锁机制解析与问题排查实践
Download
聚焦模式
字号
一、引言
锁机制是关系型数据库实现并发访问控制的核心机制之一,理解其工作原理是排查访问冲突问题的关键切入点。例如,在高并发或复杂事务处理场景中常见的锁冲突报错(如 “Lock wait timeout exceeded”),本质上反映了当前事务请求的数据资源(如行、表等)已被其他事务持有锁,当前事务在持续无法获取锁的情况下,达到锁等待超时阈值而被主动中断。
要解决锁冲突,持有锁的会话必须释放锁。让会话释放锁的最佳方式是找出长期持锁会话发起者并联系用户完成事务(提交或回滚)。紧急情况下,DBA 可以终止持有锁的会话。
本文介绍腾讯云数据库 TDSQL 系列的最新产品——TDSQL Boundless,结合典型问题案例,解析锁机制在事务并发中的核心作用,揭示其在保障数据一致性与提升系统吞吐量之间的平衡之道。
二、TDSQL Boundless 架构介绍
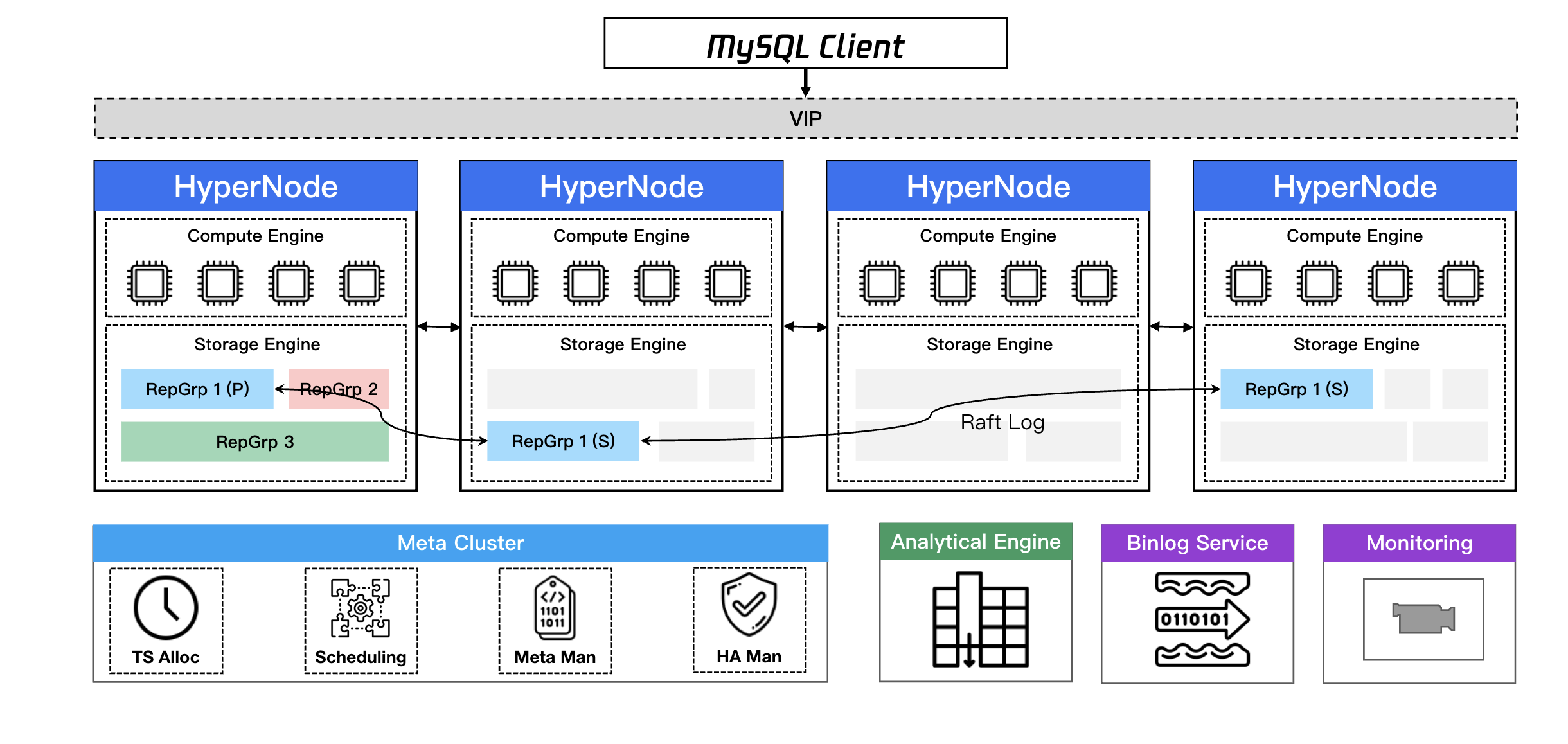
TDSQL Boundless 是腾讯面向金融级应用场景的,高性能、高可用的企业级分布式数据库解决方案,采用容器化云原生架构,提供集群高性能计算能力和低成本海量存储。
