本文介绍并行查询功能的实现原理。
并行原理
TDSQL-C MySQL 版推出并行查询(Parallel Query)能力,将完整数据分区下推到不同的线程上,利用多个线程进行并行计算,并将结果汇总到用户线程上,并返回给用户,提升查询效率。
下面用一个简单的例子介绍并行查询的基本原理。
说明:
MySQL/InnoDB 物理存储为段页式,分区单位为页,这里用行演示分区的概念。
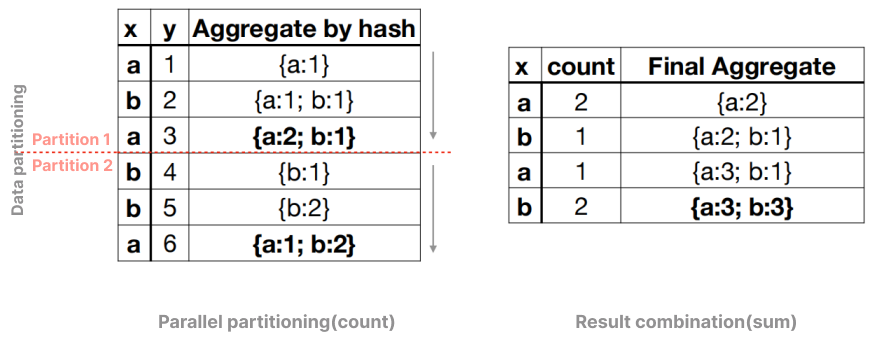
给定一个表 t 和如下分组聚合查询。
select x, count(*) from t group by x;
哈希聚合算法(迭代求值)过程如下表所示。算法迭代每一行,更新分组聚合状态。当所有数据行迭代结束时,就得到了分组聚合结果。假设聚合状态更新操作是恒定的,那么算法时间复杂度是 O(n) 的。
如果用 k 个线程来加速这个查询(这里 k = 2),那么最好先将数据表划分成 k * p 个分区(这里 p = 1)。这样,每个线程可以处理 p 个分区,产生一个局部结果。显然,这些局部结果并不是最终结果,还需要进行合并处理。合并操作需要放在同一个用户线程里执行,才能获得正确的最终结果。
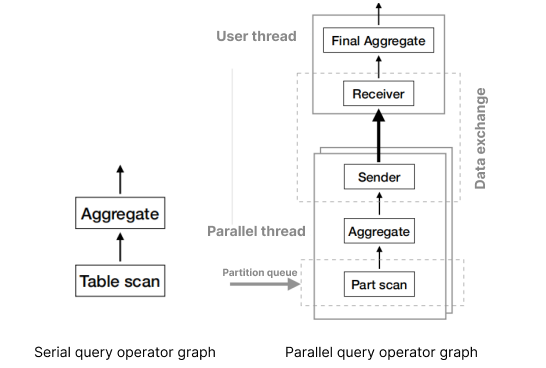
由上述示例我们可以将串行查询模式与并行查询模式的运算用算子图表示为:
通过算子图可看到,在并行查询中数据会根据并行度,被拆分为数个不重叠的分区,这一过程被称为数据分区。 在数据分区完成后,原始计划中的特殊运算也会进行拆分,此过程为任务拆分。全部拆分完成后数据会被多个工作线程(并行线程)扫描并执行,工作线程会将各部分结果通过数据交换算子聚集到用户线程,这一过程依赖于数据交换。
数据交换完成后,由用户线程完成聚集操作,汇总结果,将完整结果输出。其中,用户线程负责数据分区和任务分拆,同时充当协调者角色(也称为协调线程),协调多个工作线程并行地执行子任务。用户线程还负责合并最终结果,返回给用户。工作线程执行并行子任务,并通过数据通道交换中间结果。
那么,可以总结并行查询的几个核心要素为:
数据分区:将原始表数据划分成不重叠的分区,并支持按分区读数据。
任务拆分:将原始计划中的特殊运算拆分成“局部-整体”两段运算,除此之外,还要插入数据交换算子,支持跨线程数据传递。
数据交换:支持在不同线程间传递数据。
并行流程
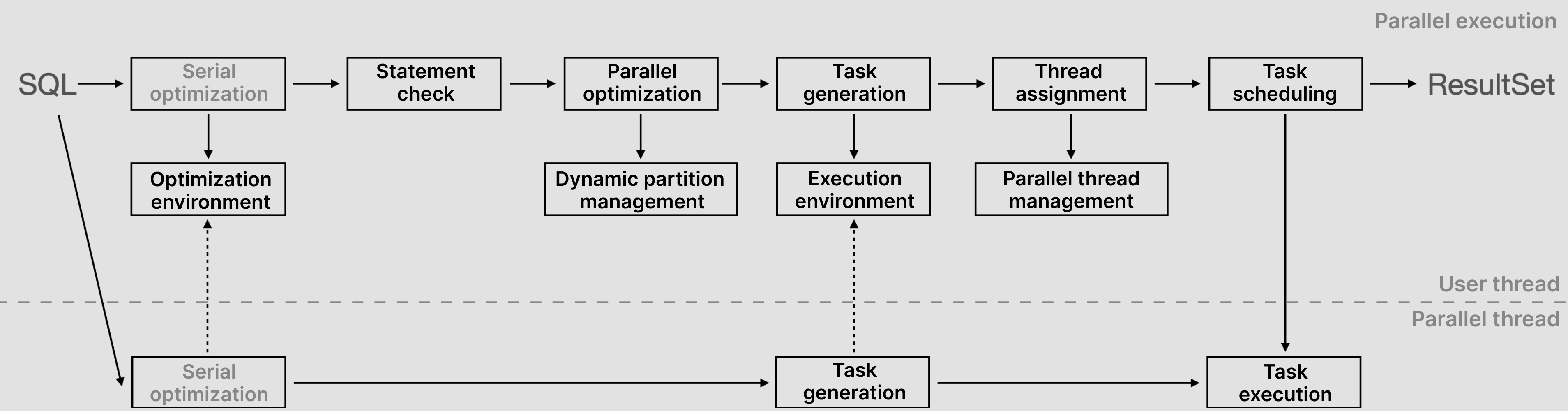
TDSQL-C MySQL 版基于上述原理,实现了整套并行查询计划,将串行处理流程扩展为了并行处理流程,如下图所示。
