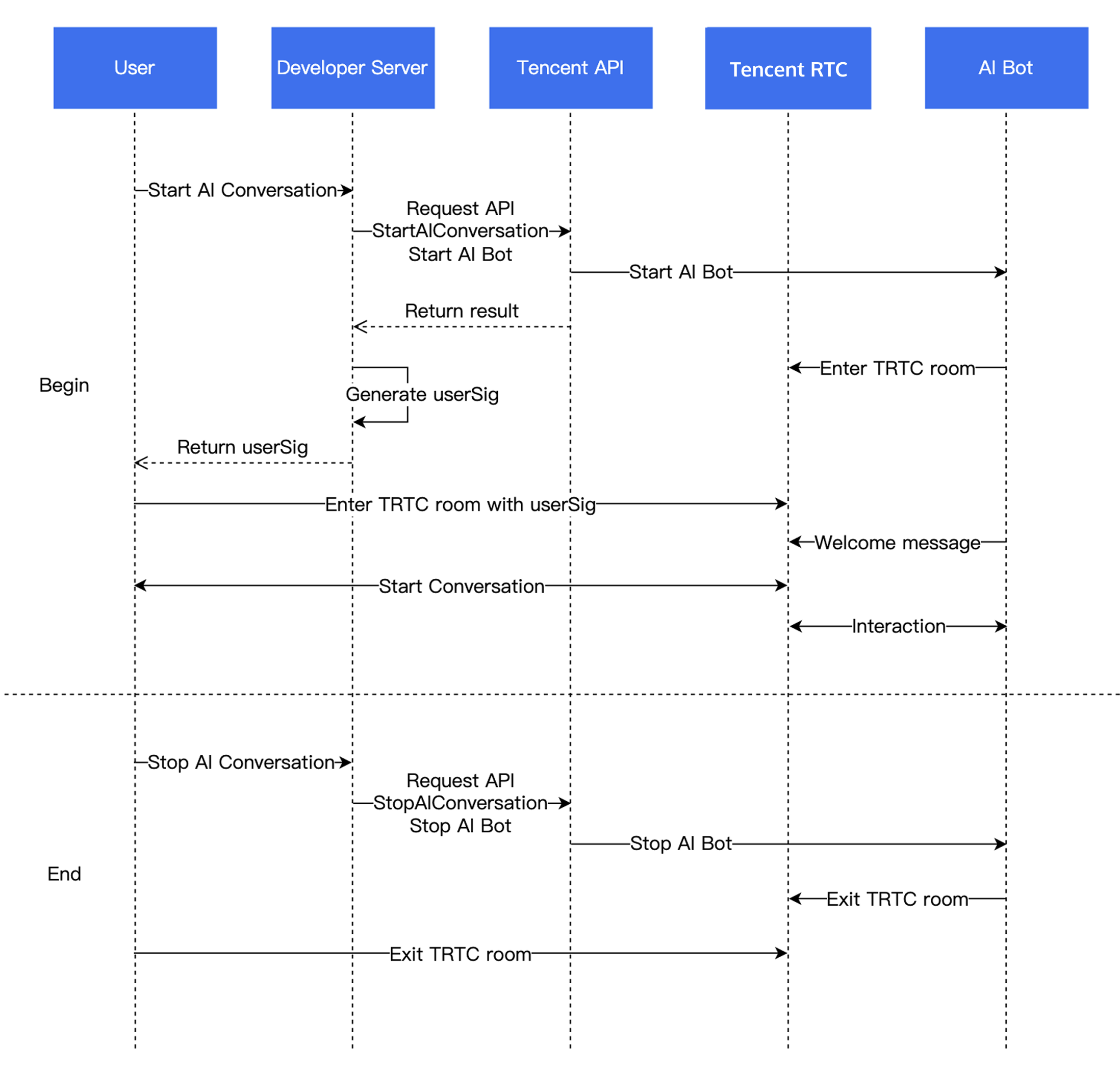
Conversational AI | Tencent Conversational AI 솔루션은 고객이 여러 AI 대형 모듈 서비스를 유연하게 접속할 수 있도록 지원하며, AI와 사용자 간의 RTC 인터랙션을 구현하여 업무 시나리오에 부합하는 Conversational AI 능력을 구축합니다. Tencent Real-Time Communication (Tencent RTC)의 글로벌 저지연 전송을 기반으로 대화 효과가 자연스럽고 리얼하며 접속이 간편하고 즉시 사용할 수 있습니다. |
LLM | 지능적으로 지원자의 음성 내용과 맥락을 이해하여 응답 요점을 정확하게 추출하고, 후속 면접 질문을 동적으로 생성하여 개인화및 구조화 면접 프로세스를 구현합니다. LLM 기술은 또한 직무별 알고리즘에 따라 자동으로 채점 기준을 조정하여 평가의 공정성과 정확성을 높입니다. |
TTS | 제3자 TTS 연동을 지원하며 다양한 언어와 음성 스타일의 출력이 가능합니다. AI 면접관은 TTS 기술을 통해 다양한 어조와 성격을 구현함으로써 실제 면접관을 최대한 모방하여 지원자 체험감을 향상시킵니다. |
Chat | Chat을 통해 핵심 업무 신호의 전달을 완료합니다. |
면접 관리 백엔드 | 문제 은행과 면접 설계, 자동 채점, 데이터 저장, 시각적 분석, 면접 일정 관리 등의 기능을 포함합니다. |
// 마이크 수집을 시작하고 현재 시나리오를 음성 모드(고소음 억제 능력, 강약 네트워크 저항성)로 설정합니다.mCloud.startLocalAudio(TRTCCloudDef.TRTC_AUDIO_QUALITY_SPEECH );
self.trtcCloud = [TRTCCloud sharedInstance];// 마이크 수집을 시작하고 현재 시나리오를 음성 모드(고소음 억제 능력, 강약 네트워크 저항성)로 설정합니다.[self.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
// 마이크 수집을 시작하고 현재 시나리오를 음성 모드(고소음 억제 능력, 강약 네트워크 저항성)로 설정합니다.trtcCloud.startLocalAudio(TRTCAudioQuality.speech);
await trtc.startLocalAudio();
// 마이크 수집을 시작하고 현재 시나리오를 음성 모드로 설정합니다.// 높은 노이즈 억제 능력을 가지며 강약 네트워크 저항력이 있습니다.ITRTCCloud* trtcCloud = CRTCWindowsApp::GetInstance()->trtc_cloud_;trtcCloud->startLocalAudio(TRTCAudioQualitySpeech);
// 마이크 수집을 시작하고 현재 시나리오를 음성 모드로 설정합니다.// 높은 노이즈 억제 능력을 가지며 강약 네트워크 저항력이 있습니다.AppDelegate *appDelegate = (AppDelegate *)[[NSApplication sharedApplication] delegate];[appDelegate.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
LLMConfig 및 TTSConfig에 입력합니다.명칭 | 유형 | 기입 필수 여부 | 설명 |
LLMType | String | 예 | 대모듈 유형, OpenAI API 프로토콜을 준수하는 대모듈은 모두 openai으로 기입합니다. |
Model | String | 예 | 구체적인 모듈 이름, 예를 들어 gpt-4o, deepseek-chat. |
APIKey | String | 예 | 대형 모듈의 APIKey |
APIUrl | String | 예 | 대형 모듈의 APIUrl |
Streaming | Boolean | 아니요 | 스트리밍 모드인지, 기본값은 false이며 true을 기입하는 것을 권장합니다. |
SystemPrompt | String | 아니요 | 시스템 프롬프트. |
Timeout | Float | 아니요 | 타임아웃 시간, 범위는 [1~50]이며 기본값은 3초(단위: 초)입니다. |
History | Integer | 아니요 | LLM의 컨텍스트 라운드 설정합니다.기본값은 0(컨텍스트 관리 없음)이며 최대값은 50(최근 50라운드의 컨텍스트 관리 제공)입니다. |
MaxTokens | Integer | 아니요 | 출력 텍스트의 최대 token 제한. |
Temperature | Float | 아니요 | 샘플링 온도. |
