Hadoopのインストールとテスト
Download
フォーカスモード
フォントサイズ
Hadoopツールは、Hadoop-2.7.2以降のバージョンに依存して、基盤となるファイルストレージシステムとしてTencent Cloud COSを使用し、上位層のコンピューティングタスクを実行する機能を実装しています。Hadoopクラスターを起動するには、主にスタンドアロン、疑似分散、完全分散という3つの主なモードがあります。ここでは主に、Hadoop-2.7.4バージョンを例として、完全分散Hadoop環境をビルド、およびwordcountの簡単なテストをご紹介します。
環境の準備
複数のマシンを準備します。
システムのインストールと設定は、CentOS公式サイト からダウンロードしてインストールできます。この記事では、CentOS 7.3.1611システムバージョンを使用します。
Java環境をインストールします。操作の詳細については、Javaのインストールと設定をご参照ください。
Hadoopの利用可能なパッケージApache Hadoop Releases Downloadをインストールします。
ネットワークの設定
ifconfig -aを使用して各マシンのIPを確認し、pingコマンドを使用して相互にpingを送信できるかどうかを確認し、各マシンのIPを記録します。CentOSの設定
ホスト名の設定
それぞれのマシンに対応するホスト名を設定します。例えば「master」、「slave*」などです。
hostnamectl set-hostname master
hostsの設定
vi /etc/hosts
コンテンツの編集:
202.xxx.xxx.xxx master202.xxx.xxx.xxx slave1202.xxx.xxx.xxx slave2202.xxx.xxx.xxx slave3# IPアドレスを実際のIPに置き換えます
ファイアウォールの無効化
systemctl status firewalld.service # ファイアウォールのステータスをチェックしますsystemctl stop firewalld.service # ファイアウォールを無効にしますsystemctl disable firewalld.service # ファイアウォールの起動を無効にします
時刻同期
yum install -y ntp # ntpサービスをインストールしますntpdate cn.pool.ntp.org # ネットワークの時刻を同期させます
JDKのインストールと設定
JDKインストールパッケージ(jdk-8u144-linux-x64.tar.gzなど)を
rootルートディレクトリにアップロードします。mkdir /usr/javatar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/java/rm -rf jdk-8u144-linux-x64.tar.gz
各ホスト間でのJDKのコピー
scp -r /usr/java slave1:/usrscp -r /usr/java slave2:/usrscp -r /usr/java slave3:/usr.......
各ホストのJDK環境変数の設定
vi /etc/profile
コンテンツの編集:
export JAVA_HOME=/usr/java/jdk1.8.0_144export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ファイルを保存した後、/etc/profileを有効にするために、以下のコマンドを実行します:
source /etc/profile # 設定ファイルを有効にするjava -version # javaバージョンを確認する
SSHキーレスアクセスの設定
各ホストのSSHサービスステータスを個別にチェックします。
systemctl status sshd.service //SSHサービスのステータスをチェックしますyum install openssh-server openssh-clients //SSHサービスをインストールします。すでにインストールされている場合は、この手順は不要ですsystemctl start sshd.service //SSHサービスを開始します。すでにインストールされている場合は、この手順は不要です
各ホストで個別にキーを発行します
ssh-keygen -t rsa //キーの発行
slave1の場合:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave1.id_rsa.pubscp ~/.ssh/slave1.id_rsa.pub master:~/.ssh
slave2の場合:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave2.id_rsa.pubscp ~/.ssh/slave2.id_rsa.pub master:~/.ssh
という感じで..
masterの場合:
cd ~/.sshcat id_rsa.pub >> authorized_keyscat slave1.id_rsa.pub >>authorized_keyscat slave2.id_rsa.pub >>authorized_keysscp authorized_keys slave1:~/.sshscp authorized_keys slave2:~/.sshscp authorized_keys slave3:~/.ssh
Hadoopのインストールと設定
Hadoopのインストール
hadoopインストールパッケージ(hadoop-2.7.4.tar.gzなど)を
rootルートディレクトリにアップロードします。tar -zxvf hadoop-2.7.4.tar.gz -C /usrrm -rf hadoop-2.7.4.tar.gzmkdir /usr/hadoop-2.7.4/tmpmkdir /usr/hadoop-2.7.4/logsmkdir /usr/hadoop-2.7.4/hdfmkdir /usr/hadoop-2.7.4/hdf/datamkdir /usr/hadoop-2.7.4/hdf/name
hadoop-2.7.4/etc/hadoopディレクトリに移動し、次の操作に進みます。Hadoopの設定
1.
