Optimizer Hints
Download
Modo Foco
Tamanho da Fonte
Overview
TDSQL extends specialized parallel Hints based on compatibility with MySQL's official Hint standards, tailored for distributed parallel execution characteristics. These Hints primarily serve as optimizer directives, enabling users to exercise finer-grained control over policies for parallel execution of queries and enhance the performance of complex queries.
Parallelism Control of the PARALLEL/NO_PARALLEL Hint
The PARALLEL Hint can be used to specify the table for Parallel Scan and its parallelism degree. The syntax is as follows:
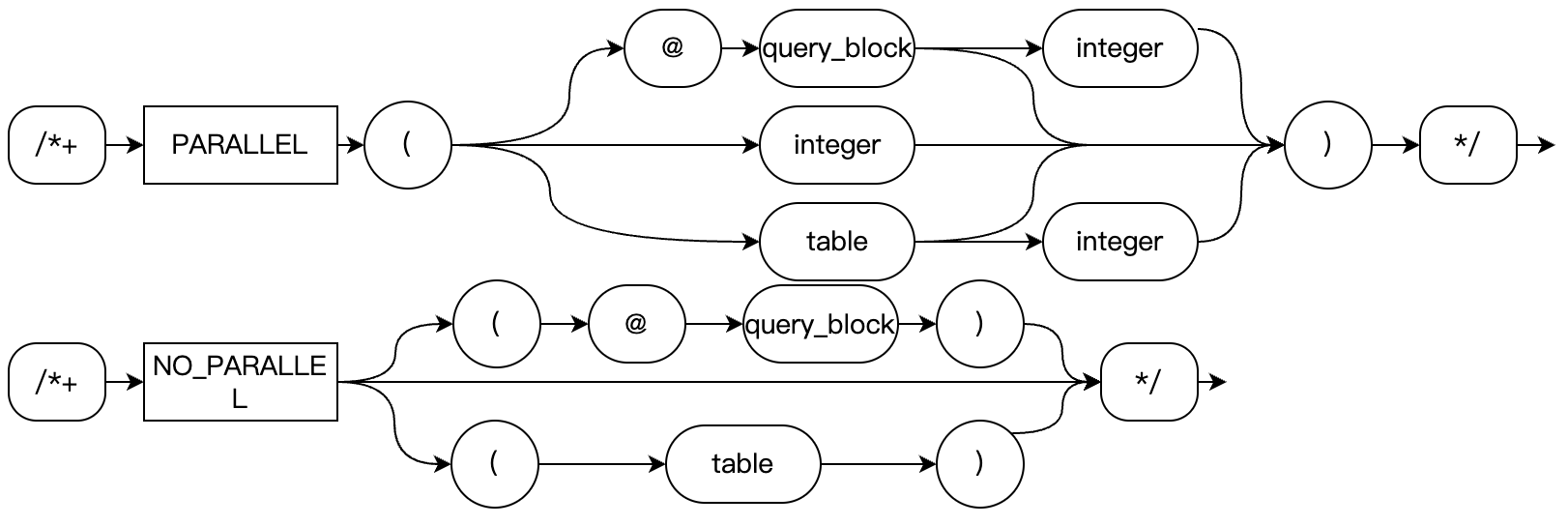
PARALLEL Hint is a three-level Hint: Global, Query Block, and Table levels. For example:
PARALLEL(num) -- Global level, the level of the Query BlockPARALLEL(@qbname num) -- the level of the Query BlockPARALLEL(tablename) -- the level of the TablePARALLEL(tablename num) -- the level of the TableNO_PARALLEL -- Global level, the level of the Query BlockNO_PARALLEL(@qbname) -- the level of the Query BlockNO_PARALLEL(tablename) -- Table level
Among them, NO_PARALLEL disables parallel execution. For the syntax of tablename and qbname, see the MySQL official documentation.
Global level: When num is specified in the main query without a given query block name and table name. In this case, num will serve as the default degree of parallelism for the entire query, and subqueries can override it with their own PARALLEL Hint.
Query Block level: When num is specified in non-main query contexts or with a given query block name but without a table name. In this case, num will serve as the default degree of parallelism for this subquery, which can be overridden at the table level.
Table level: When a table name is specified in the Hint. If only the table name is provided without num, the degree of parallelism will be determined by propagating upward (that is, Query Block level, Table level, max_parallel_degree variable). If no degree of parallelism is ultimately resolved (that is, when max_parallel_degree is 0), parallel execution will not occur. Additionally, parallel execution for multiple tables is currently supported. Future plans include enabling parallel execution across multiple tables.
