HDFS 联邦管理开发指南
Download
聚焦模式
字号
HDFS 联邦管理类型选择
注意
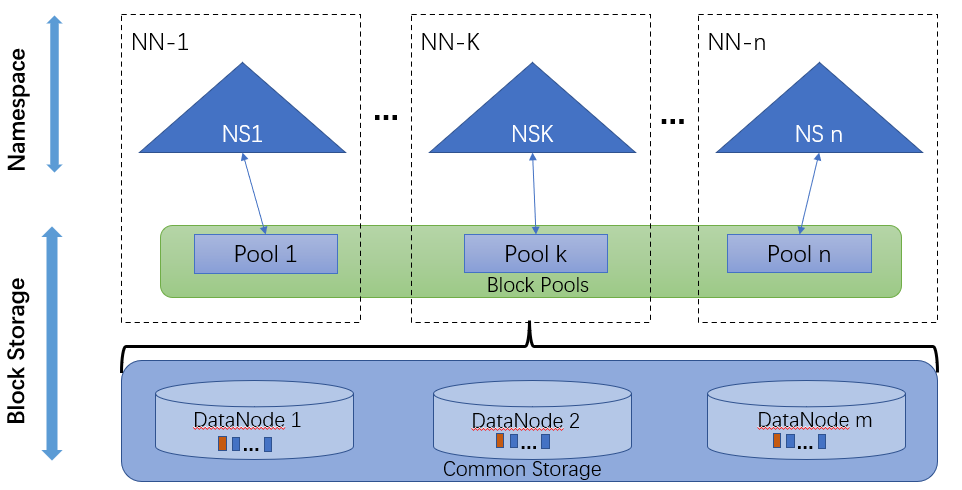
HDFS 联邦管理架构
HDFS Federation(联邦)使用多个独立的 NameNode/Namespace 来使 HDFS 的命名服务能够水平扩展,联邦中的 DataNode 被所有的 NameNode 用作公共存储块的地方;每一个 DataNode 都会向所在集群中所有的 NameNode 注册,并且会周期性地发送心跳和块信息报告,同时处理来自所有 NameNode 的指令。
ViewFs Federation 原理
为了方便管理多个命名空间,HDFS ViewFs Federation 采用了经典的 Client Side Mount Table(社区 ViewFs 功能)。通过客户端侧将应用的不同路径映射到具体的 NameService 上,从而达成存储分离或者性能分离的场景。HDFS ViewFs Federation 采用 Client-Side Mount Table 分摊文件和负载,该方法更多的需要人工介入(明确的规划)以达到理想的负载均衡。
Router-based Federation 原理
Router-based Federation 提供了一个软件层来管理多个 NameSpace 空间。相较于 ViewFs 通过在客户端维护挂载表信息,Router-based Federation 是真正做到了对客户端的完全透明。因为这部分映射信息将会被额外的保存下来,还会持久化下来。
HDFS 联邦管理配置
主要是要考虑两个方面:所需的 NameService 数量,业务数据目录挂载方式。
NameService 数量的规划原则
1. 单 NameService 的安全存储容量上限为1亿文件,如果超过该数量,该 NameService 的访问速度、读写吞吐量都会严重降低。所以,如果文件存储量(预计)超过1亿文件,则需要新增 NameService。
2. 对于 HDFS 的重度使用(即大量读写 HDFS 中文件)应用,有必要单独划分一个 NameService 来处理其请求,以保证该应用的数据可以独占该 NameService 的所有处理能力,也避免了该应用对其他应用的影响。
3.对于可靠性要求严苛的应用,可以划分一个 NameService,以免其他应用的过高的读写频率导致该应用无法访问 HDFS,造成该应用业务的不稳定。
业务数据目录挂载方式的规划原则
1. 业务数据相关联的服务的数据目录,尽量挂载在同一 NameService 下面。否则,跨 NameService 的文件读写速率较慢,会降低应用的文件存储性能。
2. 数据量大,且对其他服务的业务无关联的,可以直接使用一个 NameService。
3. 对业务量较小的业务,建议直接将其目录挂载在默认的 NameService(HDFS${clusterid},HDFS 拼接数字形式 clusterid)中,这样就不用做数据迁移,可以降低配置为 Federation 的复杂性。
4. 建议只对全局一级目录进行 NameService 映射以减少配置复杂度。
方案比较
ViewFs Federation 类型
1. 直接使用 ViewFs
优点:统一视图,不同的应用有相同的使用方式。
缺点:ViewFs 挂载表的变更需要所有使用集群的应用同步读取最新的挂载点。
2. 指定 NameService
优先:不需要同步更改所有应用的配置。
缺点:不同组件和应用需要明确各自的使用目录,组件路径之间耦合的场景将复杂化。
Router-based Federation 类型配置方式
1. 直接使用 Router-based Federation
优点:统一视图,不同的应用有相同的使用方式。与 ViewFs 相比,Router-based Federation 挂载表的变更直接生效,不需要使用集群的应用同步更新挂载表。
缺点:客户端访问时,增加 DFSRouter 转发层,对性能略有影响。
2. 指定 NameService
优先:不需要同步更改所有应用的配置。
缺点:不同组件和应用需要明确各自的使用目录,组件路径之间耦合的场景将复杂化。
文档反馈