hadoop-env.shファイルを変更して、以下を追加しますexport JAVA_HOME=/usr/java/jdk1.8.0_144
SSHポートがデフォルトの22でない場合は、
hadoop-env.shファイルで以下のように変更します。export HADOOP_SSH_OPTS="-p 1234"
2.
yarn-env.shを変更しますexport JAVA_HOME=/usr/java/jdk1.8.0_144
3.
slavesを変更します設定内容:
削除:localhost追加:slave1slave2slave3
4.
core-site.xmlを変更します<configuration><property><name>fs.default.name</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/hadoop-2.7.4/tmp</value></property></configuration>
5.
hdfs-site.xmlを変更します<configuration><property><name>dfs.datanode.data.dir</name><value>/usr/hadoop-2.7.4/hdf/data</value><final>true</final></property><property><name>dfs.namenode.name.dir</name><value>/usr/hadoop-2.7.4/hdf/name</value><final>true</final></property></configuration>
6.
mapred-site.xmlを変更します<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
7.
mapred-site.xml.template をコピーして、mapred-site.xml という名前にしますcp mapred-site.xml.template mapred-site.xml
8.
yarn-site.xmlを変更します<configuration><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property></configuration>
9. ホスト間でHadoopを複製します
scp -r /usr/ hadoop-2.7.4 slave1:/usrscp -r /usr/ hadoop-2.7.4 slave2:/usrscp -r /usr/ hadoop-2.7.4 slave3:/usr
10. 各ホストのHadoop環境変数を設定します
設定ファイルを開きます。
vi /etc/profile
コンテンツの編集:
export HADOOP_HOME=/usr/hadoop-2.7.4export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport HADOOP_LOG_DIR=/usr/hadoop-2.7.4/logsexport YARN_LOG_DIR=$HADOOP_LOG_DIR
設定ファイルを有効にします。
source /etc/profile
Hadoopの起動
1. namenodeのフォーマット
cd /usr/hadoop-2.7.4/sbinhdfs namenode -format
2. 起動
cd /usr/hadoop-2.7.4/sbinstart-all.sh
3. プロセスのチェック
masterホストにResourceManager、SecondaryNameNode、NameNodeなどが含まれている場合は、次のような表示があれば起動に成功しています。
2212 ResourceManager2484 Jps1917 NameNode2078 SecondaryNameNode
各slaveホストにDataNode、NodeManagerなどが含まれている場合は、次のような表示があれば起動に成功しています。
17153 DataNode17334 Jps17241 NodeManager
wordcountの実行
Hadoopにはwordcountルーチンが付属されているため、直接呼び出すことができます。Hadoopを起動した後、以下のコマンドを使用すれば、HDFS内のファイルを操作することができます。
hadoop fs -mkdir inputhadoop fs -put input.txt /inputhadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /input /output/
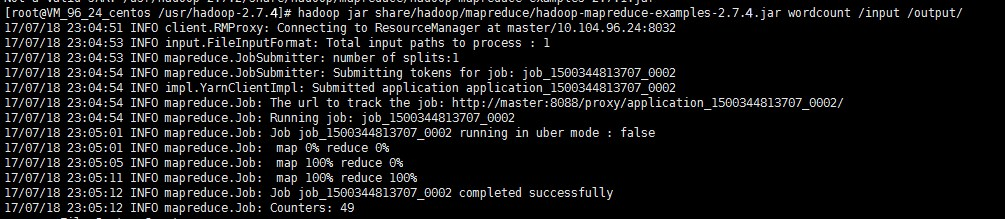
上図に示されている結果は、Hadoopのインストールが成功したことを示しています。
出力ディレクトリの確認
hadoop fs -ls /output
出力結果の確認
hadoop fs -cat /output/part-r-00000
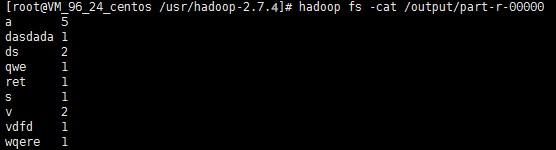
説明:
フィードバック