The Lifecycle of an Update SQL
Download
포커스 모드
폰트 크기
To illustrate the key execution steps of a statement in our distributed database, let's trace an UPDATE statement from start to finish:
UPDATE t1 SET b=10 WHERE a=1;. After this statement is processed by the SQL engine's parser and optimizer, it is passed to the executor. The following sections detail the executor's critical steps.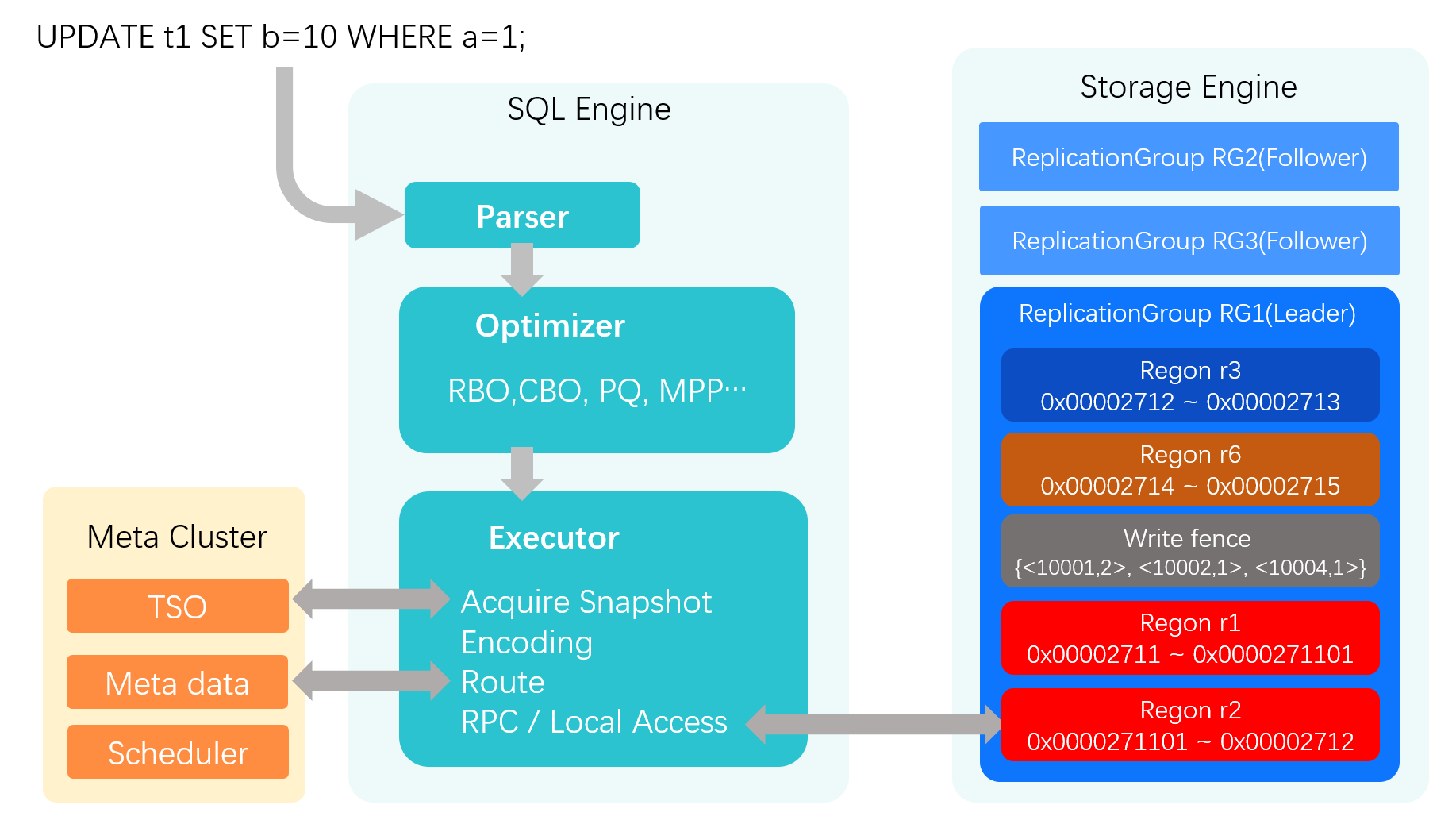
The following details the key steps of the executor.
Acquiring
At the beginning of a transaction, the executor must acquire a global timestamp from the central Metadata Center (MC).This timestamp serves as the transaction's read snapshot and is used for multiversion concurrency control (MVCC) and consistency checks throughout its lifecycle. The MC provides a Hybrid Logical Clock (HLC) timestamp, which combines a physical timestamp with a logical counter.
Data Encoding
The UPDATE operation needs to locate and modify records for both the primary key and any affected secondary indexes. All data is encoded in key-value pairs. For this statement, the key-value pairs would look something like this:
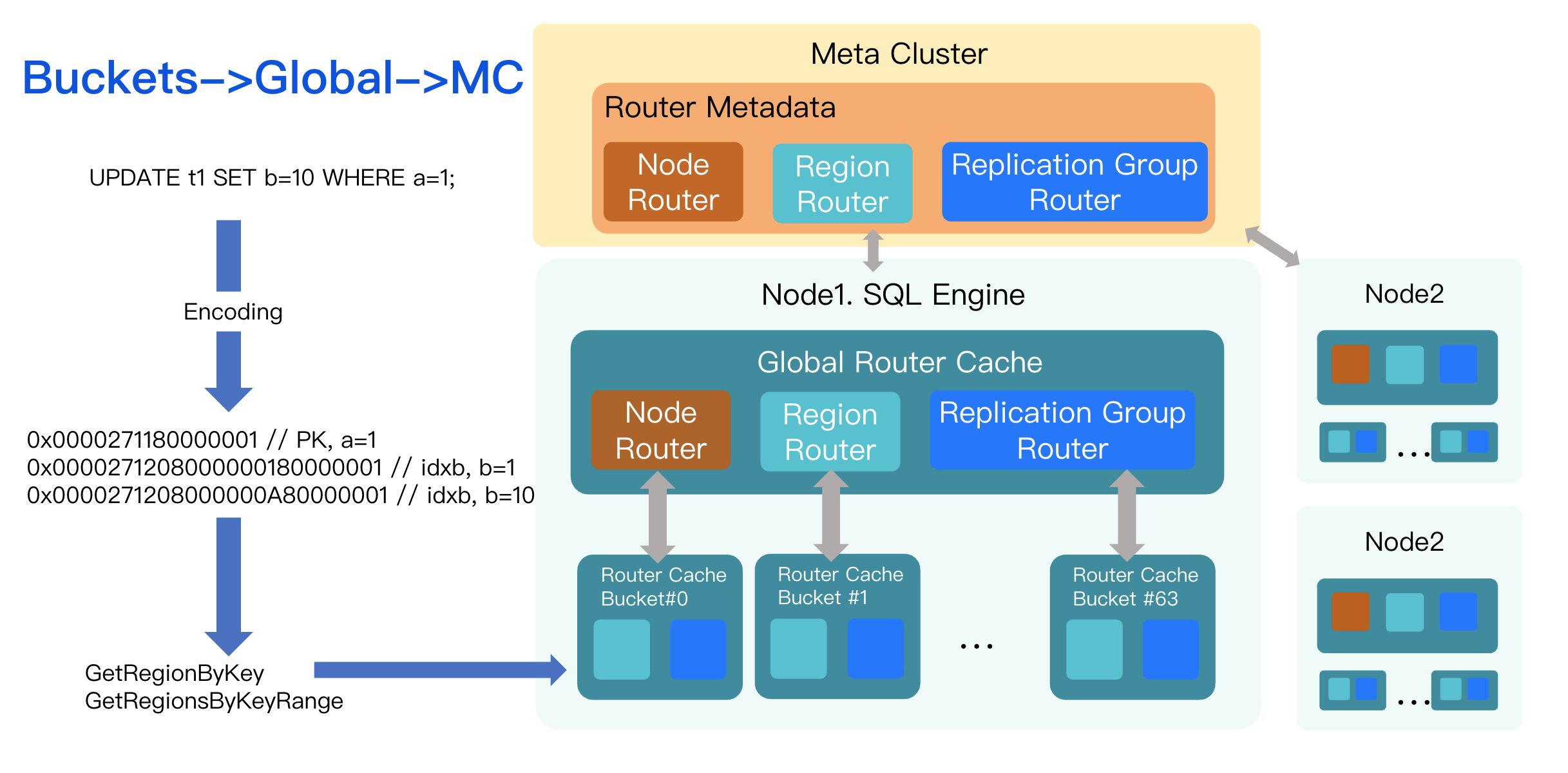
0000271180000001, this key corresponds to the row where the primary key a=10000271208000000180000001: corresponds to the old index entry for b=1 (for the original record where a=1, b=1)0000271208000000A80000001: corresponds to the new index entry for b=10 (for the updated record where a=1, b=10)Routing Cache of the SQLEngine
After encoding the keys, the executor must determine which storage node holds the data for each key. This is the responsibility of the routing layer. In TDSQL Boundless, the Metadata Center (MC) maintains the global routing map, which is essentially a mapping from key ranges to the nodes that store them.
