Document segmentation refers to the system dividing document content into multiple independent segments by certain rules. These segments will be indexed and stored in the knowledge base, which is the core component for implementing RAG (Retrieval-Augmented Generation). During the QA process, when the user asks a question, the system will first retrieve the most related content segments from the knowledge base, then inject these segments as external knowledge into the context of the large model to assist in generating the answer. Appropriate segmentation size will directly affect the effect of retrieval and generation.
Oversized segments: may contain too many irrelevant information, leading to a drop in retrieval accuracy and increased computation and resource consumption.
Undersized segments: incomplete content, lack of consistent context, easily lead to fragmented knowledge fragments, making generated answer insufficiently comprehensive.
Hence, the platform provides flexible document segmentation rules at the product level, supporting users to customize and modify rules according to business needs, achieving the best balance between retrieval efficiency and generation quality, and fully leveraging the advantages of RAG technology in knowledge q&a and information retrieval.
Document Segmentation Function Introduction
Document segmentation rules support default splitting rules and custom splitting rules:
Default splitting rules: The product uses model capability to segment, and the default slicing rules do not support user intervention.
Custom splitting rules: Provide 3 splitting rules to support user selection, including common identifier split, parent-child identifier split, and line-by-line split.
Splitting Rules and Comparison
Default Split
Common Identifier Split
Parent-Child Identifier Split
Split by Row
Applicable Document Type
All document types supported for importing in the product.
Support non-table type documents, excluding xlsx, xls, csv.
Support non-table type documents, excluding xlsx, xls, csv.
Support table type documents, including xlsx, xls, csv.
Use Cases
Suitable for scenarios with no special requirements for document segmentation.
Suitable for scenarios with special business requirements for splitting, such as by page number or custom flag.
Suitable for scenarios with special requirements for both retrieve split and recall split. Support user customization to set split identifier for splitting.
The form document takes effect, and each line or every few lines of row data are independent with no semantic correlation, for example, product sku document.