TopP | Float | 아니요 | 샘플링 선택 범위로 출력 token의 다양성을 제어합니다. |
UserMessages | Object[] | 아니요 | 사용자 프롬프트. |
MetaInfo | Object | 아니요 | 커스텀 매개변수는 요청의 body에 포함되어 대형 모듈에 전달됩니다. |
"LLMConfig": {"LLMType": "openai","Model": "gpt-4o","APIKey": "api-key","APIUrl": "https://api.openai.com/v1/chat/completions","Streaming": true,"SystemPrompt": "개인 비서입니다""Timeout": 3.0,"History": 5,"MetaInfo": {},"MaxTokens": 4096,"Temperature": 0.8,"TopP": 0.8,"UserMessages": [{"Role": "user","Content": "content"},{"Role": "assistant","Content": "content"}]}
{"TTSType": "tencent", // String TTS 유형, 현재 "tencent"와 "minixmax" 지원하며 다른 업체 지원 중입니다"AppId": 손님의 애플리케이션 ID입니다. // Integer 기입 필수합니다"SecretId": "손님의 키 ID입니다", // String 기입 필수합니다"SecretKey": "손님의 키 Key입니다", // String 기입 필수합니다"VoiceType": 101001, // Integer 기입 필수합니다.음색 Id는 표준 음색과 프리미엄 음색을 포함하며 프리미엄 음색은 더 높은 사실감을 제공하고 가격이 표준 음색과 다릅니다. 음성 합성 요금 개요를 참조하십시오. 전체 음색 ID 목록은 음성 합성 음색 목록을 참조하십시오."Speed": 1.25, // Integer 기입 선택 사항입니다. 음성 속도의 범위는 [-2, 6]이며, 각각 다른 속도에 해당됩니다. -2: 0.6배, -1: 0.8배, 0: 1.0배(기본값), 1: 1.2배, 2: 1.5배, 6: 2.5배를 의미합니다. 더 세분화된 음성 속도가 필요한 경우 소수점 2자리까지 지정 가능합니다(예: 0.5/1.25/2.81 등). 매개변수 값과 실제 음성 속도의 변환은 음성 속도 변환을 참조하십시오.""Volume": 5, // Integer 기입선택 사항입니다.볼륨 크기의 범위는 [0, 10]이며, 각각 11개의 볼륨 레벨에 해당하며 기본값은 0이고 정상 볼륨을 나타냅니다."PrimaryLanguage": 1, // Integer 기입 선택 사항입니다. 주요 언어는 1-중국어(기본값), 2-영어, 3-일본어로 됩니다"FastVoiceType": "xxxx" // String 선택적 매개변수이며 빠른 음성 복제하는 매개변수입니다"EmotionCategory":"angry",// String 기입선택 사항입니다.합성된 오디오의 감정을 제어하며 다중 감정 음색에서만 사용 가능합니다. 값: neutral(중립), sad(슬픔)..."EmotionIntensity":150 //Integer 기입 선택 사항입니다.합성된 오디오의 감정 강도를 제어하며 범위는 [50,200]이며 기본값은 100입니다. EmotionCategory가 비어 있지 않을 때만 적용됩니다.}
STTConfig, LLMConfig 및 TTSConfig 구성에 대한 설명입니다:RoomId는 클라이언트가 방 입장하는 RoomId와 일치해야 하며, 방 번호 유형(숫자 방 번호, 문자열 방 번호)도 동일해야 합니다(즉, 로봇과 사용자가 동일한 방에 있어야 함).TargetUserId는 클라이언트가 방 입장할 때 사용하는 UserId와 일치해야 합니다.LLMConfig와 TTSConfig는 모두 JSON 문자열이며 Conversational AI를 성공적으로 시작하려면 올바르게 구성해야 합니다.STTConfig.VadLevel을 2 또는 3으로 설정하면 원거리 음성 억제 기능을 혀과적으로 발휘할 수 있습니다.상태 코드 | 설명 |
asr_latency | ASR 지연.주의: 지표는 AI 대화 시작 시 VadSilenceTime으로 설정된 시간을 포함합니다. |
llm_network_latency | LLM 요청한 네트워크 소요 시간. |
llm_first_token | LLM 첫 token 소요 시간의 지표는 네트워크 소요 시간을 포함합니다. |