Dynamic Routing
Compared to the architecture for database and table sharding (which only requires determining the location of DB nodes corresponding to shards), the adaptive scheduling architecture for elastic scaling exhibits more complex routing characteristics:
Routing can change dynamically.
Data ranges (Region) can be split or merged.
The size of each Key Range is not fixed.
Two-Level Routing Cache
It would be prohibitively expensive for the SQL engine to issue an RPC to the MC for every key in every statement. To mitigate this, we implement a two-level routing cache within the SQL engine:
Shard-Bucket Cache: A sharded cache where each bucket holds routing information independently.
Global Cache: A single, process-wide cache that serves as a fallback.
The lookup process is as follows:
When SQL is executed, the executor first queries its local shard-level cache.
On a miss or if the route is stale, it checks the process-wide global cache.
If the global cache also misses or has a stale entry, it makes an RPC call to the MC to fetch the latest route.
This tiered design minimizes lock contention and reduces RPC overhead.
Routing Hierarchy
Region Level Router
This is the most common path for data reads and writes (put/get). When data operations such as put or get are performed, the system locates the data shard to which the key belongs based on the key value.
The core data structure is the mapping from key values to regions.
The system employs the upper bound method to determine the region to which the key belongs, thereby locating the specific node.
Replication Group Level Router
Primarily used for retry operations during transaction commit and rollback.
When committing or rolling back a transaction, the system does not need to focus on accessing specific key values. Instead, based on the existing transaction context, it obtains the corresponding routing for the Replication Group to perform retry operations.
Node Router
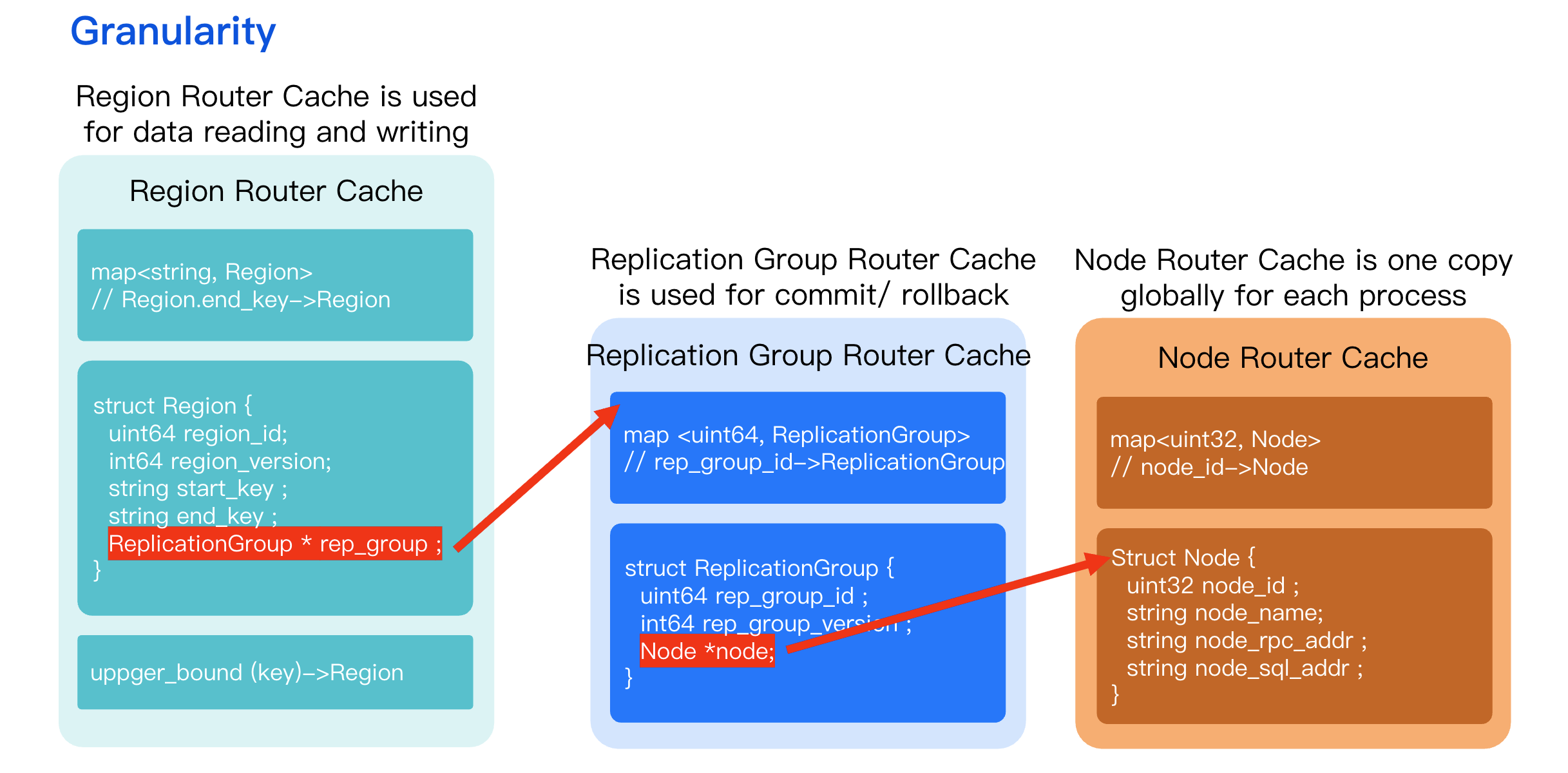
This is a global, mostly read-only map. Node-level changes are infrequent and typically only occur during capacity expansion when new nodes are added to the cluster. Most scheduling operations (like Region splits/merges or leader elections) happen at the Region or Replication Group level.
In the context of elastic scaling, the most common scheduling operations primarily occur at the region level (including splitting and merging of data shards) and the replication group level (such as primary node switchover, which involves migrating the entire replication group and its subordinate regions from node1 to node2). The node granularity remains relatively stable, with new nodes added only when resource bottlenecks are faced that require scaling out.
