产品架构
Download
聚焦模式
字号
TDSQL Boundless 实例分为集群版和基础版两种:
集群版:由多个节点构成,以多副本 Raft 集群的形态提供高性能可用的数据库服务,适用于企业生产环境。
基础版:由单个节点构成,以较低的成本提供完整的数据库功能但不包含高可用能力,适用于个人用户。
说明:
基础版实例创建后可以通过控制台升级为集群版实例,集群版实例创建后不可以降级为基础版实例。
TDSQL Boundless 实例内的节点分为对等架构和分离架构两种:
对等架构:计算层 SQLEngine 与数据层 TDStore 合并在一个物理节点中,减少硬件节点数量和跨节点通信,从而降低成本并提高性能。
分离架构:计算层 SQLEngine 与数据层 TDStore 分别在不同的物理节点中。
TDStore 技术架构
无论是集中式单机数据库还是分布式数据库,功能模块通常可以分为三大组件:
计算引擎:主要包括 SQL 解析、优化器、执行器等。
存储引擎:主要包括事务处理、数据存储等。
元数据服务:主要包括全局逻辑时钟服务、全局 ID 生成器、元数据存储、调度引擎(数据/容灾调度)以及负载采集等。
TDSQL Boundless 的总体架构如图所示:
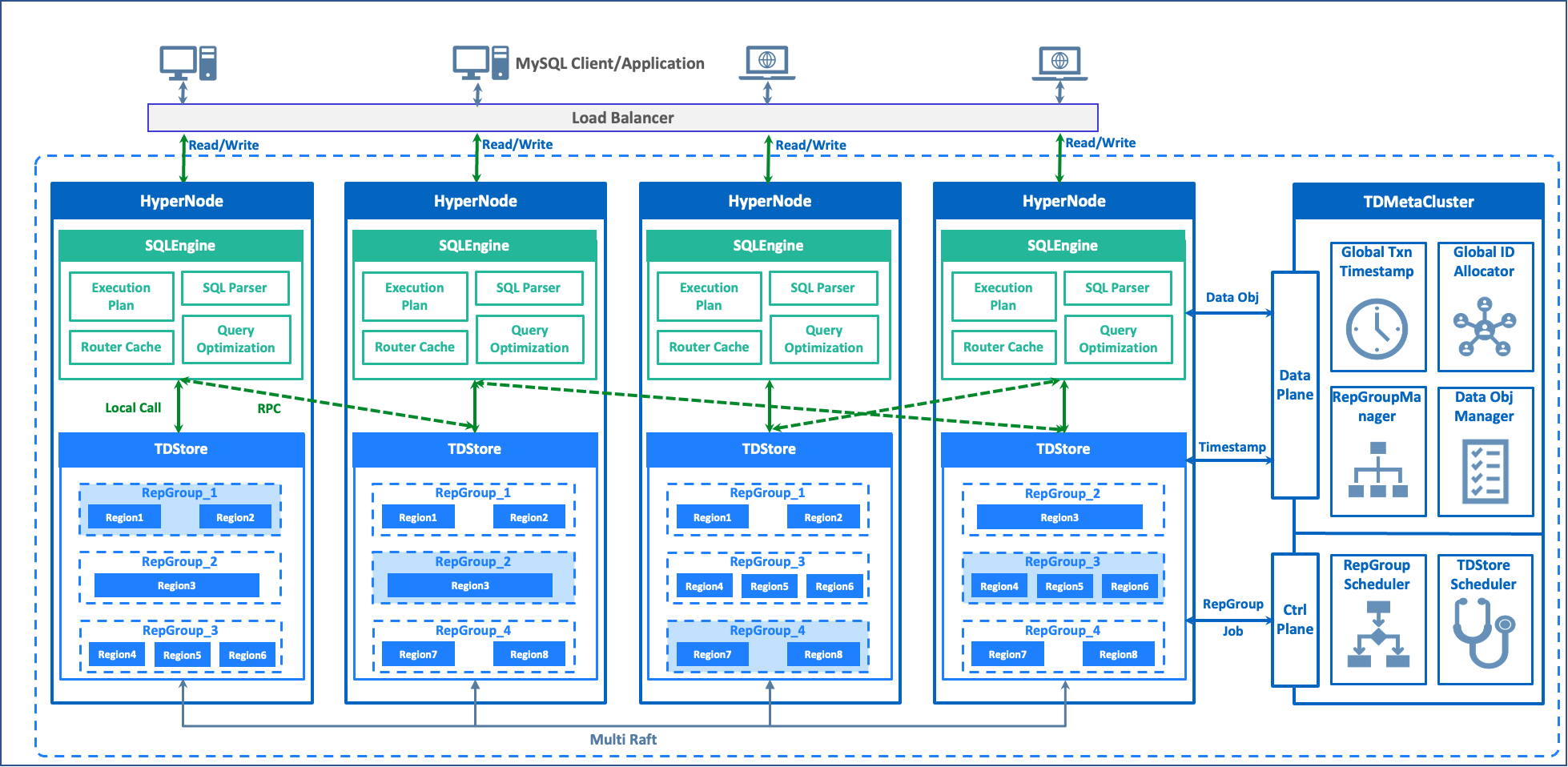
计算引擎-SQLEngine
内核:基于 MySQL 8.0 实现,对 MySQL 兼容度高。
架构:计算层为多主架构,无状态化设计,每个 SQLEngine 节点均可读写。
交互:从管控节点获取全局事务时间戳和数据路由信息,然后与存储节点进行事务交互,向客户端返回结果。
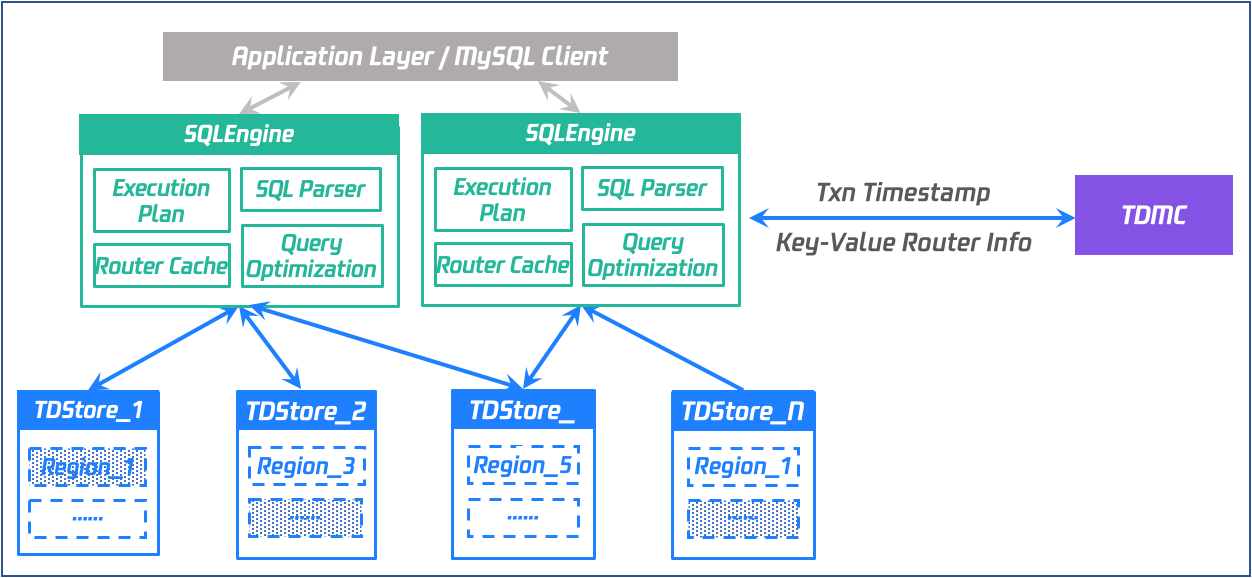
存储引擎-TDStore
架构:基于 LSM-Tree 和 Multi-Raft 的分布式 KV 存储引擎。
数据:基于 Raft 同步的多副本的存储,数据根据 Key 范围分布在不同 Region 上,多个 Region 共同组成复制组并借助 Raft 共识协议进行数据复制和高可用切换。
交互:TDStore 接收来自计算节点的请求,处理后返回结果;每个 Region 的主副本负责接收和处理读写请求。
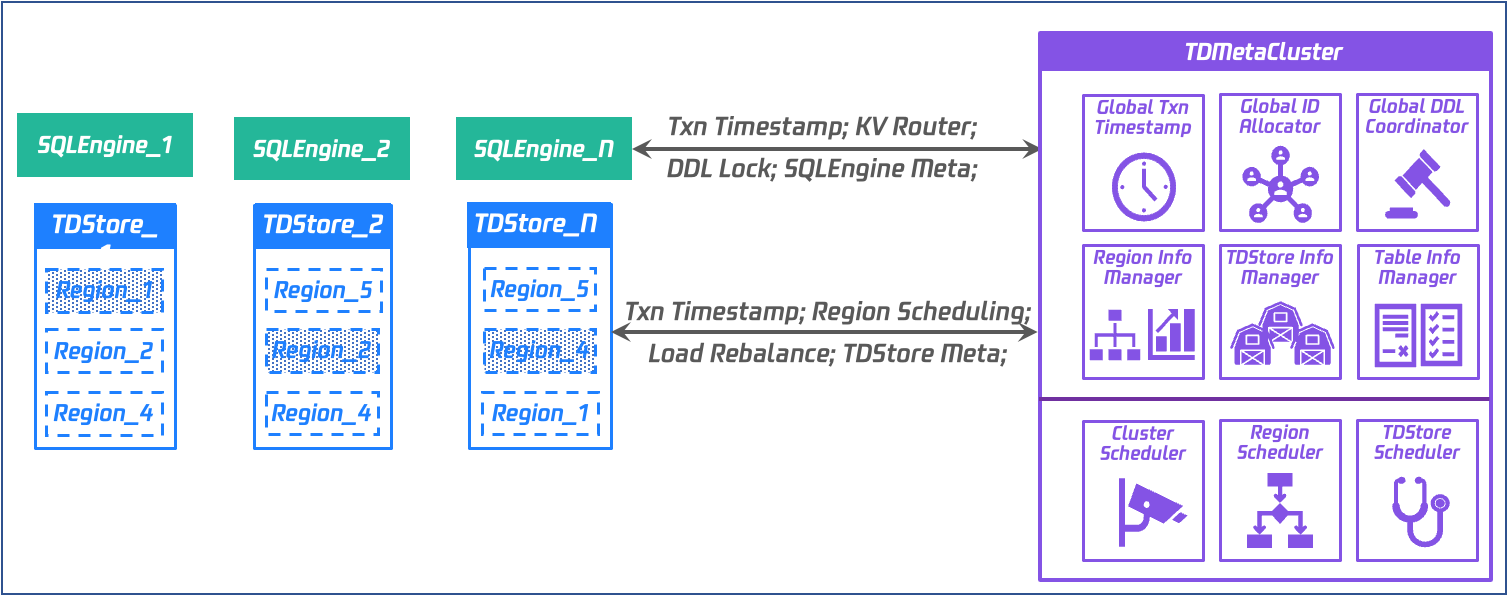
元数据服务-TDMC
架构:基于 Raft 的一主两备的元数据管理集群,由 Leader 提供服务。
数据:
分配全局唯一且递增的事务 ID。
