数据智能调度及相关性能优化实践
Download
聚焦模式
字号
引言
历经多年技术演进,分布式数据库已突破传统"分库分表"的单一场景局限,从应对海量数据的权宜之策进化为支撑业务弹性扩展的核心架构。分布式数据库 TDSQL Boundless 通过构建集中分布式一体化能力(Integrated Centralized-Distributed Solution),实现了数据库运行模式与业务规模的动态适配:在业务初期,系统以完全兼容集中式数据库的形态运行,保障开发习惯与运维体系的延续性;当业务进入高速增长阶段,仅需配置级调整即可无缝切换至分布式模式,通过在线弹性扩缩容应对流量洪峰与数据膨胀。整个过程实现了两大突破:
1. 零改造平滑演进:业务逻辑层无需适配分布式事务逻辑,数据层通过智能路由保持访问一致性。
2. 无感知架构切换:从集中式到分布式的升级过程保持业务连续性,规避传统方案耗时的数据迁移与停服风险。
分布式数据库 TDSQL Boundless 的集中分布式一体化能力主要依赖数据智能调度技术。数据智能调度技术不仅实现了集中分布式一体化能力,更在分布式场景下创新性地引入数据亲和性优化机制,通过预定义规则与定制化策略结合,将具有强业务耦合的数据单元智能调度至同一物理节点,从根本上规避跨节点RPC访问的性能损耗。本文将分享腾讯云数据库 TDSQL 系列的最新产品:分布式数据库 TDSQL Boundless 的数据智能调度及相关性能优化实践。
TDSQL Boundless 数据智能调度组件 TDMetaCluster
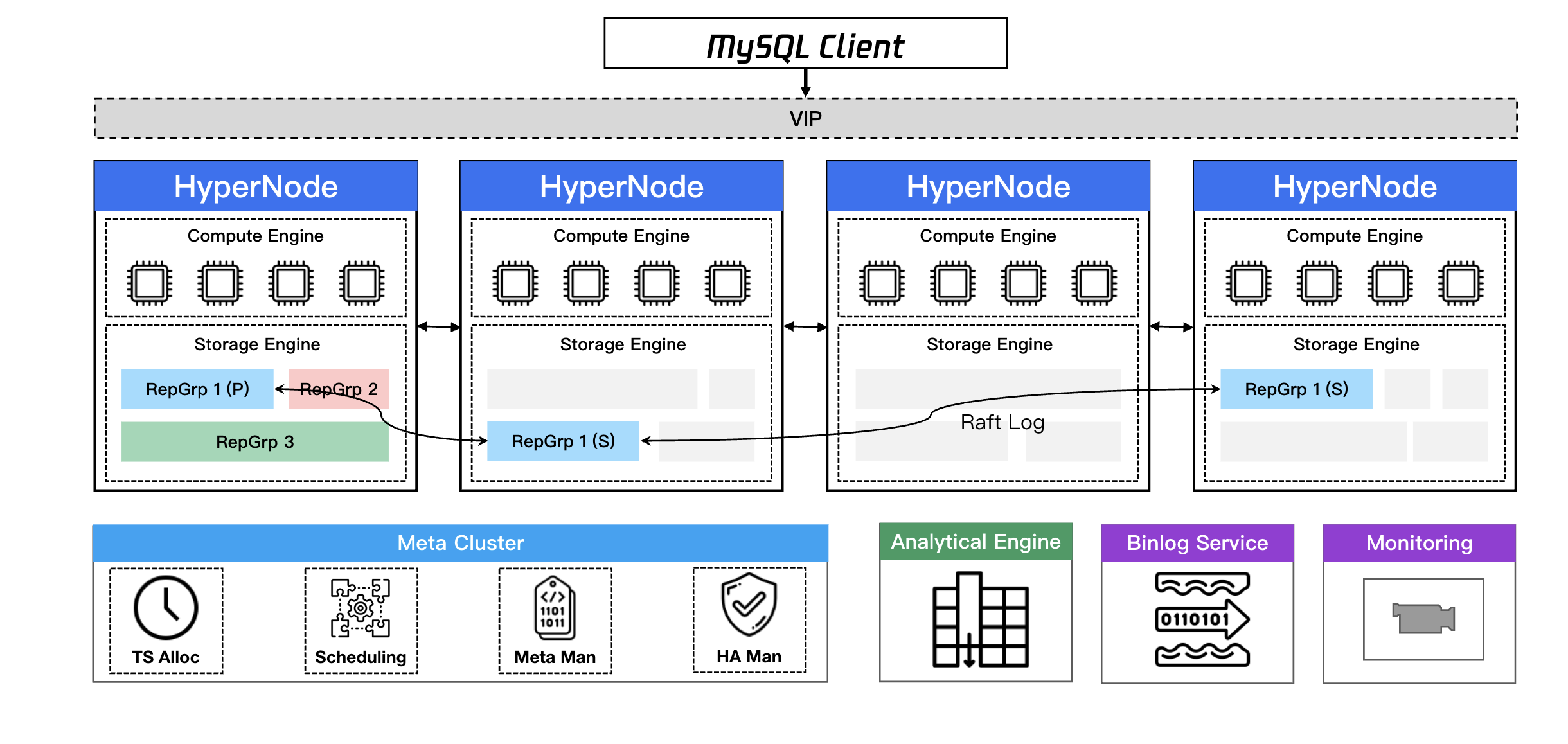
TDSQL Boundless 是腾讯面向金融级应用场景的,高性能、高可用的企业级分布式数据库解决方案,采用容器化云原生架构,提供集群高性能计算能力和低成本海量存储。
TDSQL Boundless 架构和功能特性:全分布式 + 存算一体/存算分离 + 数据面/控制面分离 + 高可扩展 + 全局一致性 + 高压缩率。
在 TDSQL Boundless 中负责数据智能调度的正是组件 TDMetaCluster(上图右侧,以下简称 TDMC),它是 TDSQL Boundless 数据库实例的中心管控模块。
1. TDMC 的架构:基于 Raft 协议的一主两备的元数据管理服务,其中 Leader 节点负责处理请求。
2. TDMC 的数据面:
2.1 分配全局唯一且递增的事务ID。
2.2 管理 TDStore 和 SQLEngine 的元数据。
2.3 管理 Replication Group 数据路由信息。
2.4 全局 MDL 锁管理。
3. TDMC 的管控面:
3.1 调度 Replication Group 和 Region 的分裂、合并、迁移、切主。
3.2 存储层的扩缩容调度。
3.3 存储层的负载均衡调度。
3.4 各维度的异常事件告警。
作为 TDSQL Boundless 实例的核心调度引擎,它不仅可以通过预定义规则管理数据副本的组织与分布,还支持用户根据业务需求灵活配置定制化策略。接下来,我们将探讨如何基于业务场景选择合适的部署模式:集中式或分布式模式。尽管 TDSQL Boundless 作为原生分布式数据库具备强大的分布式处理能力,但在特定场景下,集中式模式可能更契合实际应用需求。
TDSQL Boundless 集中分布式一体化
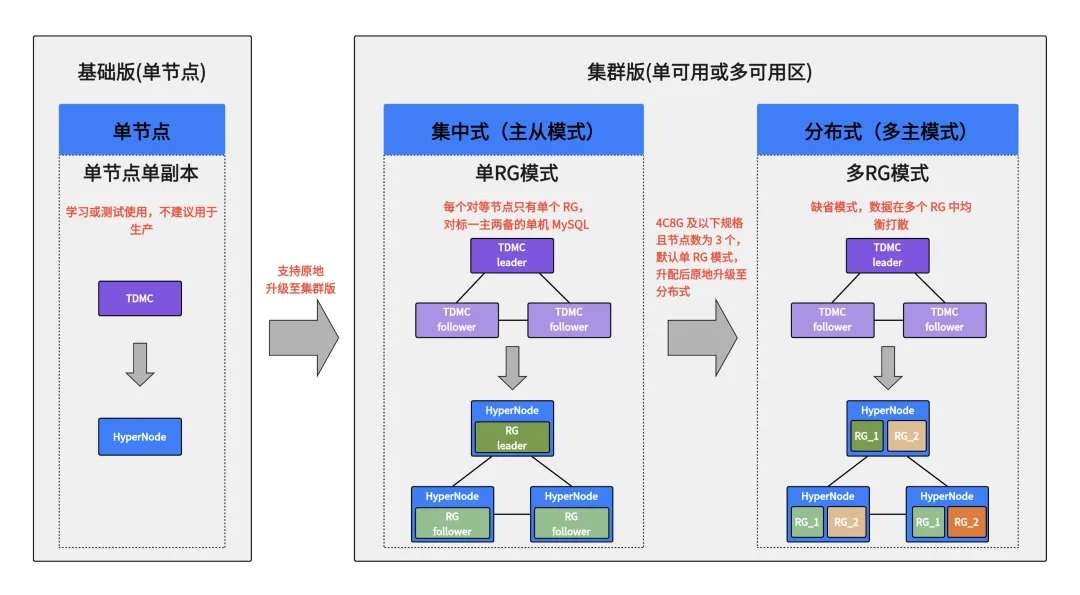