TDSQL Boundless 架构和功能特性:全分布式 + 存算一体/存算分离 + 数据面/控制面分离 + 高可扩展 + 全局一致性 + 高压缩率。
三、TDSQL Boundless 中的锁
TDSQL Boundless 作为典型的分布式系统,不仅单个节点内要有并发访问控制的机制,跨多节点仍要确保满足互斥性(Mutual Exclusion),以防止多节点同时修改同一资源导致数据不一致。
核心锁类型与实现层级
1. 表级锁(计算层)粗粒度锁,采用 MySQL 原生的元数据锁(Metadata Lock, MDL),用于在单节点内解决 DDL/DML 之间的并发冲突问题。
2. 行级锁 & 范围锁(存储层)细粒度锁,防止多会话并发修改同一记录,实现精准并发控制。
3. 全局对象锁(计算层申请,TDMC 层持久化)计算层的表级锁用于在单节点内阻塞并发的 DDL 操作,而跨节点间 DDL 的协调则通过全局对象锁来发挥作用,也属于表级锁。
表级锁作用于计算层,其冲突场景可细分为同节点与跨节点两类,以下将逐一分析两种场景下的具体冲突情况。
表级锁冲突
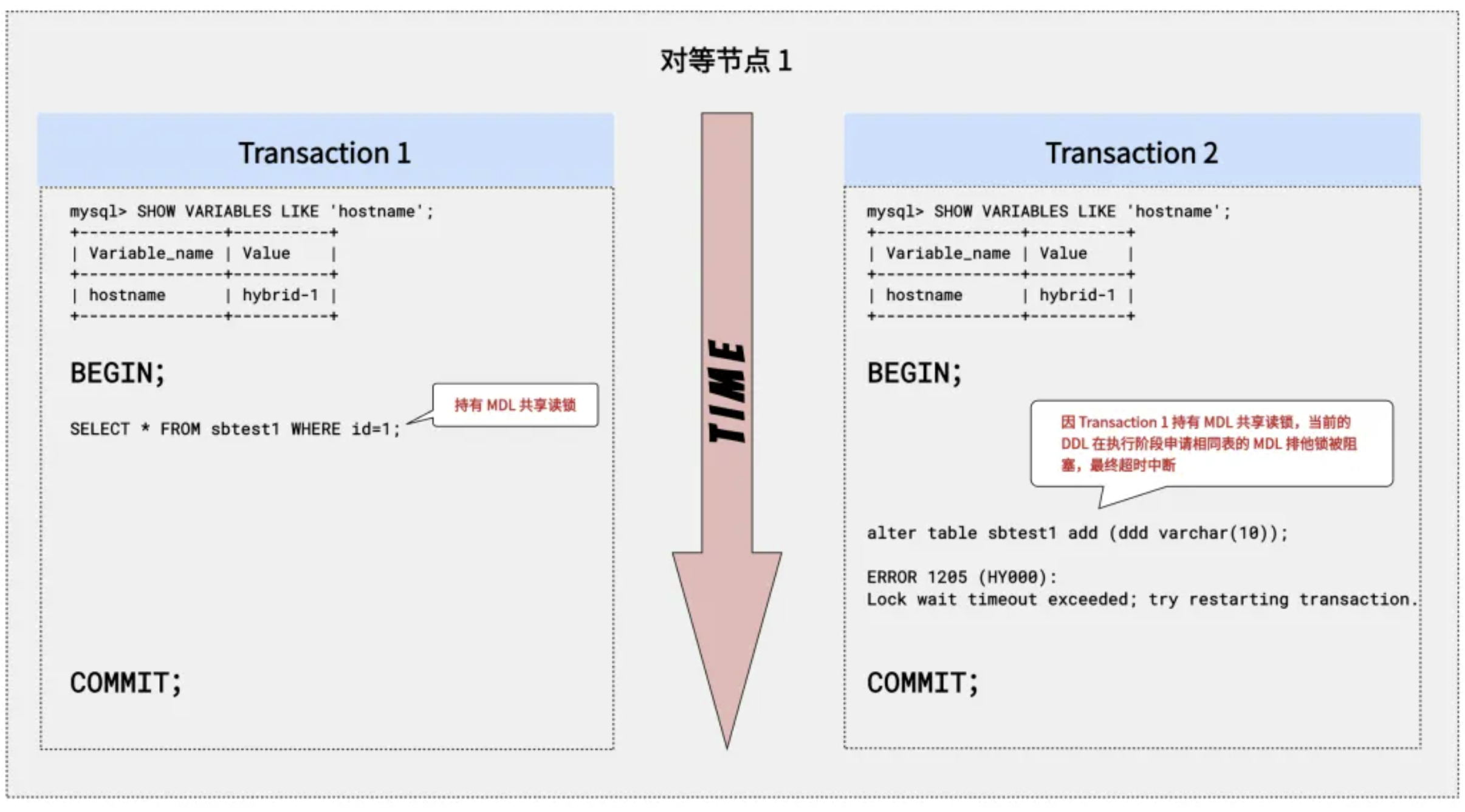
1. 同节点 DDL-DML 冲突
