Overview - INTELLIGENT TIERING
Download
Mode fokus
Ukuran font
Overview
INTELLIGENT TIERING is a COS storage class designed to reduce storage costs by automatically moving objects between two storage tiers (frequent access and infrequent access) when access patterns change.
INTELLIGENT TIERING is suitable for data with an unpredictable or variable access pattern. COS monitors the access situation of objects, and storage fees are charged based on the actual storage tier utilized (frequent access tier, infrequent access tier, archive tier, and deep archive tier).Users can change the storage class of objects with uncertain access patterns from STANDARD to INTELLIGENT TIERING as needed to reduce in-cloud storage costs.
Note:
INTELLIGENT TIERING is currently only supported in Beijing, Nanjing, Shanghai, Guangzhou, Chengdu, Chongqing, Hong Kong (China), Singapore, Tokyo, Jakarta, Frankfurt, Virginia and São Paulo regions.
INTELLIGENT TIERING is a standalone storage class that will incur storage usage fees and object monitoring fees. You can purchase an INTELLIGENT TIERING storage pack to redeem the storage usage fees. For detailed pricing, see Product Pricing.
MAZ buckets do not support enabling configurations for intelligent tiering archive/deep archive tiers.
Advantages
The access patterns of data stored in INTELLIGENT TIERING will be monitored. COS moves objects that have not been accessed for a continuous period to the lower-cost infrequent access tier. If an object in the infrequent access tier is accessed later, it is automatically moved back to the frequent access tier to ensure the data retrieval performance. INTELLIGENT TIERING manages to strike a balance between storage costs and read/write performance and features the following strengths:
Cost-effective: When you use INTELLIGENT TIERING for persistent storage, the longer your data is stored, the more you can save on your storage costs (up to about 20%) compared with the STANDARD storage class. INTELLIGENT TIERING is also involved in the object storage lifecycle, where you can transition your INTELLIGENT TIERING data to ARCHIVE to further lower storage costs.
Stable and durable: INTELLIGENT TIERING provides the same low latency and high throughput as the STANDARD storage class. Besides, it offers durability of up to 99.999999999% (11 9s) by using erasure code-based redundancy, and up to 99.99% availability by using block storage and concurrent reads/writes. INTELLIGENT TIERING has also been integrated with the COS MAZ architecture, featuring high durability (99.9999999999%, that is, 12 9s) and availability (99.995%).
Easy-to-use: To use INTELLIGENT TIERING, all you need to do is specify it as the storage class of your object. This COS storage class is inherently compatible with COS APIs, SDKs, tools, and applications, making it easy for you to manage your in-cloud data as needed.
Supported Storage Tiers
Note:
Files smaller than 64KB will remain in the standard tier and will not descend to the infrequent access tier, archive tier, or deep archive tier.
Users can check which tier an intelligent tiering object is in by using the header x-cos-storage-tier returned by the API HEAD Object. Additionally, in the list of objects returned by calling APIs GET Bucket (List Objects) and GET Bucket Object Versions, an intelligent tiering object will include the StorageTier field for viewing the object's tier.
Access Tier | x-cos-storage-tier |
Frequent Access Tier | FREQUENT |
Infrequent Access Tier | INFREQUENT |
Archive Tier | ARCHIVE_ACCESS |
Deep Archive Tier | DEEP_ARCHIVE_ACCESS |
Frequent Access Tier (Enabled by default)
After intelligent tiering objects are uploaded, they are in the frequent access tier (FREQUENT) by default. While objects are in this tier, storage fees are billed according to the regional standard storage list price.
Infrequent Access Tier (Enabled by default)
When enabling intelligent tiering for a bucket, you need to select the number of days after which to transition to the infrequent access tier, with options including 30, 60, and 90 days. Once set, it cannot be modified.
If an object remains unaccessed for a continuous period of 30 days (or 60 or 90 days), it will transition from the frequent access tier to the infrequent access tier (INFREQUENT). While the object is in this tier, storage fees are billed according to the current region's infrequent storage list price. After being accessed, the object will return to the frequent access tier.
Archive Tier (Optional)
Since objects in the archive tier must be restored before access, enabling the archive tier is optional. Users can enable the archive tier for objects with specific prefixes or tags by adding one or more intelligent tiering archive configuration rules, and set the transition days. The minimum transition period of the archive tier is 91 days, and the maximum is 730 days.