Splitting Logic
Split based on split model.
Support semantic integrity split.
Support cross-page table merging.
Supports parsing image information in spreadsheets.
Support parsing table content in documents, including wired and wireless tables.
Support parsing data diagrams, flowcharts, architecture diagrams, and mind maps.
Support parsing complex elements such as multi-column layouts, formulas, and subgraphs.
Support identifiers, maximum split length, and overlap length set by the user to split documents. The splits are used for retrieval and large model recall.
Parent and child splits respectively support identifiers, maximum split length, and overlap length set by the user.
Child splits are used for knowledge retrieval. After retrieving the corresponding parent fragment, they are used for large model recall.
Support users to set the header range, data sharding start line, and split line count. The system will split the form document into fragments according to the split line count.
Function Entries
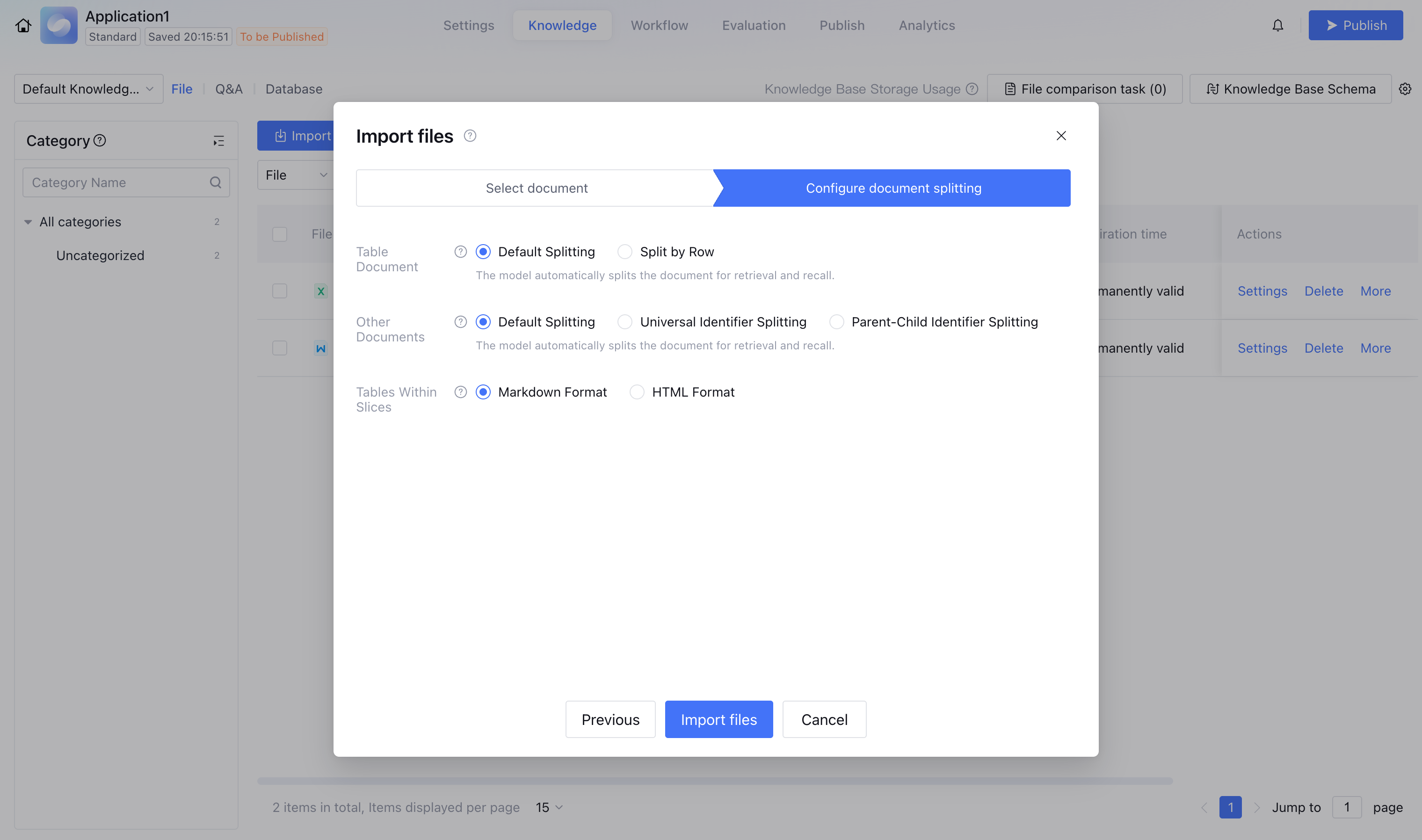
Entry 1 - Splitting after uploading documents: In the knowledge base document import procedure, document segmentation is customizable after uploading documents. It takes effect by document type for the same batch of uploaded documents.
