A TaskManager of a Flink job executes the various types of operator logic you define. If its CPU load is too high, reduced throughput, increased delay, and other issues may occur. This event is triggered when the majority of TaskManagers of a job are almost fully loaded for a long period.
Note
This feature is in beta testing, so custom rules are not supported. This capability will be available in the future.
Trigger conditions
The system detects the CPU utilization of all TaskManagers of a Flink job every 5 minutes.
If the CPU utilization of a TaskManager exceeds 90% in 5 consecutive data points, its CPU load is considered to be too high.
If more than 80% of the TaskManagers of the job are under an extremely high CPU load, this event is triggered and pushed.
Note
To avoid frequent alarms, at most one push of this event can be triggered per hour for each running instance ID of each job.
Alarms
You can configure an alarm policy as instructed in Configuring Event Alarms (Events) for this event to receive trigger and clearing notifications in real time.
Suggestions
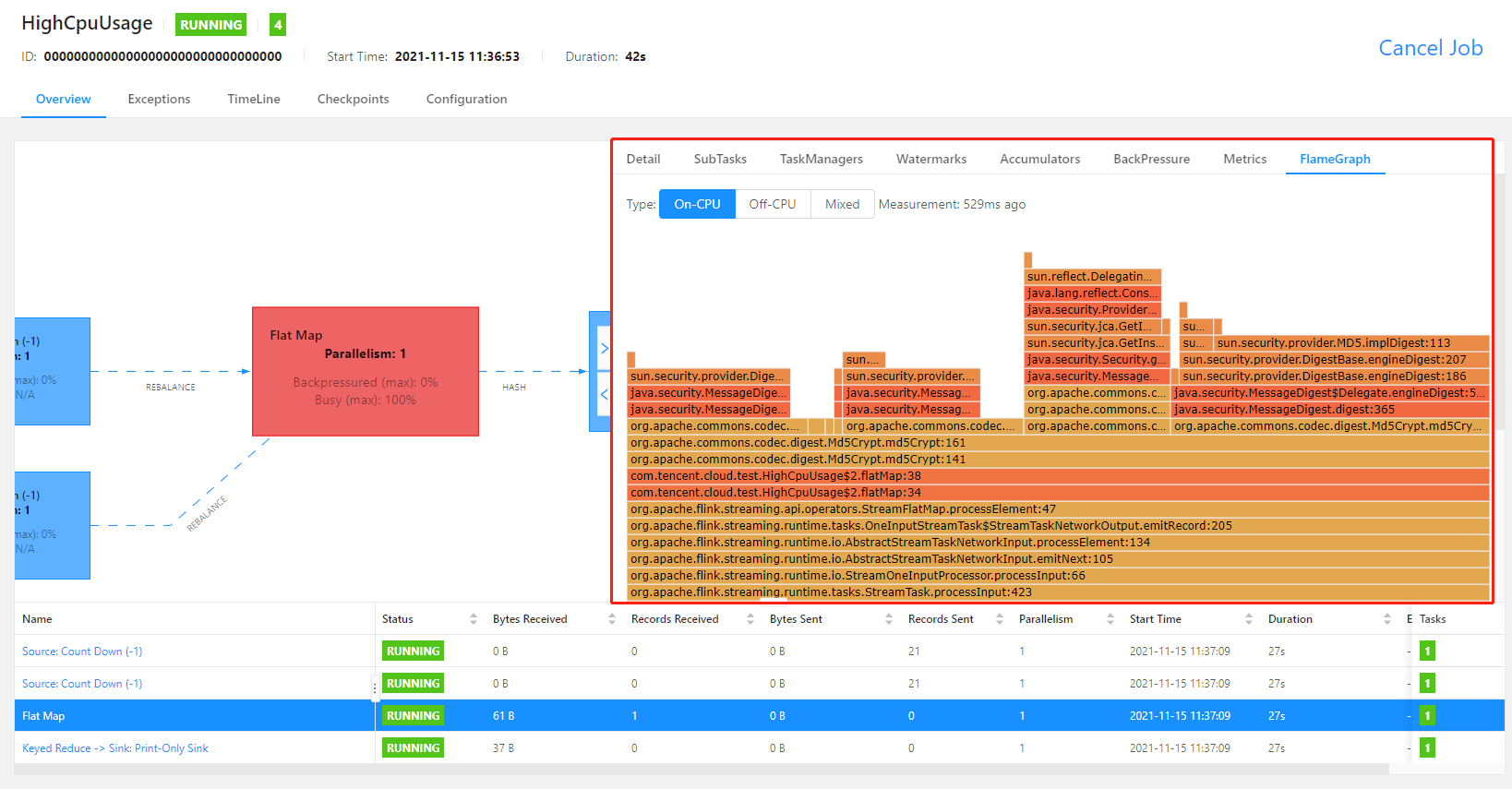
If Flink v1.13 or later is used, you can use the built-in Flame Graphs in Flink UI to analyze method call hotspots, i.e., those methods that occupy a lot of CPU time. Specifically, you need to add rest.flamegraph.enabled: true to the advanced parameters of the job as instructed in Advanced Job Parameters, and publish the new job version to use flame graphs.
