본 문서는 TencentDB for MySQL 또는 TDSQL-C MySQL의 DTS에서 데이터 구독 작업을 생성하는 방법을 설명합니다.
전제 조건
구독할 TencentDB 인스턴스를 준비했으며 데이터베이스 버전이 요구 사항을 충족합니다. 자세한 내용은 데이터 구독이 지원하는 데이터베이스를 참고하십시오.
원본 인스턴스에서 binlog가 활성화되었습니다.
구독 계정이 원본 인스턴스에 생성되었습니다. 필요한 계정 권한은 다음과 같습니다: REPLICATION CLIENT, REPLICATION SLAVE, PROCESS 및 모든 대상의 SELECT 권한.
구체적인 권한 부여 명령은 다음과 같습니다.
create user ‘마이그레이션 계정’ IDENTIFIED BY ‘계정 비밀번호’;
grant SELECT, REPLICATION CLIENT, REPLICATION SLAVE, PROCESS on *.* to '마이그레이션 계정'@'%';
flush privileges;
제한
현재 구독 메시지 내용은 기본적으로 1일 동안 보관됩니다. 만료된 데이터는 삭제됩니다. 따라서 즉시 데이터를 소비하는 것이 좋습니다.
데이터가 소비되는 리전은 가입된 데이터베이스의 리전과 동일해야 합니다.
geometry 데이터 유형은 현재 지원되지 않습니다.
DTS에서 Kafka 메시지 구독의 전달 의미는 적어도 한 번(at least once) 메시지를 전달하는 것입니다. 따라서 특별한 경우에 소비된 데이터가 중복될 수 있습니다. 예를 들어 구독 작업이 다시 시작되면 다시 시작한 후 중단 오프셋 전에 원본 Binlog가 당겨져 메시지가 반복적으로 전달됩니다. 등록된 객체 수정 및 비정상 작업 복원과 같은 콘솔 작업은 중복 메시지를 유발할 수 있습니다. 비즈니스가 중복 데이터에 민감한 경우 소비 Demo에서 비즈니스 데이터를 기반으로 중복 제거 로직을 추가해야 합니다.
구독을 지원하는 SQL 작업
작업 유형
지원되는 SQL 작업
DML
INSERT, UPDATE, DELETE
DDL
CREATE DATABASE, DROP DATABASE, CREATE TABLE, ALTER TABLE, DROP TABLE, RENAME TABLE
작업 단계
1. DTS 콘솔에 로그인한 뒤 왼쪽 사이드바에서 데이터 구독을 선택하고 데이터 구독 생성을 클릭합니다.
2. 데이터 구독 생성 페이지에서 적합한 설정을 선택하고 구매하기를 클릭합니다.
과금 방식: 정액 과금제 및 종량제 과금 방식을 지원합니다.
리전: 리전은 구독하려는 데이터베이스의 인스턴스 리전과 일치해야 합니다.
데이터베이스: 실제 데이터베이스 유형을 선택합니다.
버전: kafka 버전을 선택하면 Kafka 클라이언트를 통한 직접 소비를 지원합니다.
구독 인스턴스 이름: 현재 데이터 구독 인스턴스의 이름을 편집합니다.
3. 구매 성공 후, 데이터 구독 리스트로 돌아가 작업열의 구독 설정을 클릭해 새로 구입한 구독의 설정을 진행합니다. 설정 완료 후 사용할 수 있습니다.