以下例子中,假设 Transaction 1 和 Transaction 2 都连到同一对等节点 hybrid-1 上。Transaction 1 显式开启事务查询表 sbtest1,在事务结束前持有该表的 MDL 共享读锁【表级锁】;在 Transaction 1 还未结束时,Transaction 2 执行 DDL 就会被阻塞,保护了表 sbtest1 的元数据。
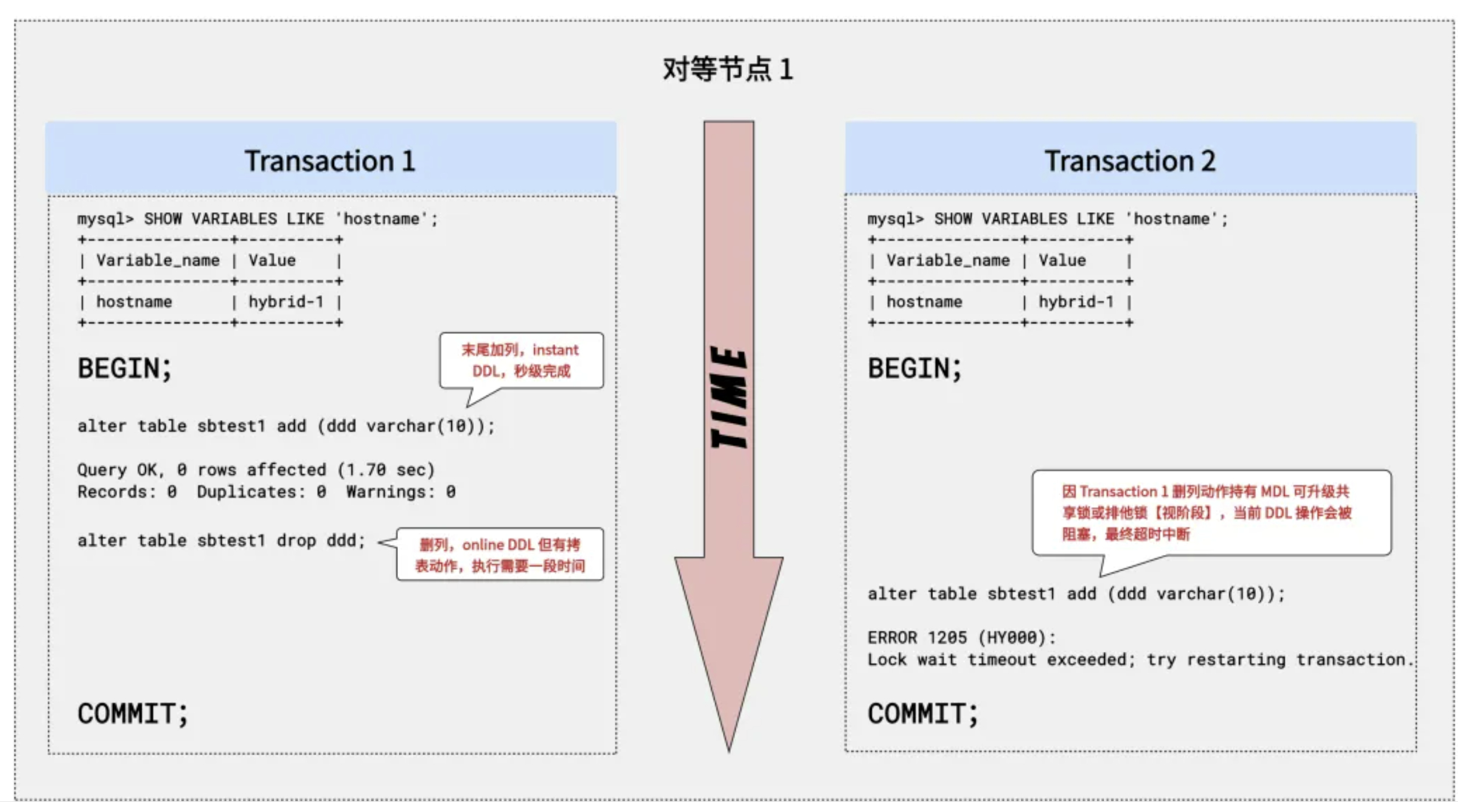
2. 同节点 DDL-DDL 冲突
同样的,还是假设 Transaction 1 和 Transaction 2 都连到同一对等节点 hybrid-1 上。Transaction 1 正在表 sbtest1 进行 DDL 操作,分阶段持有该表的 MDL 共享锁和排他锁【表级锁】,避免后来的 Transaction 2 的 DDL 破坏表 sbtest1 的元数据。
在同一对等节点上,DDL 和 DML 是平等的,谁先拿到 MDL 锁谁就执行,没有优先之分,MDL 锁是进程中的内存状态。而 TDSQL Boundless 是一个分布式数据库,会话连接进来会均匀打散在所有的节点上,如果连到两个不同对等节点的会话对同一张表执行操作,会是怎样呢?
