Product Architecture
Download
포커스 모드
폰트 크기
TDSQL Boundless instances are divided into two kinds: cluster edition and basic edition.
Cluster edition: Composed of multiple nodes, it provides high-performance and highly available database services in the form of a multi-replica Raft cluster, suitable for enterprise production environments.
Basic edition: Composed of a single node, it provides complete database features at a relatively low cost without high availability, suitable for individual users.
Note:
After a basic edition instance is created, it can be upgraded to a cluster edition instance through the console. Once a cluster edition instance is created, it cannot be downgraded to a basic edition instance.
The nodes in a TDSQL Boundless instance are divided into two types: peer-to-peer architecture and separated computing and storage architecture.
Peer-to-peer architecture: The computing layer SQLEngine and data layer TDStore are integrated into a single physical node, reducing the number of hardware nodes and cross-node communication, thereby lowering costs and improving performance.
Separated computing and storage architecture: The computing layer SQLEngine and data layer TDStore reside on separate physical nodes.
Technical Architecture of TDStore
The feature modules of centralized stand-alone databases and distributed databases can be divided into three components:
Computing engine: Mainly includes SQL parsing, optimizers, and executors.
Storage engine: Mainly includes transaction processing and data storage.
Metadata service: Mainly includes global logical clock services, global ID generators, metadata storage, scheduling engines (data/disaster recovery scheduling), and load collection.
The overall architecture of TDSQL Boundless is as shown below:
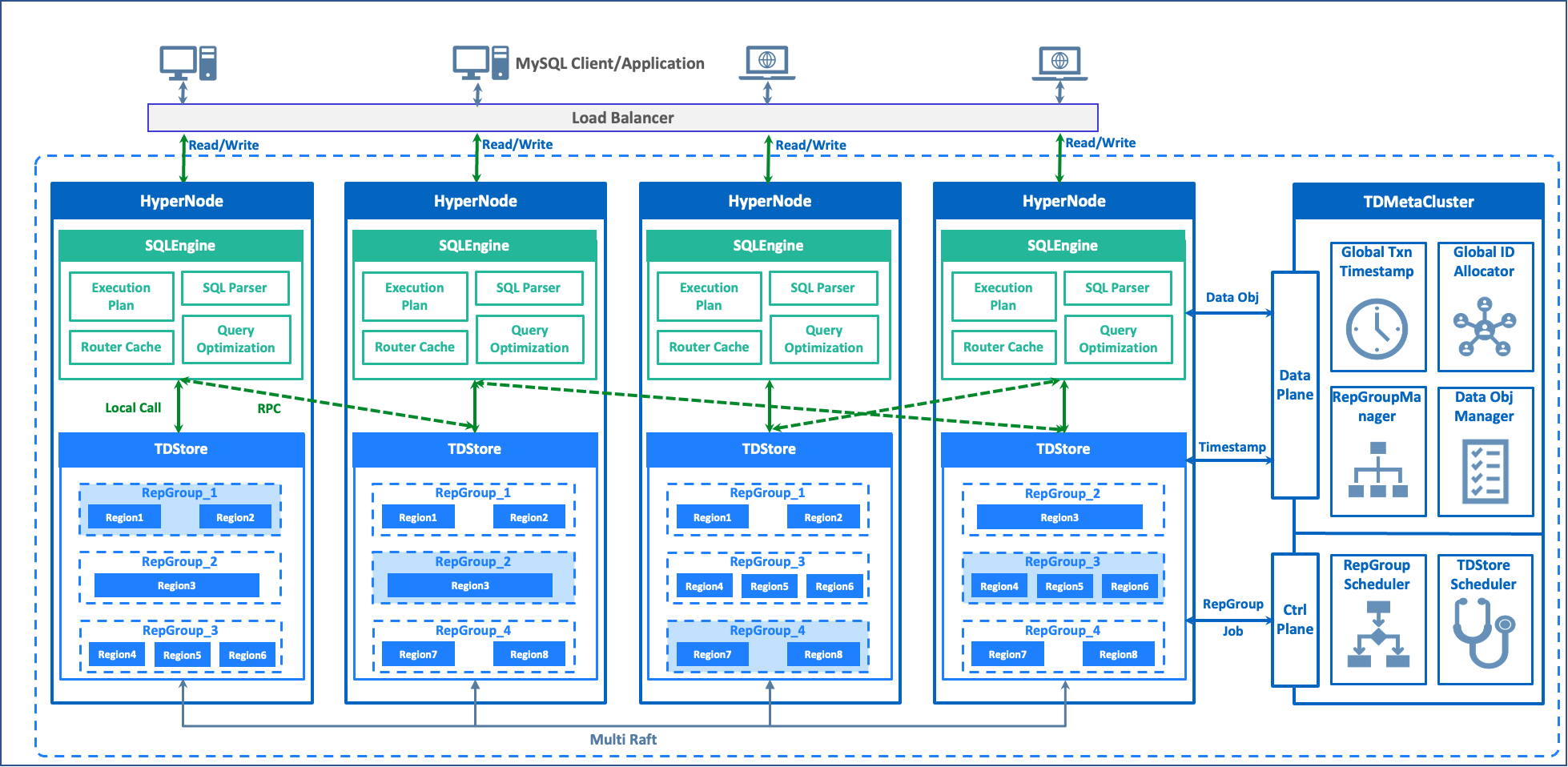
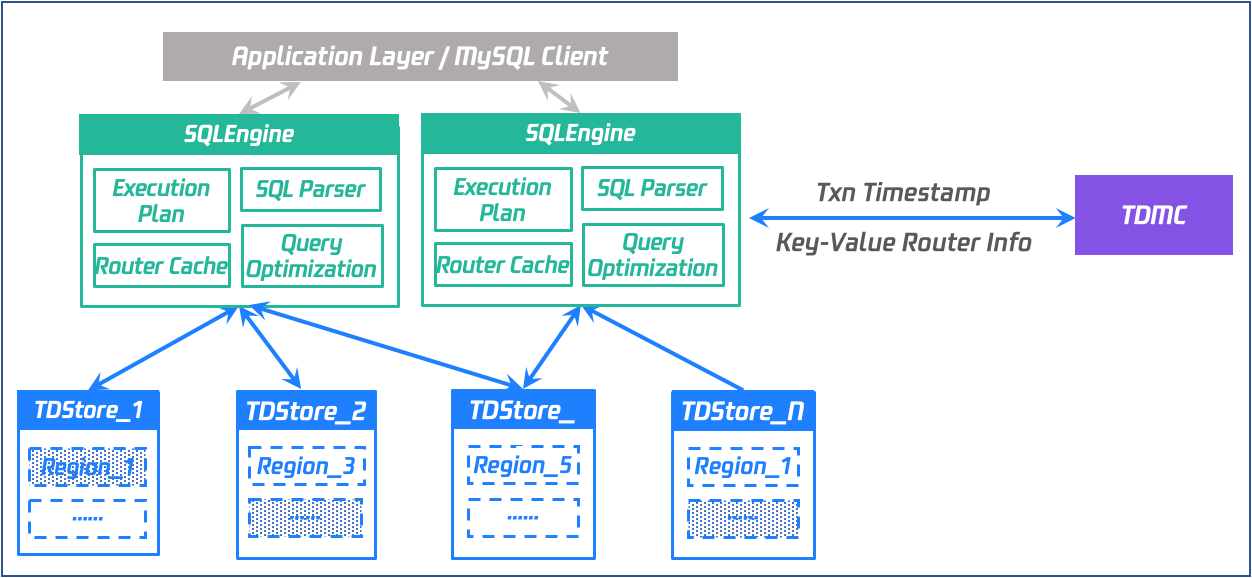
Computing Engine - SQL Engine
Kernel: It is implemented based on MySQL 8.0 and is highly compatible with MySQL.
Architecture: The computing layer adopts a multi-leader architecture with a stateless design. Each SQLEngine node can be read or written.
Interaction: Obtain the global transaction timestamp and data routing information from the control node, interact with the storage node for transactions, and return results to the client.
