안내
TPS는 2022년 5월 16일에 비활성화되었습니다. 자세한 내용은 공지를 참고하십시오. 새로운 Prometheus 서비스는 TMP에서 제공됩니다. 만약 귀하의 DeScheduler가 데이터 소스로 TPS를 사용하고 이를 변경하지 않은 경우, DeScheduler는 더 이상 유효하지 않게 됩니다. TMP에 API 인증 기능이 추가되었으므로, TMP를 데이터 소스로 사용하려면, TMP 인스턴스와 연동하기 전에 DeScheduler를 업그레이드해야 합니다.
만약 귀하의 DeScheduler가 직접 구축한 Prometheus 서비스를 사용하고 있다면, TPS 비활성화의 영향을 받지 않지만, 직접 구축한 Prometheus 서비스의 안정성과 신뢰성을 자체적으로 보장해야 합니다. 개요
애드온 설명
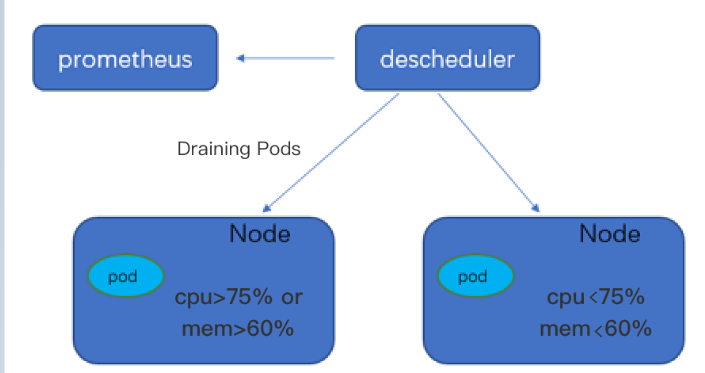
DeScheduler는 실제 노드 로드를 기반으로 하는 TKE 리스케쥴링 애드온입니다. 이는 Kubernetes의 Descheduler를 기반으로 구현됩니다. TKE 클러스터에 설치된 후, 이 애드온은 kube-scheduler와 함께 클러스터의 고부하 Node를 실시간으로 모니터링하고 우선순위가 낮은 Pod를 비우게 됩니다. 다차원적인 클러스터 로드 밸런싱을 보장하기 위해 TKE Dynamic Scheduler와 함께 사용하는 것을 권장합니다. 이 애드온은 Prometheus 애드온과 규칙 구성에 의존합니다. 설치하기 전에 종속성 배포를 주의 깊게 읽어보시기를 권장합니다. 그렇지 않으면 올바르게 작동하지 않을 수 있습니다. 클러스터에 배포된 Kubernetes 객체
|
| | 각 인스턴스에 대해 CPU:200m, Memory:200Mi, 총 1개의 인스턴스 | |
| | | |
| | | |
| | | |
| | | |
| | | |
사용 사례
DeScheduler는 리스케쥴링을 통해 클러스터 내 기존 노드의 비합리적인 실행 문제를 해결합니다. 커뮤니티 Descheduler의 정책은 APIServer의 데이터를 기반으로 구현되지만 실제 노드 로드는 아닙니다. 따라서 노드를 모니터링하여 실제 로드를 기반으로 일정을 리스케쥴링하도록 정책을 조정할 수 있습니다.
TKE의 ReduceHighLoadNode 정책은 Prometheus 및 node_exporter 모니터링 데이터에 의존합니다. Pod는 CPU 사용률, 메모리 사용률, 네트워크 IO 및 system loadavg와 같은 노드 지표를 기반으로 드레이닝되고 리스케쥴링되어 극단적인 노드 로드를 방지합니다. DeScheduler의 ReduceHighLoadNode는 실제 노드 로드를 기반으로 하는 Dynamic Scheduler의 정책과 함께 사용해야 합니다.
주의 사항
Kubernetes 버전 ≥ v1.10.x
경우에 따라 일부 Pod는 일정 변경이 필요한 노드에 반복적으로 스케쥴링되어 Pod가 반복적으로 드레이닝됩니다. 이 경우 필요에 따라 Pod를 스케쥴링할 수 있는 노드를 변경하거나 Pod를 드레이닝 불가로 표시할 수 있습니다.
이 애드온은 TKE의 모니터링 및 알람 시스템에 상호 연결되었습니다.
더 나은 애드온 예외 모니터링과 장애 진단을 위해, 클러스터에 대한 이벤트 지속성을 활성화하는 것이 좋습니다. Descheduler가 Pod를 드레이닝하면 이벤트가 생성됩니다. ‘Descheduled’의 reason으로 이벤트를 통해 Pod가 반복적으로 드레이닝되는지 확인할 수 있습니다.
