COSDistCp
Download
Mode fokus
Ukuran font
Feature Overview
COSDistCp is a MapReduce-based distributed file copy tool mainly used for data copy between HDFS and COS. It introduces the following features:
Performs incremental file migration and data verification based on length and CRC checksum.
Filters files in the source directory with regular expression.
Decompresses files in the source directory and compresses them to the target compression format.
Aggregates text files based on a regular expression.
Preserves user/user group, extension attributes, and time of the source file and directory.
Configures alarms and Prometheus monitoring.
Collects the statistics of file size distribution.
Limits the read bandwidth.
Operating Environments
Operating system
Linux
Software dependency
Hadoop 2.6.0 or above; Hadoop-COS 5.9.3 or above.
Download and Installation
Obtaining the COSDistCp JAR package
If your Hadoop version is 2.x, you can download cos-distcp-1.13-2.8.5.jar and verify the integrity of the downloaded JAR package according to the MD5 checksum of the package.
If your Hadoop version is 3.x, you can download cos-distcp-1.13-3.1.0.jar and verify the integrity of the downloaded JAR package according to the MD5 checksum of the package.
Installation notes
You can download the corresponding versions of COSDistCp, Hadoop-COS, and cos_api-bundle JAR packages from download addresses listed above according to the Hadoop version. Then, specify the Hadoop-COS-related parameters to perform the copy operation, where the JAR package addresses should be the local addresses:
hadoop jar cos-distcp-${version}.jar \\-libjars cos_api-bundle-${version}.jar,hadoop-cos-${version}.jar \\-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \\-Dfs.cosn.userinfo.secretId=COS_SECRETID \\-Dfs.cosn.userinfo.secretKey=COS_SECRETKEY \\-Dfs.cosn.bucket.region=ap-guangzhou \\-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \\-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \\--src /data/warehouse \\--dest cosn://examplebucket-1250000000/warehouse
How It Works
COSDistCp uses the MapReduce framework. The multi-process and multi-thread tool performs operations such as file copy, data verification, compression, file attribute preservation, and copy retries. COSDistCp will overwrite files with the same name in the destination location. If data copy or verification fails, the corresponding file may fail to be copied and information about these files will be written in a temporary directory. If new files are added to your source file system or the file content changes, you can use the
--skipMode or --diffMode parameter to compare the length or CRC checksum of the files to implement data verification and incremental file migration.Parameter description
You can run the hadoop jar cos-distcp-${version}.jar --help (${version} is the version number) command under the hadoop user to view the COSDistCp-supported parameters. The following table describes the parameters of the COSDistCp of the current version:
Attribute Key | Description | Default Value | Required |
--help | Outputs parameters supported by COSDistCp.
Example: --help | None | No |
--src=LOCATION | Location of the data to copy. This can be either an HDFS or COS location.
Example: --src=hdfs://user/logs/ | None | Yes |
--dest=LOCATION | Destination for the data. This can be either an HDFS or COS location.
Example: --dest=cosn://examplebucket-1250000000/user/logs | None | Yes |
--srcPattern=PATTERN | A regular expression that filters files in the source location.
Example: --srcPattern='.*\\.log$'
*Note: Enclose your parameter in single quotation marks (') in case asterisks () are parsed by the shell.** | None | No |
--taskNumber=VALUE | Number of copy threads
Example: --taskNumber=10 | 10 | No |
--workerNumber=VALUE | Number of copy threads. COSDistCp will create a copy thread pool for each copy process based on this value set.
Example: workerNumber=4 | 4 | No |
--filesPerMapper=VALUE | The number of files input to each mapper.
Example: --filesPerMapper=10000 | 500000 | No |
--groupBy=PATTERN | A regular expression to concatenate text files that match the regular expression.
Example: --groupBy='.*group-input/(\\d+)-(\\d+).*' | None | No |
--targetSize=VALUE | The size (in MB) of the files to create. This parameter is used together with --groupBy.