RPC Execution and Exception Handling
Once the target node for key-value pairs is identified, the executor sends the operation via RPC to the storage engine. The UPDATE statement involves several RPC calls:
Step 1: Fetch the Old Record (GetRecord) by Primary Key
First, we issue a Get operation on the primary key (a=1) to fetch the complete old version of the row. The GetRecord RPC message contains four main parts:
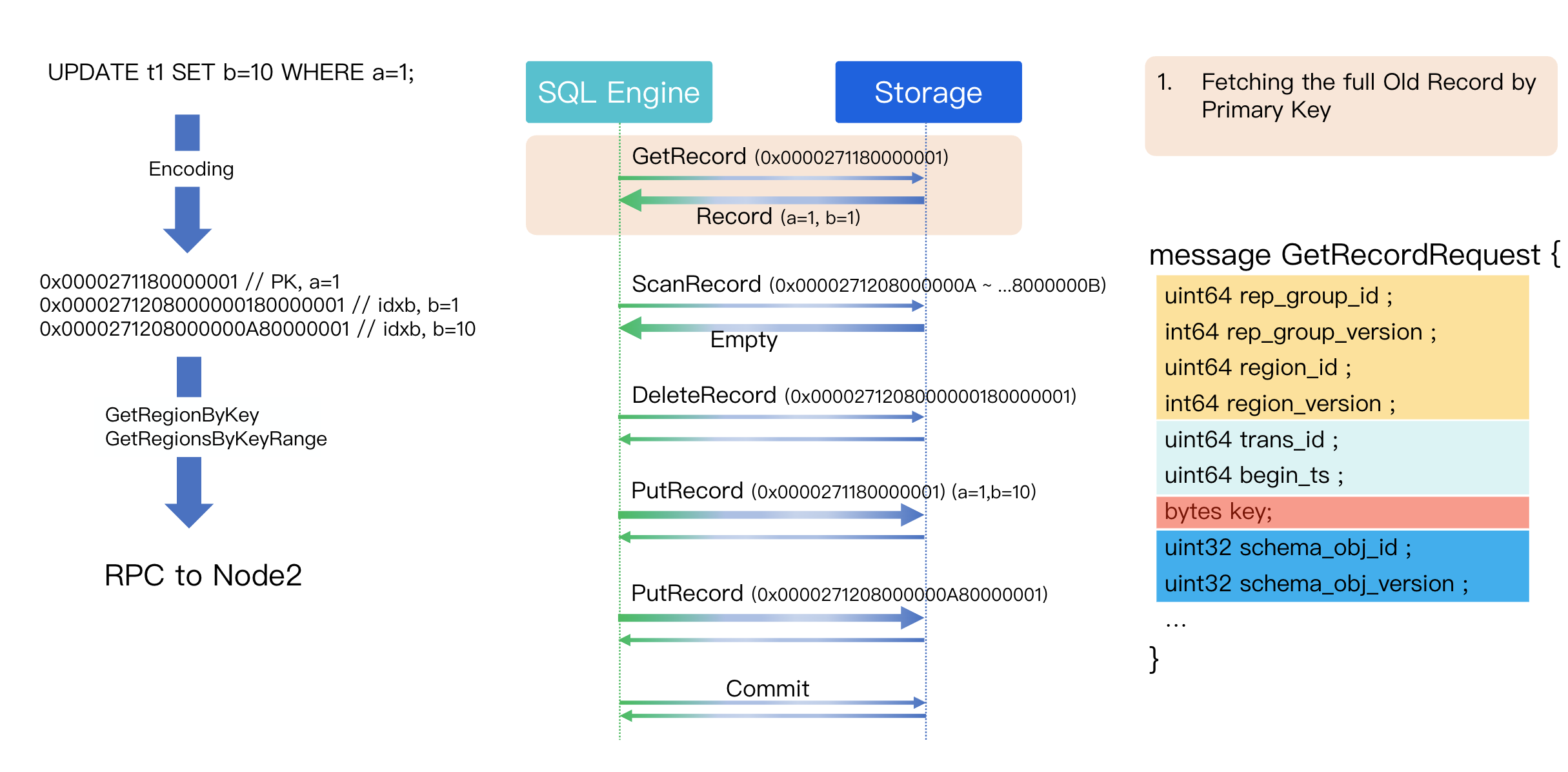
Replication Group (RG) Metadata (Yellow): Contains the Region version to validate the route. If the storage node receives a request with a stale version, it means the client used an outdated route. It rejects the request, forcing the SQL engine to refresh its route from the MC and retry.
Transaction Snapshot Info (Green): The transaction's read timestamp.
Target Key (Red): The key being requested.
Schema Info (Blue): The schema object ID and version, used for DML/DDL concurrency control.
Handling of GetRecord RPC Exceptions
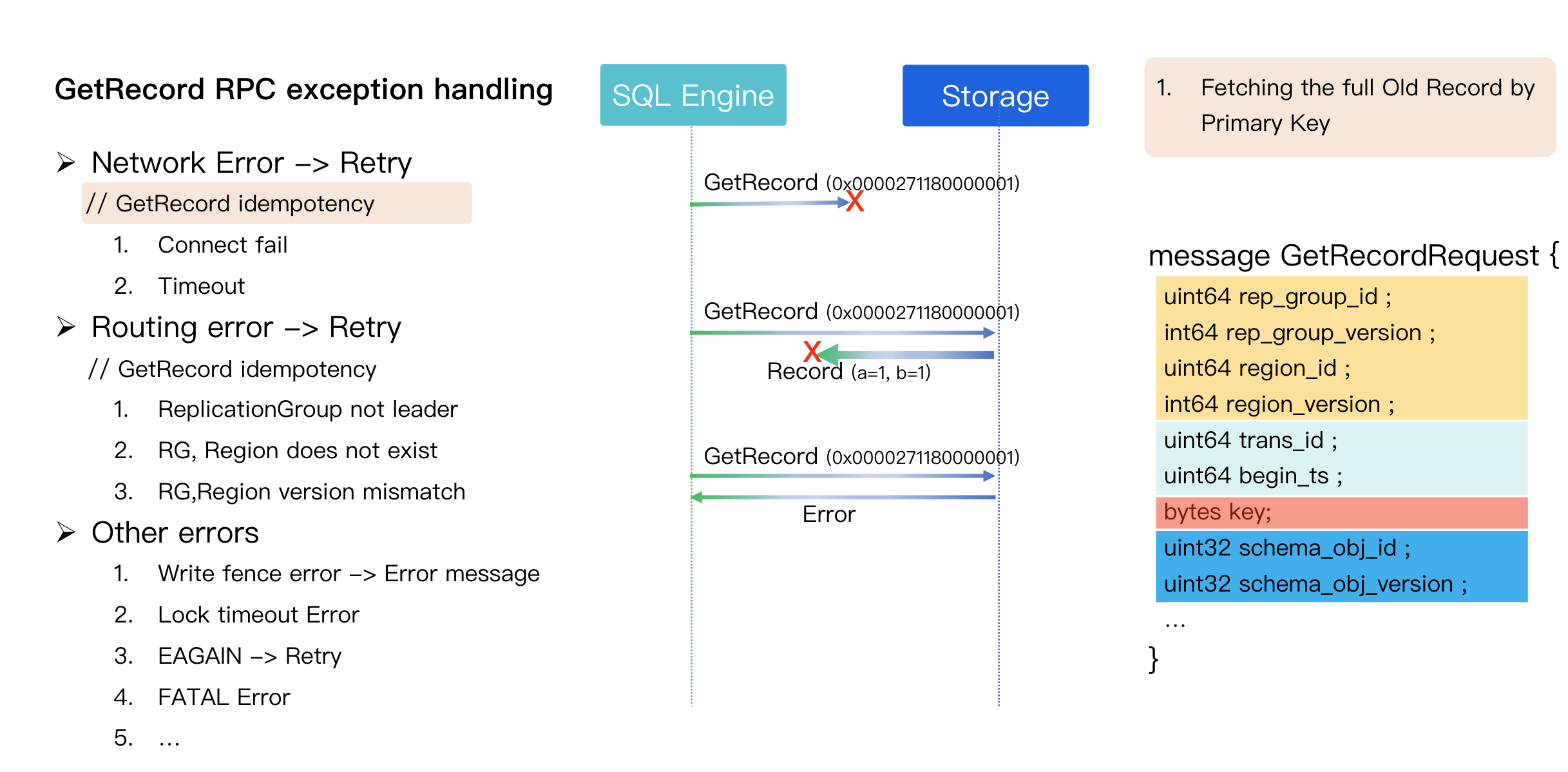
Network Errors (e.g., Timeout, Connection Failure)
Scenario: The SQL Engine (client) knows the RPC failed but cannot distinguish the exact cause (e.g., request never arrived, response was lost, or the storage node was too slow).
Possible Scenarios
The exception in request transmission resulted in a delay, and the storage layer did not receive the GET request.
The storage layer received the request, but the delay of the response packet exceeded the RPC timeout.
The storage layer received the request, but the operation execution took too long and failed to return a response within the timeout.
Resolution: Since GetRecord is a single-point, read-only, and idempotent operation, it can be safely retried.
Routing Errors
Handling method: Refresh the routing cache and resend the GetRecord RPC to the correct new location.
Feature: This RPC is idempotent, thus retries will not cause data errors.
