表分区使用
Download
聚焦模式
字号
本文介绍腾讯云数据仓库 TCHouse-P 如何使用表的分区能力。
什么是分区表
分区表就是将一个大表在物理上分割成若干小表,并且整个过程对用户是透明的,也就是用户的所有操作仍然是作用在大表上,不需要关心数据实际上落在哪张小表里面。腾讯云数据仓库 TCHouse-P 中分区表的原理和 PostgreSQL 一样,都是通过表继承和约束实现的。
分区表示例如下:
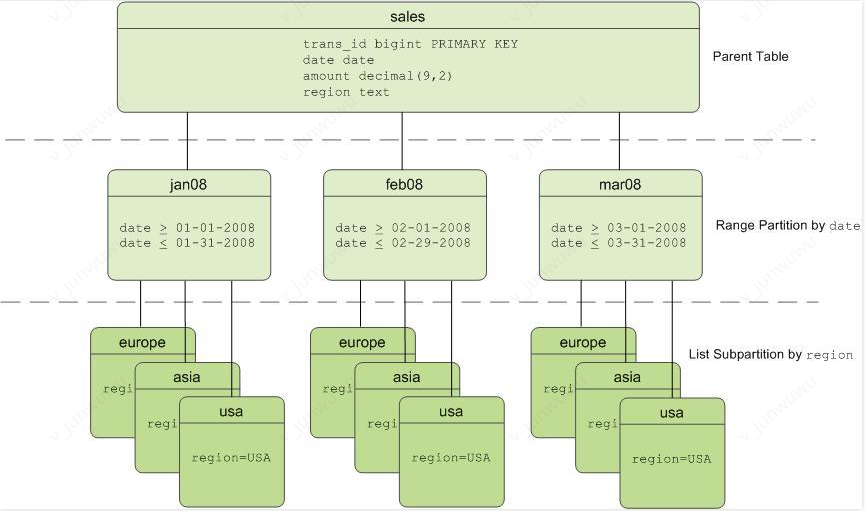
使用分区表场景
是否使用分区表,可以通过以下几个方面进行考虑:
表数据量是否足够大:通常对于大的事实表,例如数据量有几千万或者过亿,我们可以考虑使用分区表,但数据量大小并没有一个绝对的标准可以使用,一般是根据经验,以及对目前性能是否满意。
表是否有合适的分区字段:如果数据量足够大了,这个时候我们就需要看下是否有合适的字段能够用来分区,通常如果数据有时间维度,例如按天,按月等,是比较理想的分区字段。
表内数据是否具有生命周期:通常数仓中的数据不可能一直存放,一般都会有一定的生命周期,例如最近一年等,这里就涉及到对旧数据的管理,如果有分区表,就很容易删除旧的数据,或者将旧的数据归档到 对象存储 等更为廉价的存储介质上。
查询语句中是否含有分区字段:如果您对一个表做了分区,但是所有的查询都不带分区字段,这不仅无法提高性能反而会使性能下降,因为所有的查询都会扫描所有的分区表。
创建分区表
范围分区(Range Partition)
列表分区(List Partition)
组合分区(A combination of both types)
范围分区示例:
CREATE TABLE test_range_partition(uid int,fdate character varying(32))PARTITION BY RANGE(fdate)(PARTITION p1 START ('2018-11-01') INCLUSIVE END ('2018-11-02') EXCLUSIVE,PARTITION p2 START ('2018-11-02') INCLUSIVE END ('2018-11-03') EXCLUSIVE,DEFAULT PARTITION pdefault);
以上例子是按天建表,如果时间跨度比较大,会导致建表语句很长,书写起来也不方便,这时候可以使用以下语法:
CREATE TABLE test_range_partition_every_1(uid int,fdate date)partition by range (fdate)(PARTITION pn START ('2018-11-01'::date) END ('2018-12-01'::date) EVERY ('1 day'::interval),DEFAULT PARTITION pdefault);
列表分区示例:
CREATE TABLE test_list_partition(uid int,gender char(1))PARTITION BY LIST (gender)(PARTITION girls VALUES ('F'),PARTITION boys VALUES ('M'),DEFAULT PARTITION pdefault);
管理分区表
分区表也是一张表,所以对于表的很多操作也可以作用于分区表上,这里列举了常用的一些操作:
清空子分区
ALTER TABLE test_range_partition TRUNCATE PARTITION p1;
删除子分区
ALTER TABLE test_range_partition DROP PARTITION p1;
说明:
DROP PARTITION 之后跟的是 partition name,而不是 partition table name,这两者之间是有区别的,如果是使用 EVERY 语法创建的分区表,您需要通过 pg_partitions 表查询到对应分区的 partition name。
ALTER TABLE test_range_partition ADD PARTITION p3 START ('2018-11-03') INCLUSIVE END ('2018-11-04') EXCLUSIVE;
说明:
如果分区表中含有 DEFAULT 分区,会出现如下错误
ERROR: cannot add RANGE partition "p3" to relation "test_range_partition" with DEFAULT partition "pdefault",解决办法可以参见滚动分区。滚动分区
通常按时间分区的表,都有一个特性,就是分区会不断往前滚动,例如一个按天分区,保存最近10天的分区表,每到新一天,就会要删除10天前的分表,并且创建一个新的分区表容纳最新的数据。
如果是含有默认分区的,可以使用分区 Split。
ALTER TABLE test_range_partition SPLIT DEFAULT PARTITION START ('2018-11-03') INCLUSIVE END ('2018-11-04') EXCLUSIVE INTO (PARTITION p3, DEFAULT partition);
