Release Notes
Broker Release Notes
Announcement
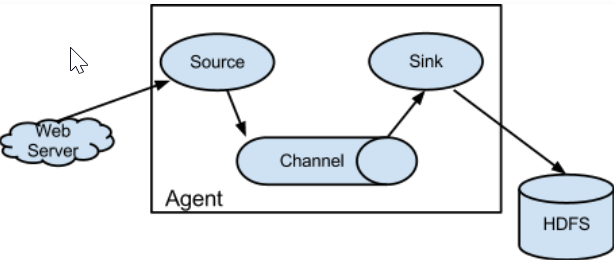
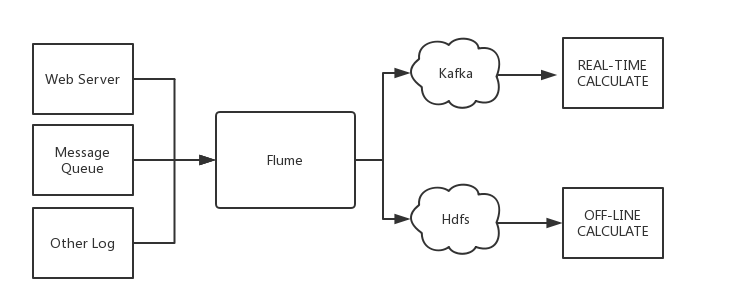
Configuration Item | Description |
channels | Channel configured by yourself |
type | Must be org.apache.flume.source.kafka.KafkaSource |
kafka.bootstrap.servers | Server address of the Kafka broker |
kafka.consumer.group.id | ID of Kafka's consumer group |
kafka.topics | Data target topics in Kafka |
batchSize | Size of each write into the channel |
batchDurationMillis | Maximum write interval |
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSourcetier1.sources.source1.channels = channel1tier1.sources.source1.batchSize = 5000tier1.sources.source1.batchDurationMillis = 2000tier1.sources.source1.kafka.bootstrap.servers = localhost:9092tier1.sources.source1.kafka.topics = test1, test2tier1.sources.source1.kafka.consumer.group.id = custom.g.id
Configuration Item | Description |
channel | Channel configured by yourself |
type | Must be org.apache.flume.sink.kafka.KafkaSink |
kafka.bootstrap.servers | Server of the Kafka broker |
kafka.topics | Data source topics in Kafka |
