구독 정규식
Download
포커스 모드
폰트 크기
정규식이 무엇입니까?
정규식은 텍스트에서 특정 형식에 부합하는 텍스트를 검색하는 데 사용됩니다.
정규식은 좌측에서 우측으로 하나의 문자열에 매칭합니다. “Regular Expression”이라는 단어가 길어서 보통 축약어 “regex” 또는 “regexp”를 사용합니다.
정규식을 사용하면 문자열의 텍스트를 변경하고 양식을 확인하며 패턴 매칭에 기초하여 문자열에서 특정 문자열을 추출할 수 있습니다.
응용 프로그램을 만드는 중에 사용자가 사용자 이름을 선택할 때 적용되는 규칙을 설정합니다. 사용자 이름은 알파벳, 숫자, 언더바, 하이픈을 포함할 것을 권장합니다.
인식하기 쉽도록 사용자 이름의 문자 수를 제한합니다. 아래 정규식을 사용하여 사용자 이름을 인증할 수 있습니다.
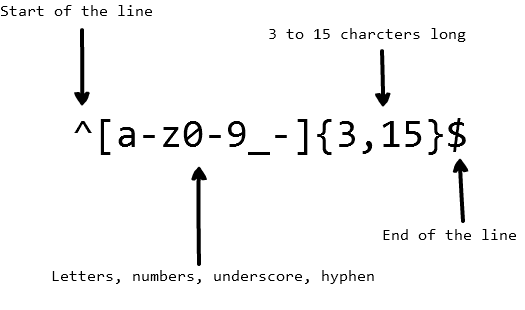
위의 정규식은
john_doe, jo-hn\\_doe, john12\\_as에 매칭할 수 있습니다. 이때 Jo는 매칭할 수 없는데, 문자열 안에 대문자가 포함되어 있고 너무 짧기 때문입니다.목록
기본 매칭
메타 문자
마침표
문자 세트
부정 문자 세트
중복
별표
덧셈표
물음표
중괄호
문자 집합
분기 구조
이스케이프 문자
위치 조정 문자
삽입 부호
달러 부호
약어 문자 세트
어서션
플래그
전역 검색
여러 행 매칭
일반 정규식
기본 매칭
정규식은 텍스트에서 알파벳과 숫자를 검색할 때 사용되는 패턴입니다. 예를 들어 정규식
cat은 알파벳 c 뒤에 알파벳 a가 오고, 바로 뒤에 알파벳 t가 따라옴을 의미합니다."cat" => The cat sat on the mat
정규식
123은 문자열 “123”에 매칭됩니다. 정규식의 각 문자에 대해 매칭할 문자열의 각 문자와 하나씩 비교하여 정규 매칭을 완료합니다.
정규식은 일반적으로 대소문자를 구분하므로 정규식 Cat과 문자열 “cat”은 서로 매칭되지 않습니다."Cat" => The cat sat on the Cat
메타 문자
메타 문자는 정규식의 기본 구성 요소입니다. 여기서 메타 문자는 일반적 의미와는 다르며 특수한 의미로 해석됩니다. 일부 메타 문자는 대괄호 안에서 특수한 의미를 가집니다.
메타 문자는 아래와 같습니다.
메타 문자 | 설명 |
. | 줄 바꿈 부호 외의 임의 문자에 매칭합니다. |
[ ] | 문자 클래스. 대괄호 안에 포함된 임의 문자에 매칭합니다. |
[^ ] | 부정 문자 클래스. 대괄호에 포함되지 않은 임의 문자에 매칭합니다. |
* | 앞의 하위 표현식과 0번 이상 매칭합니다. |
+ | 앞의 하위 표현식과 한 번 이상 매칭합니다. |
? | 앞의 하위 표현식과 0번 또는 한 번 매칭하거나 하나의 Non greedy qualifier를 가리킵니다. |
{n,m} | 중괄호. 앞의 문자를 최소 n번 매칭하지만 m번을 초과하지 않습니다. |
(xyz) | 문자 집합. 정확한 순서로 문자 xyz에 매칭합니다. |
| | 분기 구조. 부호 앞 또는 뒤의 문자에 매칭합니다. |
\ | 이스케이프 문자. 메타 문자 원래의 의미를 환원하고 예약어 [ ] ( ) { } . * + ? ^ $ \\. |
^ | 행의 시작에 매칭합니다. |
$ | 행의 종료에 매칭합니다. |
마침표
마침표
.은 메타 문자의 가장 간단한 예입니다. 메타 문자 .은 임의의 한 문자에 매칭할 수 있습니다. 줄 바꿈 부호와 새로운 행의 부호는 매칭되지 않습니다. 예를 들어 정규식 .ar은 임의 문자 뒤에 알파벳 a가 옵니다.
