CDH (Cloudera's distribution, including Apache Hadoop) is one of the most popular Hadoop distributions in the industry. This document describes how to use the COSN storage service in a CDH environment to separate big data computing from storage.
Note:
COSN refers to the Hadoop-COS file system.
Currently, the support for big data modules by COSN is as follows:
Module
Supported
Service Module to Restart
YARN
Yes
NodeManager
Hive
Yes
HiveServer and HiveMetastore
Spark
Yes
NodeManager
Sqoop
Yes
NodeManager
Presto
Yes
HiveServer, HiveMetastore, and Presto
Flink
Yes
None
Impala
Yes
None
EMR
Yes
None
Self-built component
To be supported in the future
No
HBase
Not recommended
None
Versions
This example uses software versions as follows:
CDH 5.16.1
Hadoop 2.6.0
How to Use
Configuring storage environment
1. Log in to the CDH management page.
2. On the homepage, select Configuration > Service-Wide > Advanced as shown below:
3. Specify your COSN settings in the configuration snippet Cluster-wide Advanced Configuration Snippet(Safety Valve) for core-site.xml.
<property>
<name>fs.cosn.userinfo.secretId</name>
<value>AK***</value>
</property>
<property>
<name>fs.cosn.userinfo.secretKey</name>
<value></value>
</property>
<property>
<name>fs.cosn.impl</name>
<value>org.apache.hadoop.fs.CosFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.cosn.impl</name>
<value>org.apache.hadoop.fs.CosN</value>
</property>
<property>
<name>fs.cosn.bucket.region</name>
<value>ap-shanghai</value>
</property>
The following lists the required COSN settings (to be added to core-site.xml). For other settings, see Hadoop.
COSN Configuration Item
Value
Description
fs.cosn.userinfo.secretId
AKxxxx
API key information of the account
fs.cosn.userinfo.secretKey
Wpxxxx
API key information of the account
fs.cosn.bucket.region
ap-shanghai
Bucket region
fs.cosn.impl
org.apache.hadoop.fs.CosFileSystem
The implementation class of COSN for FileSystem, which is fixed at `org.apache.hadoop.fs.CosFileSystem`
fs.AbstractFileSystem.cosn.impl
org.apache.hadoop.fs.CosN
The implementation class of COSN for AbstractFileSystem, which is fixed at `org.apache.hadoop.fs.CosN`
4. Take action on your HDFS service by clicking. Now, the core-site.xml settings above will apply to servers in the cluster.
5. Place the latest SDK package of COSN in the path of the JAR package of the CDH HDFS service and replace the relevant information with the actual value as shown below:
(1) Configure HDFS settings as instructed in Data migration and put the JAR file of the COSN SDK in the correct HDFS directory.
(2) On the CDH homepage, find YARN and restart the NodeManager service (recommended). You can choose not to restart it for the TeraGen command, but must restart it for the TeraSort command because of the internal business logic.
Sample
The example below shows TeraGen and TeraSort in Hadoop standard test:
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.job.maps=500 -Dfs.cosn.upload.buffer=mapped_disk -Dfs.cosn.upload.buffer.size=-1 1099 cosn://examplebucket-1250000000/terasortv1/1k-input
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.max.split.size=134217728 -Dmapred.min.split.size=134217728 -Dfs.cosn.read.ahead.block.size=4194304 -Dfs.cosn.read.ahead.queue.size=32 cosn://examplebucket-1250000000/terasortv1/1k-input cosn://examplebucket-1250000000/terasortv1/1k-output
Note:
cosn:// Replace the content behind schema` with your own bucket path
2. Hive
2.1 MR engine
Directions
(1) Configure HDFS settings as instructed in Data migration and put the JAR file of the COSN SDK in the correct HDFS directory.
(2) On the CDH homepage, find Hive and restart the HiveServer2 and HiveMetastore roles.