3. 跨节点 DDL-DML 冲突
我们来看下面这个例子,Transaction 1 和 Transaction 2 分别连到对等节点 hybrid-1、hybrid-2。
Transaction 1 显式开启事务查询表 sbtest1,Transaction 2 之后在另一个节点 hybrid-2 上执行 DDL 成功(因为在这个节点上没有其他会话访问表 sbtest1,不存在锁冲突),并将表 sbtest1 的 schema version 推高;
之后 Transaction 1 继续执行查询表 sbtest1 报错,因为对于Repeatable Read 隔离级别而言,只会在事务第一次查询时生成一致性视图(Consistent Read View),如果返回新版本表结构下的记录与这一点是相违背的,因此会报错 ERROR 1412 并提示事务重试(业务程序在捕获该 Exception 时应执行 rollback 并重试事务)。

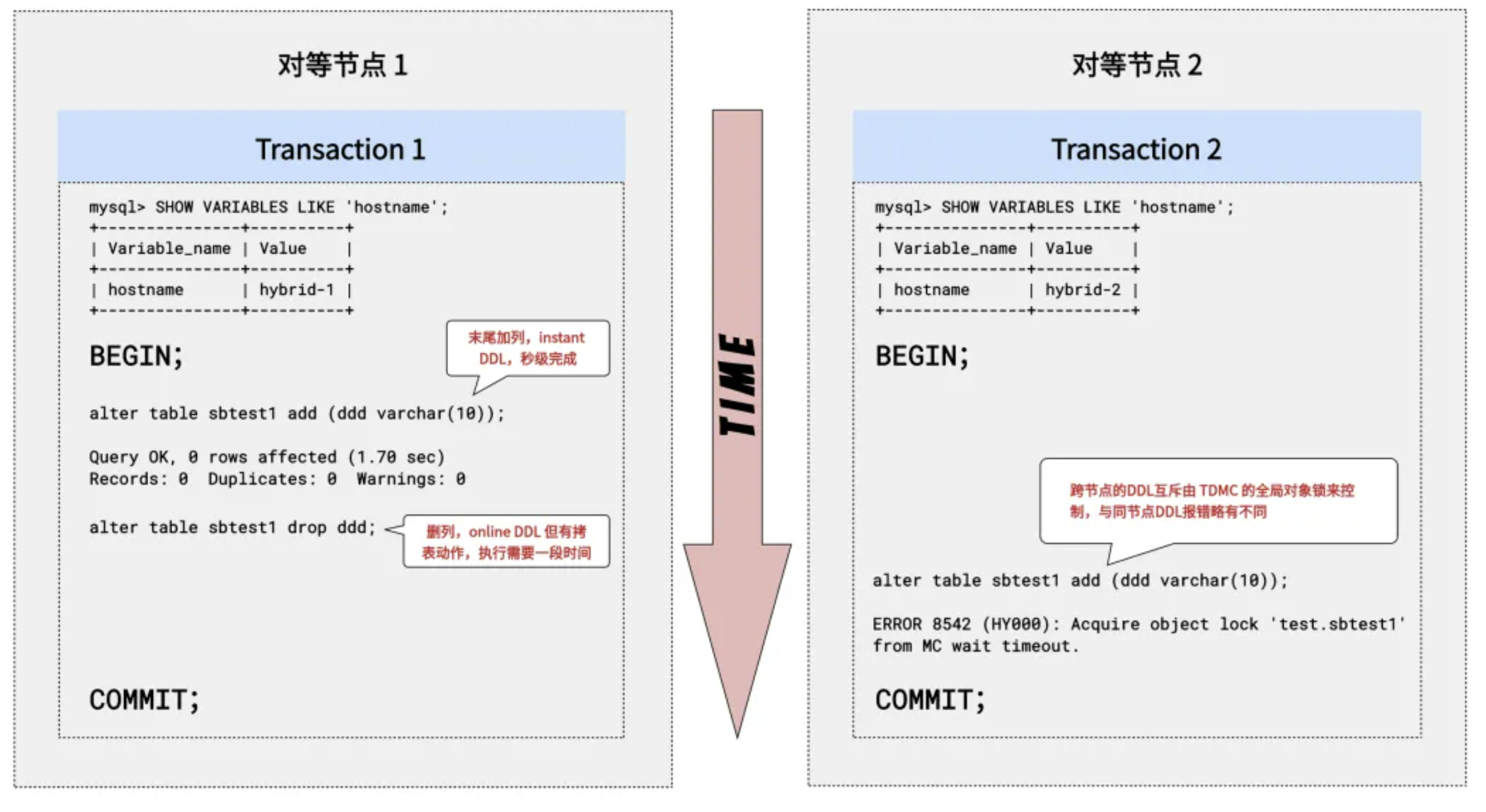
4. 跨节点 DDL-DDL 冲突
跨节点的 DDL 操作依赖于 TDMC 层的全局对象锁机制来实现操作的互斥性,确保分布式环境下的数据一致性与操作有序。
以下例子展示的还是同一张表的 DDL 相互阻塞,和之前区别的地方在于是在不同的节点上执行,这时互斥性不是由节点级的 MDL 锁来保护,而是通过 TDMC 的全局对象锁来保护。
行级锁 & 范围锁作用于存储层,当两个会话发生行锁或范围冲突,说明最终都访问了相同存储节点的主副本。因此无论其会话所连 SQLEngine 是不是同节点,都是相同的结果。以下将分析范围锁、行级锁,以及比较特殊的行级锁-死锁的具体冲突情况。
范围锁冲突
如果是对表的一段范围进行操作,TDSQL Boundless 存储层会加范围锁(range lock),锁的范围是左闭右开的一段 key 区间,在 Repeatable Read 隔离级别下同 InnoDB 的 next-key lock 行为类似。
以下例子展示在可重复读(Repeatable Read) 隔离级别下,对 id 范围 [5, 11] 进行更新时会对 id 范围的间隙上锁,以避免有新记录插入导致幻读。
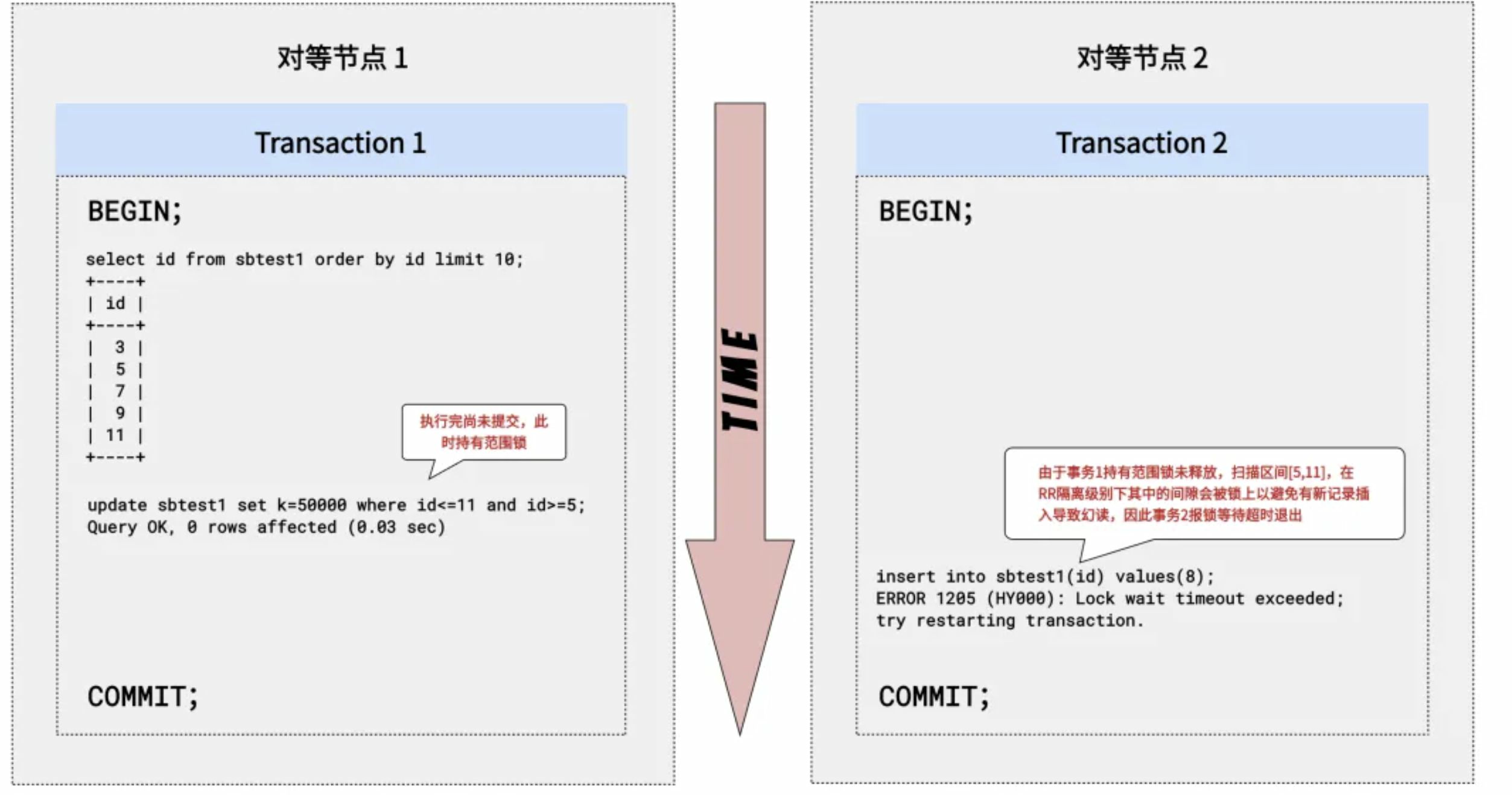
行级锁冲突
如果是对表的单个 key 进行操作,则加的是行级锁,TDSQL Boundless 通过精细化的锁机制将数据库的并发能力尽力最大化。
具体例子就不再列举了,相比范围锁而言只针对单行记录加锁,大家可以自行分析一下。
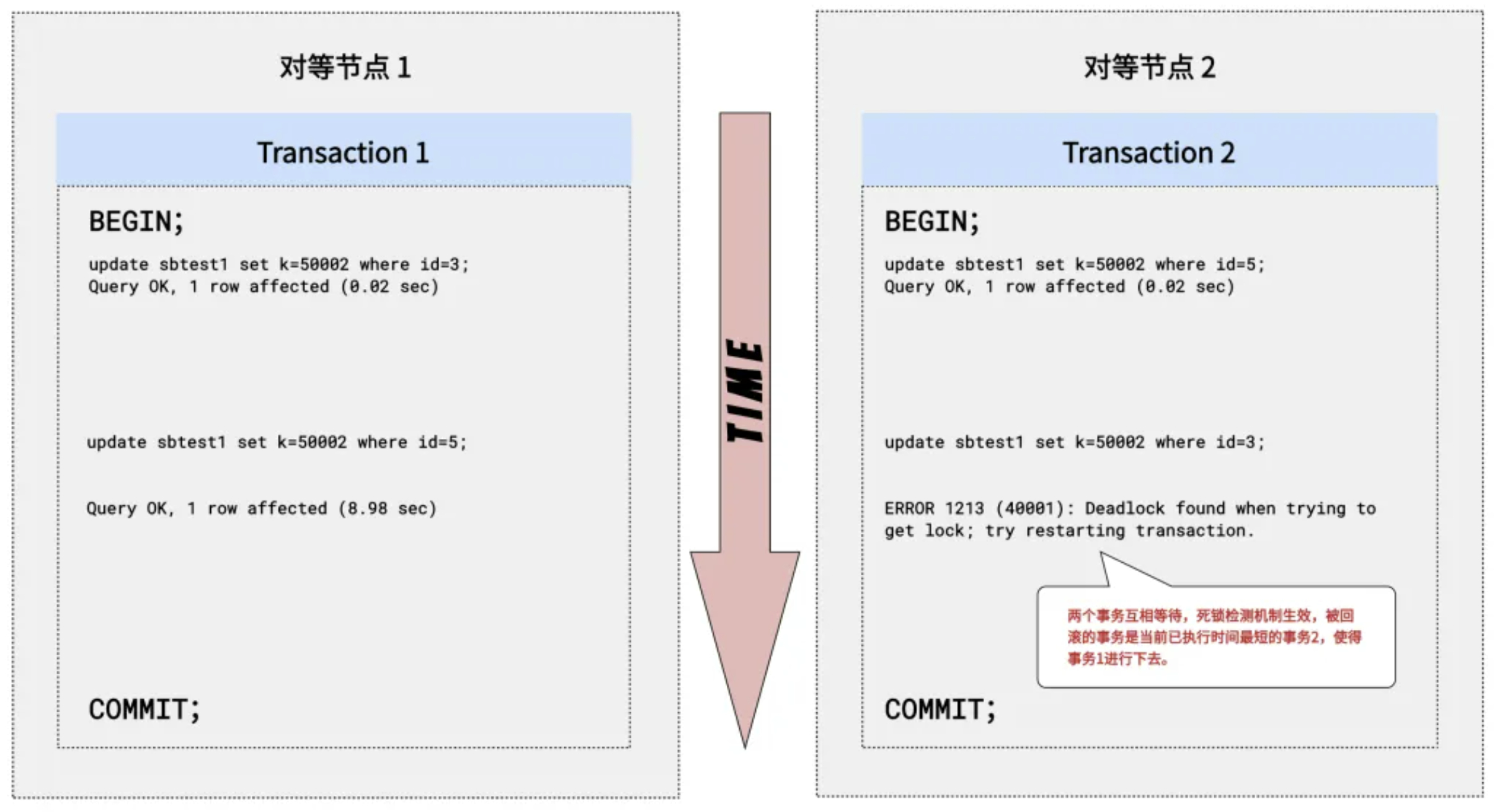
死锁冲突
死锁是行级锁冲突的一种特殊情况。当两个或多个会话等待已被对方锁定的数据时,就会发生死锁。由于双方都在等待对方,因此双方都无法完成事务来解决冲突。
TDSQL Boundless 具备自动死锁检测能力,默认回滚写数据量较少的事务并返回错误,这将释放该会话中的所有其他锁,以便另一个会话可以继续其事务。
以下例子中,Transaction 1 和 Transaction 2 互为死锁后,死锁检测机制生效,Transaction 2 被回滚,Transaction 1 得以继续执行。
存储层有没有表级锁?
InnoDB 提供表级别的 S 锁、X 锁,但其实非常“鸡肋”,它们并不会提供额外的保护,只会降低并发能力而已。因此 TDStore 存储层没有实现表级锁,仅支持语法解析,实际并没有起作用:
locktables sbtest1 read;Query OK,0rows affected,1 warning (0.02 sec)showwarnings;+---------+------+-----------------------------------------------------------------------------------+|Level| Code | Message |+---------+------+-----------------------------------------------------------------------------------+| Warning |8533|LOCK/UNLOCKoptionis used for compatibility only,and it does not actually work.|+---------+------+-----------------------------------------------------------------------------------+
四、最佳实践
锁超时和死锁是高并发数据库系统中的常见问题,有效的锁管理需要从业务逻辑、数据库配置和 troubleshooting 三个维度进行系统性优化。
业务逻辑
事务设计是预防锁问题的首要环节。坚持“短事务、轻操作、顺序访问”三大原则,可有效降低锁冲突概率。
1. 应尽量缩短事务执行时间。如单次事务操作的行数控制在2000以内。事务中包含的 SQL 语句越多、操作行数越大,持锁时间就越长,与其他事务的冲突概率就越高。
2. 避免在事务中进行用户交互,仅保留核心数据操作在事务中执行,确保事务快速完成并释放资源。
3. 确保事务中资源访问的顺序一致性。当多个事务需要访问多个资源时,必须按统一顺序访问这些资源,这是预防死锁的关键。例如,在库存扣减和订单创建的事务中,所有事务都应先锁定库存表再锁定订单表,或者相反,但绝不能有的事务先锁库存后锁订单,有的事务顺序相反,避免形成循环等待。
4. TDSQL Boundless 已经支持大多数场景下的 Online DDL 能力,但 DDL 操作发起前仍建议检查下,参考 OnlineDDL 说明,另建议在业务低峰期操作。
数据库配置
其次,针对生产系统在发生锁等待超时场景时,应优先核查相关参数的配置是否合理。针对由旧版本升级上来的实例,需特别关注后续版本新增的锁控制参数是否因兼容性需求保持关闭,必要时手动启用。
数据库相关参数:
1. tdsql_lock_wait_timeout:控制锁等待的最大时间,默认值为50秒。在上述图例中的场景演示中,被阻塞的会话如果在50秒内仍没法拿到锁,就会报错“Lock wait timeout exceeded”。一般无需调整默认值,如果业务有比较严重的锁冲突,无法迅速解决则可以适当调低该值来应急。
2. tdstore_deadlock_detect(需超级管理员权限):死锁自动检测功能。新购实例默认值为ON,建议保持开启状态。从老版本升级上来的实例则默认关闭,如有需要可手工开启。
3. tdstore_deadlock_victim(需超级管理员权限):当死锁发生时,决定选取哪个事务回滚【在 tdstore_deadlock_detect 死锁检测功能开启时,该参数才生效】。默认值为 “WRITE_LEAST” ,与 InnoDB 行为保持一致。一般无需调整默认值,当设置为 “WRITE_LEAST” 时,优先选取写数据量较少的事务回滚;当设置为 “START_LATEST” 时,优先选取较晚开启的事务回滚。
troubleshooting
第三章通过案例对比直观呈现了 TDSQL Boundless 在节点内与跨节点场景下的 DDL/DML 冲突处理机制。实际业务场景中的报错就分为两类:DDL 超时失败或 DML 超时失败。通过以下步骤进行排查与处理。
说明:
1. DDL 超时失败:
如果 DDL 执行报错“Lock wait timeout exceeded”,则表明执行 DDL 的会话被同节点的 DML 或 DDL 阻塞;如果 DDL 执行报错ERROR 8542 (HY000): Acquire object lock 'test.sbtest1' from MC wait timeout,sql-node: node-tdsql3-xxxxxxxx-xxx,则表明执行 DDL 的会话被其他节点上的 DDL 阻塞。
可以通过查询 performance_schema.metadata_locks 查看当前节点 SQLEngine MDL 锁的占用情况【TDSQL Boundless 中不需要将 performance_schema 系统变量设置为 ON】