kafka.flumeBatchSize | Size of each written batch |
kafka.producer.acks | Production policy of the Kafka producer |
a1.sinks.k1.channel = c1a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSinka1.sinks.k1.kafka.topic = mytopica1.sinks.k1.kafka.bootstrap.servers = localhost:9092a1.sinks.k1.kafka.flumeBatchSize = 20a1.sinks.k1.kafka.producer.acks = 1

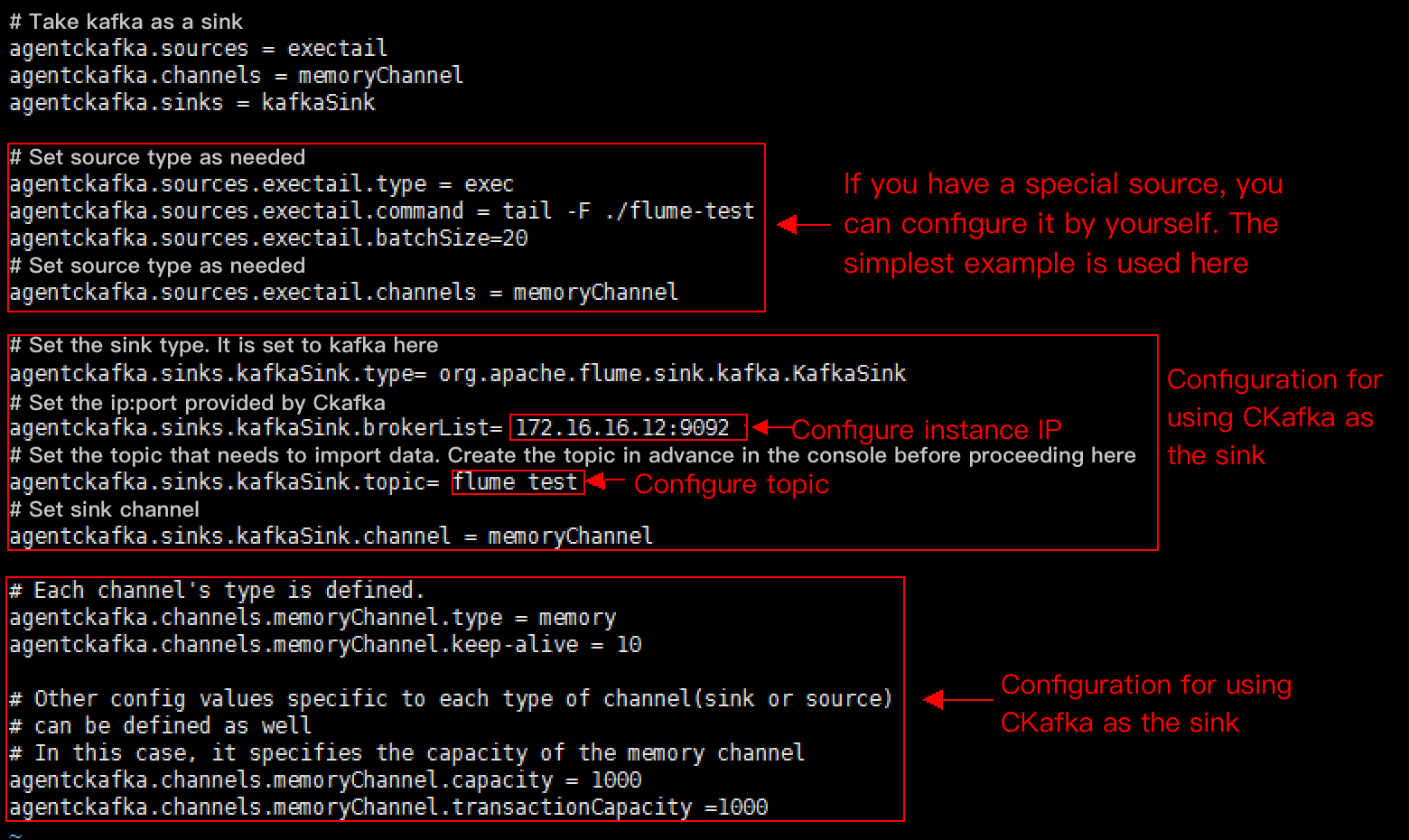
# Demo for using Kafka as the sink.agentckafka.source = exectailagentckafka.channels = memoryChannelagentckafka.sinks = kafkaSink# Set the source type based on different requirements. For a special source, you can configure it yourself. In this case, we use the simplest example.agentckafka.sources.exectail.type = execagentckafka.sources.exetail.command = tail -F ./flume.testagentckafka.sources.exectail.batchSize = 20# Set the source channel.agentckafka.sources.exectail.channels = memoryChannel# Set the sink type. In this case, it is set to Kafka.agentckafka.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink# In this case, set the ip:port provided by CKafka.agentckafka.sinks.kafkaSink.brokerList = 172.16.16.12:9092 # Configure the instance IP address.