Other Errors
Concurrent DML/DDL errors
Lock timeouts
Internal errors
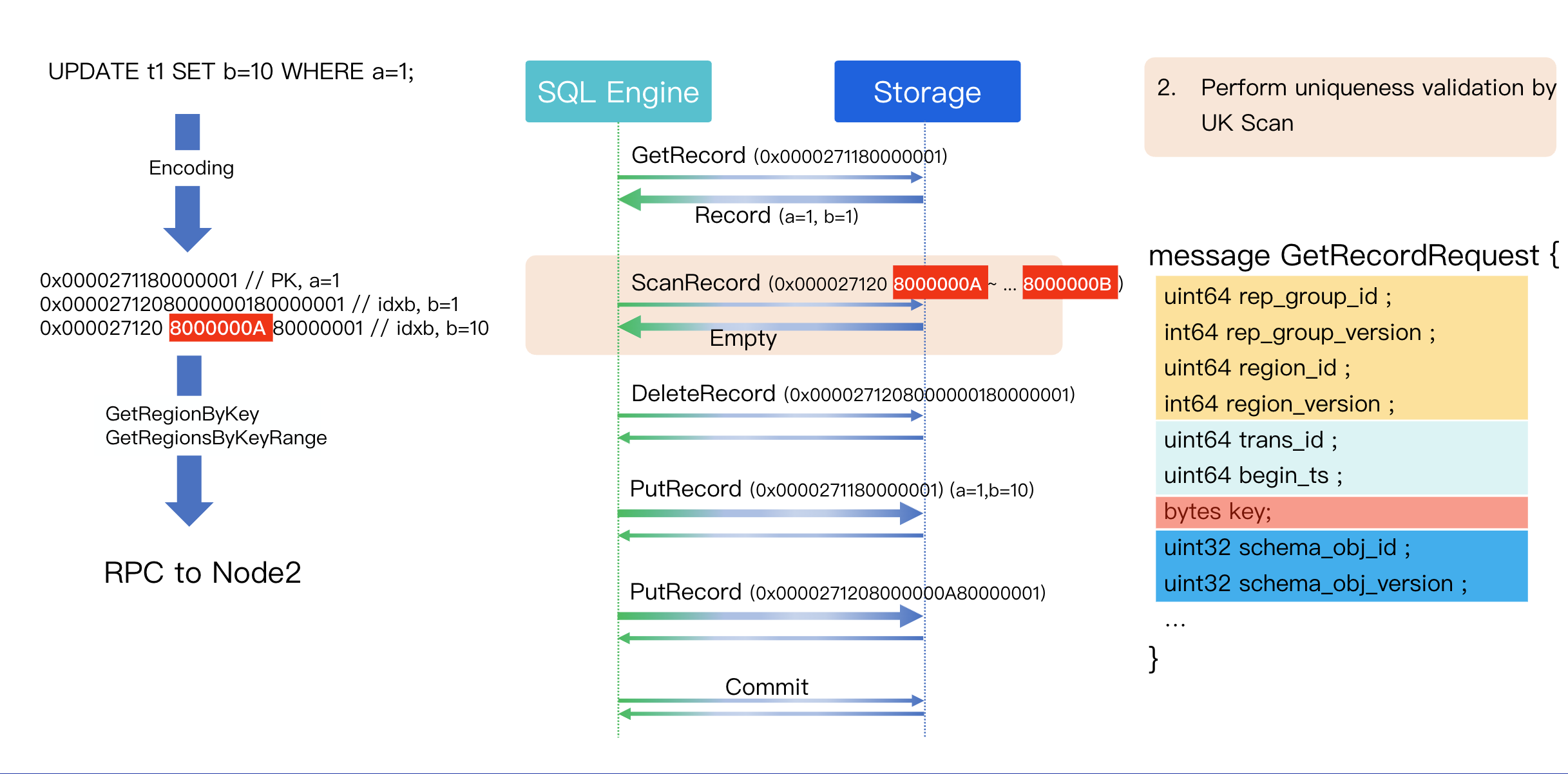
Step 2: Check Uniqueness (UK Scan)
Since column b has a unique index, we must check if a record with b=10 already exists before writing the new value. This is done with a Scan operation.
A Scan RPC is not fully idempotent. When retrying a Scan after a network or routing error, the executor must track the scan's progress (offset) to avoid duplicate results or missing data.
Example: Resumable Scan after a Region Split
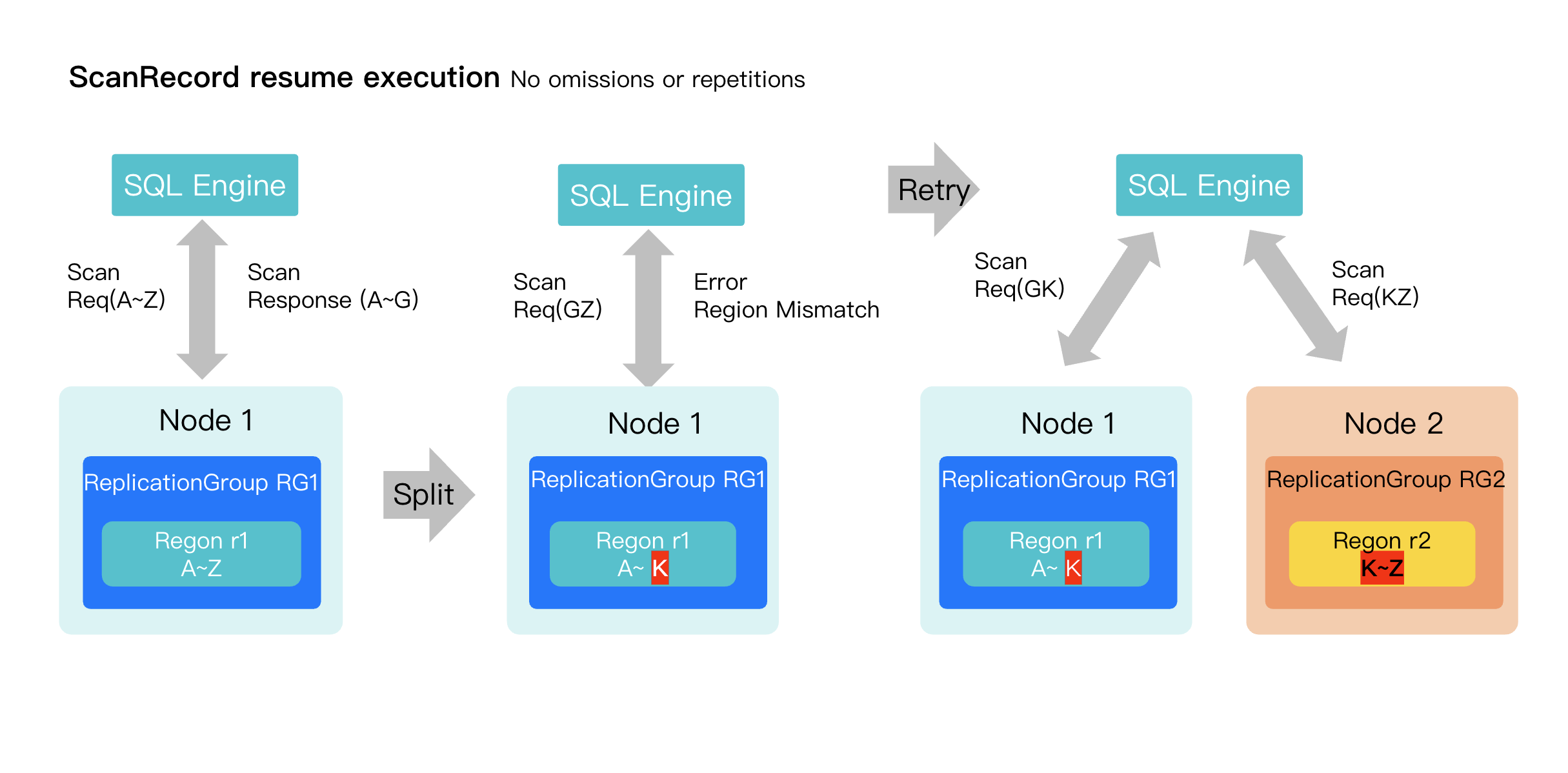
1. Initial Plan: Scan the range from 'A' to 'Z'.
2. First Request: The scan is sent to Replication Group 1(Region r1), which returns data for the range from 'A' to 'G'.
3. Region Split: While the scan is in progress, Replication Group 1(Region r1) splits. It no longer owns the entire 'G' to 'Z' range.
4. Error & Retry
The next request to Region1 for the 'G' to 'Z' range fails with a routing error.
The SQL Engine updates its routing cache.
Discovers the range is now split between Region1 ('G' to 'K') and Region2 ('K' to 'Z').
5. Resuming the Scan
Splitting the request: The executor splits the remaining work, sending a request for 'G'-'K' to Region1 and 'K'-'Z' to Region2.
This ensures the scan is completed without duplicates or omissions.