Example: --targetSize=10 | None | No |
--outputCodec=VALUE | Compression method of output file. Valid values: gzip, lzo, snappy, none, keep. Here:
1. keep indicates to keep the compression method of the original file.
2. none indicates to decompress the file based on the file extension.
Example: --outputCodec=gzip
Note: if the /dir/test.gzip and /dir/test.gz files exist, and you specify the output format as lzo, only /dir/test.lzo will be retained. | keep | No |
--deleteOnSuccess | Deletes the source file immediately after it is successfully copied to the destination directory.
Example: --deleteOnSuccess
Note: v1.7 and later no longer provide this parameter. We recommend you delete the data in the source file system after migrating the data successfully and using --diffMode for verification. | false | No |
--multipartUploadChunkSize=VALUE | The size (in MB) of the multipart upload part transferred to COS using the Hadoop-COS plugin. COS supports up to 10,000 parts. You can set the value based on the file size.
Example: --multipartUploadChunkSize=20 | 8 MB | No |
--cosServerSideEncryption | Specifies whether to use SSE-COS for encryption on the COS server side.
Example: --cosServerSideEncryption | false | No |
--outputManifest=VALUE | Creates a file (Gzip compressed) that contains a list of all files copied to the destination location.
Example: --outputManifest=manifest.gz | None | No |
--requirePreviousManifest | If this parameter is set to true, --previousManifest=VALUE must be specified for incremental copy.
Example: --requirePreviousManifest | false | No |
--previousManifest=LOCATION | A manifest file that was created during the previous copy operation.
Example: --previousManifest=cosn://examplebucket-1250000000/big-data/manifest.gz | None | No |
--copyFromManifest | Copies files specified in --previousManifest to the destination file system. This is used together with previousManifest=LOCATION.
Example: --copyFromManifest | false | No |
--storageClass=VALUE | The storage class to use. Valid values: STANDARD, STANDARD_IA, ARCHIVE, DEEP_ARCHIVE, and INTELLIGENT_TIERING. For more information, see Storage Class Overview. | None | No |
--srcPrefixesFile=LOCATION | A local file that contains a list of source directories, one directory per line.
Example: --srcPrefixesFile=file:///data/migrate-folders.txt | None | No |
--skipMode=MODE | Verifies whether the source and destination files are the same before the copy. If they are the same, the file will be skipped. Valid values are none (no verification), length, checksum, length-mtime, and length-checksum.
Example: --skipMode=length | length-checksum | No |
--checkMode=MODE | Verifies whether the source and destination files are the same when the copy is completed. Valid values are none (no verification), length, checksum, length-mtime, and length-checksum.
Example: --checkMode=length-checksum | length-checksum | No |
--diffMode=MODE | Specifies the rule for obtaining the list of different files in the source and destination directories. Valid values are length, checksum, length-mtime, and length-checksum.
Example: --diffMode=length-checksum | None | No |
--diffOutput=LOCATION | Specifies the HDFS output directory in diffMode. This directory must be empty.
Example: --diffOutput=/diff-output | None | No |
--cosChecksumType=TYPE | Specifies the CRC algorithm used by the Hadoop-COS plugin. Valid values are CRC32C and CRC64.
Example: --cosChecksumType=CRC32C | CRC32C | No |
--preserveStatus=VALUE | Specifies whether to copy the user, group, permission, xattr, and timestamps metadata of the source file to the destination file. Valid values are any combinations of letters u, g, p, x, and t (initials of user, group, permission, xattr, and timestamps, respectively).
Example: --preserveStatus=ugpt | None | No |
--ignoreSrcMiss | Ignores files that exist in the manifest file but cannot be found during the copy. | false | No |
--promGatewayAddress=VALUE | Specifies the Prometheus PushGateway address and port for pushing the counter data of MapReduce jobs. | None | No |
--promGatewayDeleteOnFinish=VALUE | Whether to delete JobName metrics from Prometheus PushGateway when the specified job is completed.