# 确认 session1、session2 连在同一节点# 如果不是连在同一节点上,ddl是可以执行成功的,参考“跨节点 DDL-DML 冲突”show variables like'hostname';#session1BEGIN;UPDATE sbtest1 SET k =0WHERE id =999;#session2ALTERTABLE sbtest1 ADDCOLUMN new_column VARCHAR(255);#查看 metadata_locks,可以看到:#第一行LOCK_STATUS=GRANTED的记录正是 session1,表示已获得 MDL 锁;#第二行LOCK_STATUS=PENDING的记录正是 session2,表示获取 MDL 锁被挂起。#需要在开头加上 broadcast HINT 指定在所有节点广播查询。/*#broadcast*/select*from performance_schema.metadata_locks where OBJECT_NAME='sbtest1' \\G***************************1.row***************************OBJECT_TYPE: TABLEOBJECT_SCHEMA: testOBJECT_NAME: sbtest1COLUMN_NAME: NULLOBJECT_INSTANCE_BEGIN: 140384374661472LOCK_TYPE: SHARED_WRITELOCK_DURATION: TRANSACTIONLOCK_STATUS: GRANTEDSOURCE: sql_parse.cc:6373OWNER_THREAD_ID: 4879164OWNER_EVENT_ID: 1***************************2.row***************************OBJECT_TYPE: TABLEOBJECT_SCHEMA: testOBJECT_NAME: sbtest1COLUMN_NAME: NULLOBJECT_INSTANCE_BEGIN: 140375267009376LOCK_TYPE: SHAREDLOCK_DURATION: EXPLICITLOCK_STATUS: PENDINGSOURCE: ddl_executer.cc:245OWNER_THREAD_ID: 4879122OWNER_EVENT_ID: 12rowsinset(0.02 sec)#当查询多次都发现 LOCK_STATUS: GRANTED 的会话一直没有变化时,可通过 OWNER_THREAD_ID 定位到持有锁的线程所对应的 SESSION ID,在确认该会话可安全终止后,先通过 KILL 命令结束该会话,再重新发起 DDL 操作。/*#broadcast*/select*from performance_schema.threads where THREAD_ID=4879164\\G***************************1.row***************************THREAD_ID: 4879164NAME: thread/sql/one_connectionTYPE: FOREGROUNDPROCESSLIST_ID: 2346946PROCESSLIST_USER: xxxxxPROCESSLIST_HOST: xxx.xxx.xxx.xxxPROCESSLIST_DB: testPROCESSLIST_COMMAND: SleepPROCESSLIST_TIME: 1330PROCESSLIST_STATE:PROCESSLIST_INFO:PARENT_THREAD_ID:ROLE:INSTRUMENTED: YESHISTORY: YESCONNECTION_TYPE: TCP/IPTHREAD_OS_ID: 