# Set the topic to which data is to be imported. Create the topic in the console in advance.agentckafka.sinks.kafkaSink.topic = flume test #Configure the topic.# Set the sink channel.agentckafka.sinks.kafkaSink.channel = memoryChannel# Use the default configuration for the channel.# Each channel's type is defined.agentckafka.channels.memoryChannel.type = memoryagentckafka.channels.memoryChannel.keep-alive = 10# Other config values specific to each type of channel(sink or source) can be defined as well# In this case, it specifies the capacity of the memory channelagentckafka.channels.memoryChannel.capacity = 1000agentckafka.channels.memoryChannel.transactionCapacity = 1000
./bin/flume-ng agent -n agentckafka -c conf -f conf/flume-kafka-sink.properties

./kafka-console-consumer.sh --bootstrap-server xx.xx.xx.xx:xxxx --topic flume_test --from-beginning --new-consumer


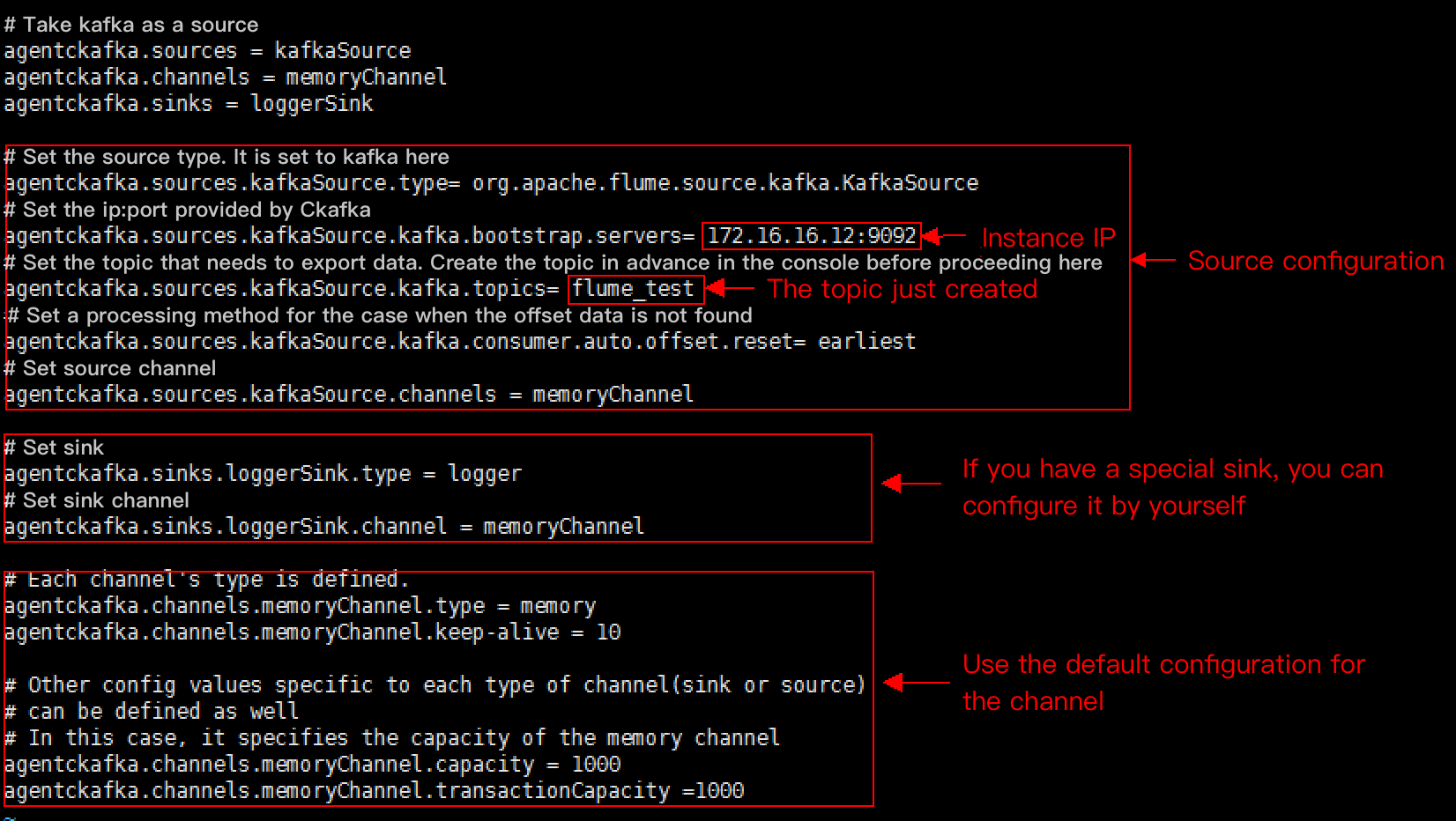
./bin/flume-ng agent -n agentckafka -c conf -f conf/flume-kafka-source.properties
logs/flume.log).

피드백