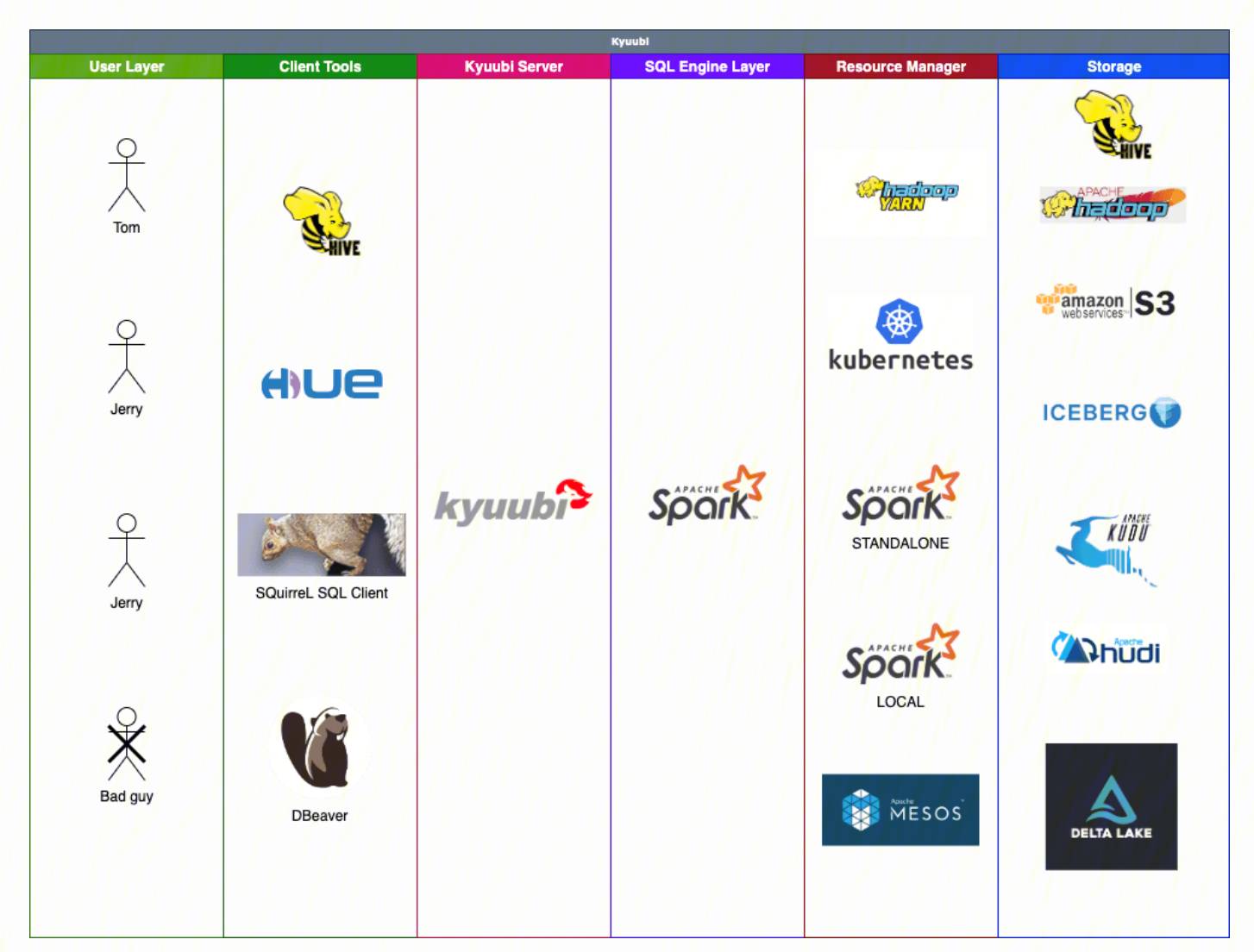
Apache Kyuubi (Incubating) is a distributed multi-tenant Thrift JDBC/ODBC service. Currently, it has been connected to Apache Spark and is being connected to Apache Flink and Trino. It can be used for diverse big data scenarios within enterprises, such as ETL and BI reporting.
Use Cases
You can replace HiveServer2 to increase the performance by 10–100 times.
Kyuubi is highly compatible with HiveServer2 APIs and supports seamless migration.
The layered architecture of Kyuubi eliminates client compatibility issues and supports imperceptible upgrade.
Kyuubi supports full-linkage Spark SQL optimization and enhancement for an excellent performance.
Kyuubi offers various enterprise-grade features, such as high availability, multi-tenancy, and fine-grained authentication.
You can build a Serverless Spark platform.
The goal of serverless Spark is definitely not to let you call Spark APIs or continue to write Spark jobs.
The built-in engine module of Kyuubi makes Spark easier to use, and you don't even need to understand the logic.
You can focus on your business development by manipulating data through JDBC and SQL. The resources are elastically scalable and Ops-free.
Resource managers such as Kubernetes and YARN as well as engine lifecycle are supported. Spark allocates resources dynamically and elastically at three different granularities.
You can schedule resources with multiple resource managers such as YARN and Kubernetes simultaneously. This guarantees the secure migration of historical jobs to the cloud.
Spark Adaptive Query Execution (AQE) and Kyuubi AQE Plus robustly empower data operations.
You can build a unified data lake insight, analysis, and management platform (with Kyuubi 1.5 or later).
All Spark and third-party data sources are supported.
Metadata can be managed through Spark DSv2 to visually build and manage data lakes.
All popular data lake frameworks are supported, including Apache Iceberg, Apache Hudi, and Delta Lake.
With one copy of data for one API and one engine, Kyuubi provides a unified query, analysis, data ingestion, and data lake management platform.
Kyuubi integrates batch processing and stream processing and supports stream operations (upcoming).