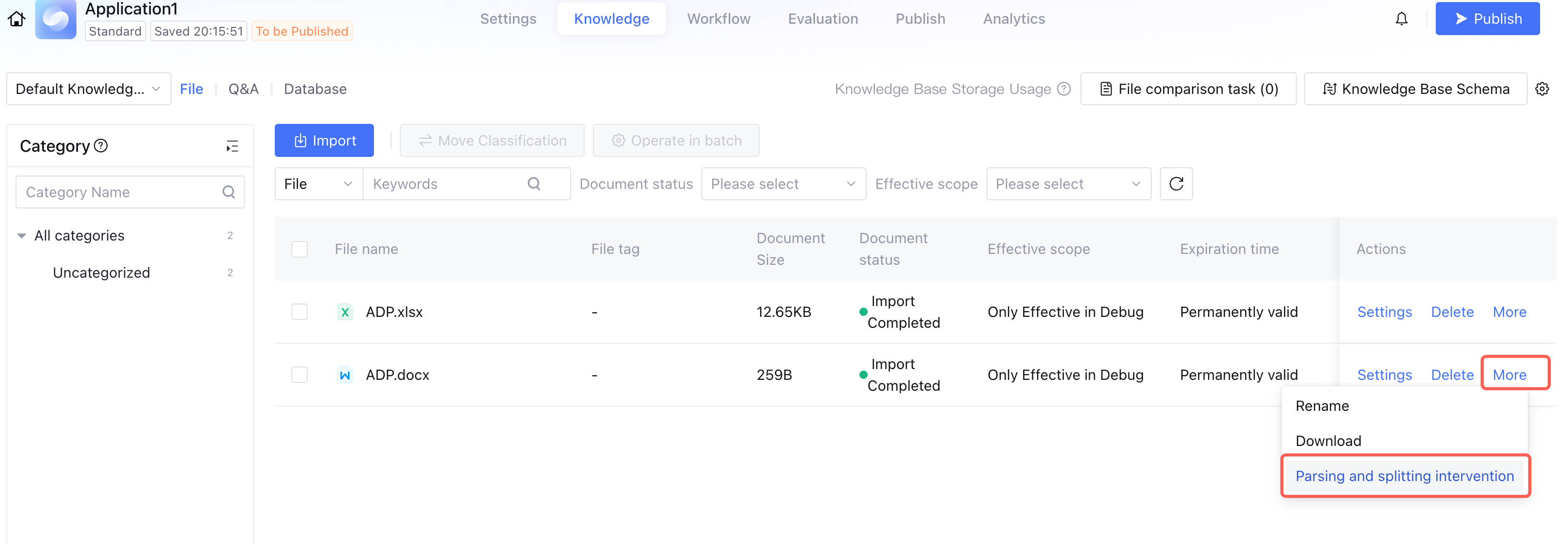
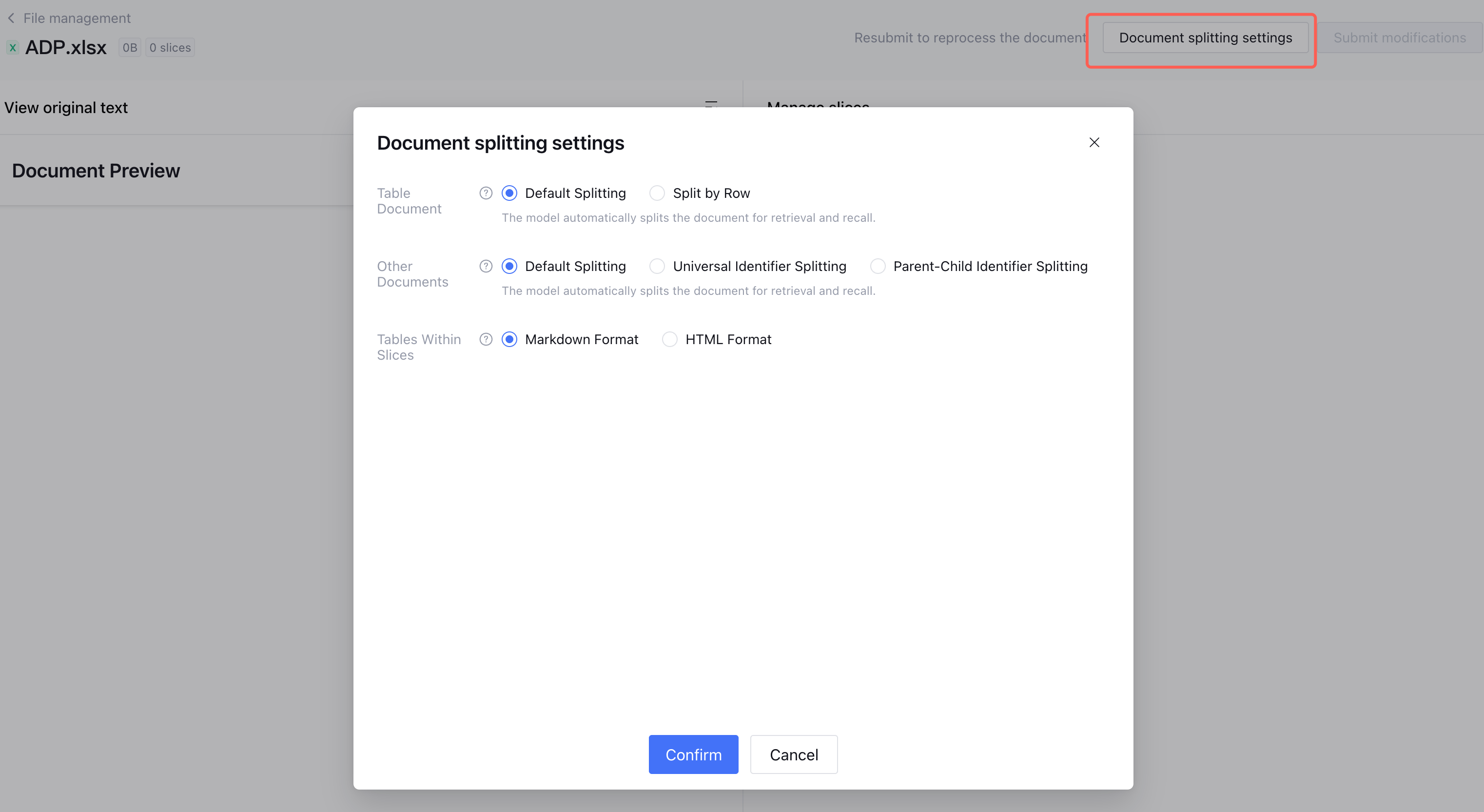
Entry 2 - Readjust existing document splitting rules: Imported documents are resettable for segmentation. Sequentially click More > Parsing And Splitting Intervention on the right of the designated document in the knowledge base to view parsing and splitting results. You can re-set segmentation rules by clicking Document Segmentation Settings.
Note:
After setting the document split rule, the system will split the original document again and overwrite the earlier split results.
Document Splitting Rules for Different Document Types
The platform offers multiple document segmentation rules to adapt to different document structures.
Spreadsheet content: segment by row, column, or cell to maintain structured data features and enable locating specific data cells during retrieval.
Non-table content (such as PDF, DOCX, TXT, web page text): normally segment by paragraph, heading level, or fixed length to ensure context integrity and consistent logic.
Form Document
Support setting Default Split or Split by Row. After configuration, it takes effect on all table documents, including xlsx, xls, and csv.
Default Split
The product uses the "split model" to segment based on table row count and semantic integrity.