45448RESOURCE_GROUP:SQLEngine_id: node-tdsql3-***-0021rowinset(0.02 sec)#KILL 持锁者(LOCK_STATUS: GRANTED 会话)#session1 被杀#session2ALTERTABLE sbtest1 ADDCOLUMN new_column VARCHAR(255);Query OK,0rows affected (1.67 sec)Records: 0 Duplicates: 0 Warnings: 0
2. DML 超时失败:
如果 DML 执行报错“Lock wait timeout exceeded”,基本上是获取不到行级锁或是遇到了死锁。针对一路升级上来的老实例,首先建议检查死锁自动检测功能,如果是未打开状态,建议开启(无需重启),之后如再遇到死锁系统会自动解开。
如仍然有锁超时问题,使用如下方法识别持有锁(Lock Holder)的会话 ID,通过 KILL 终止阻塞会话,释放行锁资源,使等待会话(Lock Waiter)得以继续执行。
可以通过查询 performance_schema.data_locks、performance_schema.data_lock_waits 查看 TDStore 持有锁和等待锁的会话信息【TDStore 中不需要将 performance_schema 系统变量设置为 ON】
# 这里 session1、session2 无论是否连到同一节点,结果都是一样的;因为行锁是存储层的,两个会话发生行锁冲突,说明最终都访问了相同存储节点的主副本#session1SELECT id FROM sbtest1 ORDERBY id limit10;+----+| id |+----+|1||3||5||7||9||11||12||13||14||15|+----+10rowsinset(9.23 sec)BEGIN;UPDATE sbtest1 SET k=50000WHERE id<=11AND id>=5;#session2INSERTINTO sbtest1(id) VALUES(8);#查询当前节点上,持锁者(Lock Holder)的悲观锁信息。#先查询 data_lock_waits 表,获取 BLOCKING_ENGINE_LOCK_ID 字段【悲观锁ID】;再根据该字段值去查询 data_locks 表,获取持锁者信息。#TDStore 的 range lock 左闭右开,可以看到列 ENGINE_LOCK_ID 中显示为 [5,12) 区间。SELECT * FROM performance_schema.data_lock_waits\\G*************************** 1. row ***************************ENGINE: RocksDBREQUESTING_ENGINE_LOCK_ID: 29746913880309907_000082E380000008REQUESTING_NODE_ID: 3REQUESTING_NODE_NAME: node-tdsql3-***-003REQUESTING_ENGINE_TRANSACTION_ID: 29746913880309907REQUESTING_THREAD_ID: 428330REQUESTING_EVENT_ID: 0REQUESTING_OBJECT_INSTANCE_BEGIN: 140197932217896BLOCKING_ENGINE_LOCK_ID: 29746911900598447_[000082E380000005,000082E38000000C)BLOCKING_NODE_ID: 1BLOCKING_NODE_NAME: node-tdsql3-***-001BLOCKING_ENGINE_TRANSACTION_ID: 29746911900598447BLOCKING_THREAD_ID: 592422BLOCKING_EVENT_ID: 0BLOCKING_OBJECT_INSTANCE_BEGIN: 140197201734928TINDEX_ID: 33507DATA_SPACE_TYPE: DATA_SPACE_TYPE_USERREPLICATION_GROUP_ID: 868437KEY_RANGE_REGION_ID: 41824091 row in set (0.03 sec)SELECT data_locks.