그 뒤에 r이 옵니다.".ar" => The car parked in the garage.
문자 세트
문자 세트는 문자 클래스라고도 합니다. 대괄호는 문자 세트를 지정할 때 사용됩니다. 문자 세트에 하이픈을 사용하여 문자 범위를 지정합니다. 대괄호 안의 문자 범위 순서는 중요하지 않습니다.
예를 들어 정규식
[Tt]he는 대문자 T 또는 소문자 t 뒤에 알파벳 h가 오고, 그 뒤에 알파벳 e가 따라오는 것을 나타냅니다."[Tt]he" => The car parked in the garage.
단, 문자 세트의 마침표는 문자 그대로의 의미를 나타냅니다. 정규식
ar[.]은 알파벳 소문자 a 뒤에 알파벳 r이 오고 그 뒤에 마침표 . 문자 부호가 오는 것을 나타냅니다."ar[.]" => A garage is a good place to park a car.
부정 문자 세트
일반적으로 삽입 문자
^은 한 문자열의 시작을 나타냅니다. 그러나 대괄호 안에 나타날 때는 문자 세트를 취소합니다. 예를 들어 정규식 [^c]ar은 알파벳 c를 제외한 임의 문자 뒤에 문자 a가 옵니다.
그 뒤에 r이 옵니다."[^c]ar" => The car parked in the garage.
중복
메타 문자
+, * 또는 ?는 하위 패턴이 여러 번 나타날 수 있음을 지정할 때 사용합니다. 이런 메타 문자는 상황에 따라 그 역할이 다릅니다.별표
* 부호는 이전 매칭 규칙과 0번 이상 매칭함을 나타냅니다. 정규식 a*은 알파벳 소문자 a가 0번 이상 중복될 수 있음을 나타냅니다. 그러나 문자 세트나 문자 클래스 뒤에 나타날 경우 이는 전체 문자 세트의 중복을 나타냅니다.
예를 들어 정규식 [a-z]*은 한 행에 임의 수의 알파벳 소문자을 포함할 수 있음을 나타냅니다."[a-z]*" => The car parked in the garage.
* 부호는 메타 부호 .과 함께 사용되어 임의 문자열 .*에 매칭될 수 있습니다. * 부호는 공란 부호 \\s와 함께 사용하여 일련의 공란 부호에 매칭될 수 있습니다.
예를 들어 정규식 \\s*cat\\s*는 0개 이상의 공란 뒤에 알파벳 소문자 c, a, t가 오고 그 뒤에 0개 이상의 공란이 오는 것을 나타냅니다."\\s*cat\\s*" => The fat cat sat on the cat.
덧셈표
부호
+는 이전 문자에 한 번 이상 매칭합니다. 예를 들어 정규식 c.+t는 알파벳 소문자 c 뒤에 임의의 수의 문자가 오고 그 뒤에 알파벳 소문자 t가 오는 것을 나타냅니다."c.+t" => The fat cat sat on the mat.
물음표
정규식에서 메타 문자
?는 이전 문자가 선택 가능함을 나타냅니다. 이 부호는 이전 부호와 0번 또는 한 번 매칭합니다.
예를 들어 정규식 [T]?he는 선택 가능한 알파벳 대문자 T 뒤에 알파벳 소문자 h, e가 오는 것을 나타냅니다."[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
중괄호
정규식에서 중괄호(양화사라고도 함)는 문자 또는 한 세트의 문자가 중복 가능한 횟수를 지정하는 데 사용됩니다. 예를 들어 정규식
[0-9]{2,3}은 최소 두 자리 숫자에 매칭되고 세 자리를 초과하지 않음(0에서 9 범위 내의 문자)을 나타냅니다."[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
두 번째 숫자를 생략할 수 있습니다. 예를 들어 정규식
[0-9]{2,}는 2개 이상의 숫자에 매칭됨을 나타냅니다. 쉼표를 삭제한 경우 정규식 [0-9]{2}는 정확히 두 자리의 숫자에 매칭함을 나타냅니다."[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
"[0-9]{2}" => The number was 9.9997 but we rounded it off to 10.0.