Step 3: Delete Secondary Index
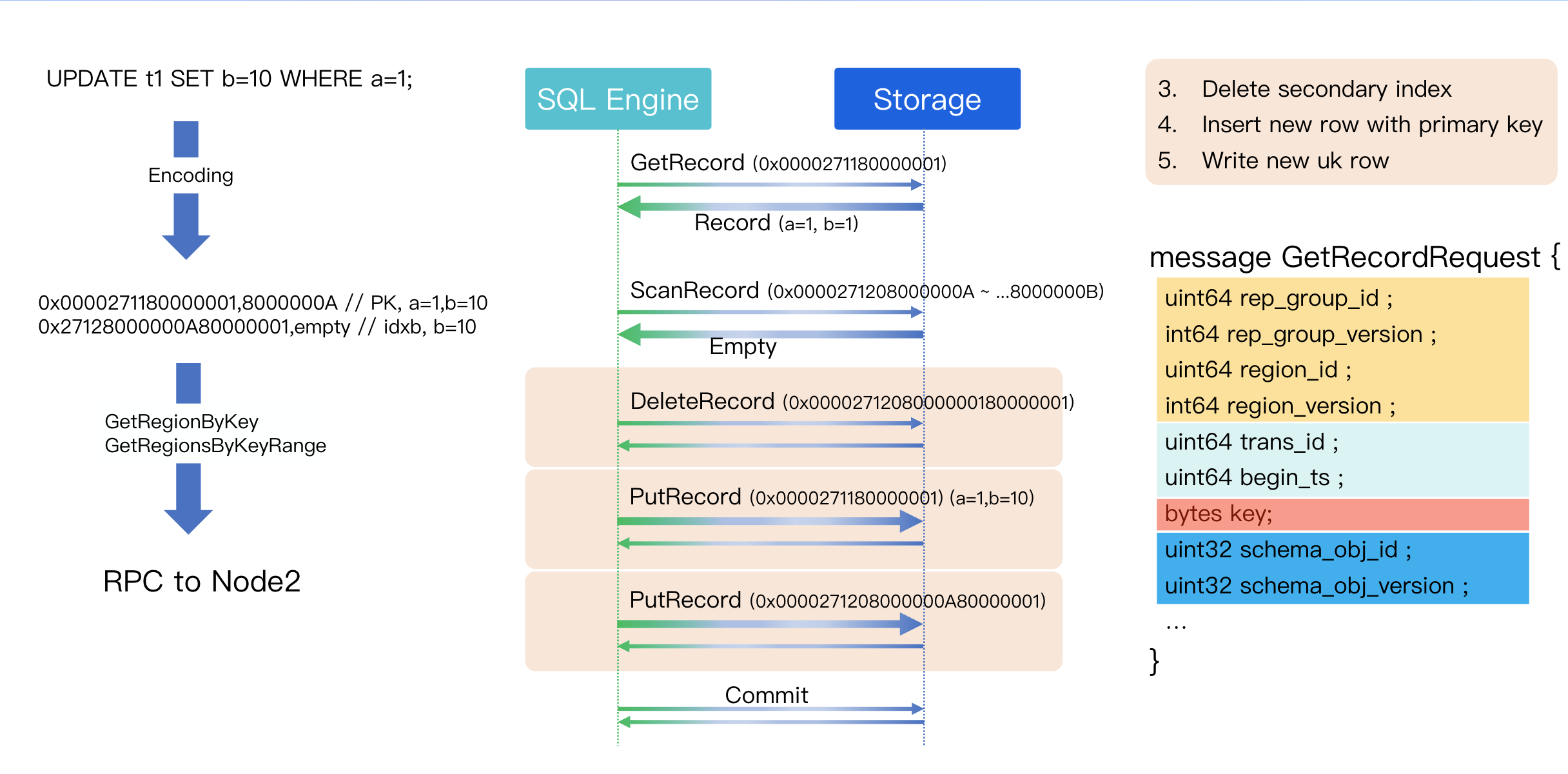
Step 4: Write New Rows with PK, Overwriting Old Rows
Insertion of new records with primary keys.
Step 5: Write New UK Rows
Writing new records to secondary indexes. For the primary key, since the UPDATE SQL did not modify the value of a=1, simply PUTting the new record will overwrite the old row.
During the processing of secondary indexes, DELETE operations are required. Compared to read operations, RPCs for write operations exhibit the following key differences:
Handling Network Errors for Write RPCs:
If a write RPC encounters a network error, the system must terminate the client connection.
To ensure data correctness, it is necessary to prevent retry packets from arriving at the storage layer out of order with the original packets, which could lead to data inconsistency. Although the TCP protocol inherently guarantees in-order data transmission, at the level of network encapsulation or coroutine framework implementation, it is impossible to completely eliminate scenarios where retry packets might be written to the Socket earlier than initially transmitted packets due to factors like coroutine scheduling delays.
Security Assurance:
Handling Approach: Proactively disconnect the client connection upon detecting network errors during write RPC operations.
Effect: After a write RPC connection is interrupted, the entire transaction will not be committed, thereby preventing the generation of erroneous data.
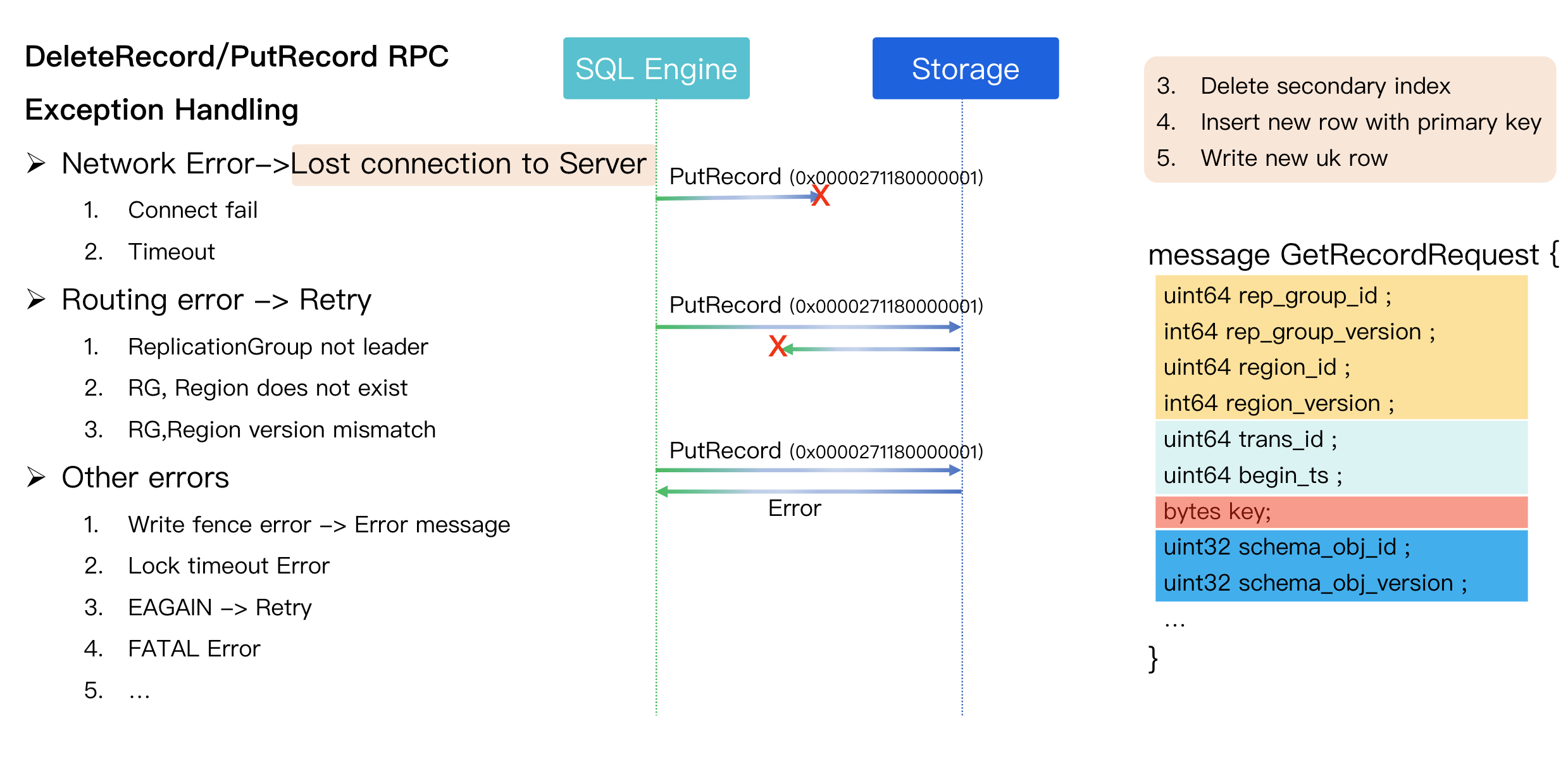
Step 6: Commit
Once all read and write operations are complete, the transaction is committed.:
The commit RPC is simple, typically just containing the transaction ID.
If a network error occurs during the commit RPC, the connection is also terminated.
State Uncertainty: This leaves the client in an uncertain state, similar to when a MySQL process is killed mid-transaction. The client receives a "lost connection" error and does not know if the transaction succeeded or failed. It is then the application's responsibility to verify the outcome.
DML and DDL Concurrency
In a distributed database, preventing concurrent Data Manipulation Language (DML) and Data Definition Language (DDL) operations is crucial. The core problem is that a DDL statement (e.g., ALTER TABLE) puts the table schema into a transient "intermediate state." If a DML operation writes data based on the old schema during this period, the resulting "out-of-sync" data cannot be correctly parsed by either the new or old schema after DDL completion, leading to data corruption.