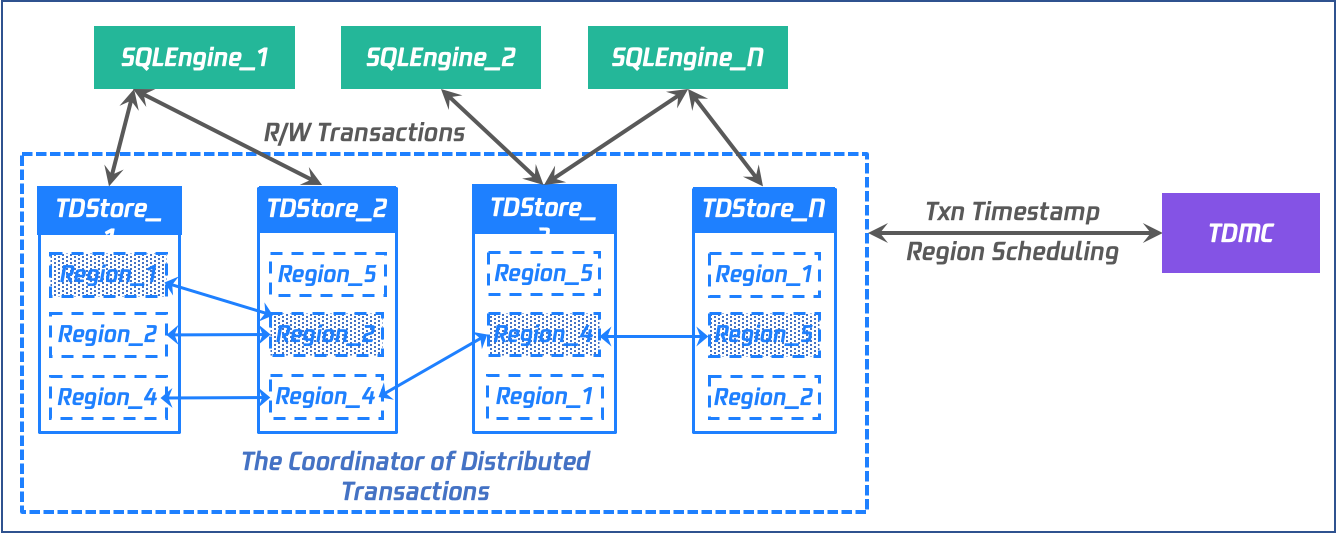
Storage Engine - TDStore
Architecture: Distributed KV storage engine based on LSM-Tree and Multi-Raft.
Data: Multi-replica storage synchronized via Raft, with data distributed across different Regions based on Key ranges. Multiple Regions form a replication group and leverage the Raft consensus protocol for data replication and high availability failover.
Interaction: TDStore receives requests from compute nodes, processes them, and returns results. The primary replica of each region is responsible for receiving and handling read-write requests.
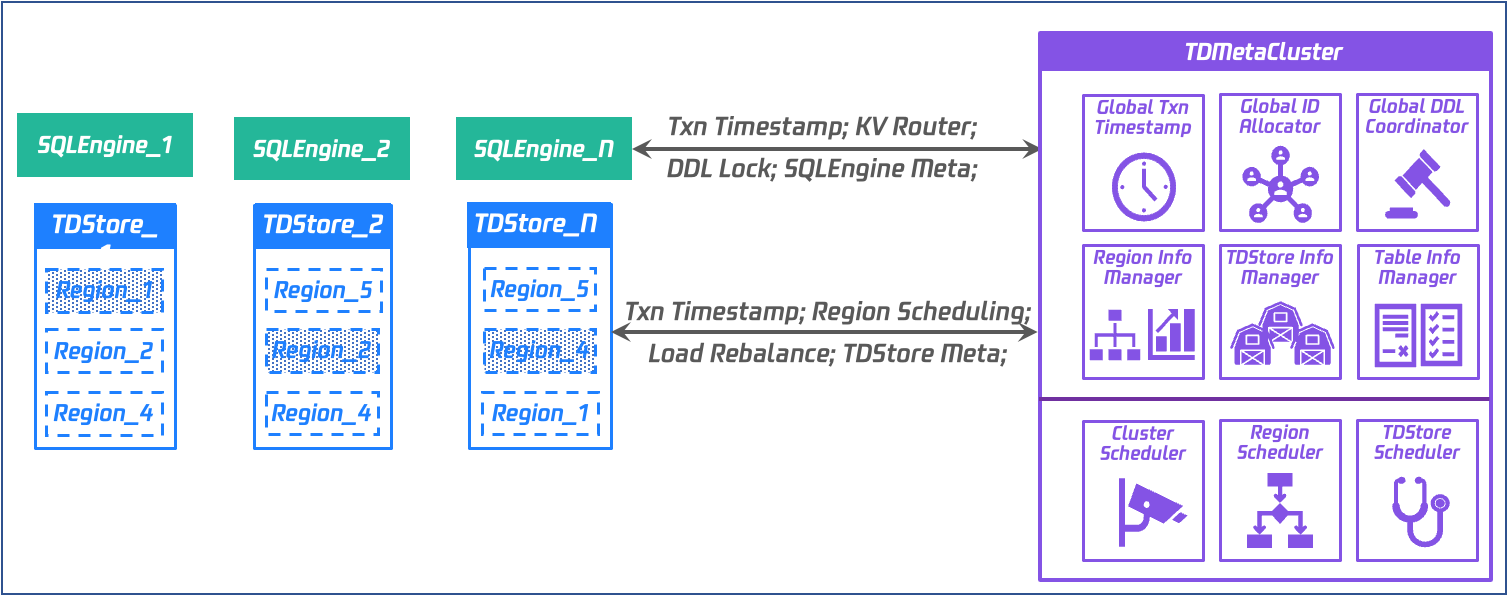
Metadata Service - TDMC
Architecture: Raft-based metadata management cluster with one leader and two followers, with services provided by the leader.
Data:
Assign a globally unique and incremental transaction ID.
Manage TDStore and SQLEngine metadata.
Manage region data routing information.
Manage global MDL locks.
Control:
Schedule the split, merge, migration, and master switch of a replication group.
Schedule the scaling of the storage layer.
Schedule the load balancing of the storage layer.
Issue alarms for abnormal events in various dimensions.
Storage Model
TDSQL Boundless's storage engine will map all users' data to a linear ordered infinite Key space (-∞, +∞), with each line of data corresponding to a certain point in the Key space.