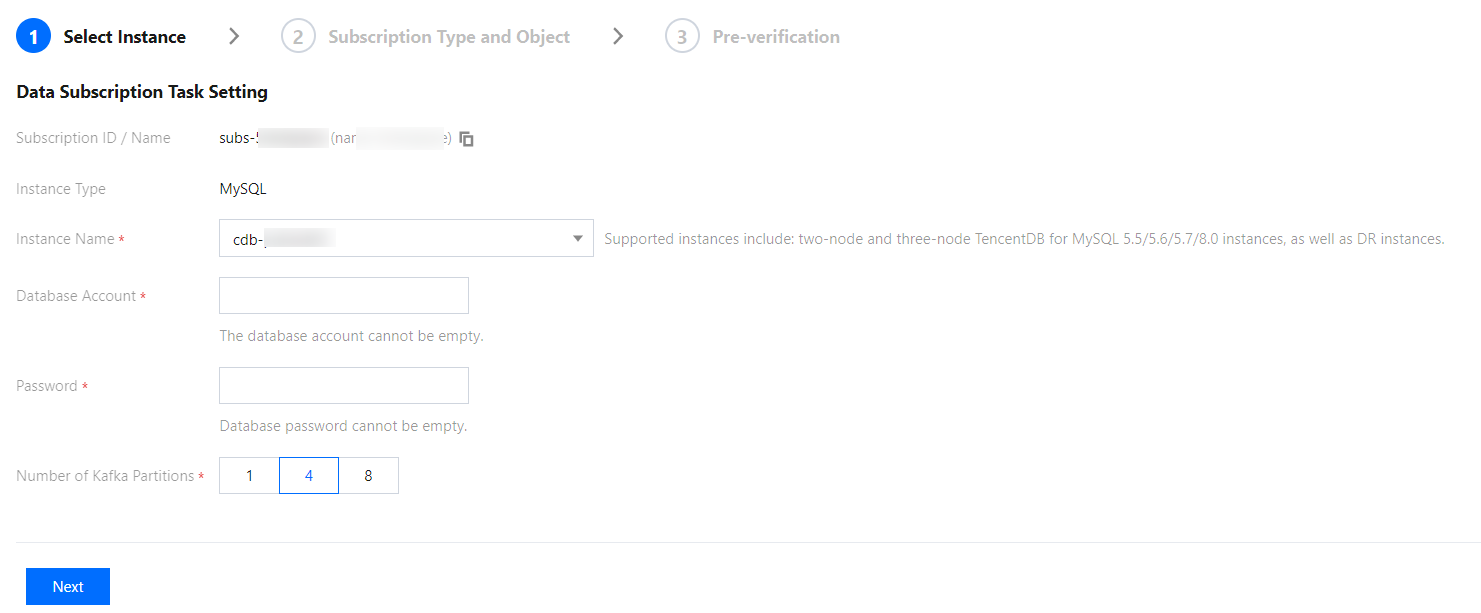
4. 데이터베이스 구독 설정 페이지에서 적합한 설정을 선택하고 다음 단계를 클릭합니다.
인스턴스: 데이터 인스턴스를 선택합니다. 현재 읽기 전용 및 재해 복구 인스턴스는 데이터 구독을 지원하지 않습니다.
데이터베이스 계정: 구독 인스턴스의 계정과 비밀번호를 추가합니다. 계정은 구독 작업에 필요한 REPLICATION CLIENT, REPLICATION SLAVE, PROCESS 및 모든 대상의 SELECT 권한을 갖추고 있습니다.
kafka 파티션 수: kafka 파티션의 수를 설정합니다. 숫자를 늘리면 데이터 쓰기 및 소비 속도가 향상될 수 있습니다. 단일 파티션은 메시지 순서를 보장할 수 있지만 여러 파티션은 보장할 수 없습니다. 사용 중 메시지 순서에 대한 엄격한 요구 사항이 있는 경우 이 값을 1로 설정하십시오.