tts_network_latency | TTS 요청한 네트워크 소요 시간. |
tts_first_frame_latency | TTS 첫 프레임 소요 시간의 지표는 네트워크 소요 시간을 포함합니다. |
tts_discontinuity | TTS 연속되지 않는 횟수는 TTS 스트리밍 요청 재생 완료 후 다음 요청 결과가 아직 반환되지 않은 경우를 나타내며, 일반적으로 TTS 지연이 높은 경우에 발생합니다. |
interruption | 이번 대화가 중단되었음을 나타냅니다. |
Streaming을 true로 설정해야 함). 이렇게 하면 지연 시간을 크게 줄일 수 있습니다. DeepSeek-R1과 같은 사고형 모듈은 LLM 지연 시간이 너무 길어 음성 대화에 적용할 수 없으므로 사용하지 않는 것이 좋습니다. 대화 지연에 특히 민감한 경우 매개변수가 더 작은 모듈을 선택할 수 있으며, 많은 모듈이 첫 패킷 소요 시간을 500ms 정도로 제어할 수 있습니다.{"type": 10000, // 10000은 실시간 자막 전송을 나타냅니다"sender": "user_a", // 발화자의 userid입니다"receiver": [], // 수신자 userid 목록입니다.해당 메시지는 실제로 방 내에서 브로드캐스트됩니다"payload": {"text":"", // 음성에서 인식된 텍스트입니다"start_time":"00:00:01", // 이 문장의 시작 시간입니다"end_time":"00:00:02", // 이 문장의 종료 시간입니다"roundid": "xxxxx", // 한 라운드 대화의 고유 식별자입니다"end": true // true인 경우, 이 문장이 완전한 문장임을 나타냅니다}}
{"type": 10001, // 로봇의 상태입니다"sender": "user_a", // 발신자 userid입니다. 여기는 로봇의 id입니다"receiver": [], // 수신자 userid 목록입니다.해당 메시지는 실제로 방 내에서 브로드캐스트됩니다"payload": {"roundid": "xxx", // 한 라운드 대화의 고유 식별자입니다"timestamp": 123,"state": 1, // 1 듣는 중, 2 생각 중, 3 말하는 중, 4 중단됨, 5 말을 마침}}
@Overridepublic void onRecvCustomCmdMsg(String userId, int cmdID, int seq, byte[] message) {String data = new String(message, StandardCharsets.UTF_8);try {JSONObject jsonData = new JSONObject(data);Log.i(TAG, String.format("receive custom msg from %s cmdId: %d seq: %d data: %s", userId, cmdID, seq, data));} catch (JSONException e) {Log.e(TAG, "onRecvCustomCmdMsg err");throw new RuntimeException(e);}}
func onRecvCustomCmdMsgUserId(_ userId: String, cmdID: Int, seq: UInt32, message: Data) {if cmdID == 1 {do {if let jsonObject = try JSONSerialization.jsonObject(with: message, options: []) as? [String: Any] {print("Dictionary: \\(jsonObject)")} else {print("The data is not a dictionary.")}} catch {print("Error parsing JSON: \\(error)")}}}
trtcClient.on(TRTC.EVENT.CUSTOM_MESSAGE, (event) => {let data = new TextDecoder().decode(event.data);let jsonData = JSON.parse(data);console.log(`receive custom msg from ${event.userId} cmdId: ${event.cmdId} seq: ${event.seq} data: ${data}`);if (jsonData.type == 10000 && jsonData.payload.end == false) {// 자막 중간 상태} else if (jsonData.type == 10000 && jsonData.payload.end == true) {// 한 마디가 끝났습니다}});