문자 집합
문자 집합은 소괄호 안에 기입된 하위 패턴
(...)입니다. 정규식에서 언급했듯이 하나의 중괄호를 하나의 문자 뒤에 놓으면 이는 이전 문자를 반복하게 됩니다.
그러나 중괄호를 하나의 문자 집합 뒤에 놓으면 이는 전체 문자 집합을 반복합니다.
예를 들어 정규식 (ab)*는 0개 이상의 문자열 “ab”에 매칭함을 나타냅니다. 또한 문자 집합에서 메타 문자 |를 사용할 수 있습니다. 예를 들어 정규식 (c|g|p)ar은 알파벳 소문자 c, g 또는 p 뒤에 알파벳 소문자 a, r이 오는 것을 나타냅니다."(c|g|p)ar" => The car is parked in the garage.
분기 구조
정규식에서 수직바
|는 여러 표현식 간의 조건에 해당하는 분기 구조를 정의하는 데 사용됩니다. 문자 세트와 분기 구조의 원리가 동일하다고 생각할 수 있습니다.
그러나 문자 세트와 분기 구조의 큰 차이점은 문자 세트는 문자 수준에서만 적용되지만 분기 구조는 표현식 수준에서 사용될 수 있다는 점입니다.
예를 들어 정규식 (T|t)he|car는 알파벳 대문자 T 또는 t, 알파벳 소문자 h, 알파벳 소문자 e 또는 알파벳 소문자 c, 알파벳 소문자 a, 알파벳 소문자 r이 순서대로 오는 것을 나타냅니다."(T|t)he|car" => The car is parked in the garage.
이스케이프 문자
정규식에서 백슬래시
\\를 사용하여 다음 문자를 이스케이프 처리합니다. 이렇게 하면 예약어를 사용하여 문자 { } [ ] / \\ + * . $ ^ | ?에 매칭하도록 허용합니다. 특수 문자 앞에 \\를 추가하면 문자 매칭을 할 수 있습니다.
예를 들어 정규식 .은 줄 바꿈 부호 외의 임의 문자에 매칭하는 데 사용됩니다. 이제 입력 문자열에서 . 문자에 매칭해야 합니다. 정규식 (f|c|m)at\\.?은 알파벳 소문자 f, c 또는 m 뒤에 알파벳 소문자 a, t가 오고, 그 뒤에 선택 가능한 . 문자가 오는 것을 나타냅니다."(f|c|m)at\\.?" => The fat cat sat on the mat.
위치 조정 문자
정규식에서 매칭 부호가 시작 부호인지, 종료 부호인지 확인하기 위해 위치 조정 문자를 사용합니다.
위치 조정 문자에는 두 가지 유형이 있습니다. 첫 번째 유형은
^로, 매칭 문자가 시작 문자인지 확인합니다. 두 번째 유형은 $로, 매칭 문자가 입력 문자열의 가장 마지막 문자인지 확인합니다.삽입 부호
삽입 부호
^는 매칭 문자가 입력 문자열의 첫 번째 문자인지 확인할 때 사용됩니다. 정규식 ^a를 사용하여(a가 시작 부호인 경우) 문자열 abc에 매칭하는 경우 a에 매칭됩니다.
그러나 정규식 ^b를 사용한 경우 문자열 abc에서 “b”는 시작 문자가 아니므로 어떤 것에도 매칭되지 못합니다.
다음으로, 정규식 (T|t)he는 알파벳 대문자 T 또는 알파벳 소문자 t가 입력 문자열의 시작 부호이고, 뒤에 알파벳 소문자 h, e가 오는 것을 나타냅니다."(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
달러 부호
달러 부호
$는 매칭 문자가 입력 문자열의 가장 마지막 문자인지 확인할 때 사용됩니다. 예를 들어 정규식 (at\\.)$은 알파벳 소문자 a, t가 오고 그 뒤에 하나의 . 문자가 오는 것을 나타냅니다. 그리고 이 매칭은 반드시 문자열의 끝이어야 합니다."(at\\.)" => The fat cat. sat. on the mat.
"(at\\.)$" => The fat cat sat on the mat.