* FROM performance_schema.data_locks WHERE engine_lock_id='29746911900598447_[000082E380000005,000082E38000000C)'\\G*************************** 1. row ***************************ENGINE: RocksDBENGINE_LOCK_ID: 29746911900598447_[000082E380000005,000082E38000000C)ENGINE_TRANSACTION_ID: 29746911900598447THREAD_ID: 592422EVENT_ID: NULLOBJECT_SCHEMA:OBJECT_NAME:PARTITION_NAME: NULLSUBPARTITION_NAME: NULLINDEX_NAME: NULLOBJECT_INSTANCE_BEGIN: 140197201734928LOCK_TYPE: PRE_RANGELOCK_MODE: WriteLOCK_STATUS: GRANTEDLOCK_DATA: NULLSTART_KEY: 000082E380000005END_KEY: 000082E38000000CEXCLUDE_START_KEY: 0BLOCKING_TRANSACTION_NUM: 1BLOCKING_CHECK_READ_TRANSACTION_NUM: 0READ_LOCKED_NUM: 0TINDEX_ID: 33507DATA_SPACE_TYPE: DATA_SPACE_TYPE_USERREPLICATION_GROUP_ID: 868437KEY_RANGE_REGION_ID: 4182409PROCESSLIST_ID: 1693568NODE_ID: 1NODE_NAME: node-tdsql3-***-0011 row in set (0.03 sec)# 查看持锁者(Lock Holder)的会话信息。# 说明:data_locks 表中的 THREAD_ID 为 Performance Schema 的内部线程 ID。如需查询对应的会话信息,请使用 PROCESSLIST_ID 字段关联 information_schema.processlist 表。此外,NODE_ID 和 NODE_NAME 字段可用于定位该事务所在的 SQLEngine 节点。select * from information_schema.processlist where id=1093359\\G***************************1.row***************************ID: 1093359USER: tdsql_adminHOST: xxx.xxx.xxx.xxx:35956DB: testCOMMAND: SleepTIME: 946STATE: NULLINFO: NULLTIME_MS: 945727ROWS_SENT: 0ROWS_EXAMINED: 41rowinset(0.12 sec)#KILL 持锁者(Lock Holder)后,阻塞会话执行成功。#session1 被杀#session2INSERTINTO sbtest1(id)VALUES(8);Query OK,1row affected (43.78 sec)#注意:高并发场景下,可能等待会话(Lock Waiter)队列比较长,这样可能又会再次出现持锁者(Lock Holder),可能需要多杀几次。
文档反馈