void onRecvCustomCmdMsg(const char* userId, int cmdID, int seq,const uint8_t* message, uint32_t msgLen) {std::string data;if (message != nullptr && msgLen > 0) {data.assign(reinterpret_cast<const char*>(message), msgLen);}if (cmdID == 1) {try {auto j = nlohmann::json::parse(data);std::cout << "Dictionary: " << j.dump() << std::endl;} catch (const std::exception& e) {std::cerr << "Error parsing JSON: " << e.what() << std::endl;}return;}}
void onRecvCustomCmdMsg(String userId, int cmdID, int seq, String message) {if (cmdID == 1) {try {final decoded = json.decode(message);if (decoded is Map<String, dynamic>) {print('Dictionary: $decoded');} else {print('The data is not a dictionary. Raw: $decoded');}} catch (e) {print('Error parsing JSON: $e');}return;}}

import timefrom fastapi import FastAPI, HTTPExceptionfrom fastapi.middleware.cors import CORSMiddlewarefrom pydantic import BaseModelfrom typing import List, Optionalfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIapp = FastAPI(debug=True)# CORS 미들웨어의 추가app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)class Message(BaseModel):role: strcontent: strclass ChatRequest(BaseModel):model: strmessages: List[Message]temperature: Optional[float] = 0.7class ChatResponse(BaseModel):id: strobject: strcreated: intmodel: strchoices: List[dict]usage: dict@app.post("/v1/chat/completions")async def chat_completions(request: ChatRequest):try:# 요청 메시지를 LangChain 메시지 형식으로 변환합니다langchain_messages = []for msg in request.messages:if msg.role == "system":langchain_messages.append(SystemMessage(content=msg.content))elif msg.role == "user":langchain_messages.append(HumanMessage(content=msg.content))# add more historys# LangChain의 ChatOpenAI 모듈 사용합니다chat = ChatOpenAI(temperature=request.temperature,model_name=request.model)response = chat(langchain_messages)print(response)# OpenAI API 형식에 맞는 응답을 구성합니다return ChatResponse(id="chatcmpl-" + "".join([str(ord(c))for c in response.content[:8]]),object="chat.completion",created=int(time.time()),model=request.model,choices=[{"index": 0,"message": {"role": "assistant","content": response.content},"finish_reason": "stop"}],usage={"prompt_tokens": -1, # LangChain은 이 정보를 제공하지 않으므로 플레이스홀더 값을 사용합니다"completion_tokens": -1,"total_tokens": -1})except Exception as e:raise HTTPException(status_code=500, detail=str(e))if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