首先,基于业务规模评估:包括数据量、访问频率、响应时间及扩展性需求,选择匹配的 TDSQL Boundless 规格。即使初期估算存在偏差也无需担忧,TDSQL Boundless 凭借其高效弹性伸缩能力,可灵活适配各类动态变化的敏态业务场景。
参考上图所示,部署模式选择如下:
1. 体验学习:选择"基础版"【单节点单副本】,无高可用特性。
2. 生产环境:选择"集群版"【基于 Raft 多数派协议的三副本架构】。
3. 高级容灾:集群版支持"单可用区"和"多可用区"部署,后者可实现同地域三可用区容灾。
4. 小型业务:4C/8G及以下规格且节点数为3时,系统自动启用集中式模式(单 RG 模式),主副本集中存储,兼容单机 MySQL 使用体验。
5. 中大型业务:4C/8G以上规格或节点数超过3时,系统自动切换为分布式模式(多 RG 模式),数据均衡分布,多节点对等读写,确保高性能与高可用。
建议结合实际业务进行功能与性能测试,以验证配置是否满足峰值需求。
在了解如何选择 TDSQL Boundless 配置后,您可能对集中式模式已无疑问,但仍会担忧分布式架构是否影响性能。这种顾虑确实存在,而数据库智能调度技术正是解决此类性能问题的关键。在深入探讨前,需先理解分布式系统的一个关键设计:数据均衡——它是保障系统性能与可靠性的基石。接下来,我们将详细解析数据均衡的原理及其在 TDSQL Boundless 中的实践应用。
TDSQL Boundless 数据均衡
数据均衡是分布式系统的一个关键特性,涵盖容量均衡与热点均衡两大维度:容量均衡通过均匀数据分布,优化全局资源利用率;而热点均衡则致力于解决局部高负载问题。
TDSQL Boundless 的技术亮点
1. 容量均衡
1.1 三层存储模型与资源预分配:
1.2 双维度分裂控制:
Region级:256M/500万 Key 触发分裂,保持原 RG 归属。
RG级:32G/1.6亿 Key 触发分裂,单表 RG 超节点容量20%才分裂,避免分布式事务;分裂后以 RG 为单元自动迁移,维持容量均衡。
1.3 迁移优先级策略:
优先迁移备副本。仅在节点中存在主副本时,才进行主副本的迁移,确保业务无感知。
1.4 弹性扩缩容联动:
自动触发数据再均衡以适应节点数变化。
2. 热点均衡
2.1 智能决策引擎:
采用加权移动平均算法实时采集节点/ RG /数据对象三级流量指标,逐级判定热点源并执行差异化调度,如跨节点切主或分裂+切主组合操作。
稳定性保障机制:
调度冷却期:热点 RG 调度后进入冷却状态,防止热点频繁切。
历史调度记忆:记录节点迁移轨迹,防止热点来回切。
2.2 场景化调度模式:
支持手动配置读写热点模式,默认读热点优先,灵活适配不同业务需求。
然而,对于分布式数据库系统而言,单纯的数据均衡并不等同于“最优”状态。如果调度模块未能充分理解存储层的库表逻辑含义,系统仍可能遭遇性能瓶颈。
为了更好地说明这一点,我们考察一个典型的分布式应用场景:当应用程序客户端向 TDSQL Boundless 数据库实例提交一条 SQL 语句时,TDMC(管控模块)如何与 SQLEngine(SQL 引擎)以及 TDStore (存储引擎)协同工作以处理这一请求。
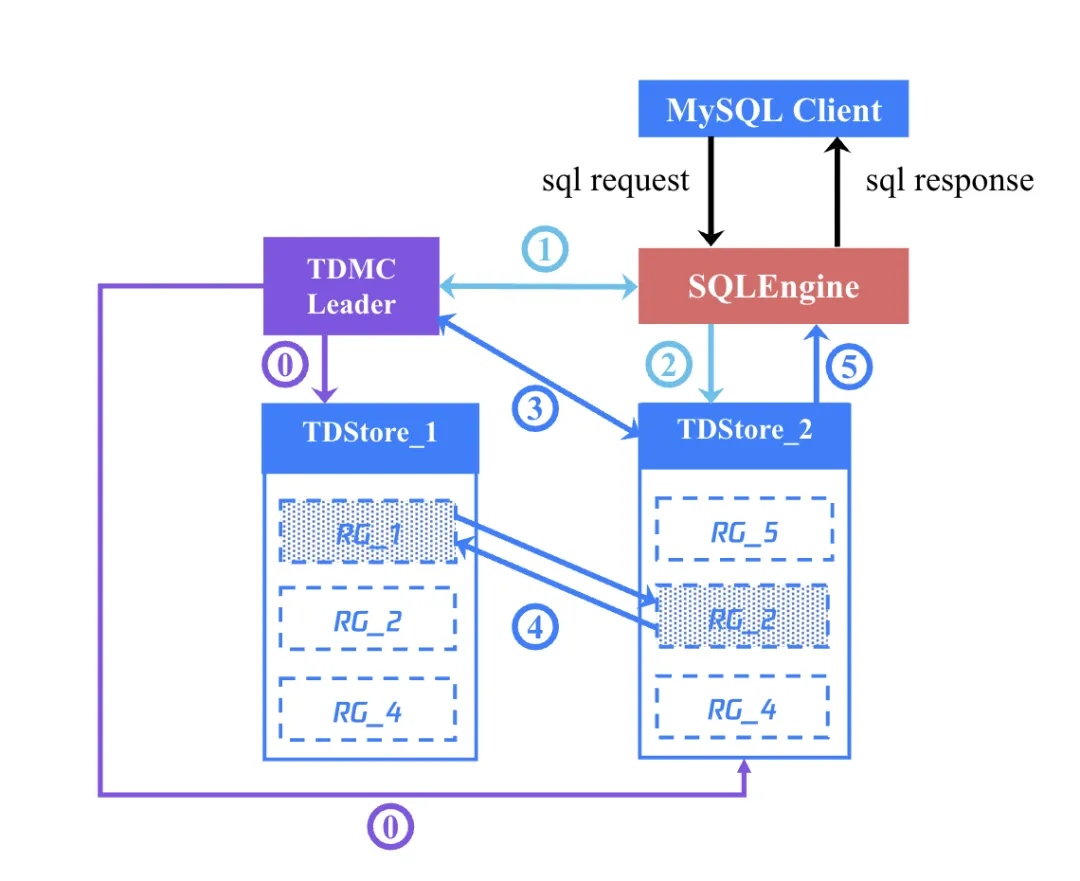
Step 0:TDMC 周期性向所有 TDStore 下发全局最小快照点,确保读操作的全局一致性。
Step 1:SQLEngine 接收到 SQL 语句,开启事务,从 TDMC 取回事务开启时间戳