Example: --promGatewayDeleteOnFinish=true | true | No |
--promGatewayJobName=VALUE | JobName to report to Prometheus PushGateway
Example: --promGatewayJobName=cos-distcp-hive-backup | None | No |
--promCollectInterval=VALUE | Interval to collect MapReduce jobs, in ms
Example: --promCollectInterval=5000 | 5000 | No |
--promPort=VALUE | Server port to expose Prometheus metrics
Example: --promPort=9028 | None | No |
--enableDynamicStrategy | Enables the dynamic task assignment policy to make tasks with quicker migration migrate more files.
Note: This mode has certain limits; for example, the task counter may be inaccurate if the process is abnormal. Therefore, use --diffMode to verify the data after migration.
Example: --enableDynamicStrategy | false | No |
--splitRatio=VALUE | Split ratio of the dynamic strategy. A higher splitRatio indicates a smaller job granularity.
Example: --splitRatio=8 | 8 | No |
--localTemp=VALUE | Local folder to store the job files generated by the dynamic strategy
Example: --localTemp=/tmp | /tmp | No |
--taskFilesCopyThreadNum=VALUE | Number of concurrency to copy the job files generated by the dynamic strategy to the HDFS
Example: --taskFilesCopyThreadNum=32 | 32 | No |
--statsRange=VALUE | Statistics range
Example: ---statsRange=0,1mb,10mb,100mb,1gb,10gb,inf | 0,1mb,10mb,100mb,1gb,10gb,inf | No |
--printStatsOnly | Collects only statistics on the file size distribution without copying the data.
Example: --printStatsOnly | None | No |
--bandWidth | Maximum bandwidth for reading each migrated file (in MB/s). Default value: -1, which indicates no limit on the read bandwidth.
Example: --bandWidth=10 | None | No |
--jobName | Migration task name.
Example: --jobName=cosdistcp-to-warehouse | None | No |
--compareWithCompatibleSuffix | Whether to change the source file extension gzip to gz and lzop to lzo when using the --skipMode and --diffMode parameters.
Example: --compareWithCompatibleSuffix | None | No |
--delete | Moves files that exist in the source directory but not in the target directory to the separate trash directory and generates the file list in order to ensure the file consistency between the source and target directories.
Note: This parameter cannot be used together with --diffMode. | None | No |
--deleteOutput | Specifies the HDFS output directory for delete. This directory must be empty.
Example: --deleteOutput=/dele-output | None | No |
Example
Viewing the help option
Run the following command with
--help to view the parameters supported by COSDistCp:hadoop jar cos-distcp-${version}.jar --help
In the command above,
${version} is the version ID of the COSDistCp. For example, the name of the COSDistCp JAR package (version 1.0) is cos-distcp-1.0.jar.File size distribution of the files to copy
Run the following command with the
--printStatsOnly and --statsRange=VALUE parameters to output the file size distribution of the files to copy:hadoop jar cos-distcp-${version}.jar --src /wookie/data --dest cosn://examplebucket-1250000000/wookie/data --printStatsOnly --statsRange=0,1mb,10mb,100mb,1gb,10gb,infCopy File Distribution Statistics:Total File Count: 4Total File Size: 1190133760| SizeRange | TotalCount | TotalSize || 0MB ~ 1MB | 0(0.00%) | 0(0.00%) || 1MB ~ 10MB | 1(25.00%) | 1048576(0.09%) || 10MB ~ 100MB | 1(25.00%) | 10485760(0.88%) || 100MB ~ 1024MB | 1(25.00%) | 104857600(8.81%) || 1024MB ~ 10240MB | 1(25.00%) | 1073741824(90.22%) || 10240MB ~ LONG_MAX| 0(0.00%) | 0(0.00%) |
Specifying the source and destination locations for the files to copy
Run the following command with the
--src and --dest parameters:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse
COSDistCp will retry 5 times for files that failed to be copied. If the copy still fails, these files will be written to the
/tmp/${randomUUID}/output/failed/ directory, where ${randomUUID} is a random string. After recording the failed file information, COSDistCp will continue to migrate the remaining files, and the migration task will not fail due to the migration failure of some files. When the migration task is completed, COSDistCp will output counter information (ensure that your task submitting machine is configured with INFO log output for MapReduce jobs on the submission end) and determine whether there are files that failed to be migrated, and if yes, it will throw an exception on the client that submitted the task.The following information about a source file might be contained in the output:
1. SRC_MISS: The copy fails because the source file contained in the manifest is not found.
2. COPY_FAILED: The copy fails due to other reasons.
You can run the copy command again to implement incremental migration. Run the following command to obtain the log of the MapReduce job. In this way, you can find out the cause of the copy failure. Note that
application_1610615435237_0021 is the application ID.yarn logs -applicationId application_1610615435237_0021 > application_1610615435237_0021.log
Querying counters
When the copy operation ends, statistics on the copy will be output. The counters are as follows:
CosDistCp CountersBYTES_EXPECTED=10198247BYTES_SKIPPED=10196880FILES_COPIED=1FILES_EXPECTED=7FILES_FAILED=1FILES_SKIPPED=5
The statistics are described as follows:
Statistics Item | Description |
BYTES_EXPECTED | Total size (in bytes) to copy according to the source directory |
FILES_EXPECTED | Number of files to copy according to the source directory, including the directory itself |
BYTES_SKIPPED | Total size (in bytes) of files that can be skipped (same length or checksum value) |
FILES_SKIPPED | Number of source files that can be skipped (same length or checksum value) |
FILES_COPIED | Number of source files that are successfully copied |
FILES_FAILED | Number of source files that failed to be copied |
FOLDERS_COPIED | Number of directories that are successfully copied |
FOLDERS_SKIPPED | Number of directories that are skipped |
Specifying the number of copy processes and the number of threads in each process
Run the following command with the
--taskNumber and --workersNumber parameters. COSDistCp adopts a multi-process, multi-thread framework for the copy operation. You can:Use
--taskNumber to specify the number of processes.Use
--workerNumber to specify the number of threads in each copy process.hadoop jar cos-distcp-${version}.jar --src /data/warehouse/ --dest cosn://examplebucket-1250000000/data/warehouse --taskNumber=10 --workerNumber=5
Skipping files with the same check value for incremental migration
Run the following command with the
--skipMode parameter to skip copying source files with the same length and checksum as those of destination files. The default value is length-checksum:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --skipMode=length-checksum
--skipMode is used to verify whether the source and destination files are the same before the copy. If they are the same, the file will be skipped. Valid values are none (no verification), length, checksum, and length-checksum (length + CRC checksum).If the checksum algorithms of the source and destination file systems are different, the source file will be read for calculating a new checksum. If your source is HDFS, you can identify whether the HDFS source supports the COMPOSITE-CRC32C algorithm as follows:
hadoop fs -Ddfs.checksum.combine.mode=COMPOSITE_CRC -checksum /data/test.txt/data/test.txt COMPOSITE-CRC32C 6a732798
Verifying data after migration and migrating incremental data
Run the command with the
--diffMode and --diffOutput parameters:--diffMode can be set to length or length-checksum.--diffMode=length obtains the list of different files based on whether the file sizes are the same.--diffMode=length-checksum obtains the list of different files based on whether the file size and CRC checksum are the same.--diffOutput specifies the output directory for the diff operation.
If the destination file system is COS and the CRC algorithm of the source file system is different from that of COS, COSDistCp will pull the source file to calculate the CRC checksum of the destination file system and compare the CRC checksums to check whether they are the same. In the following sample code, the --diffMode parameter is used to check whether the source and destination files are the same based on the file size and CRC checksum after migration.hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --diffMode=length-checksum --diffOutput=/tmp/diff-output
After the above command is executed successfully, the counter information based on the file list of the source file system will be output (ensure that your task submitting machine is configured with INFO log output for MapReduce jobs on the submission end). You can analyze whether the source and destination files are the same based on the counter information as detailed below:
1. SUCCESS: the source and destination files are the same.
2. DEST_MISS: The destination file does not exist.
3. SRC_MISS: The source file contained in the source file manifest is not found during the verification.
4. LENGTH_DIFF: Sizes of the source and destination files are different.
5. CHECKSUM_DIFF: CRC checksums of the source and destination files are different.
6. DIFF_FAILED: The
diff operation fails due to insufficient permissions or other reasons.7. TYPE_DIFF: the source is a directory but the destination is a file.