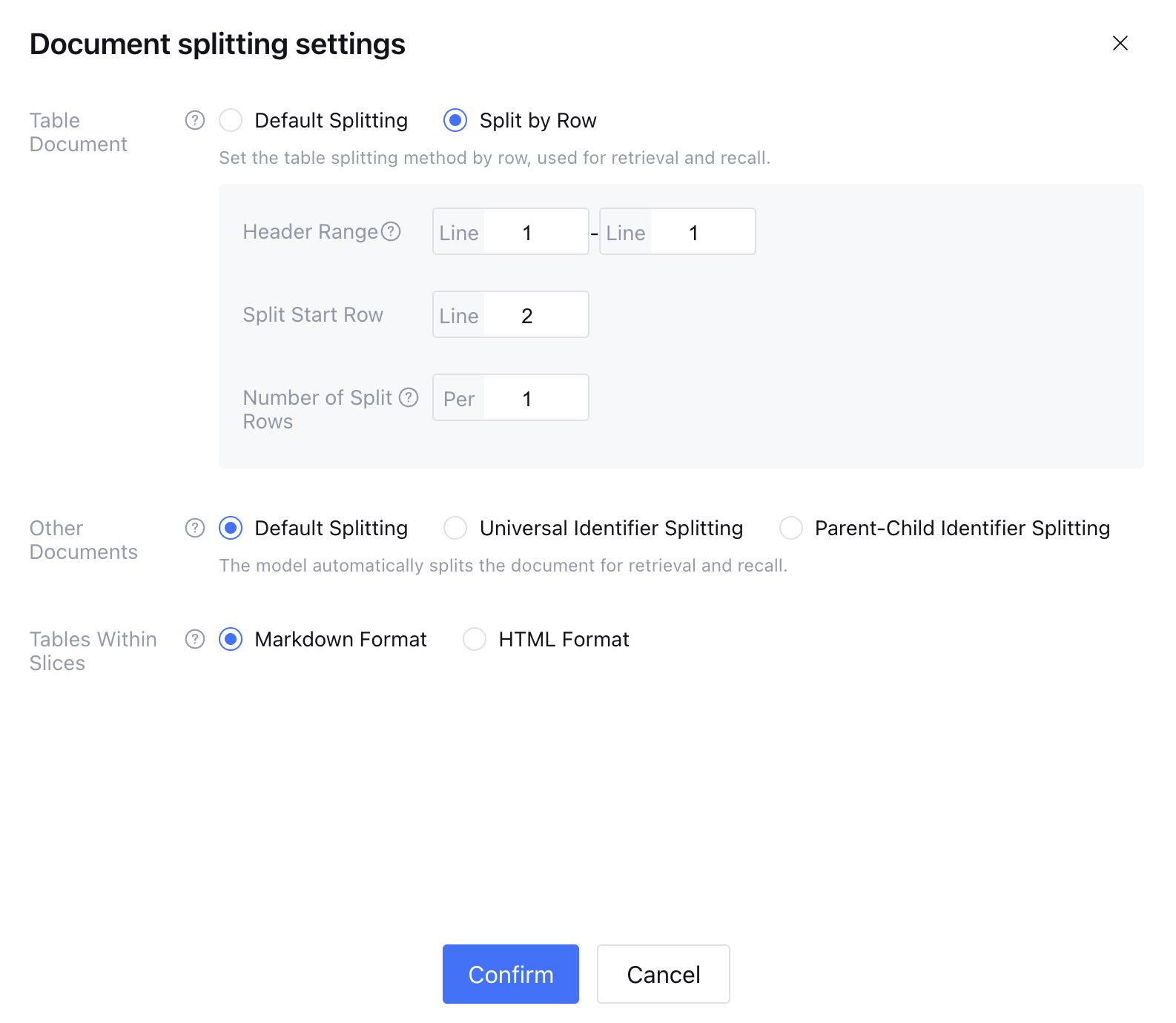
Split by Row
The system splits content into independent fragments as customized by users. When a user enters a question, the system uses the user question to retrieve content fragments and recalls matched fragments for the large model to generate answers. Fragments are used for knowledge retrieval and large model recall.
Header range: Support selecting the header range of the form document. Each fragment contains header data, with an interval supporting up to 5 rows.
Split start line: The number of rows to start splitting. For example, if set to start splitting from the second row, the first slice contains the header and the second row data. The split start line is not allowed to overlap with the header range.
Row count for split: Each segment is split according to the set row count starting from the split start row. For example, if the row count is set to 1 per segment and the start row is row 2, the first segment will be the header + row 2, the second segment will be the header + row 3, and so on.
2. Other Documents
Support setting Default Split, Common Identifier Split, Parent-Child Identifier Split. After configuration, it takes effect on non-table documents in the knowledge base, except xlsx, xls, and csv.