At the Query Block level and Global level (when the Query Block level is unspecified), it can be determined at that time whether the current Query Block uses a parallel plan. For example, if it is specified with NO_PARALLEL, the Query Block will not enter the parallel optimization phase. The table level only affects whether the current table undergoes parallel scanning. That is to say, if neither Query Block nor Global level specifies a Hint, and the current max_parallel_degree is greater than 0, even if all tables use NO_PARALLEL, the parallel optimizer will still identify a table for parallel scanning to execute in parallel.
For the syntax of the PARALLEL Hint, some usage examples are demonstrated as follows:
-- Global levelEXPLAIN select /*+ PARALLEL(4) */ * from t1 where a > 4;-- Query block level, which takes effect only at the top-level query.EXPLAIN select /*+ QB_NAME(q1) PARALLEL(@q1 4) */ * from t1 where a > 4;-- Query block level, which takes effect only in subqueries.explain select * from t3 where a = (select /*+ PARALLEL(2) */ count(a) from t3);-- Table levelEXPLAIN select /*+ PARALLEL(t1 4) */ from t1 where a > 4;-- Table levelEXPLAIN select /*+ PARALLEL(t3@q2 4) */ * from t3 where a = (select /*+ QB_NAME(q2) */ count(a) from t3);-- Table levelEXPLAIN select /*+ PARALLEL(@q2 t3 4) */ * from t3 where a = (select /*+ QB_NAME(q2) */ count(a) from t3);
PQ_DISTRIBUTE Hint Data Distribution Strategy of the Hint
Used to instruct the optimizer on how to add data redistribution operations in the query plan. The syntax is as follows:
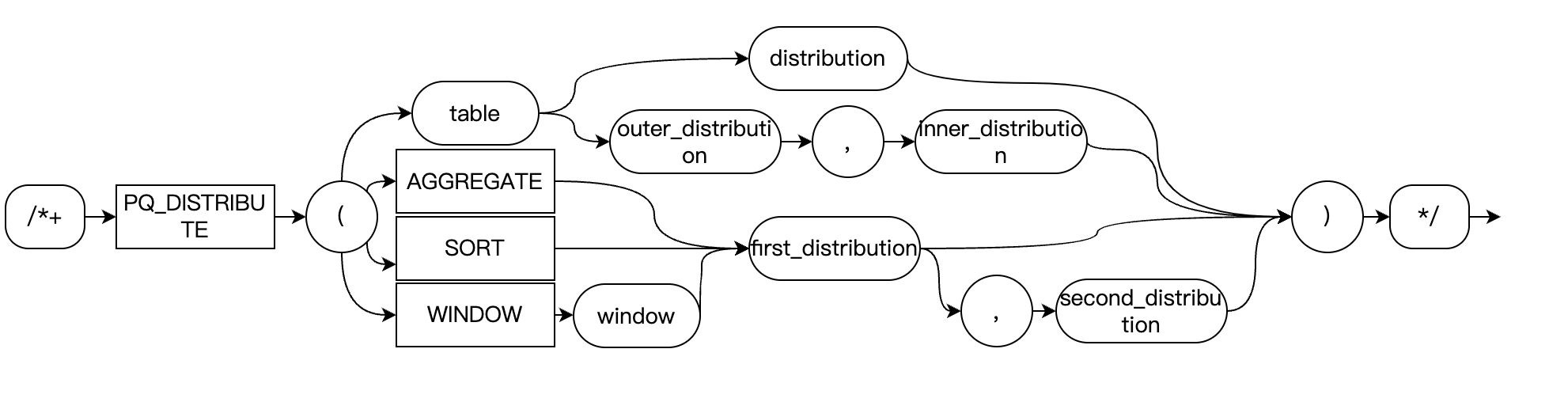
-- Basic syntaxPQ_DISTRIBUTE(tablespec strategy1 strategy2)PQ_DISTRIBUTE(tablespec strategy)-- For specific operation typesPQ_DISTRIBUTE(target strategy1 strategy2)
target: Operation target, which supports AGGREGATE, SORT, and WINDOW. It specifies the distribution policy for GROUP BY, ORDER BY, and WINDOW functions respectively. WINDOW can be followed by the name of the WINDOW.strategy1, strategy2: Redistribution policy, which supports NONE, GATHER, HASH, BROADCAST.Distribution Policy for JOIN Operations
PQ_DISTRIBUTE(t1 HASH, HASH), PQ_DISTRIBUTE(t1@qb1 HASH, HASH), or PQ_DISTRIBUTE(@qb1 t1 HASH HASH): Specifies that when a JOIN is performed between t1 and its preceding table, HASH redistribution is applied first, followed by JOIN operations on each node.PQ_DISTRIBUTE(t1 BROADCAST, NONE): Specifies that when a JOIN is performed between t1 and its preceding table, the preceding table (outer table) is broadcasted before being joined with t1.PQ_DISTRIBUTE(t1 GATHER): Specifies that table t1 is gathered first before being joined with other tables.Usage example:
-- Both tables undergo HASH redistribution before JOINSELECT /*+ PQ_DISTRIBUTE(t1 HASH, HASH) */ *FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id;-- Outer table broadcast, inner table not redistributedSELECT /*+ PQ_DISTRIBUTE(t1 BROADCAST, NONE) */ *FROM small_table t1 JOIN large_table t2 ON t1.id = t2.id;-- Perform JOIN after the table data is gathered to the LeaderSELECT /*+ PQ_DISTRIBUTE(t1 GATHER) */ *FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id;