管理 TDStore 和 SQLEngine 元数据。
管理 Region 数据路由信息。
全局 MDL 锁管理。
管控:
调度复制组的分裂、合并、迁移、切主。
存储层的扩缩容调度。
存储层的负载均衡调度。
各维度的异常事件告警。
存储模型
TDSQL Boundless 的存储引擎会将所有用户数据映射到(-∞,+∞)的线性有序无限的 Key 空间中,每行数据对应到 key 空间中的某个点。
//示例create table t1 (f1 varchar(50),f2 varchar(20),f3 varchar(20),f4 varchar(20),primary key(f1,f2),index idx_f3(f3));insert into t1 values('a', 'b', 'c', 'd');
在上图的示例中,插入一行数据后,会产生两个 KV 键值对:
主键:pk_encode('t1', 'a', 'b') -> pk_value_encode('c', 'd')
索引:sk_encode('idx_f3', 'c', 'a', 'b') -> sk_value_encode()
因为每个 key 的最前面部分是该数据对象(表/索引/分区表)的 ID,故该数据对象的所有数据会连续分布在 Key 空间的某一段上。
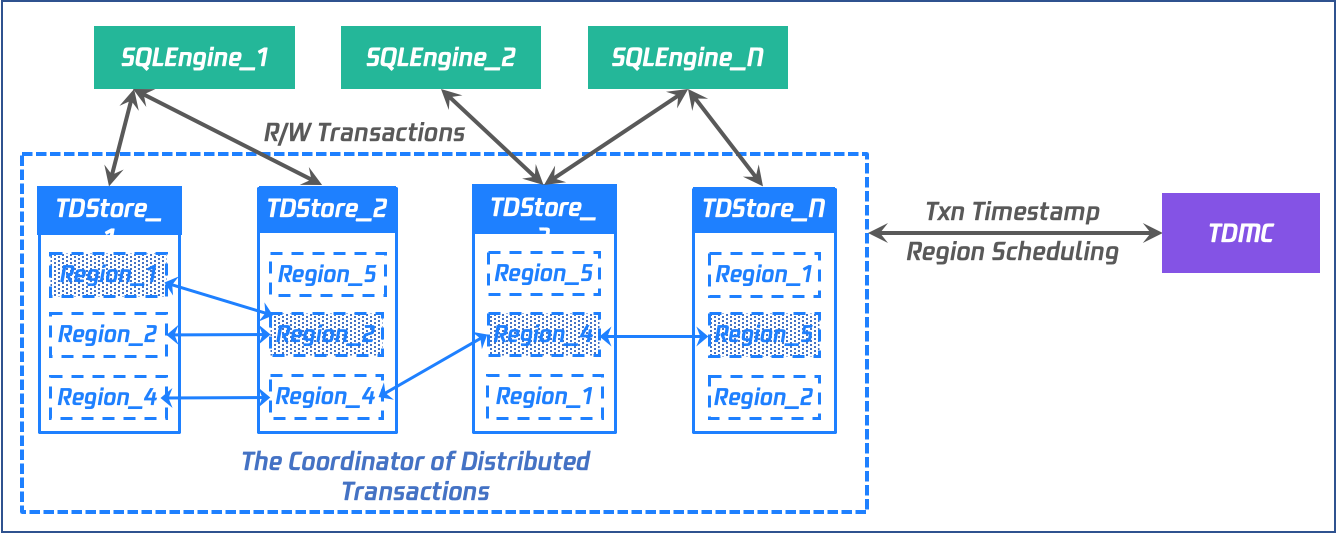
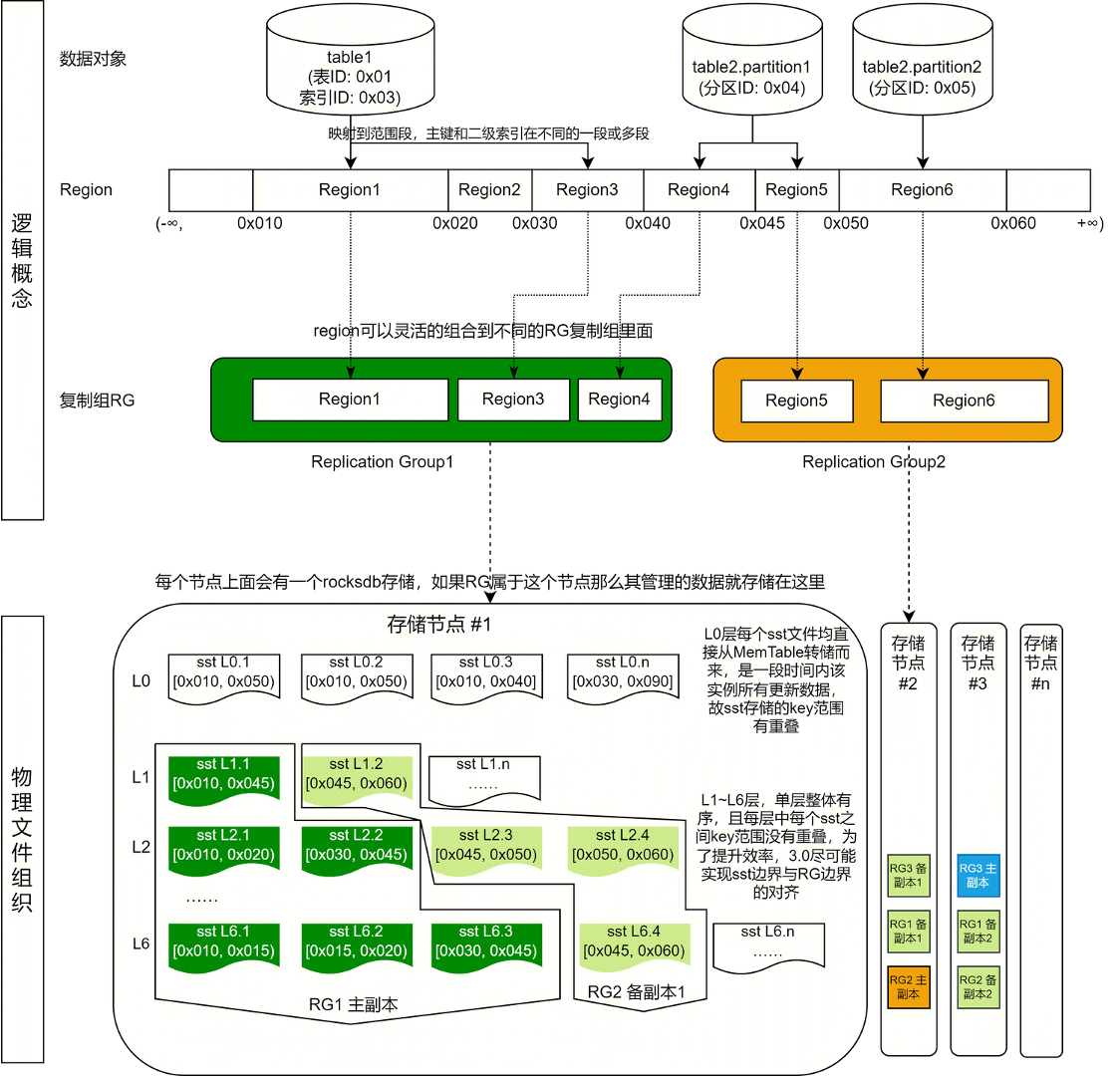
三层组织模式(DO-Region-RG)
数据对象(Database Object):例如表(table),分区(Partition),索引(Index),通常会为这些数据对象分配一个全局唯一的 ID(index_id)。
数据分片(Region):
①:一段连续的,左闭右开的 key 空间,[startkey, endkey)。
②:一个数据库对象对应一个或多个 Region,且在运行过程中,可以根据数据调度策略,对 Region 进行分裂,或将多个 Region 合并为一个 Region。
③:数据调度的基本单位,不同的 Region 可以分布在该实例中的任何节点。
④:Region 是一个逻辑概念,在底层存储上,并不是完全独立的一段或一个文件。
复制组(Replication Group):
①:一个复制组中可以包含一个或多个 Region,这些 Region 属于一个或多个数据对象。