In addition, COSDistCp will generate a list of different files in the
/tmp/diff-output/failed directory in HDFS (or /tmp/diff-output for v1.0.5 or earlier versions). You can run the following command to obtain the list of different files except for those recorded as SRC_MISS:hadoop fs -getmerge /tmp/diff-output/failed diff-manifestgrep -v '"comment":"SRC_MISS"' diff-manifest |gzip > diff-manifest.gz
Run the following command to implement incremental copy based on the list of different files:
hadoop jar cos-distcp-${version}.jar --taskNumber=20 --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --previousManifest=file:///usr/local/service/hadoop/diff-manifest.gz --copyFromManifest
After incremental migration is completed, run the command with the
--diffMode parameter again to check whether the files are completely identical.Verifying whether the source and destination files have the same CRC checksum
Run the command with the
--checkMode parameter to check whether the source and destination files have the same length and checksum after file copy is completed. The default value is length-checksum.When you are copying files from a non-COS file system to COS, if the CRC algorithms of the source and Hadoop-COS are different, the CRC checksum will be calculated during the copy operation. When the copy operation is completed, the CRC checksum of the destination file will be obtained and compared with the calculated CRC checksum of the source file.
hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --checkMode=length-checksum
Note:
It takes effect if
--groupBy is not specified and --outputCodec is the default value.Restricting the read bandwidth for a single file
Run the command with the
--bandWidth parameter (in MB). The following example command restricts the read bandwidth of each copied file to 10 MB/s:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --bandWidth=10
Copying multiple directories
You can create a local file (for example, srcPrefixes.txt) and add the absolute paths of multiple directories to copy to the file (the directories cannot be in parent-child relationships). After this, you can run the
cat command to view the directories as follows:cat srcPrefixes.txt/data/warehouse/20181121//data/warehouse/20181122/
Then, you can use
--srcPrefixesFile to specify this file. The command is as follows:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --srcPrefixesFile file:///usr/local/service/hadoop/srcPrefixes.txt --dest cosn://examplebucket-1250000000/data/warehouse/ --taskNumber=20
Filtering source files with a regular expression
Run the following command with the
--srcPattern parameter. In this example, only files whose extension is ".log" in the /data/warehouse/ directory are copied.hadoop jar cos-distcp-${version}.jar --src /data/warehouse/ --dest cosn://examplebucket-1250000000/data/warehouse --srcPattern='.*\\.log$'
Do not copy files whose extension is ".temp" or ".tmp":
hadoop jar cos-distcp-${version}.jar --src /data/warehouse/ --dest cosn://examplebucket-1250000000/data/warehouse/ --srcPattern='.*(?<!\\.temp|\\.tmp)$'
Specifying the checksum type of Hadoop-COS
Run the following command with the
--cosChecksumType parameter. Valid values are CRC32C (default) and CRC64.hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --cosChecksumType=CRC32C
Specifying the storage class for COS objects
Run the following command with the
--storageClass parameter:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --outputManifest=manifest-2020-01-10.gz --storageClass=STANDARD_IA
Specifying the output compression codec
Run the command with the
