- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 最佳实践
- 消息队列(Queue)模型
- 消息主题(Topic)模型
- 迁移说明
- 案例分享
- API 文档
- SDK 文档
- 词汇表
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 最佳实践
- 消息队列(Queue)模型
- 消息主题(Topic)模型
- 迁移说明
- 案例分享
- API 文档
- SDK 文档
- 词汇表
大数据入门的第一步,就是将海量的数据进行挖掘分析,提炼有价值的结果,引导未来的商业模型,如大众点评、滴滴打车在腾讯云已有深度的实践。例如:将微信、手机 QQ 上用户的热门分享的餐馆,实时反映到大众点评 App 的手机客户端上,推荐给消费者。
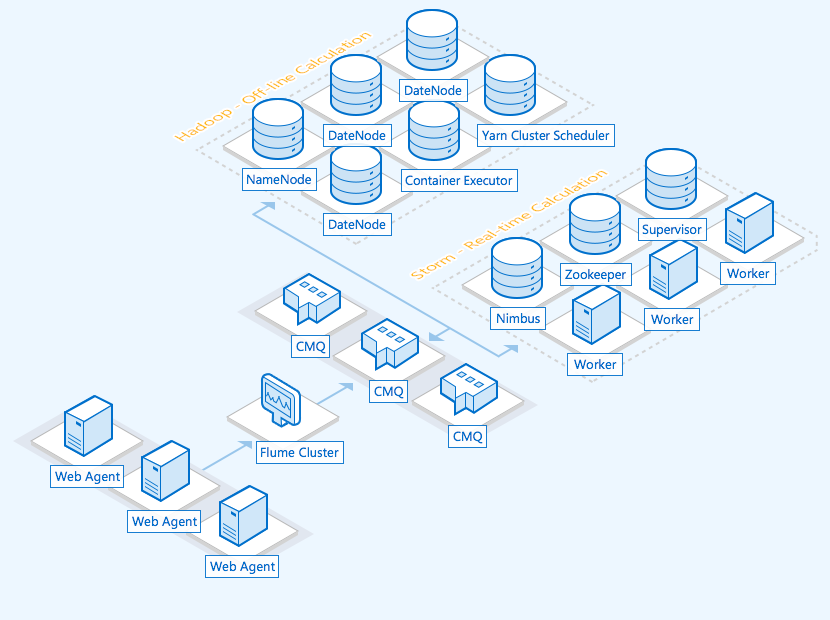
抽象出数据分析系统的特性,主要由以下模块组成:数据采集、数据接入、流式计算、离线计算、数据持久化。
- 数据采集
负责从各节点上实时采集数据,选用开源的 flume 来实现。所有的业务服务器的日志等数据以漏斗形式的数据流入到 CMQ 管道。 - 数据接入
由于采集数据的速度和数据处理的速度不一定同步,为了保证日志写入、分析的稳定可靠,添加一个 CMQ 消息中间件来作为缓冲。 - 流式计算、离线数据分析
对采集到的数据进行实时分析,选用 Apache 的 Storm;离线数据分析基于 Spark 做长久的数据挖掘。 - 数据输出
对分析后的结果持久化,可用腾讯云数据库 MySQL 等方案。
在数据处理场景中,消息生产者是海量的日志数据的输入,在线分析的 Storm 集群是消息消费者。从经验来看, 消息消费端 Storm 处理消息的业务逻辑可能很复杂(涉及到实时计算、数据流式处理、Topology 的数据处理)。另一个问题则是消息消费端 Storm 出现故障的概率较高,导致短暂时间内无法消费或消费不畅。总而言之,消息生产者的效率是远高于消息消费者的。
Push 方式由于无法得知当前消息消费者的状态,所以只要有数据产生,便会不断地进行推送。在Storm集群处于高负载时,使用 Push 的方式可能会导致消费者的负载进一步加重,甚至崩溃。除非消息消费者有合适的反馈机制能够让服务端知道自己的状况。而采取 Pull 的方式问题就简单了许多,由于消息消费者是主动到服务端拉取数据,此时只需要降低访问频率。
腾讯云 CMQ 后续将推出 topic 主题模式,提供 Pull/Push 两种数据获取方式,CMQ 作为生产者数据和消费者数据之间的缓冲区。它允许消费者可用并且准备好的时候才读取数据。缓解消息生产者与消息消费者之间不同步问题,从而在两者之间加了一层缓冲区。

 是
是
 否
否
本页内容是否解决了您的问题?