Distribution Policy for GROUP BY Aggregation
Parallel GROUP BY operations can involve up to two phases. The first policy indicates the data distribution operation before the initial GROUP BY phase, while the second policy denotes the data distribution operation prior to the second phase. If only one policy is specified, it indicates a single-phase operation.
PQ_DISTRIBUTE(AGGREGATE NONE): Fully pushes down the operation in a single phase.PQ_DISTRIBUTE(AGGREGATE NONE, GATHER): Two phases for Worker and Leader.PQ_DISTRIBUTE(AGGREGATE NONE HASH): Two-phase operation between Workers.PQ_DISTRIBUTE(AGGREGATE GATHER): Performed solely on the Leader in a single phase.Usage example:
-- Fully pushed down single-phase aggregationSELECT /*+ PQ_DISTRIBUTE(AGGREGATE NONE) */department, AVG(salary)FROM employeesGROUP BY department;-- Two-phase aggregation between Worker and LeaderSELECT /*+ PQ_DISTRIBUTE(AGGREGATE NONE, GATHER) */department, AVG(salary)FROM employeesGROUP BY department;-- Two-phase aggregation between WorkersSELECT /*+ PQ_DISTRIBUTE(AGGREGATE NONE HASH) */department, AVG(salary)FROM employeesGROUP BY department;-- Single-phase aggregation performed solely on the LeaderSELECT /*+ PQ_DISTRIBUTE(AGGREGATE GATHER) */department, AVG(salary)FROM employeesGROUP BY department;
Distribution Policy for ORDER BY Sorting
PQ_DISTRIBUTE(SORT NONE, GATHER): Merge Sort performed by Worker + Leader.PQ_DISTRIBUTE(SORT GATHER): Sort is performed solely on the Leader.Usage example:
-- Partial sorting by Workers + Merge sort by the LeaderSELECT /*+ PQ_DISTRIBUTE(SORT NONE, GATHER) */ *FROM large_tableORDER BY create_time DESC;-- Global sorting performed solely on the LeaderSELECT /*+ PQ_DISTRIBUTE(SORT GATHER) */ *FROM large_tableORDER BY create_time DESC;
Distribution Policy for WINDOW Functions
PQ_DISTRIBUTE(WINDOW GATHER)
Policy description: Window function computation is entirely centralized on the Leader node. All data is first collected to the Leader node, and window function computation is performed on a single node.
Applicable scenarios:
Data volume is relatively small and can be processed on a single node.
Window functions requiring global sorting (such as RANK() OVER (ORDER BY ...))
The number of window function partitions is insufficient and cannot be effectively parallelized.
Example:
-- Compute global ranking on the Leader nodeSELECT /*+ PQ_DISTRIBUTE(WINDOW GATHER) */student_id,score,RANK() OVER (ORDER BY score DESC) as global_rankFROM exam_scores;-- Calculate the trend of grade changes for each student (data volume is small)SELECT /*+ PQ_DISTRIBUTE(WINDOW GATHER) */student_id,exam_date,score,LAG(score) OVER (PARTITION BY student_id ORDER BY exam_date) as prev_scoreFROM student_scores;
PQ_DISTRIBUTE(WINDOW HASH)
Policy description: Perform hash distribution based on the columns in the PARTITION BY clause of the window function and execute the window function computation in parallel on each Worker node.