一条 SQL 语句,在 MySQL 传统的串行流程中为:一条 SQL 语句先进行串行优化,输出串行执行计划,之后执行迭代式模型输出结果,整个过程效率不高。为实现并行查询能力,TDSQL-C MySQL 版全新设计了整套 SQL 语句处理流程: 1. 基于并行查询原理我们可知,整个过程被划分为用户线程和工作线程(并行线程)两部分,所有的流程均在这两类线程中进行。在一条 SQL 语句开始执行后,用户线程会在优化器中根据所设定的参数值对这条语句进行分析,生成对应的执行计划。SQL 优化环境可以简单理解为一个高度抽象的确定性计算模块,其输入是 SQL 和优化环境,输出是执行计划。对于相同的输入,就会有相同的优化路径,产生相同的输出,保证结果的准确性。
2. 生成执行计划后,会进入语句检测阶段,此时计算层会检测该语句是否符合执行并行查询的标准,语句层面检测包括动态查询,数据隔离级别是 RC 或 RR,数据处理量是否足够多代价,执行计划层面检测迭代算子和函数是否可以并行,若不符合要求,该语句会回到串行执行;若符合标准则执行并行查询,进入并行优化阶段。具体支持的语句请参见 并行查询支持的语句场景。 3. 在并行优化阶段,计算层会根据需求去选择对哪个表进行数据拆分,并对聚合或排序等操作进行任务拆分,方便各 worker 并行执行。在优化阶段,由于涉及数据划分,为保证划分到每个线程的数据足够均衡,TDSQL-C MySQL 版引入动态分区管理能力,保证一个线程执行多个任务,最大程度避免数据倾斜。
4. 在完成上述一系列流程后,计算层将生成并行查询任务,通过任务副本的方式下推至工作线程,并根据参数设置的值对工作线程数量进行分配与限制,工作线程此时开始执行并行查询操作,各线程并行执行,得到结果后将数据上推至用户线程进行聚合处理,并返回给用户,至此,一条语句完整的并行查询流程执行完毕。
整体流程可以总结为,用户线程收到 SQL 后,经解析、校验和优化等常规步骤,产生串行执行计划,同时搜集优化过程依赖的各种信息(优化环境)。然后,分析串行执行计划(语句检测,实际上是检测算子树、执行环境和优化代价),决定是否启动并行优化。并行优化时将串行算子树划分成粗粒度任务,选定并行表(动态分区)和任务间数据交换算法,并构造任务依赖图。此时,用户线程准备就绪,从可用线程管理器里申请到足够的工作线程,就可以开始调度执行,工作线程完成后,根据并行查询原理,数据通过数据交换至用户线程进行聚合处理,返回给用户完整结果。
在以上流程中,TDSQL-C MySQL 版设置了多种参数方便用户对并行查询能力进行调整,控制语句的执行代价与并行查询造成的资源负载等,并辅以多种监控指标,实时监控与并行查询有关的多项信息,详情请参见 开启或关闭并行查询。