2. 인스턴스 목록 페이지에서 데이터 수집 규칙을 구성할 인스턴스 이름을 선택하여 세부 정보 페이지로 이동합니다.
3. ‘클러스터 모니터링’ 페이지에서 클러스터 오른쪽의 데이터 수집을 클릭하여 수집 구성 목록 페이지로 들어갑니다.
4. 제품화된 페이지에서 기본 메트릭의 대상을 추가하거나 제거할 수 있습니다. 오른쪽에서 ‘메트릭 세부 정보’를 클릭합니다.
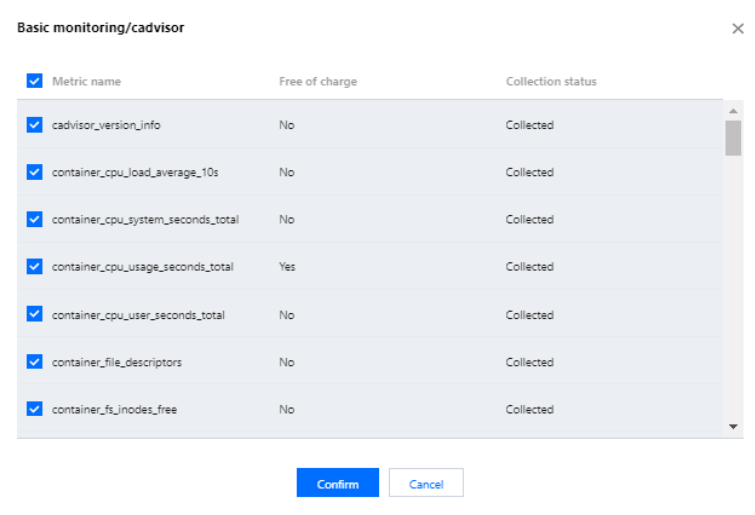
5. 다음은 메트릭이 무료인지 여부를 보여줍니다. 메트릭을 선택하면 해당 메트릭이 수집됩니다. 추가 비용 발생을 방지하려면 유료 메트릭을 선택 해제하는 것이 좋습니다. 기본 모니터링 메트릭만 무료입니다. 무료 메트릭에 대한 자세한 내용은 종량제 무료 메트릭을 참고하십시오. 유료 메트릭에 대한 자세한 내용은 종량제 과금을 참고하십시오.
YAML을 통한 메트릭 간소화
현재 TMP는 모니터링 데이터 포인트 수에 따라 과금됩니다. 필요한 메트릭만 수집하고 불필요한 메트릭은 필터링하도록 수집 구성을 최적화하는 것이 좋습니다. 이렇게 하면 비용이 절감되고 보고되는 전체 데이터 양이 줄어듭니다. 과금 방식 및 클라우드 리소스 사용에 대한 자세한 내용은 문서를 참고하십시오.
다음은 필터링 구성을 ServiceMonitor, PodMonitor 및 RawJob에 추가하여 사용자 지정 메트릭을 간소화하는 방법을 설명합니다.
2. 인스턴스 목록 페이지에서 데이터 수집 규칙을 구성할 인스턴스 이름을 선택하여 세부 정보 페이지로 이동합니다.
3. ‘클러스터 모니터링’ 페이지에서 클러스터 오른쪽의 데이터 수집을 클릭하여 수집 구성 목록 페이지로 들어갑니다.
4. 메트릭 세부 정보를 보려면 인스턴스 오른쪽에 있는 편집을 클릭합니다.
ServiceMonitor 및 PodMonitor
RawJob
ServiceMonitor 및 PodMonitor는 동일한 필터링 필드를 사용하며 이 문서에서는 ServiceMonitor를 예시로 사용합니다.