Therefore, database system must implement a mechanism to ensure strict isolation between DML and DDL operations.
Single-Node Solution: Metadata Lock (MDL)
In a single-node database, this is typically solved with Metadata Locks (MDL). MDL is a lock with coarser granularity than row-level locks, protecting the "metadata" of a table, that is, its schema definition.
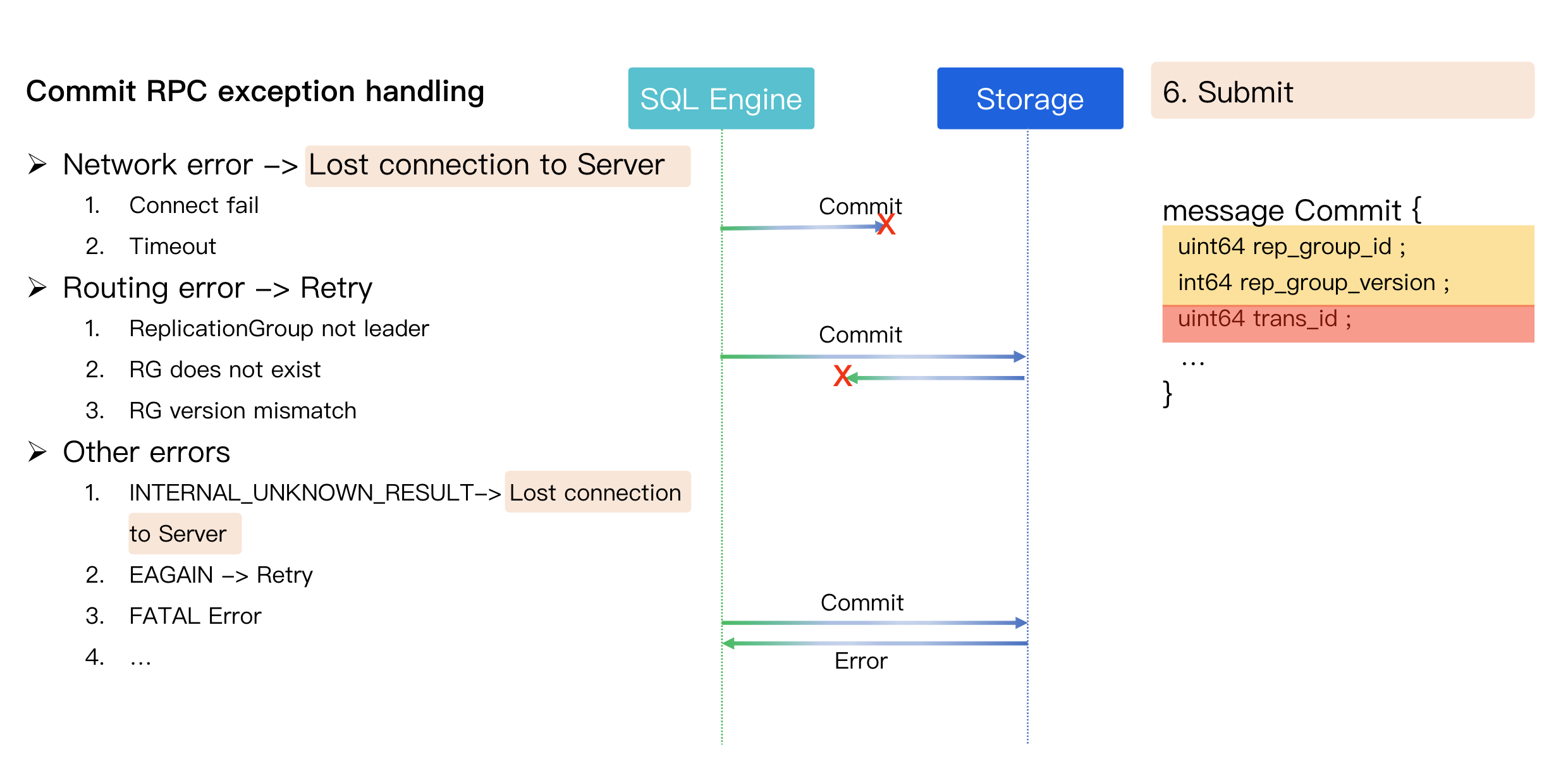
Scenario 1: DML Waits During DDL (RRL runs first)
1. Session1 (DDL) runs first, and with no other active transactions currently present, it successfully acquires the X lock on the table and begins modifying metadata or copying data.
2. At this point, Session2 (DML) attempts to perform read/write operations on the table and needs to obtain an S lock.
3. Since the S lock and X lock are mutually exclusive, Session2 must enter the waiting state until Session1's DDL operation fully completes and releases the X lock.

Scenario 2: DDL Waits During DML (DML runs first)
1. Session2 (DML) starts a transaction first, performs read/write operations, and successfully obtains the S lock on the table.
2. At this point, Session1 (DDL) attempts to modify the table structure and needs to obtain an X lock.
3. Since the X lock and S lock are mutually exclusive, Session1 must enter the waiting state until Session2 commits or rolls back the transaction, releasing all S locks.
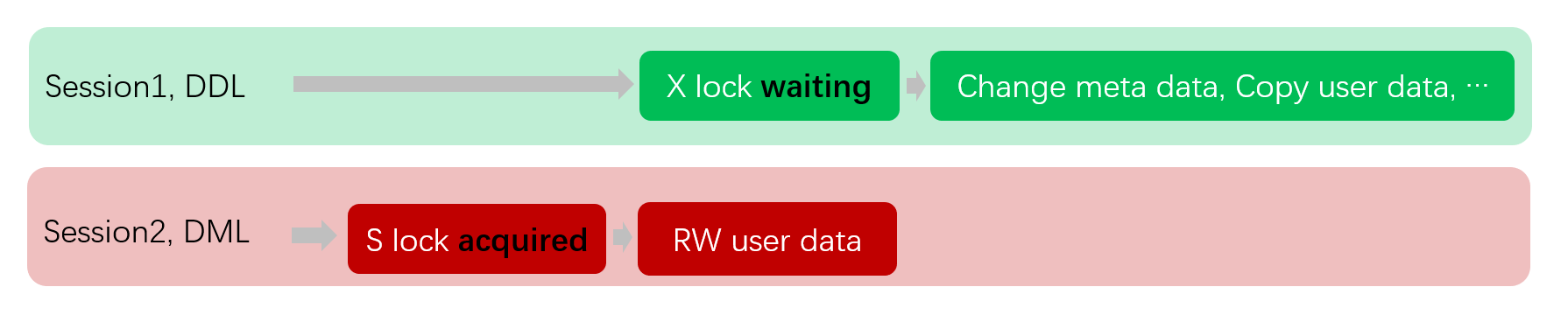
Distributed Solution: Write Fence Mechanism
In a distributed environment, we use a mechanism called the Write Fence to prevent DML from writing data using a stale schema. Process for Distributed Coordination:

1. DML initiation (Node2):
A client connects to Node2 and begins a DML transaction.
Node2 performs the
Open table operation, fetches the table definition (It caches the table's schema, let's call it Schema V1) from the global metadata center, caches it in local memory, and prepares for subsequent data read/write operations.2. DDL concurrent execution (Node1):
Almost simultaneously, another client connects to Node1 and issues a DDL command (such as
ALTER TABLE ADD COLUMN ...).Node1 successfully executed the DDL, updated the table structure to Schema V2, and synchronized the updates to the global metadata center.
3. Conflict occurs (Node2):
Node2 has completed the DML transaction and prepares to write data to the underlying storage via Put/Get RPC calls.
Key conflict point: The data Node2 is about to write is encoded according to the old structure of Schema V1 cached locally. However, the entire system (as defined by the metadata center) now recognizes the table structure as Schema V2.