약어 문자 세트
정규식은 일반적으로 사용되는 문자 세트 및 정규식에 대한 약어를 제공합니다. 약어 문자 세트는 아래와 같습니다.
약어 | 설명 |
. | 줄 바꿈 부호 외의 임의 문자 매칭 |
\\w | 모든 알파벳 및 숫자의 문자 매칭: [a-zA-Z0-9_] |
\\W | 알파벳 및 숫자가 아닌 문자의 매칭: [^\\w] |
\\d | 숫자 매칭: [0-9] |
\\D | 비숫자 매칭: [^\\d] |
\\s | 공란 부호 매칭: [\\t\\n\\f\\r\\p{Z}] |
\\S | 비공란 부호 매칭: [^\\s] |
어서션
후방 탐색 어서션과 전방 탐색 어서션은 단순히 어서션이라고 불리기도 합니다. 이는 특수 유형의 non-capturing 그룹으로, 패턴 매칭에 사용되지만 매칭 리스트에 포함되지 않습니다. 특정 패턴 앞이나 뒤에 이런 패턴이 있을 경우 우선적으로 어서션을 사용하게 됩니다.
예를 들어 입력 문자열
$4.44 and $10.88에서 $ 문자 앞의 모든 숫자를 가져오려고 할 경우, 정규식 (?<=\\$)[0-9\\.]*을 사용하여 $ 문자 앞의 모든 숫자는 . 문자를 포함하도록 나타낼 수 있습니다.
다음은 정규식에 사용되는 어서션입니다.부호 | 설명 |
?= | 긍정형 전방 탐색 어서션 |
?! | 부정형 전방 탐색 어서션 |
?<= | 긍정형 후방 탐색 어서션 |
?<! | 부정형 후방 탐색 어서션 |
긍정형 전방 탐색 어서션
긍정형 전방 탐색 어서션은 표현식의 첫 번째 부분이 전방 탐색 어서션 표현식이어야 한다고 선언합니다. 반환된 매칭 결과에는 첫 번째 부분과 매칭되는 텍스트만 포함됩니다.
괄호 안에서 긍정형 전방 탐색 어서션을 정의하려면 괄호 안 물음표와 등호는
(?=...)와 같이 사용됩니다. 전방 탐색 어서션 표현식은 괄호 안에서 등호 뒤에 입력됩니다.
예를 들어 정규식 (T|t)he(?=\\sfat)는 알파벳 대문자 T 또는 알파벳 소문자 t 뒤에 알파벳 h, e가 오는 것을 나타냅니다.
괄호 안에는 정규식 엔진이 The 또는 the 뒤에 fat에 매칭하도록 하는 긍정형 전방 탐색 어서션을 정의합니다."(at\\.)$" => The fat cat sat on the mat.
부정형 전방 탐색 어서션
입력 문자열에서 매칭되지 않는 표현식의 콘텐츠를 가져오려고 할 경우, 부정형 전방 탐색 어서션을 사용합니다. 부정형 전방 탐색 어서션의 정의는 긍정형 전방 탐색 어서션과 동일합니다.
유일한 차이점은 등호
=가 아닌 부정 부호 !를 사용합니다. 예를 들면 (?!...)와 같습니다.
정규식 (T|t)he(?!\\sfat)을 살펴보겠습니다. 입력 문자열에서 The 또는 the 모두를 가져오고 매칭되지 않는 fat 앞에 한 개의 공란 문자를 추가한 것을 나타냅니다."(T|t)he(?!\\sfat)" => The fat cat sat on the mat.
긍정형 후방 탐색 어서션
긍정형 후방 탐색 어서션은 특정 패턴 앞의 모든 매칭 콘텐츠를 가져오는 데 사용됩니다. 긍정형 후방 탐색 어서션은
(?<=...)로 나타냅니다. 예를 들어 정규식 (?<=(T|t)he\\s)(fat|mat)은 입력 문자열에서 단어 The 또는 the 후의 모든 fat과 mat 단어를 가져오는 것을 나타냅니다."(?<=(T|t)he\\s)(fat|mat)" => The fat cat sat on the mat.
부정형 후방 탐색 어서션
부정형 후방 탐색 어서션은 특정 패턴 앞의 모든 매칭 콘텐츠를 가져오는 데 사용됩니다. 부정형 후방 탐색 어서션은
(?<!...)로 나타냅니다. 예를 들어 정규식 (?<!(T|t)he\\s)(cat)은 입력 문자열에서 The 또는 the 뒤에 오지 않는 단어 cat을 모두 가져오는 것을 나타냅니다."(?<!(T|t)he\\s)(cat)" => The cat sat on cat.