②:在运行过程中,可以合并 RG,也可以分裂 RG(具体实现中通过创建 RG,迁移 Region 进入或离开 RG 等来实现)。
③:一个 RG,对应一个 Raft 日志流(redo log/WAL),如果一个事务(transaction)所涉及到的 key 都在一个 RG 内,则该事务可转换为单机事务,如果一个事务涉及数据跨 RG,则需要走两阶段的分布式事务协议。
对等架构节点
在 TDSQL Boundless 的架构设计中,我们既要让计算离存储(缓存/存储)尽可能的近,也要能做到计算与存储分离实现高弹性,因此 TDSQL Boundless 的设计为:
采用对等架构(HyperNode)设计,每个对等节点(进程)均包含完整的计算、存储、日志三个功能引擎。
计算层与本地存储采用本地访问模式,访问远端存储则采用网络 RPC 访问模式,尽可能地确保访问本地数据的性能。
根据不同业务场景的需要,通过元数据及调度模块,也可以实现对节点进行角色指定,例如支持全功能节点(计算存储日志三个服务都提供),计算节点(仅支持计算,所有数据通过 Remote 访问),存储节点(仅支持数据存储),日志服务(仅提供日志订阅服务)等。
说明:
节点角色指定的功能特性暂未开放。
文档反馈