查看调度历史
Download
聚焦模式
字号
功能介绍
调度历史可查看资源队列配置的操作记录、任务状态等信息。
操作步骤
1. 登录 EMR 控制台,在集群列表中选择对应的 Hadoop 集群单击详情进入集群详情页。
2. 在集群详情页中选择集群服务 > Yarn 组件卡页右上角操作 > 资源调度进入资源调度页面。
3. 在资源调度页中单击调度历史,可查看任务开始时间、结束时间、状态以及操作信息等。
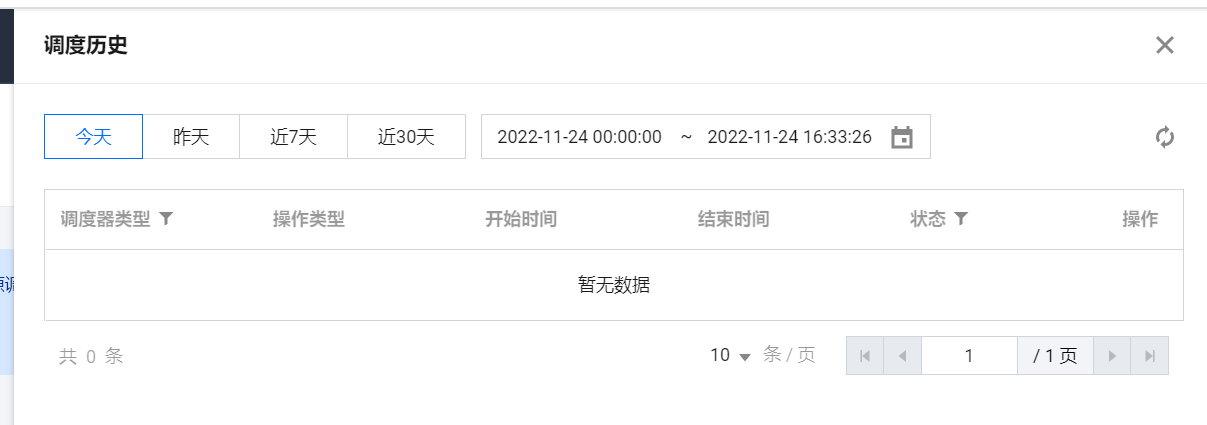
4. 可按执行时间段筛选调度记录,在操作类型下单击详情可查看详细信息。
文档反馈