metainfo이라는 커스텀 필드를 추가할 수 있습니다. AI 서비스가 metainfo을 감지한 후, 커스텀 메시지를 통해 클라이언트 SDK로 푸시하여 metainfo의 전달을 완료합니다.chat.completion.chunk 객체를 스트리밍 방식으로 반환할 때, 동시에 meta.info의 chunk을 반환합니다.{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}// 다음과 같은 커스텀 메시지 추가합니다{"id":"chatcmpl-123","type":"meta.info","created":1694268190,"metainfo": {}}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
metainfo를 감지한 후 RTC Engine의 커스텀 메시지를 통해 전송합니다. 클라이언트는 SDK 콜백의 onRecvCustomCmdMsg 인터페이스를 통해 수신할 수 있습니다.{"type": 10002, // 커스텀 메시지"sender": "user_a", // 발신자 userid입니다. 여기는 로봇의 id입니다"receiver": [], // 수신자 userid 목록입니다.해당 메시지는 실제로 방 내에서 브로드캐스트됩니다."roundid": "xxxxxx","payload": {} // metainfo}
metainfo 신호가 손실되는 문제를 방지할 수 있습니다.AgentConfig.TurnDetectionMode 매개변수를 1으로 설정하여 수동 라운드 모드를 활성화할 수 있습니다. 이 경우에 클라이언트는 자막 메시지를 수신한 후 새로운 대화를 트리거하기 위해 채팅 신호를 수동으로 보낼지, 안 보낼지를 자체적으로 결정합니다.매개변수 | 유형 | 설명 |
TurnDetectionMode | Integer | 새로운 대화의 트리거 방식을 제어하며 기본값은 0입니다. 0은 서버의 음성 인식이 완전한 문장을 감지한 후 자동으로 새로운 대화를 시작함을 나타냅니다. 1은 클라이언트가 자막 메시지를 수신한 후 수동으로 채팅 신호를 보내 새로운 대화를 트리거할지를 자체적으로 결정함을 나타냅니다. 예시 값: 0 |
{"type": 20000, // 클라이언트에서 커스텀 텍스트 메시지를 전송합니다"sender": "user_a", // 발신자 userid입니다. 서버는 해당 userid가 유효한지 확인합니다"receiver": ["user_bot"], // 수신자 userid 목록입니다.로봇 userid만 기입하면 되며, 서버에서 해당 userid의 유효성을 확인합니다"payload": {"id": "uuid", // 메시지 ID입니다.문제 해결 시 uuid를 사용할 수 있습니다"message": "xxx", // 메시지 내용입니다"timestamp": 123 // 타임스탬프입니다.문제 해결에 사용할 수 있습니다}}
public void sendMessage() {try {int cmdID = 0x2;long time = System.currentTimeMillis();String timeStamp = String.valueOf(time/1000);JSONObject payLoadContent = new JSONObject();payLoadContent.put("timestamp", timeStamp);payLoadContent.put("message", message);payLoadContent.put("id", String.valueOf(GenerateTestUserSig.SDKAPPID) + "_" + mRoomId);String[] receivers = new String[]{robotUserId};JSONObject interruptContent = new JSONObject();interruptContent.put("type", 20000);interruptContent.put("sender", mUserId);interruptContent.put("receiver", new JSONArray(receivers));interruptContent.put("payload", payLoadContent);String