--outputCodec parameter, which allows you to compress HDFS data to COS in real time to reduce storage costs. Valid values are keep, none, gzip, lzop, and snappy. If the parameter is set to none, the files will be copied uncompressed. If it is set to keep, the files will be copied with no change in their compression. The following is an example:hadoop jar cos-distcp-${version}.jar --src /data/warehouse/logs --dest cosn://examplebucket-1250000000/data/warehouse/logs-gzip --outputCodec=gzip
Note:
If the parameter is not set to
keep, the files will be decompressed and converted to the target compression format. Due to the difference in compression parameters, the content of the destination files might be different from that of the source files, but the files will be the same after decompression. If --groupBy is not specified and --outputCodec is the default value, you can use --skipMode to perform incremental migration and --checkMode to perform data verification.Deleting the source files
Run the command with the
--deleteOnSuccess parameter. The following example deletes the corresponding source files in the /data/warehouse directory immediately after they are copied from HDFS to COS:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --deleteOnSuccess
Note:
If
--deleteOnSuccess is specified, each source file is deleted immediately after the file is copied, but not after all source files are copied. The parameter is not provided in version 1.7 or later.Generating the target manifest and specifying the previous manifest
Run the command with the
--outputManifest and --previousManifest parameters.--outputManifest generates a local manifest.gz (Gzip compressed) file. When the copy operation is successful, the file is moved to the directory specified in --dest.--previousManifest specifies the destination files that are copied during the previous copy operation (--outputManifest). COSDistCp will skip files of the same size.hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --outputManifest=manifest.gz --previousManifest= cosn://examplebucket-1250000000/data/warehouse/manifest-2020-01-10.gz
Note:
The command above performs incremental copy only. Only files with size changes can be copied. If the file content is changed, you can refer to the example of
--diffMode and determine the changed manifest files based on the CRC checksum.Using dynamic strategy for migration job distribution
If your files differ greatly in size, (e.g., there are a few large files, causing imbalanced loads of a large number of small files and machines), you can use
--enableDynamicStrategy to enable the dynamic strategy, which allows faster-speed jobs to copy more files to speed up the whole copy process.hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --enableDynamicStrategy
Verify the migrated data after migration is completed:
hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --diffMode=length-checksum --diffOutput=/tmp/diff-output
Note:
This mode has certain limits; for example, the task counter may be inaccurate if the process is exceptional. Therefore, use
--diffMode to verify the data after migration.Copying metadata of the source file
Run the following command with the
--preserveStatus parameter to copy the user, group, permission, and timestamps (modification time and access time) metadata of the source file/directory to the destination file/directory. The parameter takes effect when files are copied from HDFS to CHDFS.
Sample:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --preserveStatus=ugpt
Configuring Prometheus
You can go to YARN to view the COSDistCp job counter, including the number of files/bytes that have been copied. To easily view the graph of the COSDistCp jobs, you can display the data using Prometheus and Grafana with easy configurations. The following example configures