Sample
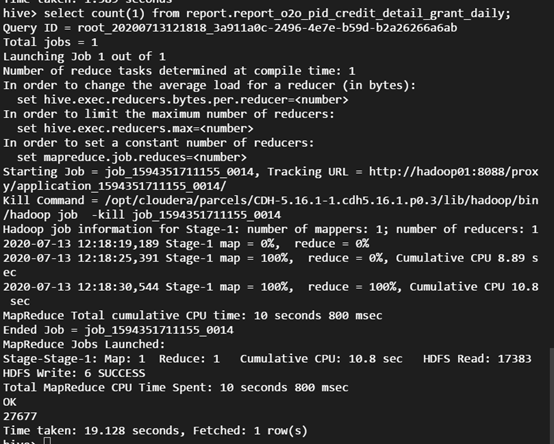
To query your actual business data, use the Hive command line to create a location as a partitioned table on CHDFS:
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
The output is as shown below:
2.2 Tez engine
You need to import the COSN JAR file as part of a Tez tar.gz file. The following example uses apache-tez.0.8.5:
Directions
(1) Locate and decompress the Tez tar.gz file installed in the CDH cluster, e.g., /usr/local/service/tez/tez-0.8.5.tar.gz.
(2) Put the COSN JAR file in the resulting directory, and then compress it into a new tar.gz file.
(3) Upload this new file to the path as specified by tez.lib.uris, or simply replace the existing file with the same name.
(4) On the CDH homepage, find Hive and restart HiveServer and HiveMetaStore.
3. Spark
Directions
(1) Configure HDFS settings as instructed in Data migration and put the JAR file of the COSN SDK in the correct HDFS directory.
(2) Restart NodeManager.
Sample
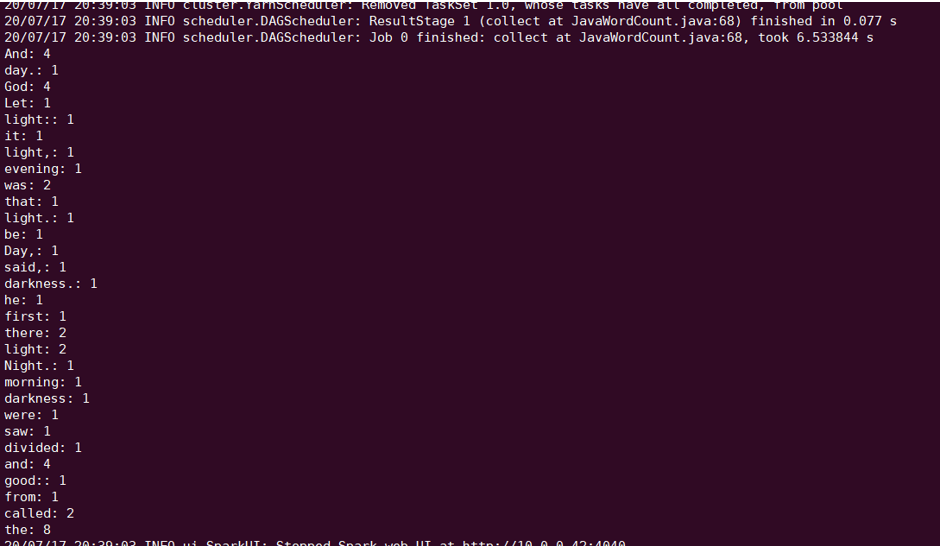
The following takes the Spark example word count test conducted with COSN as an example.
(1) Configure HDFS settings as instructed in Data migration and put the JAR file of the COSN SDK in the correct HDFS directory.
(2) Put the JAR file of the COSN SDK in the Presto directory, for example, /usr/local/services/cos_presto/plugin/hive-hadoop2.
(3) Presto does not load the gson-2...jar JAR file (only used for CHDFS) from Hadoop Common, so you need to manually put it into the presto directory, for example, /usr/local/services/cos_presto/ plugin/hive-hadoop2.
(4) Restart HiveServer, HiveMetaStore, and Presto.
Sample
The example below queries the COSN scheme table as a Hive-created location:
select * from cosn_test_table where bucket is not null limit 1;
Note:
cosn_test_table is a table with location as cosn scheme.