ServiceMonitor 샘플:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
endpoints:
- bearerTokenSecret:
key:""
interval: 15s # 수집 빈도를 나타냅니다. 이를 늘려 데이터 저장 비용을 줄일 수 있습니다. 예를 들어 덜 중요한 메트릭에 대해 300s로 설정하면 수집되는 모니터링 데이터의 양을 20배까지 줄일 수 있습니다.
port: http-metrics
scrapeTimeout: 15s # 수집 제한 시간을 나타냅니다. TMP 구성에서는 이 값이 수집 간격을 초과하지 않도록 요구합니다(예: scrapeTimeout <= interval).
jobLabel: app.kubernetes.io/name
namespaceSelector:{}
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
kube_node_info 및 kube_node_role 메트릭을 수집하려면 ServiceMonitor의 endpoints 목록에 metricRelabelings 필드를 추가해야 합니다. 주의: **metricRelabelings**이며 relabelings는 아닙니다.
metricRelabelings 추가 샘플:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
endpoints:
- bearerTokenSecret:
key:""
interval: 15s # 수집 빈도를 나타냅니다. 이를 늘려 데이터 저장 비용을 줄일 수 있습니다. 예를 들어 덜 중요한 메트릭에 대해 300s로 설정하면 수집되는 모니터링 데이터의 양을 20배까지 줄일 수 있습니다.
port: http-metrics
scrapeTimeout: 15s
# 다음 네 줄이 추가됩니다.
metricRelabelings:# 수집된 각 항목은 다음과 같이 처리됩니다
-sourceLabels:["__name__"]# 점검할 label의 이름. __name__은 메트릭의 이름 또는 항목과 함께 제공되는 label을 나타냅니다.
regex: kube_node_info|kube_node_role # 상기 label이 이 정규식을 충족하는지 여부. 여기서 __name__은 kube_node_info 또는 kube_node_role의 요구 사항을 충족해야 합니다.
action: keep # 상기 조건을 만족하면 항목을 유지하고 그렇지 않으면 드롭합니다.
jobLabel: app.kubernetes.io/name
namespaceSelector:{}
selector:
Prometheus의 RawJob을 사용하는 경우 다음 방법을 참고하여 메트릭 필터링을 진행합니다.
Job 샘플:
scrape_configs:
-job_name: job1
scrape_interval: 15s # 수집 빈도를 나타냅니다. 이를 늘려 데이터 저장 비용을 줄일 수 있습니다. 예를 들어 덜 중요한 메트릭에 대해 300s로 설정하면 수집되는 모니터링 데이터의 양을 20배까지 줄일 수 있습니다.
static_configs:
- targets:
-'1.1.1.1'
kube_node_info 및 kube_node_role 메트릭만 수집하려면 metric_relabel_configs 필드를 추가합니다. 주의: **metric_relabel_configs**이며 relabel_configs는 아닙니다.
metric_relabel_configs 추가 샘플:
scrape_configs:
-job_name: job1
scrape_interval: 15s # 수집 빈도를 나타냅니다. 이를 늘려 데이터 저장 비용을 줄일 수 있습니다. 예를 들어 덜 중요한 메트릭에 대해 300s로 설정하면 수집되는 모니터링 데이터의 양을 20배까지 줄일 수 있습니다.
static_configs:
- targets:
-'1.1.1.1'
# 다음 네 줄이 추가됩니다.
metric_relabel_configs:# 수집된 각 항목은 다음과 같이 처리됩니다
-source_labels:["__name__"]# 점검할 label의 이름. __name__은 메트릭의 이름 또는 항목과 함께 제공되는 label을 나타냅니다.
regex: kube_node_info|kube_node_role # 상기 label이 이 정규식을 충족하는지 여부. 여기서 __name__은 kube_node_info 또는 kube_node_role의 요구 사항을 충족해야 합니다.
action: keep # 상기 조건을 만족하면 항목을 유지하고 그렇지 않으면 드롭합니다.
5. 확인을 클릭합니다.
수집 대상 차단
네임스페이스 전체 모니터링 차단
TMP는 클러스터가 연결된 후 기본적으로 클러스터의 모든 ServiceMonitor 및 PodMonitor 리소스를 모니터링합니다. 네임스페이스의 모니터링을 차단하려면 지정된 네임스페이스에 tps-skip-monitor: "true" label을 추가합니다. label 관련 작업은 다음을 참고하십시오.
일부 대상 차단
TMP는 클러스터에서 ServiceMonitor 및 PodMonitor 유형의 CRD 리소스를 생성하여 모니터링 데이터를 수집합니다. 지정된 ServiceMonitor 및 PodMonitor 리소스의 수집을 차단하려는 경우 CRD 리소스에 tps-skip-monitor: "true" labe를 추가합니다. label 관련 작업은 다음을 참고하십시오.