DeScheduler가 중요한 Pod를 드레이닝하지 않도록 하기 위해, 알고리즘은 기본적으로 Pod를 드레이닝하지 않도록 설계되었습니다. 드레이닝할 수 있는 Pod의 경우 workload를 표시하고 결정해야 합니다. statefulset 및 deployment 객체의 경우 Pod를 드레이닝할 수 있음을 나타내는 annotation을 설정할 수 있습니다.
드레이닝 조건: 드레이닝 대상이 되는 Pod가 리소스를 사용하지 않도록 하기 위해 클러스터는 적어도 5개의 노드를 포함해야 하며, 목표 사용률보다 낮은 로드를 가진 노드가 4 개 이상 있어야 드레이닝이 가능합니다.
드레이닝은 고위험 작업이므로 노드 친화성, 테인트 관련 설정 및 Pod 자체의 노드 선택 요구 사항에 유의하여 드레이닝 후 스케쥴링할 노드가 없는 상황을 방지하십시오.
대량의 Pod가 드레이닝될 경우 서비스를 사용할 수 없게될 수 있습니다. Kubernetes는 네이티브 PDB 객체를 제공하여 드레이닝 API가 호출된 후 workload의 대량 Pod가 사용 불가능해지는 것을 방지하지만, PDB 구성을 생성해야 합니다. TKE의 DeScheduler는 보증 조치를 포함하고 있습니다. 드레이닝 API를 호출하기 전에, workload가 준비한 Pod 수가 복제본 수의 절반보다 큰지 확인합니다. 그렇지 않으면 드레이닝 API가 호출되지 않습니다.
애드온 원리
DeScheduler는 커뮤니티 Descheduler의 리스케쥴링 개념을 기반으로, 정책과 일치하지 않는 각 노드에서 실행 중인 Pod를 검색하고 리스케쥴링을 위해 드레이닝합니다. 커뮤니티 Descheduler는 APIServer의 데이터를 기반으로 하는 일부 정책을 제공합니다. 예를 들어, Pod의 request 및 limit 값을 기반으로 하는 LowNodeUtilization 정책입니다. 이러한 데이터는 클러스터 리소스 할당을 효과적으로 균형을 맞추고 리소스 조각화를 방지할 수 있습니다. 그러나 커뮤니티 정책은 실제 노드 리소스 점유에 대한 지원이 부족합니다. 구체적으로, A 노드와 B 노드에서 동일한 수의 리소스를 할당하더라도, 실제 Pod 실행 시 CPU 및 메모리 사용 차이로 인해 최대 로드가 크게 달라집니다. 따라서 TKE는 하위 레이어에서 실제 노드 로드를 모니터링하여 리스케쥴링하는 DeScheduler를 출시했습니다. Prometheus에서 클러스터의 Node 로드 통계와 구성된 로드 임계값을 사용하여 정책에서 확인 규칙을 정기적으로 실행하고 고부하 노드에서 Pod를 드레이닝합니다.
애드온 매개변수 설명
Prometheus 데이터 쿼리 주소
주의사항
애드온에서 필요한 모니터링 데이터를 풀링할 수 있고 스케쥴링 정책이 적용될 수 있도록 하려면 종속성 배포 > Prometheus 파일 구성 단계에 따라 모니터링 데이터 수집 규칙을 구성합니다. 자체 구축된 Prometheus 서비스를 사용하는 경우 데이터 쿼리 URL(HTTP/HTTPS)만 입력하면 됩니다.
관리형 Prometheus 서비스를 사용하는 경우 관리형 인스턴스 ID를 선택하기만 하면 시스템이 자동으로 인스턴스의 데이터 쿼리 URL을 구문 분석합니다.
사용률 임계값 및 목표 사용률
주의사항
로드 임계값 매개변수에 대해 기본값이 설정되었습니다. 특별한 요구 사항이 없으면 직접 사용할 수 있습니다.
지난 5분 동안 노드의 평균 CPU 또는 메모리 사용률이 구성된 임계값을 초과하면, Descheduler는 노드를 고부하 노드로 식별하고 로직을 실행하여, Pod를 드레이닝하고 다시 스케쥴링하여 로드를 목표 사용률 미만으로 줄입니다.
작업 단계
종속성 배포
DeScheduler 애드온은 현재 및 과거 기간의 실제 Node 로드에 의존하여 스케쥴링 결정을 내립니다. Prometheus 애드온을 통해 시스템의 실제 Node 로드 정보를 가져와야 합니다. DeScheduler 애드온을 사용하기 전에 자체 구축된 Prometheus 모니터링 서비스 또는 TKE 클라우드 네이티브 모니터링 서비스를 사용할 수 있습니다.