begin_ts;在自身缓存中查询 SQL 语句对应的 RG 路由信息;若无,则将对应的 key 范围查询请求发送给 TDMC,由 TDMC 告知最新的路由信息。Step 2:SQLEngine 将请求发送到对应的 RG 的 Leader 副本所在的 TDStore 上。
Step 3:Leader 副本作为协调者开启两阶段事务,从 TDMC 取回 prepare_ts。
Step 4:所有参与者 Prepare 就绪后,从 TDMC 取回
commit_ts,提交事务;若过程中,参与事务的其他 RG 发生切主, 则从 TDMC 查询其最新的 Leader 信息。Step 5:提交事务,成功后将结果返回至 SQLEngine, 继而将结果返回到客户端。
上述执行过程可能面临以下三个性能挑战:
1. 计算与存储的分离:如果计算节点和存储节点之间严格分离,网络延迟和带宽限制会对性能产生负面影响。数据在不同节点间的传输会增加额外的开销,从而降低整体系统的响应速度。
2. 数据对象的分散存储:如果同一表的相关数据对象分布过于分散,例如表的数据存储在 RG_1 中,而其二级索引存储在 RG_2 中,那么即使是简单的单条事务写入操作也需要通过分布式事务来协调,这无疑增加了复杂性和处理时间。
3. 跨机器的关联查询:当具有关联关系的多个表(如 A 表存储在 RG_1 中,B 表存储在 RG_2 中)需要进行 JOIN 操作或参与分布式事务时,这些操作将不可避免地涉及跨机器通信,进一步加剧了延迟和资源消耗。
针对第一个挑战,TDSQL Boundless 采用计算存储一体化架构,通过 SQLEngine 与 TDStore 物理绑定形成对等节点,提升本地化数据访问性能(函数调用替代 RPC)。至于其余两个挑战,则通过 TDSQL Boundless 的智能调度机制来解决。接下来,我们将具体探讨 TDSQL Boundless 是如何应对这些挑战的。
TDSQL Boundless 数据智能调度
TDSQL Boundless 通过多级规则体系实现数据亲和性调度。包括三类规则:
通用规则:如关系数据库中数据对象的结构耦合,此规则无需修改。
预定义规则:可能会给性能带来提升的逻辑耦合,如与业务需求不符,可以对此规则进行修改。
自定义规则:用户可根据业务需求自行创建。
通过这种分层规则体系,TDSQL Boundless 实现了系统性能与业务灵活性的最佳平衡:在确保高效运行的同时,显著降低事务延迟并提升查询响应速度。接下来,我们将深入解析其技术实现细节。
1. 通用规则
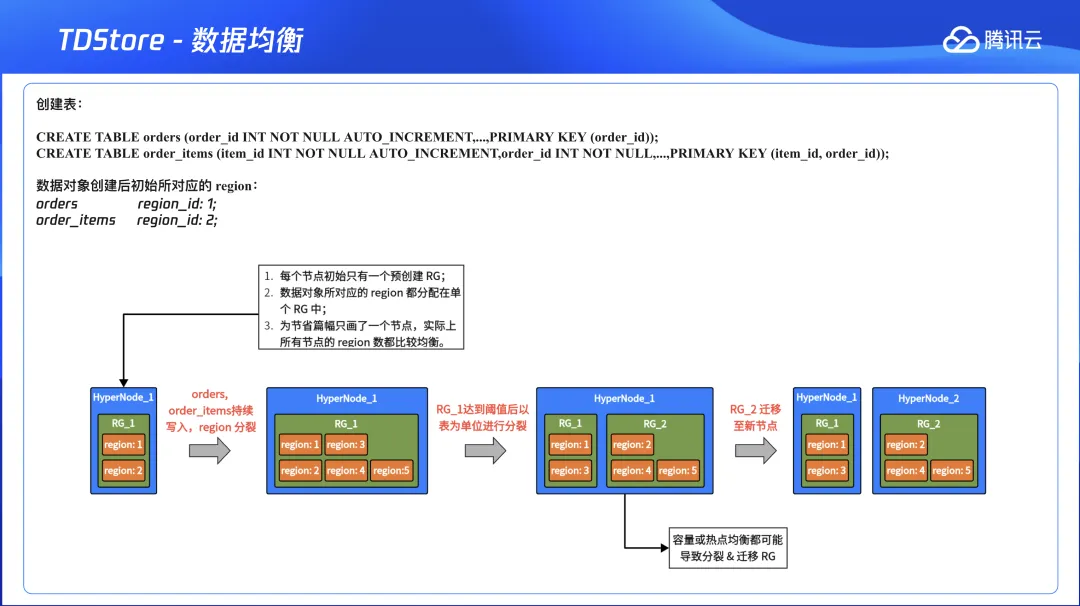
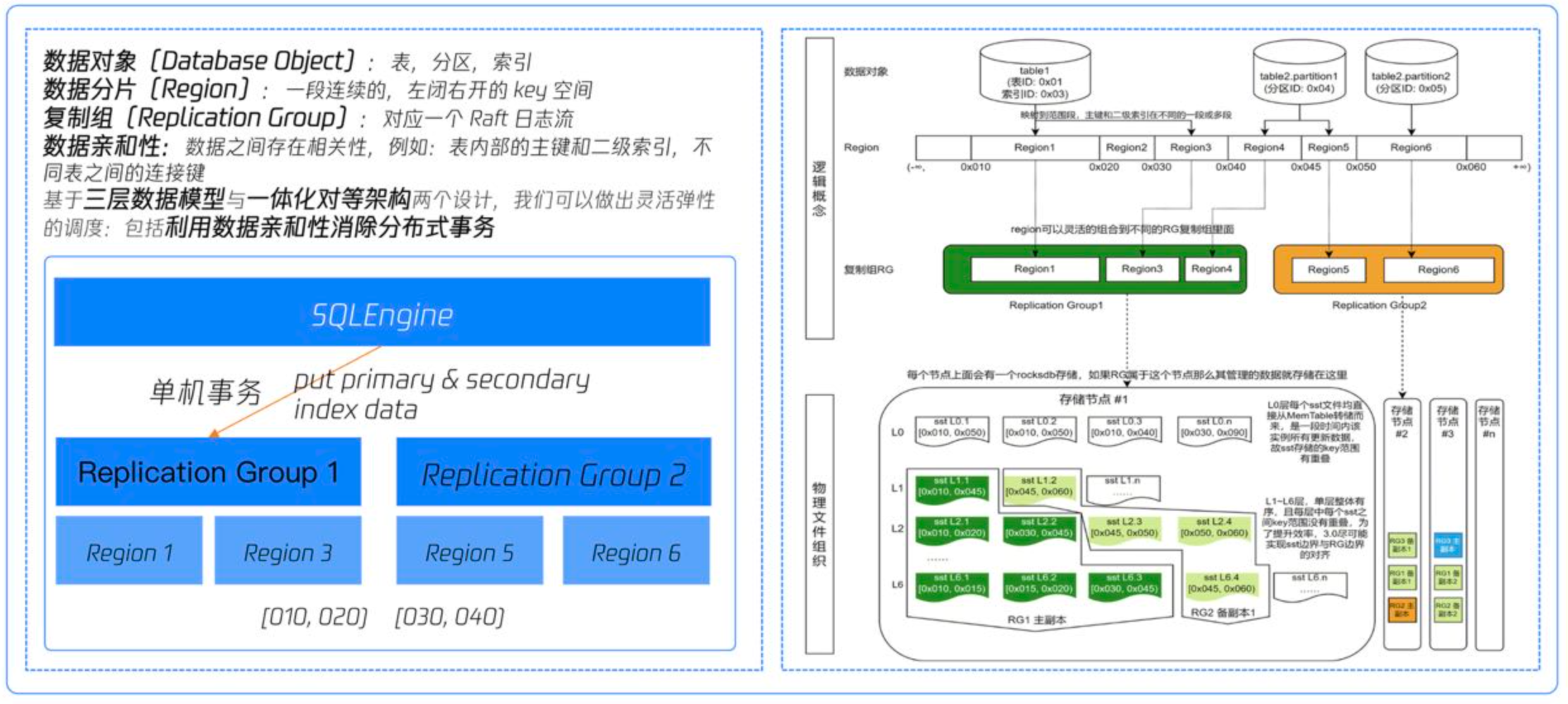
下图展示了 TDStore 的三层数据模型:在系统中一个表不会直接对应一个物理文件,而是会先映射到一个范围段 Region。图的右侧部分展示了 table 1 分配了01和03两个 Region,01对应主键,03对应其二级索引。当表的数据量非常大的时候,我们就可以把 Region 拆分,然后将其映射到其他数据节点上。在 Region 和物理数据之间引入了复制组(RG),可以灵活的把不同范围段的 Region 放入这个 RG 中,一个 RG 对应一个 Raft 日志流,如果一个事务只修改了这个复制组中的数据,那么其就可以做完单机事务之后提交,但是如果一个事务涉及到了多个复制组的话,就必须以分布式事务的形式走两阶段提交。
通过内置的通用规则,TDStore 利用数据亲和性来消除分布式事务:默认将表的主键和其对应的二级索引存放在同一个 RG 中【如图的左下侧所示,table1 的主键是 Region 1,其二级索引是 Region 3,都归属于 RG 1】,这样就保证了对表的更新和写入都一定是单机事务。
