Synchronized Table
Download
Modo Foco
Tamanho da Fonte
Overview
The Synchronized Table is a special type of table. During data writes, modifications must be strongly synchronized to multiple Follower replicas before returning. Thus, its multiple Follower replicas can provide strongly consistent read services. It is suitable for workloads with infrequent writes, read-intensive operations, and high requirements for low-latency reads.
The Synchronized Table currently functions as a broadcast table. All Regions of a user's synchronized tables share a special RG (Replication Group) for broadcast synchronization. This RG is created when the user creates the first synchronized table. Subsequent Regions of synchronized tables are also scheduled to this synchronization RG. The RG for broadcast synchronization maintains a replica on every node within the system. Each Follower periodically applies for a lease from the Leader. When a write occurs on the Leader, it must wait until the modification is strongly synchronized to every Follower holding a valid lease before returning. For read requests, the synchronized table first attempts a local read; if the local read fails, it falls back to reading from the Leader.
Working Principles
Process for Writing Regular Transactions
1. Data is temporarily stored in the write batch of the transaction context before commit.
2. Upon entering the commit phase, the Leader persists the data in the write batch to disk as transaction logs, which are then synchronized to the nodes where replicas reside via the Raft protocol.
3. After a majority is formed, the Leader writes the data to RocksDB first and then returns to the client. Follower replicas replay the Raft logs and write them to RocksDB.
Process for Writing Transactions in Synchronized Tables
1. During the execution phase, both synchronized table transactions and regular transactions temporarily store data in the write batch of the transaction context in the same manner.
2. Upon entering the commit phase, the Leader also propagates data to Followers in the form of Raft logs.
3. Unlike regular transactions, synchronized tables require that all valid Followers have acknowledged the logs before the response can be returned to the client.
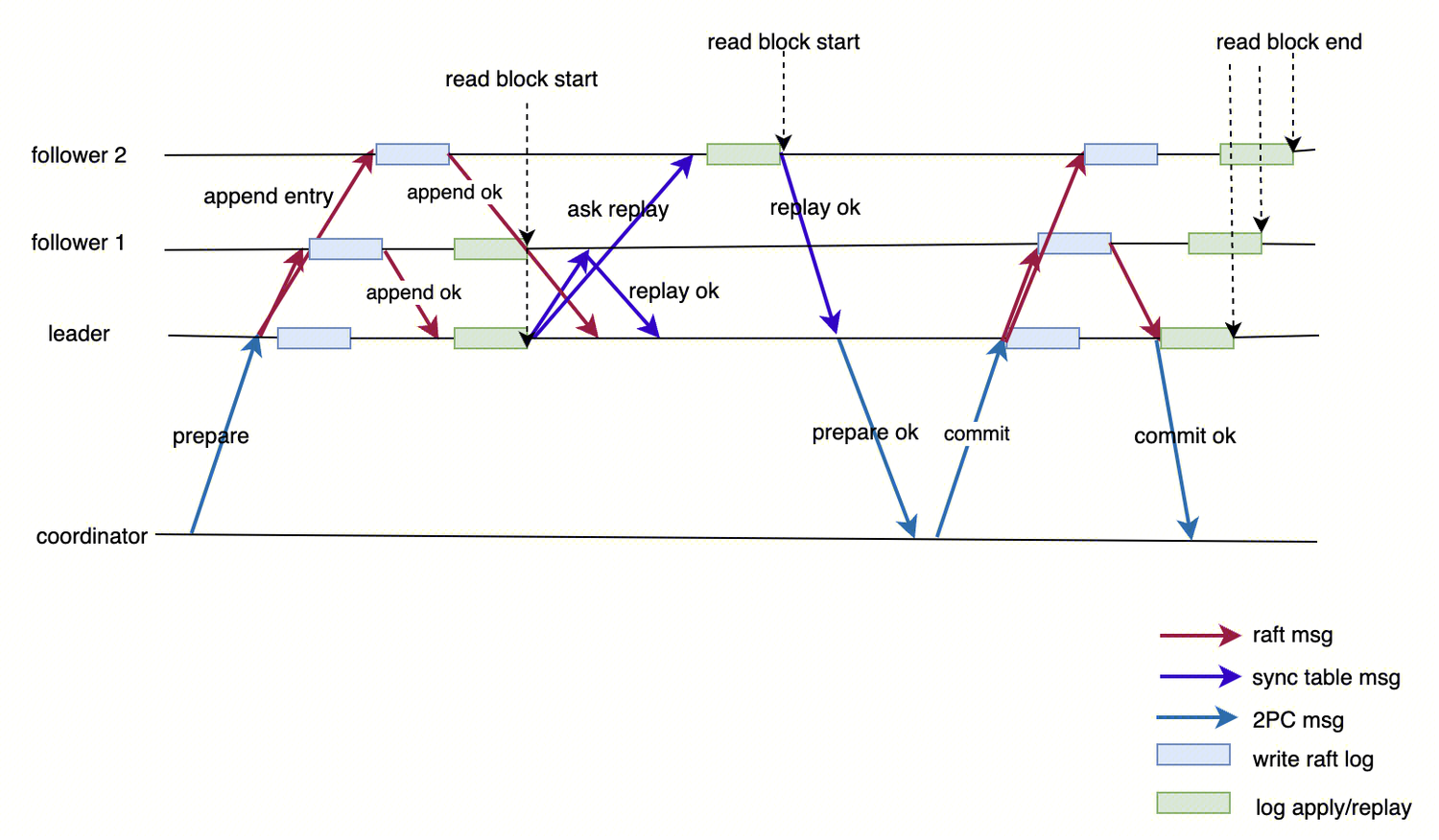
Specifically, for distributed transactions, the logic for the Leader to perform strong synchronization with Followers is as follows:
3.1 Submitting redo and prepare logs.
3.2
Obtain all replicas with valid leases.
3.3 Check whether each replica has replayed the prepare logs.
3.4 If all replicas have replayed the prepare logs, respond to the coordinator.
3.5 Otherwise, jump to Step 2 to retry.
When a read request is received on a Follower, it can no longer directly return an error. Instead, it must perform a readability check (including lease verification and so on). After the readability check is passed, the read logic aligns with that on the Leader: first check lock information to determine whether any transaction in the prepare state needs to block the current operation. If not, directly read RocksDB based on the read version number.
The Leader needs to maintain a list of valid Followers and must perform strong synchronization with all valid Followers during the commit phase. This valid Follower list is maintained through a lease mechanism. Followers periodically apply for leases from the Leader. Upon receiving a lease application, if the Leader agrees to grant the lease, it adds the node to the valid Follower list and synchronizes the lease log via Raft logs. Subsequently, all modifications on the Leader must be synchronized to this Follower. If a Follower fails to renew its lease for an extended period, causing the lease to expire, the Leader removes the Follower from the valid list and ceases strong synchronization with it. Followers can only provide strong synchronization services while their leases are valid; once a lease expires, the Follower is prohibited from providing strong synchronization services. This mechanism ensures that the Follower's lease expires first, meaning the Follower stops providing strong synchronization services first, while the Leader's lease expires later, meaning the Leader stops strong synchronization afterward.
Use Limits
Currently, synchronous tables provide services in the form of broadcast tables. Users must create synchronous tables for broadcast to use synchronous tables.
A failure in any Follower replica may cause write requests to stall for the duration of a lease.
Routing policy with local-first priority. If local access fails, the request should access the Leader.
Currently, attribute transformation for synchronous tables is not supported. That is, neither changing a synchronous table to a non-synchronous table nor changing a non-synchronous table to a synchronous table is supported.
Synchronous tables cannot be partitioned tables.
Broadcast synchronous log streams, once created, will not be destroyed even if users delete all synchronous tables.
An excessive number of replicas may cause performance degradation for write requests.
Usage Instructions
Synchronized Tables are suitable for business tables that are read-intensive with infrequent writes and sensitive to latency, such as system parameters, global configuration tables, and data warehouse dimension tables (such as the item table in TPCC).
Syntax
CREATE TABLE table_name (column_definitions) sync_level = node(all) distribution = node(all);
Read and write access syntax for synchronous tables remains consistent with that of regular tables. However, during read operations, the specific node accessed depends on the connection. Specifically, TDSQL Boundless prioritizes accessing the synchronous table replica on the local node where the connection resides. Only when the local node becomes unreadable (such as due to lease expiration) does it fall back to accessing the Leader node.
Example
tdsql [demo]> CREATE TABLE test_sync_table(c1 INT PRIMARY KEY,c2 INT,c3 INT,INDEX idx(c2)) sync_level = node(all) distribution = node(all);Query OK, 0 rows affected (2.90 sec)
Relevant parameters
Parameter Name | Default Value | Description |
tdstore_sync_table_max_allowed_log_lag | 1024 | The Leader, when deciding whether to grant a lease to a Follower, must consider the progress of log replay on the Follower. If the Follower's current replay progress lags behind the Leader by more than this parameter value, the Leader will not grant the lease. |
tdstore_sync_table_lease_interval_ms | 2000 | The interval at which Followers request leases from the Leader. |
tdstore_sync_table_log_interval_ms | 1000 | The interval at which the Leader synchronizes Raft lease logs. |
tdstore_sync_table_lease_len_us | 10000000 | The lease duration granted by the Leader to a Follower each time. |
Ajuda e Suporte
Esta página foi útil?
Você também pode entrar em contato com a Equipe de vendas ou Enviar um tíquete em caso de ajuda.
comentários