Default Split
The product uses the "split model" to segment based on semantic integrity.
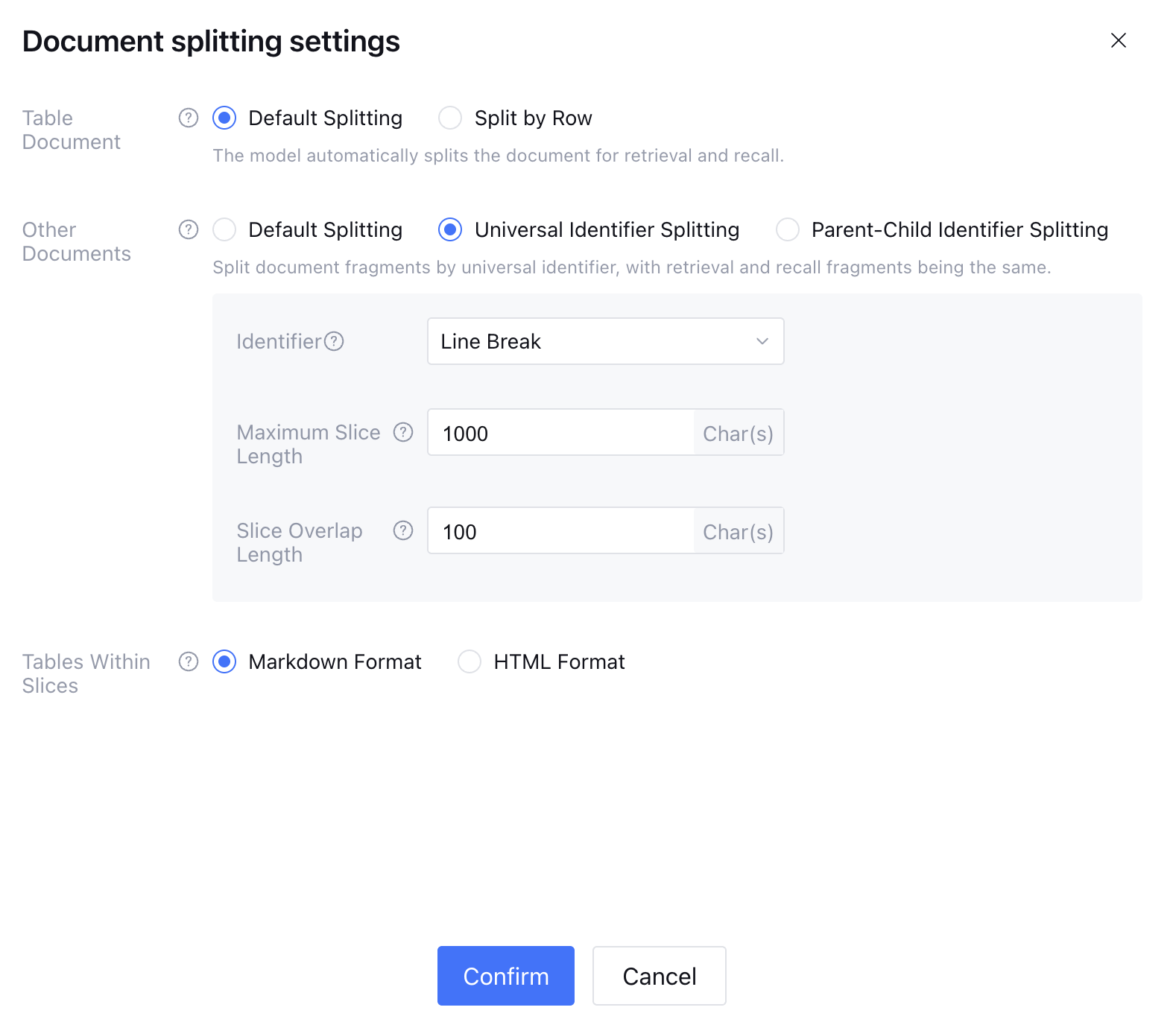
Common Identifier Split
The system splits content into independent fragments as customized by users. When a user enters a question, the system uses the user question to retrieve split content and matches the split content for large model recall to generate an answer. Splits are used for knowledge retrieval and large model recall.
Identifier: The system will split documents according to the set identifier. Customizable settings include symbols like *** and ###. The split identifier will not show in the split.
Split maximum length: The maximum length of each split. If a fragment split by identifier exceeds the set maximum length, it will be split into multiple fragments based on the maximum length, which should not exceed 4800 characters.
Split overlap length: Set the character length of the overlap section between splits to retain the semantic relationship between different splits. When the actual split length exceeds the set "split maximum length", the system split fragments take effect based on this setting. It is recommended to set 10% of the split maximum length as the split overlap length, with a maximum of 25% of the "split maximum length".