2. 预定义规则
TDSQL Boundless 支持预定义的数据亲和性规则,这些是在适配业务逻辑的日常工作中总结出的一些经验,如:创建二级分区表时,不同一级分区下的对应二级分区划分到相同 RG,如表 t1.p0.sp0 与 t1.p0.sp0 放到相同 RG。如果业务有特定需求,有方法修改其默认行为。

3. 自定义规则
此外,TDSQL Boundless 还支持根据业务逻辑自定义数据亲和性规则。用户可以根据业务数据的关联性控制一组表在物理存储上的邻近关系,进一步优化事务处理性能。具体的做法是通过特定的 SQL 命令创建一组表同号分区的绑定策略,以及节点分布策略,并与一组表进行绑定(这组表要求分区类型、分区个数、分区值一致),系统就会将这组表的同号分区聚集在同一台机器上,避免跨机查询和分布式事务,提高性能。

TDSQL Boundless 分区亲和性优化实践
在实践部分,我们举一个"自定义规则"数据亲和性的例子。具体来说,我们将对比两个表在执行 JOIN 查询时的表现:一个场景是这两个表满足数据亲和性,另一个场景则是它们不满足数据亲和性。通过对比,我们可以更直观地感受数据亲和性对查询性能的实际影响。
硬件环境
节点类型 | 节点规格 | 节点个数 |
HyperNode | 16Core CPU/32GB Memory/增强型 SSD 云硬盘300GB | 3 |
测试目的
TDSQL Boundless 率先支持的是一级 HASH 分区表的隐式分区亲和性,只要有关联关系的表都创建为一级 HASH 分区,且分区个数相同,同号分区默认就会被调度到同一个复制组【后续版本会支持手工创建亲和性策略,以及支持更丰富的分区表类型】。
本次测试的数据模型是订单和商品明细的关联查询。
数据准备
-- 订单表 orders,一级hash分区表:CREATETABLE orders (order_id INTNOTNULLAUTO_INCREMENT,customer_id INTNOTNULL,order_date DATENOTNULL,total_amount DECIMAL(10,2)NOTNULL,PRIMARYKEY(order_id))PARTITIONBYHASH(order_id)PARTITIONS 3;-- 订单明细表 order_items,每个订单随机1-3个商品,一级hash分区表:CREATETABLE order_items (item_id INTNOTNULLAUTO_INCREMENT,order_id INTNOTNULL,product_id INTNOTNULL,quantity INTNOTNULL,price DECIMAL(10,2)NOTNULL,PRIMARYKEY(item_id, order_id),INDEX idx_order_id (order_id))PARTITIONBYHASH(order_id)PARTITIONS 3;--造数过程略,两表最终记录数:MySQL [klose]>selectcount(*)from orders;+----------+|count(*)|+----------+|1000000|+----------+1rowinset(0.10 sec)MySQL [klose]>selectcount(*)from