Table Version and Write Fence
To address the concurrency conflict between DML and DDL, distributed systems introduce a concurrency control mechanism centered around the "table version number" (
schema_version). It functions like a "write fence", effectively preventing DML operations from writing data into obsolete table structures, thereby ensuring data consistency.The core design philosophy is as follows:
Responsibilities of DDL: When operations that modify table structures are performed (such as adding columns, indexes, and so on), the DDL transaction advances the table's
schema_version to a new version and persists it in the (Data Dictionary).Responsibilities of DML: When the
Open table operation is performed, it is required to not only obtain the partition and index information of the table but also simultaneously acquire the corresponding schema_version.The following is a concrete example:
1. Node1 (DML): The client connects to
Node1 and executes a DML. During the Open table phase, it caches the old version number of the table t.schema_version=1.2. Node2 (DDL): Meanwhile, a DDL was successfully executed on
Node2. This operation advances the table version from 1 to 3.3. Node3 (DML):
Open table -> Obtain t.schema_version=3 -> Initiate Put/Get RPC(data, version=3) -> Region Leader verifies 3 == 3 -> OK.4. Node1 (DML): Initiate
Put/Get RPC(data, version=1) -> Region Leader verifies 1 != 3 -> Rejects the request and returns Raise Error.Therefore, the question further translates to: How does DML determine whether the currently held
schema version is stale? 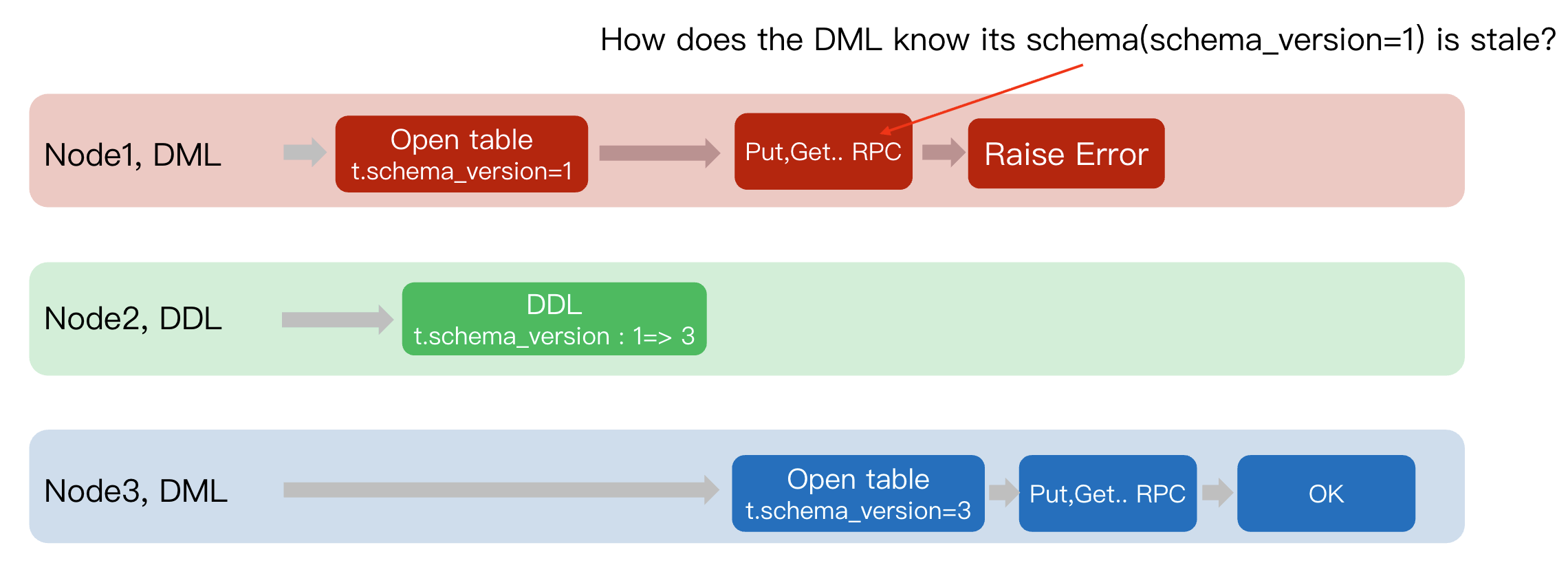
How does the DML know its schema is stale?
Initially, we considered polling the data dictionary to get the latest table schema before every Put/Get. But it is not feasible due to performance overhead and atomicity issues:
Performance Overhead: Each
put or get operation requires an additional RPC to access the Data Dictionary, which significantly increases system latency and reduces throughput.Atomicity Problem: There exists a time window between "querying the latest version" and "executing the write RPC". If the table structure is modified again by DDL during this window, the system still cannot guarantee data consistency.