interruptString = interruptContent.toString();byte[] data = interruptString.getBytes("UTF-8");Log.i(TAG, "sendInterruptCode :" + interruptString);mTRTCCloud.sendCustomCmdMsg(cmdID, data, true, true);} catch (UnsupportedEncodingException e) {e.printStackTrace();} catch (JSONException e) {throw new RuntimeException(e);}}
@objc func sendMessage() {let cmdId = 0x2let timestamp = Int(Date().timeIntervalSince1970 * 1000)let payload = ["id": userId + "_\\(roomId)" + "_\\(timestamp)", // 메시지 ID입니다.문제 해결 시 uuid를 사용할 수 있습니다"timestamp”: timestamp, // 타임스탬프입니다. 문제 해결에 사용할 수 있습니다"message": "xxx" // 메시지 내용입니다] as [String : Any]let dict = ["type": 20001,"sender": userId,"receiver": [botId],"payload": payload] as [String : Any]do {let jsonData = try JSONSerialization.data(withJSONObject: dict, options: [])self.trtcCloud.sendCustomCmdMsg(cmdId, data: jsonData, reliable: true, ordered: true)} catch {print("Error serializing dictionary to JSON: \\(error)")}}
const message = {"type": 20000,"sender": "user_a","receiver": ["user_bot"],"payload": {"id": "uuid","timestamp": 123,"message": "xxx", // 메시지 내용입니다}};trtc.sendCustomMessage({cmdId: 2,data: new TextEncoder().encode(JSON.stringify(message)).buffer});
AgentConfig.InterruptSpeechDuration과 STTConfig.VadSilenceTime 매개변수를 낮게 설정하여 응답 지연을 줄일 수 있습니다. 오작동 확률을 줄이기 위해 원거리 음성 억제 기능을 함께 활성화하는 것이 좋습니다.매개변수 | 유형 | 설명 |
AgentConfig.InterruptSpeechDuration | Integer | InterruptMode가 0일 때 사용되며 단위는 밀리초이고 기본값은 500ms입니다. 서버가 지속적으로 InterruptSpeechDuration 밀리초 동안 사람의 목소리를 감지하면 대화를 중단합니다. 예시 값: 500 |
STTConfig.VadSilenceTime | Integer | 음성 인식 vad 시간의 범위는 240~2000이며 기본값은 1000(단위: ms)입니다. 값이 작을수록 음성 인식 문장 분할이 더 빨라집니다. 예시 값: 500 |
RoomId이 클라이언트 방 입장 시 사용한 RoomId와 일치하는지, 그리고 방 번호 유형(숫자 방 번호, 문자열 방 번호)도 동일한지 확인하세요(즉, 로봇과 사용자가 동일한 방에 있어야 함). 또한 TargetUserId가 클라이언트 방입장 시 사용한 UserId와 일치하는지 확인하세요.서비스 유형 | 에러 코드 | 에러의 설명 |
ASR | 30100 | 요청이 시간 초과했습니다 |
| 30102 | 내부 오류 |
LLM | 30200 | LLM 요청이 시간 초과했습니다 |
| 30201 | LLM 요청이 빈도에 제한됩니다 |
| 30202 | LLM 서비스 반환이 실패됩니다 |
TTS | 30300 | TTS 서비스 요청이 시간 초과했습니다 |
| 30301 | TTS 요청이 빈도에 제한됩니다 |
| 30302 | TTS 서비스 반환이 실패됩니다 |