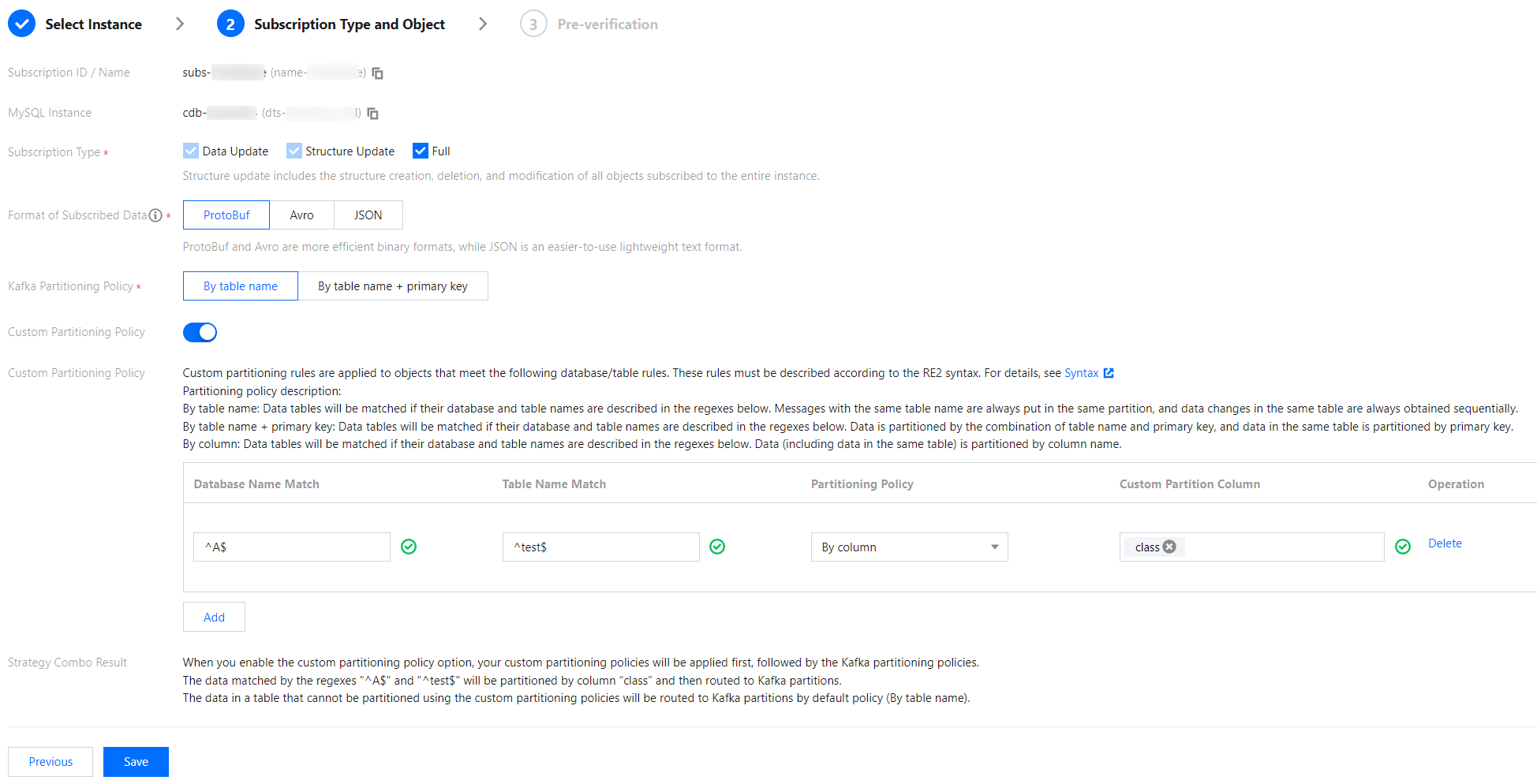
5. 구독 유형 및 대상 선택 페이지에서 구독 유형을 선택하고 설정 저장을 클릭합니다.
구독 유형: 옵션에는 데이터 업데이트, 구조 업데이트 및 전체가 포함됩니다.
데이터 업데이트: 데이터 INSERT, UPDATE, DELETE 작업을 포함하여 선택한 대상의 데이터 업데이트를 구독합니다.
구조 업데이트: 구독 인스턴스 내 모든 대상의 구조를 생성, 수정 및 삭제합니다.
전체 인스턴스: 해당 구독 인스턴스의 모든 대상의 데이터 업데이트 및 구조 업데이트를 포함합니다.
구독 데이터 형식: ProtoBuf, Avro 및 Json의 3가지 형식을 지원합니다. ProtoBuf와 Avro는 사용 효율이 높은 이진법 형식을 사용하고 Json은 사용하기 쉬운 경량 텍스트 형식을 사용합니다.
Kafka 분할 전략: 테이블 이름별 또는 테이블 이름+기본 키별을 선택합니다.
사용자 지정 파티션 정책 사용: 사용자가 자신의 필요에 따라 파티션을 사용자 지정할 수 있습니다. 자세한 내용은 파티션 정책 설정을 참고하십시오.
6. 사전 인증 페이지에서 2 - 3분에 걸쳐 사전 인증 작업이 실행됩니다. 사전 인증이 완료된 후, 실행을 클릭하여 데이터 구독 작업 설정을 완료합니다.