prometheus.yml to add the jobs to grab:- job_name: 'cos-distcp-hive-backup'static_configs:- targets: ['172.16.16.139:9028']
Run the command with the
--promPort=VALUE parameter to expose the counter of the current MapReduce job:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --promPort=9028
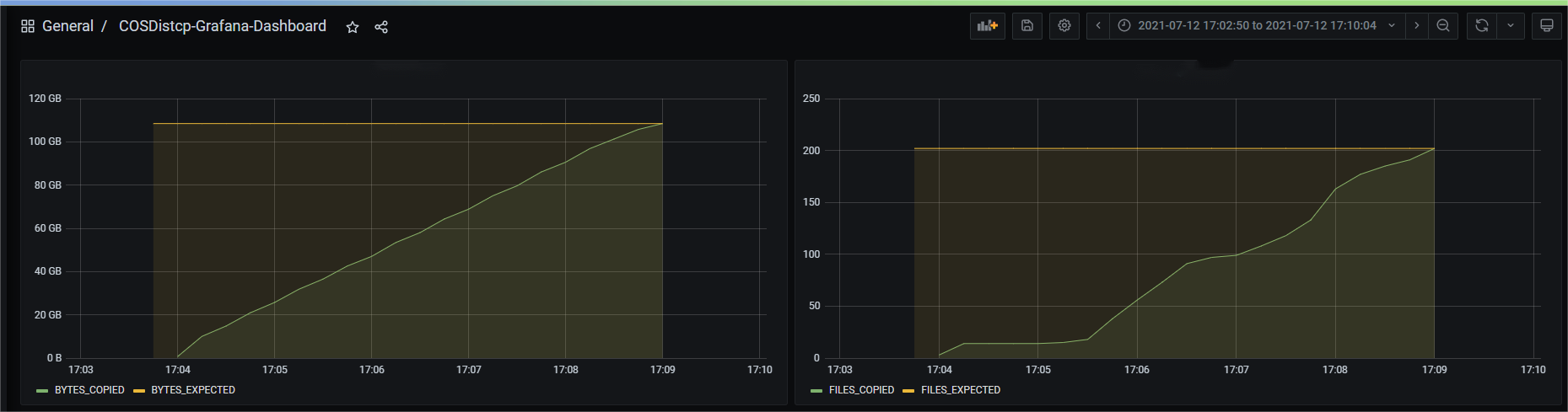
Alarms for copy failures
Run the command with the
--completionCallbackClass parameter to specify the path of the callback class. When the task is completed, COSDistCp will use the collected task information as parameters to execute the callback function. For user-defined callback functions, the following APIs need to be implemented. You can download the callback sample code.package com.qcloud.cos.distcp;import java.util.Map;public interface TaskCompletionCallback {/*** @description: When the task is completed, the callback function is executed* @param jobType Copy or Diff* @param jobStartTime the job start time* @param errorMsg the exception error msg* @param applicationId the MapReduce application id* @param: cosDistCpCounters the job*/void doTaskCompletionCallback(String jobType, long jobStartTime, String errorMsg, String applicationId, Map<String, Long> cosDistCpCounters);/*** @description: init callback config before execute*/void init() throws Exception;}
COSDistCp has integrated the alarms of Cloud Monitor. When the task runs abnormally or some files fail to be copied, alarming will be performed.
export alarmSecretId=SECRET-IDexport alarmSecretKey=SECRET-KEYexport alarmRegion=ap-guangzhouexport alarmModule=moduleexport alarmPolicyId=cm-xxxhadoop jar cos-distcp-1.4-2.8.5.jar \\-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \\-Dfs.cosn.userinfo.secretId=SECRET-ID \\-Dfs.cosn.userinfo.secretKey=SECRET-KEY \\-Dfs.cosn.bucket.region=ap-guangzhou \\-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \\-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \\--src /data/warehouse \\--dest cosn://examplebucket-1250000000/data/warehouse/ \\--checkMode=checksum \\--completionCallbackClass=com.qcloud.cos.distcp.DefaultTaskCompletionCallback
alarmPolicyId in the command above is an alarm policy created in Cloud Monitor. You can go to the Cloud Monitor console (Alarm Management > Alarm Configuration > Custom Messages) to create and configure one.FAQs
What stages are involved in migration of HDFS data with COSDistCp? How do I adjust the migration performance and ensure the data correctness?
COSDistCp verifies each migrated file upon migration completion according to
checkMode:hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse --taskNumber=20
After migration is completed, you can also run the following command to view the list of different source and destination files:
hadoop jar cos-distcp-${version}.jar --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse/ --diffMode=length-checksum --diffOutput=/tmp/diff-output
How can I run COSDistCp if Hadoop-COS is not configured in the environment?
You can download a specific version of the COSDistCp JAR package according to the Hadoop version and specify the Hadoop-COS-related parameters to perform the copy operation.
hadoop jar cos-distcp-${version}.jar \\-Dfs.cosn.credentials.provider=org.apache.hadoop.fs.auth.SimpleCredentialProvider \\-Dfs.cosn.userinfo.secretId=COS_SECRETID \\-Dfs.cosn.userinfo.secretKey=COS_SECRETKEY \\-Dfs.cosn.bucket.region=ap-guangzhou \\-Dfs.cosn.impl=org.apache.hadoop.fs.CosFileSystem \\-Dfs.AbstractFileSystem.cosn.impl=org.apache.hadoop.fs.CosN \\--src /data/warehouse \\--dest cosn://examplebucket-1250000000/warehouse
What should I do if the result shows that some files failed to be copied?