자체 구축 Prometheus 모니터링 서비스
node-exporter 및 Prometheus 배포
필요에 따라 node-exporter 및 Prometheus를 배포하여 node-exporter를 통해 Node 지표를 모니터링할 수 있습니다.
집계 규칙 구성
node-exporter에서 노드 모니터링 데이터를 가져온 후 Prometheus를 통해 기본 node-exporter에서 수집된 데이터를 집계하고 계산해야 합니다. DeScheduler에 필요한 cpu_usage_avg_5m 및 mem_usage_avg_5m과 같은 지표를 가져오려면 Prometheus에서 rules를 구성해야 합니다. 다음은 예시입니다.
groups:
- name: cpu_mem_usage_active
interval: 30s
rules:
- record: mem_usage_active
expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
- name: cpu-usage-1m
interval: 1m
rules:
- record: cpu_usage_avg_5m
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- name: mem-usage-1m
interval: 1m
rules:
- record: mem_usage_avg_5m
expr: avg_over_time(mem_usage_active[5m])
주의사항
TKE의 DynamicScheduler를 사용하는 경우 Node 모니터링 데이터를 가져오려면 Prometheus에서 집계 규칙을 구성해야 합니다. DynamicScheduler의 집계 규칙 중 일부는 DeScheduler와 동일하므로 구성 시 규칙이 겹치지 않도록 하시기 바랍니다. 또한 DeScheduler와 함께 DynamicScheduler를 사용하려면 다음 규칙을 구성해야 합니다.
groups:
- name: cpu_mem_usage_active
interval: 30s
rules:
- record: mem_usage_active
expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
- name: mem-usage-1m
interval: 1m
rules:
- record: mem_usage_avg_5m
expr: avg_over_time(mem_usage_active[5m])
- name: mem-usage-5m
interval: 5m
rules:
- record: mem_usage_max_avg_1h
expr: max_over_time(mem_usage_avg_5m[1h])
- record: mem_usage_max_avg_1d
expr: max_over_time(mem_usage_avg_5m[1d])
- name: cpu-usage-1m
interval: 1m
rules:
- record: cpu_usage_avg_5m
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- name: cpu-usage-5m
interval: 5m
rules:
- record: cpu_usage_max_avg_1h
expr: max_over_time(cpu_usage_avg_5m[1h])
- record: cpu_usage_max_avg_1d
expr: max_over_time(cpu_usage_avg_5m[1d])
Prometheus 파일 구성
1. 상기 내용에서 DeScheduler에 필요한 지표를 계산하는 rules를 정의하였습니다. Prometheus 구성 파일로 Prometheus에 대한 rules를 구성해야 합니다. 다음은 예시입니다.
global:
evaluation_interval: 30s
scrape_interval: 30s
external_labels:
rule_files:
- /etc/prometheus/rules/*.yml
2. rules 구성을 파일(예시: de-scheduler.yaml)에 복사하고 파일을 상기 Prometheus 컨테이너의 /etc/prometheus/rules/ 아래에 넣습니다.
3. Prometheus server를 다시 로딩하여 Prometheus에서 동적 스케쥴러에 필요한 지표를 가져옵니다.
설명
일반적으로 상기 Prometheus 구성 파일과 rules 구성 파일은 Prometheus server의 컨테이너에 마운트되기 전에 configmap을 통해 저장됩니다. 따라서 configmap만 수정하면 됩니다.
1. TKE 콘솔에 로그인하고 왼쪽 사이드바에서 Prometheus 모니터링을 선택하여 ‘Prometheus 모니터링’ 페이지로 이동합니다. 3. 다음과 같이 네이티브 관리형 클러스터와 연결하면 node-exporter가 클러스터의 각 노드에 설치되었음을 확인할 수 있습니다.
애드온 설치
1. TKE 콘솔에 로그인하고 왼쪽 사이드바에서 클러스터를 선택합니다. 2. 클러스터 관리 페이지에서 대상 클러스터의 ID를 클릭하여 클러스터 세부 정보 페이지로 이동합니다.
3. 왼쪽 사이드바에서 애드온 관리를 선택하여, 애드온 목록 페이지에서 생성을 클릭합니다.
4. 애드온 생성 페이지에서 Decheduler(리스케쥴러)를 선택합니다. 매개변수 구성을 클릭하고 애드온 매개변수 설명에 따라 애드온에 필요한 매개변수를 입력합니다. 5. 완료를 클릭하여 애드온을 생성합니다. 애드온이 성공적으로 설치된 후 DeScheduler는 별도의 구성 없이 정상적으로 실행될 수 있습니다.
6. workload(예시: statefulset 및 deployment 등 객체)를 드레이닝하려면 다음과 같이 Annotation을 설정합니다.
descheduler.alpha.kubernetes.io/evictable: 'true'