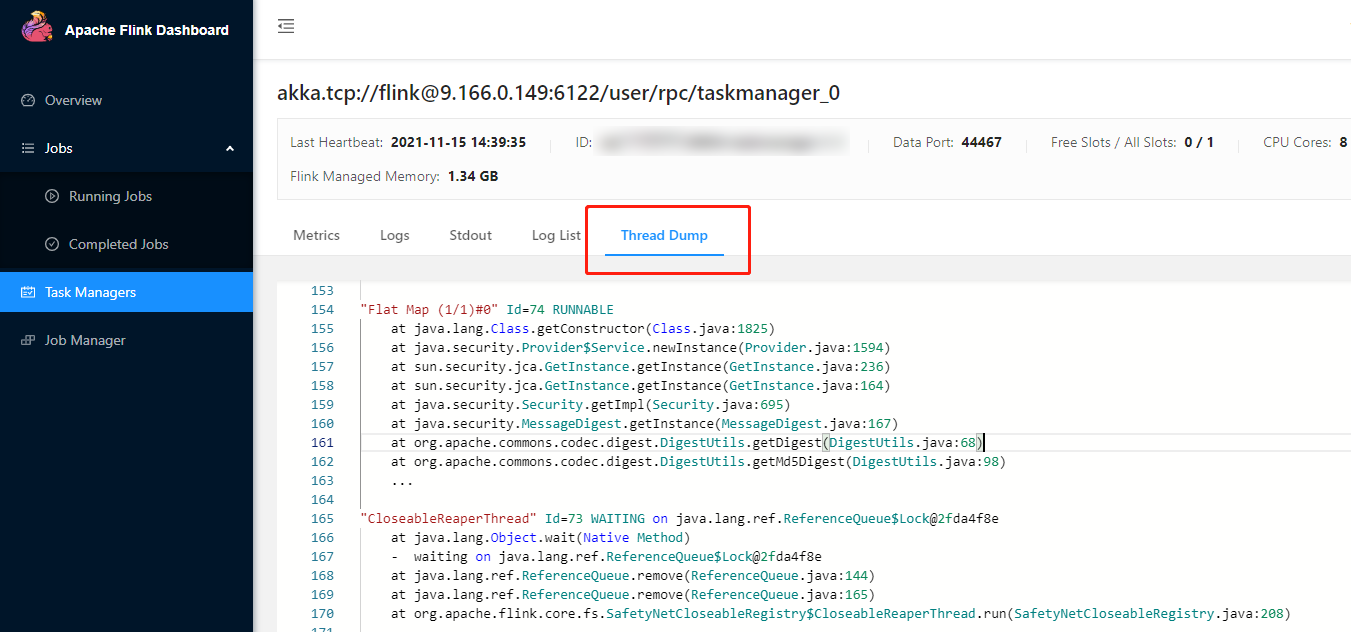
If flame graphs are not used, or Flink v1.11 or earlier is used, you need to check the thread dump information of the TaskManagers in the Flink UI to identify methods that are frequently called in busy operators.
If the problem persists after all above methods are used, submit a ticket to contact the technicians for help.