COSDistCp will retry 5 times for IOException occurred during the copy process. If the copy still fails, information about the failed files will be written to the
/tmp/${randomUUID}/output/failed/ directory, where ${randomUUID} is a random string. Common reasons for the copy failure are as follows:1. The source file contained in the copy manifest is not found during the copy (recorded as SRC_MISS).
2. The job initiator does not have permission to read the source file or write the destination file, or the copy failed due to other reasons (recorded as COPY_FAILED).
If the log message indicates that the source file does not exist, and the source file is ignorable, you can run the following command to obtain the list of different files except for those recorded as SRC_MISS:
hadoop fs -getmerge /tmp/${randomUUID}/output/failed/ failed-manifestgrep -v '"comment":"SRC_MISS"' failed-manifest |gzip > failed-manifest.gz
Except for those recorded as SRC_MISS, if there are other failed files, you can locate the failure reasons by referring to the error log messages in the
/tmp/${randomUUID}/output/logs/ directory and pulling the application logs. The following command example pulls the logs of the YARN application:yarn logs -applicationId application_1610615435237_0021 > application_1610615435237_0021.log
In the command above,
application_1610615435237_0021 is the application ID.Will COSDistCp generate incomplete files due to network or other exceptions?
If the network is abnormal, the source file is missing, or the permissions are insufficient, COSDistCp cannot generate a destination file with the same size as the source file.
For versions earlier than COSDistCp 1.5, COSDistCp will attempt to delete the destination files generated. If the deletion fails, you need to re-execute the copy task to overwrite the incomplete files, or manually delete them.
If your COSDistCp version is 1.5 or later and the version of the Hadoop-COS plugin in the running environment is 5.9.3 or later, when files fail to be copied to COS, COSDistCp will call the abort API to terminate the ongoing upload request. Therefore, no incomplete file will be generated even if an exception occurs.
If your COSDistCp version is 1.5 or later but the version of Hadoop-COS in the running environment is earlier than 5.9.3, you are advised to upgrade it to 5.9.3 or later.
If the destination location is not COS, COSDistCp will attempt to delete the destination files.
There are some invisible incomplete multipart uploads in COS buckets, which occupy storage space. How do I deal with them?
COS buckets may have some incomplete multipart uploads occupying storage space due to incidents such as server exception and process kill. You can configure an incomplete multipart upload deletion rule as instructed in Setting Lifecycle to clear them.
A memory overflow and task timeout occurred during migration. How do I adjust parameters?
During migration, both COSDistCp and the tools used to access COS and CHDFS, based on their own logic, occupy some memory. To avoid memory overflow and task timeout, you can adjust parameters of some MapReduce jobs, for example:
hadoop jar cos-distcp-${version}.jar -Dmapreduce.task.timeout=18000 -Dmapreduce.reduce.memory.mb=8192 --src /data/warehouse --dest cosn://examplebucket-1250000000/data/warehouse
As shown in the example above, the value of
mapreduce.task.timeout is changed to 18,000 seconds to avoid job timeout when large files are copied, and the value of mapreduce.reduce.memory.mb (memory size of the Reduce process) is changed to 8 GB to avoid memory overflow.How do I control the migration bandwidth of the migration task through migration over Direct Connect?
The formula for calculating the total bandwidth limit of COSDistCp migration is: taskNumber x workerNumber x bandWidth. You can set
workerNumber to 1, use the taskNumber parameter to control the number of concurrent migrations, and use the bandWidth parameter to control the bandwidth of a single concurrent migration.Bantuan dan Dukungan
Apakah halaman ini membantu?
Anda juga dapat Menghubungi Penjualan atau Mengirimkan Tiket untuk meminta bantuan.
masukan