//Examplecreate table t1 (f1 varchar(50),f2 varchar(20),f3 varchar(20),f4 varchar(20),primary key(f1,f2),index idx_f3(f3));insert into t1 values('a', 'b', 'c', 'd');
In the example above, inserting a row of data will occur two key-value pairs:
Primary key: pk_encode('t1', 'a', 'b') -> pk_value_encode('c', 'd').
Index: sk_encode('idx_f3', 'c', 'a', 'b') -> sk_value_encode().
Since the frontmost part of each key is the ID of the database object (table/index/partition table), all data of this database object is continuously distributed in a segment of the key space.
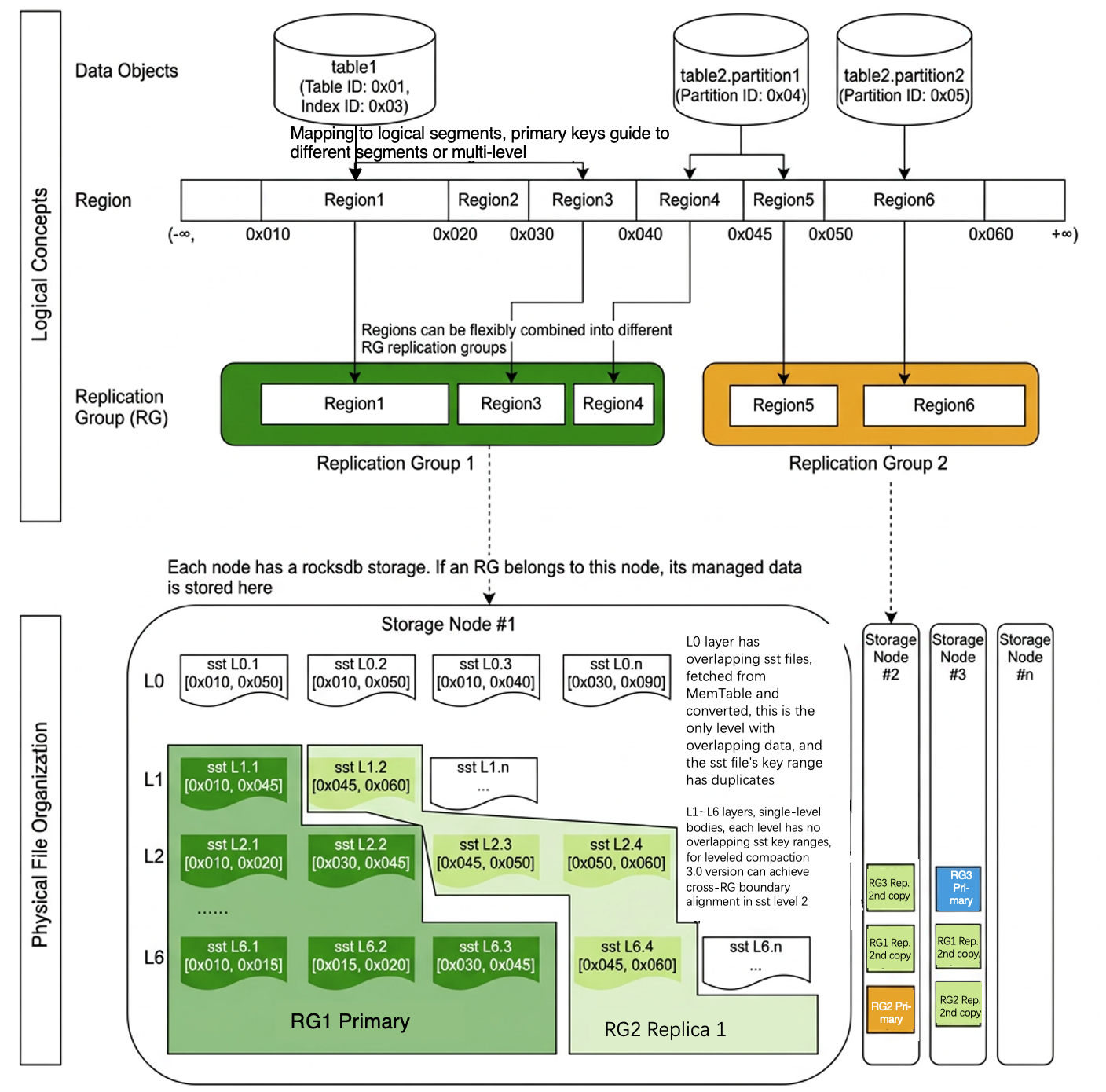
Three-Layer Organizational Mode (DO-Region-RG)
Database object: For example, table, partition, and index. Usually, a globally unique ID (index_id) is assigned for these database objects.
Data shard (region):
①: A consecutive, left-closed and right-open key space (startkey, endkey).
②: A database object corresponds to one or more regions. During operation, a region can be split or multiple regions can be merged into one based on data scheduling policies.
③: Basic unit of data scheduling. Different regions can be distributed on any node in the instance.
④: The region is a logical concept. In the underlying storage, it is not a completely independent segment or file.
Replication group (RG):
①: A replication group can contain one or more regions, and these regions belong to one or more data objects.
②: During operation, RGs can be merged or split (by creating RGs and migrating regions into or out of RGs).
③: A single RG corresponds to a Raft log stream (redo log/WAL). If all keys involved in a transaction are within one RG, the transaction can be converted to a non-distributed transaction. If a transaction involves data across RGs, a two-phase distributed transaction protocol is required.
Peer-to-Peer Architecture Node
In the architecture design of TDSQL Boundless, we aim to keep compute close to storage (cache/storage) while achieving compute-storage separation for high elasticity. Therefore, TDSQL Boundless is designed as follows:
The peer-to-peer architecture (HyperNode) design is adopted. Each peer node (process) contains three complete feature engines: computing, storage, and logging.
The computing layer and local storage use the local access mode, while accessing remote storage uses the network RPC access mode to ensure the performance of accessing local data as much as possible.
Based on the needs of different business scenarios, roles can also be assigned for nodes through metadata and the scheduling module, for example, full-featured nodes (which support all three services: computing, storage, and logging), compute nodes (which only support computing, with all data accessed remotely), storage nodes (which only support data storage), and logging services (which only provide log subscription services).
Note:
The features designated for node roles are not yet available.
피드백