플래그
플래그는 정규식의 출력을 수정하므로 수정자라고도 합니다. 플래그는 임의 순서대로 또는 조합하여 사용할 수 있으며 정규식의 일부입니다.
플래그 | 설명 |
i | 대소문자 구분하지 않음: 대소문자를 구분하지 않도록 매칭을 설정합니다. |
g | 전역 검색: 전체 입력 문자열의 모든 매칭 항목을 검색합니다. |
m | 여러 행 매칭: 입력 문자열의 각 행에 매칭합니다. |
대소문자 구분하지 않음
i 수정자는 대소문자를 구분하지 않은 매칭을 실행할 때 사용합니다. 예를 들어 정규식 /The/gi는 알파벳 대문자 T 뒤에 알파벳 소문자 h, e가 오는 것을 나타냅니다.
그러나 정규 매칭이 끝날 때 i 플래그는 정규식 엔진에서 이 상황을 무시하도록 지시합니다. 또한 전체 입력 문자열에서 매칭을 검색하므로 g 플래그를 사용하였습니다."The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
전역 검색
g 수정자는 전역 매칭 실행에 사용됩니다. 모든 매칭을 조회하게 되며 첫 번째 매칭을 조회한 후 중단하지 않습니다.
예를 들어 정규식 /.(at)/g은 줄 바꿈 부호 외의 임의 문자 뒤에 알파벳 소문자 a, t가 오는 것을 나타냅니다.
정규식의 끝에 g 플래그를 사용하였으므로 전체 입력 문자열에서 각 매칭 항목을 찾게 됩니다.".(at)" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
여러 행 매칭
m 수정자는 여러 행의 매칭 실행에 사용됩니다. 앞에서 언급한 것처럼 (^, $)은 위치 조정 부호를 사용하여 매칭 문자가 입력 문자열의 시작이나 종료인지 확인합니다. 그러나 각 행마다 위치 조정 부호를 사용하기를 원할 때는 m 수정자를 사용합니다.
예를 들어 정규식 /at(.)?$/gm은 알파벳 소문자 a, t를 나타내며 줄 바꿈 부호 외의 임의 문자를 0번 또는 한 번 매칭합니다. 그리고 m 플래그를 사용했으므로 이제 정규식 엔진은 문자열에서 각 행의 끝에 매칭합니다."/.at(.)?$/" => The fatcat saton the mat.
"/.at(.)?$/gm" => The fatcat saton the mat.
일반 정규식
유형 | 표현식 |
자연수 | ^-\\d+$ |
음수 | ^-\\d+$ |
전화번호 | ^+?[\\d\\s]{3,}$ |
전화 코드 | ^+?[\\d\\s]+(?[\\d\\s]{10,}$ |
정수 | ^-?\\d+$ |
사용자 이름 | ^[\\w\\d_.]{4,16}$ |
영숫자 | ^[a-zA-Z0-9]*$ |
공란이 있는 영숫자 | ^[a-zA-Z0-9 ]*$ |
비밀번호 | ^(?=^.{6,}$)((?=.*[A-Za-z0-9])(?=.*[A-Z])(?=.*[a-z]))^.*$ |
이메일 | ^([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,4})*$ |
IPv4 주소 | ^((?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?))*$` |
알파벳 소문자 | ^([a-z])*$ |
알파벳 대문자 | ^([A-Z])*$ |
사용자 이름 | ^[\\w\\d_.]{4,16}$ |
사이트 주소 | ^(((http|https|ftp):\\/\\/)?([[a-zA-Z0-9]\\-\\.])+(\\.)([[a-zA-Z0-9]]){2,4}([[a-zA-Z0-9]\\/+=%&_\\.~?\\-]*))*$ |
VISA 신용카드 번호 | ^(4[0-9]{12}(?:[0-9]{3})?)*$ |
날짜(MM/DD/YYYY) | ^(0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])[- /.](19|20)?[0-9]{2}$ |
날짜(YYYY/MM/DD) | ^(19|20)?[0-9]{2}[- /.](0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])$ |
마스터 신용카드 번호 | ^(5[1-5][0-9]{14})*$ |
피드백