Applicable scenarios:
The data volume is large and requires parallel processing.
The window function has a clear partition key and evenly distributed partition data.
The data volume within each partition is moderate and well-suited for parallel computing.
Example:
-- Rankings are computed in parallel by subject partition.SELECT /*+ PQ_DISTRIBUTE(WINDOW HASH) */subject,student_id,score,RANK() OVER (PARTITION BY subject ORDER BY score DESC) as subject_rankFROM exam_scores;-- Calculate the cumulative salary sum by department partition.SELECT /*+ PQ_DISTRIBUTE(WINDOW HASH) */department,employee_id,salary,SUM(salary) OVER (PARTITION BY department ORDER BY hire_date) as cumulative_salaryFROM employees;
PQ_DISTRIBUTE(WINDOW win1 GATHER)
Policy description: The GATHER policy is adopted for execution on specifically named windows (defined using the WINDOW clause).
Applicable scenarios:
The query contains multiple window functions, and it is necessary to adopt different policies for specific windows.
Named window functions require special handling.
Hybrid use of different distribution policies to optimize complex queries.
Example:
-- Apply the GATHER policy to specifically named windows.SELECT /*+ PQ_DISTRIBUTE(WINDOW win1 GATHER) */student_id,subject,score,AVG(score) OVER win1 as avg_score,RANK() OVER (PARTITION BY subject ORDER BY score DESC) as rankFROM exam_scoresWINDOW win1 AS (PARTITION BY student_id);-- Different policies for multiple named windowsSELECT /*+ PQ_DISTRIBUTE(WINDOW win1 GATHER) PQ_DISTRIBUTE(WINDOW win2 HASH) */department,employee_id,salary,AVG(salary) OVER win1 as dept_avg,SUM(salary) OVER win2 as running_totalFROM employeesWINDOW win1 AS (PARTITION BY department),win2 AS (PARTITION BY department ORDER BY hire_date);
PQ_DISTRIBUTE(WINDOW win1 HASH)
Policy description: The HASH distribution policy is adopted for parallel execution on specifically named windows.
Applicable scenarios:
Named window functions with large data volumes require parallel optimization.
Different window functions require distinct parallelization policies.
Fine-grained control over the execution plan of complex queries is implemented.
Example:
-- Use HASH distribution for specific windows.SELECT /*+ PQ_DISTRIBUTE(WINDOW win1 HASH) */product_category,product_id,sales_amount,SUM(sales_amount) OVER win1 as category_total,RANK() OVER (ORDER BY sales_amount DESC) as global_rankFROM sales_dataWINDOW win1 AS (PARTITION BY product_category);-- Mixed policy: one window GATHER, another window HASH.SELECT /*+ PQ_DISTRIBUTE(WINDOW win1 GATHER) PQ_DISTRIBUTE(WINDOW win2 HASH) */customer_id,order_date,amount,AVG(amount) OVER win1 as cust_avg, -- For small data volumes, use GATHER.SUM(amount) OVER win2 as running_sum -- For large data volumes, use HASH.FROM ordersWINDOW win1 AS (PARTITION BY customer_id),win2 AS (PARTITION BY customer_id ORDER BY order_date);
SUBQUERY Hint Policy for Parallel Subqueries
The MySQL SUBQUERY Hint for parallel queries introduces two additional parallelization strategies that can be used in combination with MySQL's native strategies.
PQ_PRE_EVALUATION: Specifies that a subquery is pre-evaluated before the execution of the parent query that references it, allowing parallel workers to directly read the subquery results.
PQ_INLINE_EVALUATION: Enforces non-advance execution of subqueries, that is, executes on demand according to the parent query's requirements following MySQL's logic.
Example:
-- Specify that this IN subquery uses the MATERIALIZATION policy and does not employ the pre-evaluation policy in the parallel plan.EXPLAIN FORMAT=TREESELECT * FROM t1WHERE t1.a IN (SELECT /*+ SUBQUERY(MATERIALIZATION, PQ_INLINE_EVALUATION) */ aFROM t2);-- Specify that the Derived Table subquery t uses the pre-evaluation policy.EXPLAIN FORMAT=TREESELECT /*+ NO_MERGE(t) pq_distribute(t1 none) */ t1.aFROM t1, (SELECT /*+ subquery(pq_inline_evaluation) */ aFROM t2) tWHERE t1.a = t.a;
Ajuda e Suporte
Esta página foi útil?
Você também pode entrar em contato com a Equipe de vendas ou Enviar um tíquete em caso de ajuda.
comentários