order_items;+----------+|count(*)|+----------+|1999742|+----------+1rowinset(0.39 sec)--查看数据分布,确保同号分区在相同对等节点的同一个 RG 中:SELECTb.rep_group_id, a.data_obj_name, a.schema_name, a.data_obj_name, c.leader_node_name,SUM(b.region_stats_approximate_size)AS size,SUM(b.region_stats_approximate_keys)AS key_numFROMINFORMATION_SCHEMA.META_CLUSTER_DATA_OBJECTS a,INFORMATION_SCHEMA.META_CLUSTER_REGIONS b,INFORMATION_SCHEMA.META_CLUSTER_RGS cWHEREa.data_obj_id = b.data_obj_idand b.rep_group_id = c.rep_group_idand a.data_obj_type notlike'%index%'and a.data_obj_type notlike'%AUTOINC%'and a.schema_name ='klose'and data_obj_name notlike'%bak%'GROUPBYb.rep_group_id, a.schema_name, a.data_obj_nameORDERBY1,2,3;+--------------+----------------+-------------+----------------+--------------------------+---------+---------+| rep_group_id | data_obj_name | schema_name | data_obj_name | leader_node_name | size | key_num |+--------------+----------------+-------------+----------------+--------------------------+---------+---------+|868437| orders.p1 | klose | orders.p1 | node-tdsql3-c1528b96-002|3909181|333334||868437| order_items.p1 | klose | order_items.p1 | node-tdsql3-c1528b96-002|7708701|666508||869169| orders.p0 | klose | orders.p0 | node-tdsql3-c1528b96-001|3792790|333333||869169| order_items.p0 | klose | order_items.p0 | node-tdsql3-c1528b96-001|7575671|666757||869736| orders.p2 | klose | orders.p2 | node-tdsql3-c1528b96-003|3782701|333333||869736| order_items.p2 | klose | order_items.p2 | node-tdsql3-c1528b96-003|7550956|666477|+--------------+----------------+-------------+----------------+--------------------------+---------+---------+--使用 Jmeter 测试关联查询,观察 local scan 的性能:SELECTCOUNT(*)FROM orders a JOIN order_items b ON a.order_id=b.order_id;--执行计划,每个节点启一个 worker 线程,完成本节点的并行子任务:以 orders 表在当前节点的任一子分区(p0-p2)作为驱动表,其每一行记录到 order_items 表中利用索引快速找到满足条件的匹配行,最终汇聚所有 worker 线程的结果并返回;如果都是 local scan,执行效率将大幅提升:|-> Aggregate: count(0)(cost=763055.75rows=2000000)-> Gather (slice: 1, workers: 3)(cost=563055.75rows=2000000)-> Aggregate: count(0)(cost=763055.75rows=2000000)-> Nested loopinnerjoin(cost=563055.75rows=2000000)->Index scan on a usingPRIMARY,with parallel scan ranges: 3(cost=112507.50rows=1000000)->Index lookup on b using idx_order_id (order_id=a.order_id)(cost=0.25rows=2)
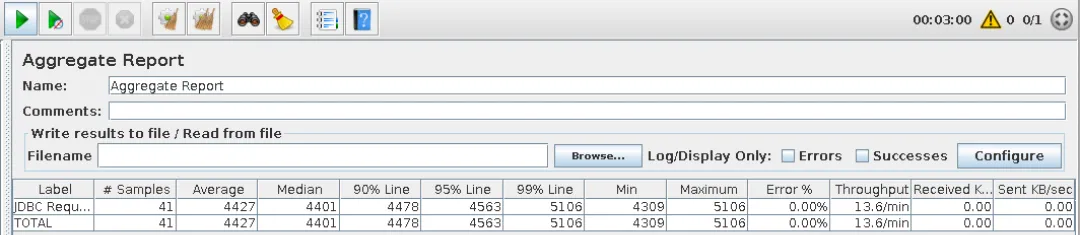
单进程,持续执行3分钟,在此期间完成请求41次,平均响应时间为4.4s:
模拟老版本 TDSQL Boundless 没有自动应用分区亲和性的情况:
--当前同号分区都在相同节点上:+--------------+----------------+-------------+----------------+--------------------------+---------+---------+| rep_group_id | data_obj_name | schema_name | data_obj_name | leader_node_name | size | key_num |+--------------+----------------+-------------+----------------+--------------------------+---------+---------+|868437| orders.p1 | klose | orders.p1 | node-tdsql3-c1528b96-002|3909181|333334||868437| order_items.p1 | klose | order_items.p1 | node-tdsql3-c1528b96-002|7708701|666508||869169| orders.p0 | klose | orders.p0 | node-tdsql3-c1528b96-001|3792790|333333||869169| order_items.p0 | klose | order_items.p0 | node-tdsql3-c1528b96-001|7575671|666757||869736| orders.p2 | klose | orders.p2 | node-tdsql3-c1528b96-003|3782701|333333||869736| order_items.p2 | klose | order_items.p2 | node-tdsql3-c1528b96-003|7550956|666477|+--------------+----------------+-------------+----------------+--------------------------+---------+---------+--模拟先前版本 TDSQL Boundless 中默认没有分区亲和性的状态,将 RG 分裂,并进行打散:ALTER INSTANCE SPLIT RG 868437BY'table';ALTER INSTANCE SPLIT RG 869169BY'table';ALTER INSTANCE SPLIT RG 869736BY'table';ALTER INSTANCE TRANSFER LEADER RG 869169TO'node-tdsql3-c1528b96-002';ALTER INSTANCE TRANSFER LEADER RG 868437TO'node-tdsql3-c1528b96-003';ALTER INSTANCE TRANSFER LEADER RG 869736TO'node-tdsql3-c1528b96-001';ALTER INSTANCE TRANSFER LEADER RG 72133681TO'node-tdsql3-c1528b96-001';--调整 TDMC 参数,避免预创建 RG leader 回切:将 TDMC 管控参数 check-primary-rep-group-enabled 设置为 0。--查看数据分布,确认同号分区当前已不再相同对等节点上:SELECTb.rep_group_id, a.data_obj_name, a.schema_name, a.data_obj_name, c.leader_node_name,SUM(b.region_stats_approximate_size)AS size,SUM(b.region_stats_approximate_keys)AS key_numFROMINFORMATION_SCHEMA.META_CLUSTER_DATA_OBJECTS a,INFORMATION_SCHEMA.META_CLUSTER_REGIONS b,INFORMATION_SCHEMA.META_CLUSTER_RGS cWHEREa.data_obj_id = b.data_obj_idand b.rep_group_id = c.rep_group_idand a.data_obj_type notlike'%index%'and a.data_obj_type notlike'%AUTOINC%'and a.schema_name ='klose'and data_obj_name notlike'%bak%'GROUPBYb.rep_group_id, a.schema_name, a.data_obj_nameORDERBY1,2,3;+--------------+----------------+-------------+----------------+--------------------------+---------+---------+| rep_group_id | data_obj_name | schema_name | data_obj_name | leader_node_name | size | key_num |+--------------+----------------+-------------+----------------+--------------------------+---------+---------+|869736| orders.p2 | klose | orders.p2 | node-tdsql3-c1528b96-001|3782701|333333||72133681| order_items.p0 | klose | order_items.p0 | node-tdsql3-c1528b96-001|7575671|666757||869169| orders.p0 | klose | orders.p0 | node-tdsql3-c1528b96-002|3792790|333333||72132949| order_items.p1 | klose | order_items.p1 | node-tdsql3-c1528b96-002|7708701|666508||868437| orders.p1 | klose | orders.p1 | node-tdsql3-c1528b96-003|3909181|333334||72134504| order_items.p2 | klose | order_items.p2 | node-tdsql3-c1528b96-003|7550956|666477|+--------------+----------------+-------------+----------------+--------------------------+---------+---------+--再次执行关联查询,由于现在同号分区全都不在一个对等节点上,orders 表中每一行记录到 order_items 表中进行索引匹配都要走 RPC 调用,叠加三可用区之间 1-3ms 左右的延迟,预期执行效率会大幅下降:SELECT COUNT(*) FROM orders a JOIN order_items b ON a.order_id=b.order_id;
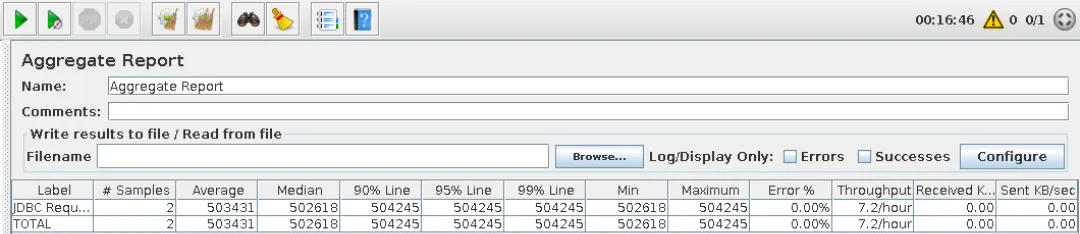
单进程,持续执行16分46秒,在此期间完成请求数量2次,平均响应时间为8分23秒,执行效率相差了足足113倍。
TDSQL Boundless 分区亲和性的未来发展
我们可以看到,分布式数据库的集中分布式一体化能力有效地弥合了传统关系型数据库向分布式架构演进的鸿沟。同时当业务规模增长到达到分布式架构的触发阈值时,依托多级规则体系的数据智能调度能力,显著提升了业务的接入效率和实际性能。架构平滑演进与智能动态调度相结合,为数字化转型提供了稳健且智能化的演进路径。
TDSQL Boundless 正处于飞速发展期,各项功能以用户需求为导向,不断快速迭代和完善。我们仍在持续不断地优化数据智能调度功能,当前版本已率先为常用的一级 HASH 分区表适配了隐式分区亲和性。在未来版本中,我们将进一步扩展支持涵盖一级 KEY 分区表以及 range / list + hash 二级分区表的隐式分区亲和性;并同步引入灵活定制的显式分区亲和性策略,初期将支持一级 HASH 分区表和普通表的显式亲和性指定。
文档反馈