这样新分区就被添加,同时保留了默认分区,然后在删除老的分区就完成新老分区的更替。
交换分区
交换分区就是将一张普通的表和某张分区表进行交换,这个功能在数据分层存储十分有用。
例如我们会需要根据对象存储的不同目录设置分区,这个需求就可以使用交换分区完成,这样对于一张大表,他的较少查询的历史数据就可以放在对象存储上,语法如下:
ALTER TABLE {table_name} EXCHANGE PARTITION {partition_name|FOR (RANK(number))|FOR (value)} WITH TABLE {cos_table_name} WITHOUT VALIDATION;
查询分区
与分区相关的系统表或者视图如下:
pg_partitionpg_partition_columnspg_partition_encodingpg_partition_rulepg_partition_templatespg_partitions
查看分区基本信息
t2=# select * from pg_partitions where partitiontablename = 'test_range_partition_1_prt_p1';-[ RECORD 1 ]------------+---------------------------------------------------------------------------------------------------schemaname | publictablename | test_range_partitionpartitionschemaname | publicpartitiontablename | test_range_partition_1_prt_p1partitionname | p1parentpartitiontablename |parentpartitionname |partitiontype | rangepartitionlevel | 0partitionrank | 1partitionposition | 2partitionlistvalues |partitionrangestart | '2018-11-01'::character varying(32)partitionstartinclusive | tpartitionrangeend | '2018-11-02'::character varying(32)partitionendinclusive | fpartitioneveryclause |partitionisdefault | fpartitionboundary | PARTITION p1 START ('2018-11-01'::character varying(32)) END ('2018-11-02'::character varying(32))parenttablespace | pg_defaultpartitiontablespace | pg_default
查看分区定义
t2=# select pg_get_partition_def('test_range_partition'::regclass,true);-[ RECORD 1 ]--------+---------------------------------------------------------------------------------------------------------------pg_get_partition_def | PARTITION BY RANGE(fdate)| (| PARTITION p1 START ('2018-11-01'::character varying(32)) END ('2018-11-02'::character varying(32)),| PARTITION p2 START ('2018-11-03'::character varying(32)) END ('2018-11-04'::character varying(32)),| DEFAULT PARTITION pdefault| )
分区表使用最佳实践
分区的粒度
通常像范围分区的表都涉及到粒度问题,例如按时间分表,究竟是按天,按周,按月等。粒度越细,每张表的数据就越少,但是分区表的数量就会越多,反之亦然。
关于分区表的数量,这里没有绝对的标准,一般来说分区表的数量在100左右已经算是比较多了。
分区表数目过多,会有多方面的影响,例如查询优化器生成执行计划较慢,同时很多维护工作也都会变慢,例如 vacuum,recovering segment,expanding the cluster, checking disk usage 等。
查询语句
为了充分利用分区表的优势,需要在查询语句中尽量带上分区条件。最终目的是扫描尽量少的分区表。
文档反馈