llm error Timeout on reading data from socket과 같은 메시지가 표시되면 일반적으로 LLM 요청이 시간 초과된 것입니다. LLMConfig의 Timeout 매개변수를 더 크게 설정하여 본 문제를 해결할 수 있습니다(기본값은 3초임). 또한 LLM의 첫 패킷 소요 시간이 3초를 초과한 경우, 높은 대화 지연은 AI 대화에 영향을 미칩니다. 특별한 요구 사항이 없는 경우 LLM의 첫 패킷 소요 시간을 최적화하는 것이 좋으며, 대화 지연 최적화을 참조하십시오.TencentTTS chunk error {'Response': {'RequestId': 'xxxxxx', 'Error': {'Code': 'AuthorizationFailed', 'Message': "Please check http header 'Authorization' field or request parameter"}}}
AgentConfig.FilterOneWord 매개변수가 false(기본값 true)로 설정되었는지 확인하세요.매개변수 | 유형 | 설명 |
FilterOneWord | Boolean | 사용자가 한 단어만 말한 문장을 필터링할지, true는 필터링하고 false는 필터링하지 않습니다. 기본값은 true입니다 예시 값: true |
열거형 | 값 | 설명 |
ERR_TRTC_INVALID_USER_SIG | -3320 | 방 입장 매개변수 userSig가 올바르지 않습니다. TRTCParams.userSig이 비어 있는지 확인하세요. |
ERR_TRTC_USER_SIG_CHECK_FAILED | -100018 | UserSig 검증에 실패했습니다. 매개변수 TRTCParams.userSig이 올바르게 입력되었는지, 또는 만료되었는지 확인하세요. |
열거형 | 값 | 설명 |
ERR_TRTC_CONNECT_SERVER_TIMEOUT | -3308 | 방 입장 요청이 시간 초과하는 경우, 네트워크 연결이 끊겼는지 또는 VPN이 켜져 있는지 확인하세요. 4G로 전환하여 테스트할 수도 있습니다. |
ERR_TRTC_INVALID_SDK_APPID | -3317 | 방 입장 매개변수 SDKAppId가 잘못되었습니다. TRTCParams.sdkAppId이 비어 있는지 확인하세요. |
ERR_TRTC_INVALID_ROOM_ID | -3318 | 방 입장 매개변수 roomId가 잘못되었습니다. TRTCParams.roomId 또는 TRTCParams.strRoomId이 비어 있는지 확인하세요. roomId와 strRoomId는 혼용할 수 없습니다. |
ERR_TRTC_INVALID_USER_ID | -3319 | 방 입장 매개변수 UserID가 올바르지 않습니다. TRTCParams.userId이 비어 있는지 확인하세요. |
ERR_TRTC_ENTER_ROOM_REFUSED | -3340 | 방 입장 요청이 거부되었습니다. enterRoom을 연속적으로 호출하여 동일한 ID의 방에 입장했는지 확인하세요. |
열거형 | 값 | 설명 |
ERR_MIC_START_FAIL | -1302 | Windows 또는 Mac 장치에서 마이크 구성 프로그램(드라이버)이 비정상일 경우에 마이크 열 수가 없습니다. 장치를 비활성화한 후 다시 활성화하거나, 장치를 재시작하거나, 구성 프로그램을 업데이트하세요. |
ERR_SPEAKER_START_FAIL | -1321 | Windows 또는 Mac 장치에서 스피커 구성 프로그램(드라이버)이 이상이 있는 경우에 스피커를 열수 가 없습니다.장치를 비활성화한 후 다시 활성화하거나, 장치를 재시작하거나 구성 프로그램을 업데이트하세요. |
ERR_MIC_OCCUPY | -1319 | 마이크가 사용 중입니다. 예를 들어 모바일 장치에서 통화 중일 때 마이크를 열 수가 없습니다. |
시스템 계층 | 제품명 | 시나리오 용도 |
접속 계층 | 저지연 및 고수준의 실시간 음성/영상 인터랙션 솔루션을 제공하며 음성/영상 통화 시나리오의 기반 인프라 기능입니다. | |
접속 계층 | 핵심 업무 신호의 전달을 완료합니다. | |
클라우드 서비스 | AI와 사용자 간의 실시간 음성 및 영상 인터랙션을 구현하여 업무 시나리오에 부합하는 Conversational AI 능력을 구축합니다. | |
클라우드 서비스 | 신원 확인 및 부정행위 방지 기능을 제공합니다. | |
대형 모듈 | 지능형 고객 서비스의 두뇌로 LLM+RAG, Workflow, Multi-agent 등 다양한 에이전트 개발 프레임워크를 제공합니다. | |
데이터 저장 | 오디오 레코딩 파일 및 오디오 슬라이스 파일의 저장 서비스를 제공합니다. |
피드백