Instead, we offload version validation to the storage layer to solve issues. The core of this mechanism is the introduction of a structure called "Write Fence" (Write Fence) on storage nodes.
At its core, the Write Fence is durable mapping stored on each storage node that associates each table/index object ID (identified by
schema_obj_id) with its latest version number (schema_obj_version). This forms a <schema_obj_id, schema_obj_version> tuple.When a DDL transaction commits, it must atomically:
1. Update the Data Dictionary: Persist the latest
schema_version (such as updating from 1 to 2) to the Data Dictionary.2. Update the Write Fence: Persist the latest version tuple (such as
<t1: <10001, 2>>) to the Write Fence on storage nodes (Node 1) where all relevant data shards (Regions) reside.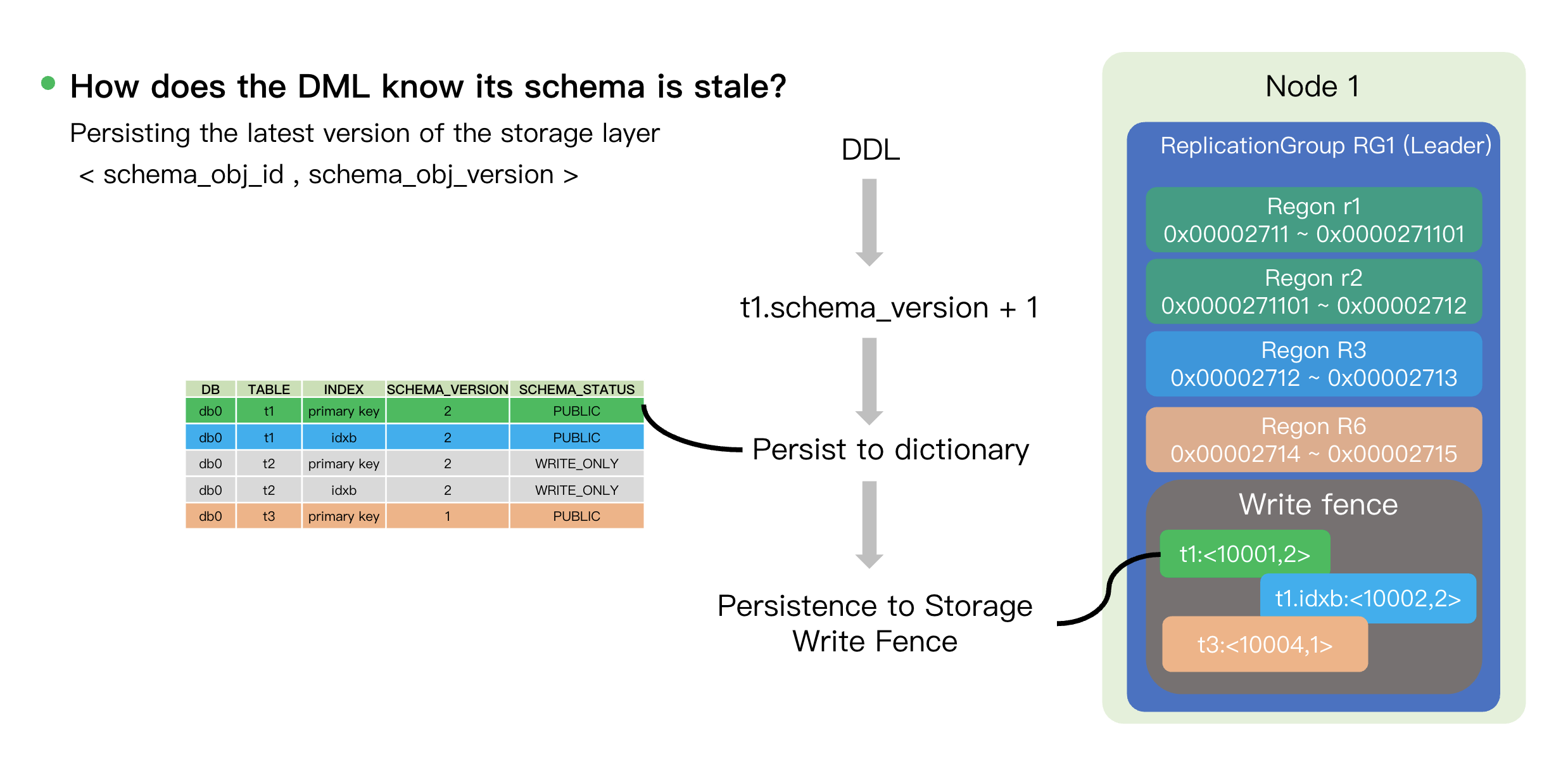
The DML process for execution and validation is as follows:
1. Request Preparation: The DML client obtains the version of the table structure during
Open table, for example, t.schema_version=2.2. RPC Carries Version: When a
Put/Get RPC is initiated, the request body (such as GetRecordRequest) carries the schema_obj_id and schema_obj_version (such as schema_obj_id = 10001 and schema_obj_version = 2).3. Atomic Verification at the Storage Layer: Upon receiving the request, the storage node compares the version tuple
<10001, 2> in the RPC with the tuple stored in its local Write Fence.Match: If the versions match, it indicates that the table schema obtained by the Put request is the latest, and the operation is permitted to execute (
OK).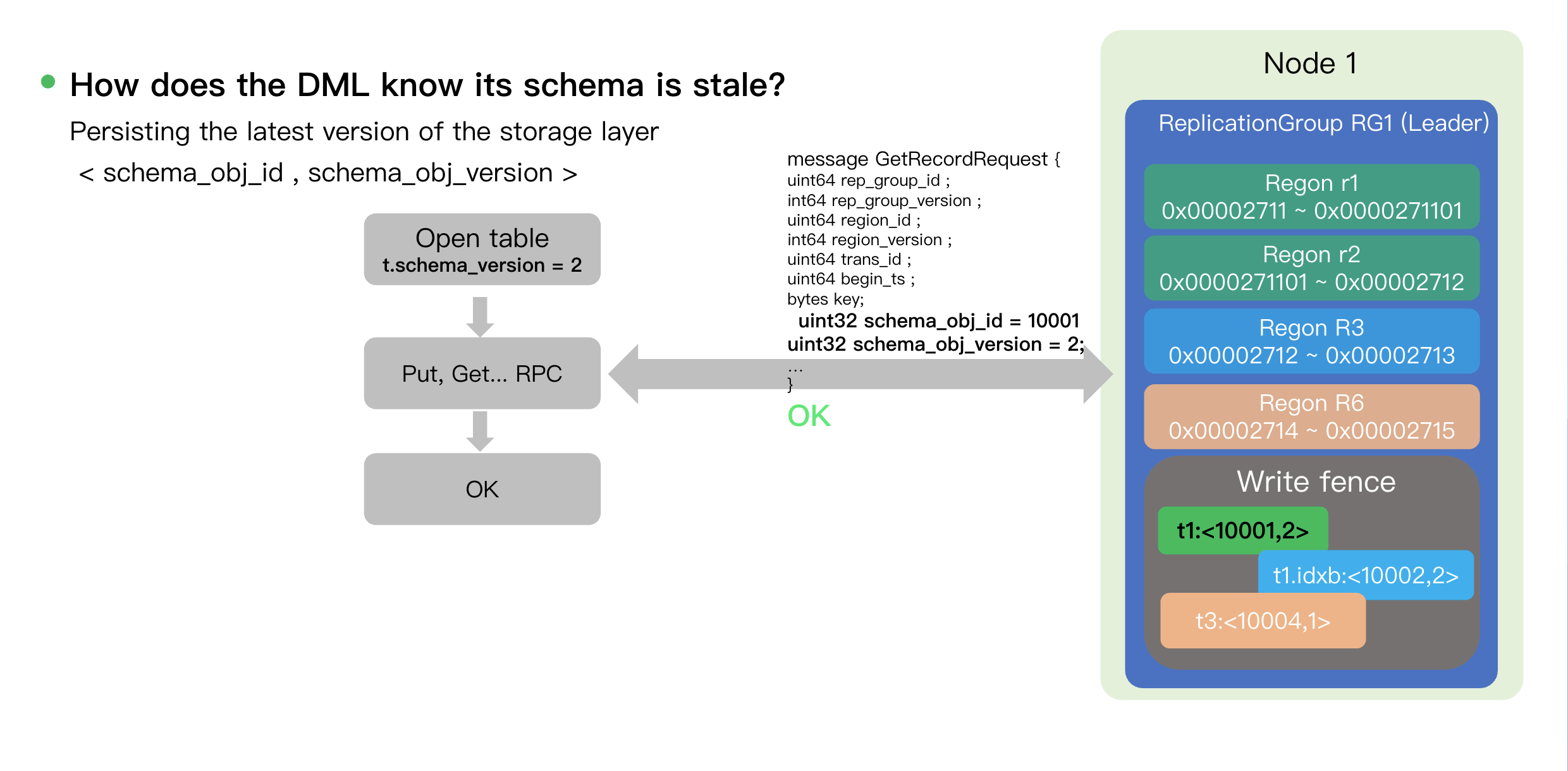
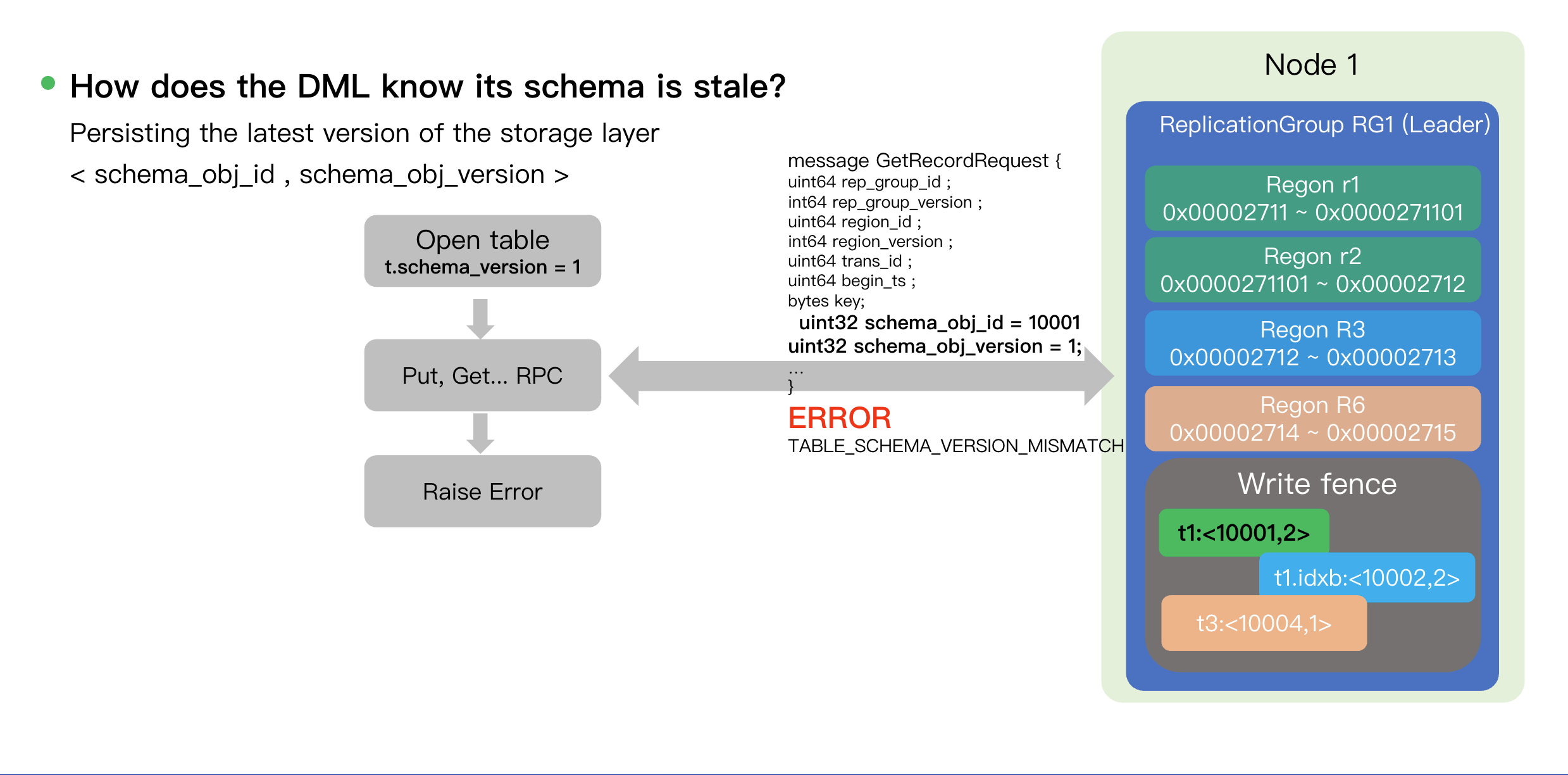
Mismatch: If the Write Fence has a newer version (e.g., the request carries version=1, while the Write Fence contains version=2), the storage node rejects the request. It indicates that the DML holds an outdated table schema. This failure forces the DML transaction to abort and retry, at which point it will fetch the new schema.
피드백