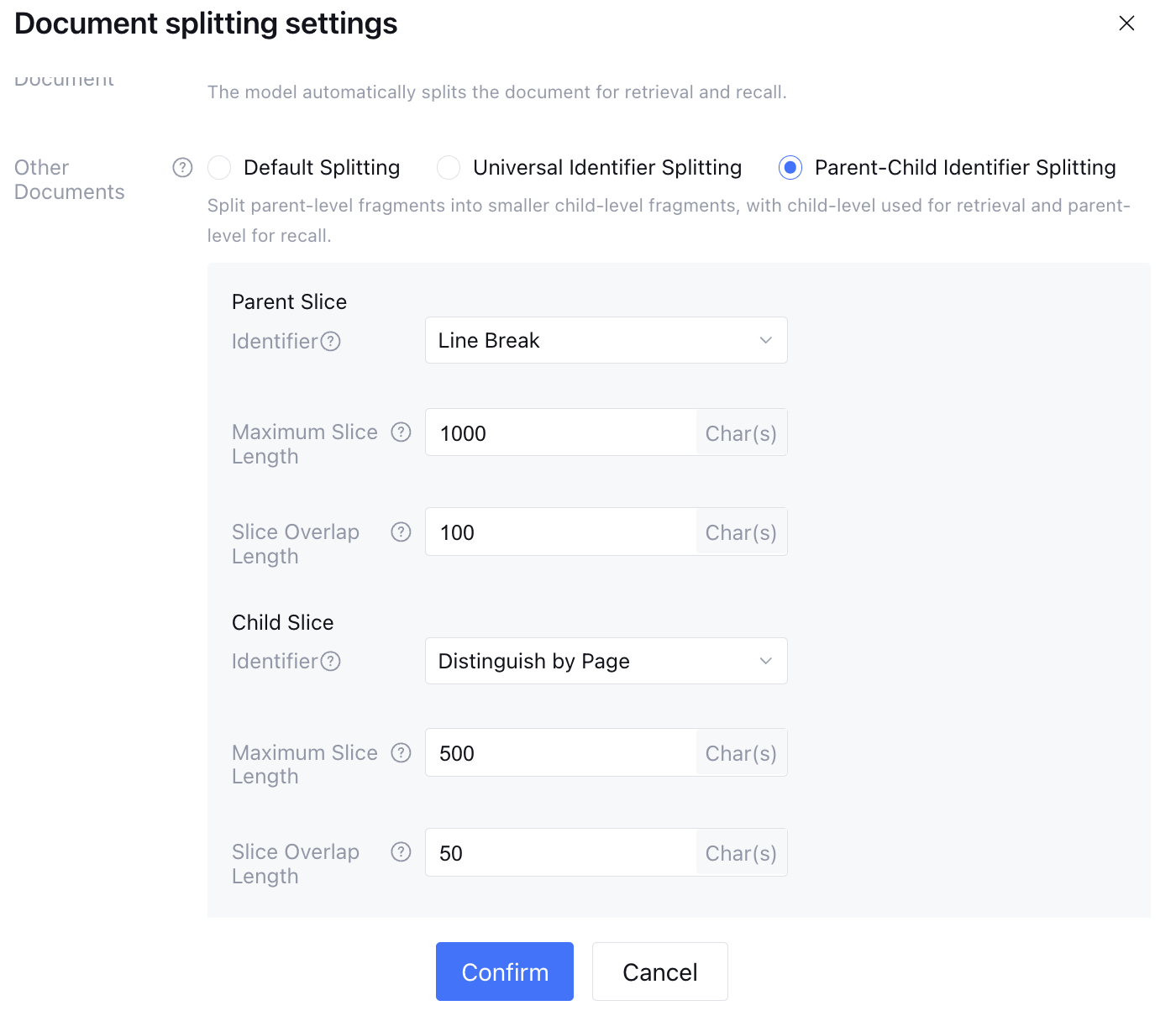
Parent-Child Level Identifier Split
The system splits content into parent and child splits according to user-defined rules. When a user enters a question, the system uses the user question to retrieve child split content and recalls the corresponding parent split matched by the child split for the large model to generate an answer. Child splits are used for knowledge retrieval, and parent splits are used for large model recall.
The maximum length set for child splits cannot exceed the parent maximum length, with a maximum settable length of 1500 characters.
Child slices have a one-to-one or many-to-one relationship with parent slices. First split the document into multiple parent slices, then split each parent slice into one or more child slices.
3. Splitting a Spreadsheet
Support setting the split format of tables in documents, including Markdown format and HTML format, with default value as Markdown format. It takes effect on table content in documents or content in spreadsheet documents.
Markdown format has better effectiveness, while HTML format consumes less tokens.