Note:
If the current region does not support archive storage, the console will not allow adding archive configuration rules, and intelligent tiering objects will not descend to the archive tier.
When intelligent tiering objects are in the archive tier, storage fees are charged according to the regional archive storage list price, and there will be no early deletion fees.
Restoring Archive Tier objects
When an object remains unaccessed for N consecutive days, it will transition from the infrequent access tier to the archive tier. Once in the archive tier, data can only be read after the object is restored via POST Object restore.
Unlike regular archive types, restoring an object from an intelligent tiering archive tier will not create a standard-type replica. Instead, the object itself will directly return to the frequent access tier.
Similar to the regular archive type, intelligent tiering archive tier objects support three retrieval modes: expedited, standard, and bulk.
Billing
intelligent tiering archive retrieval fee:
Standard retrieval and bulk retrieval are free of charge.
Expedited retrieval billing follows the same pricing as intra-regional archive storage expedited retrieval fee.
intelligent tiering archive retrieval request fee:
Standard retrieval requests and bulk retrieval requests are free of charge.
Expedited retrieval request billing follows the same pricing as intra-regional archive storage expedited retrieval request fee. Since archive storage expedited retrieval requests are currently free of charge, intelligent tiering archive expedited retrieval requests also remain free of charge to maintain consistency.
Deep Archive Tier (Optional)
Similarly, deep archive tier objects need to be restored before access. Therefore, enabling the deep archive tier is optional. Users can activate the deep archive tier for objects with specific prefixes or tags by adding one or more intelligent tiering deep archive configuration rules. It is possible to configure both the archive tier and deep archive tier transition in the same rule. It is important to note that the transition days for the deep archive tier must be at least 180 days and a maximum of 730 days, and must be greater than the transition days for the archive tier.
Note:
If the current region does not support deep archive storage, the console will not allow adding deep archive configuration rules, and intelligent tiering objects will not descend to the deep archive tier.
When intelligent tiering objects are in the deep archive tier, storage fees are charged according to the regional deep archive storage list price, and there will be no early deletion fees.
Restoring objects from the Deep Archive Tier
When an object remains unaccessed for M days, it will transition from the infrequent access tier/archive tier to the deep archive tier. Once in the deep archive tier, data can be read only after the object is restored through POST Object restore.
Unlike regular deep archive types, restoring an object from the intelligent tiering Deep Archive Tier will not produce a standard-type replica; instead, the object itself will directly return to the frequent access tier.
Similar to regular deep archive types, intelligent tiering deep archive tier objects support two retrieval modes: standard and bulk, and there will be neither retrieval fees nor retrieval request fees.
Enabling Intelligent Tiering, Archive Tier and Deep Archive Tier Configuration
Rule Description
Once a bucket is enabled with intelligent tiering configuration, the uploaded intelligent tiering objects by default only switch between the frequent access tier and the infrequent access tier. After archive and deep archive tier rules are added in the intelligent tiering configuration, switching to the archive and deep archive tiers can be enabled. Each bucket can support up to 1000 archive and deep archive tier configuration rules, with the elements included in the rules as follows. For more details on the rules, refer to the API documentation PUT Bucket IntelligentTiering.
Rule Name (Id)
Used to uniquely identify archive and deep archive rules.
Status
The archive tier and deep archive tier configuration supports enabling (Enabled) or disabling (Disabled). Even if archive/deep archive tier rules are configured, they will not be actually converted to the archive or deep archive tier when disabled.
Application Scope (Filter)
The effective range of the rules. It supports prefix filtering and tag filtering. The number of prefixes cannot exceed one, and the number of tags cannot exceed ten.
Hierarchy Settings
Supports setting the transition time for the archive tier and deep archive tier within a single rule. After the corresponding rules are set, intelligent tiering objects will start the transition to the archive and deep archive tiers. Otherwise, they will only switch between the frequent access tier and the infrequent access tier.
Archive Tier (ARCHIVE_ACCESS): Supports the setting between 91 to 730 days.
Deep Archive Tier (DEEP_ARCHIVE_ACCESS): Supports the setting between 180 to 730 days.
Note:
If both archive tier and deep archive tier conversion rules are configured in one rule, the conversion days for the deep archive tier must be greater than those for the archive tier.
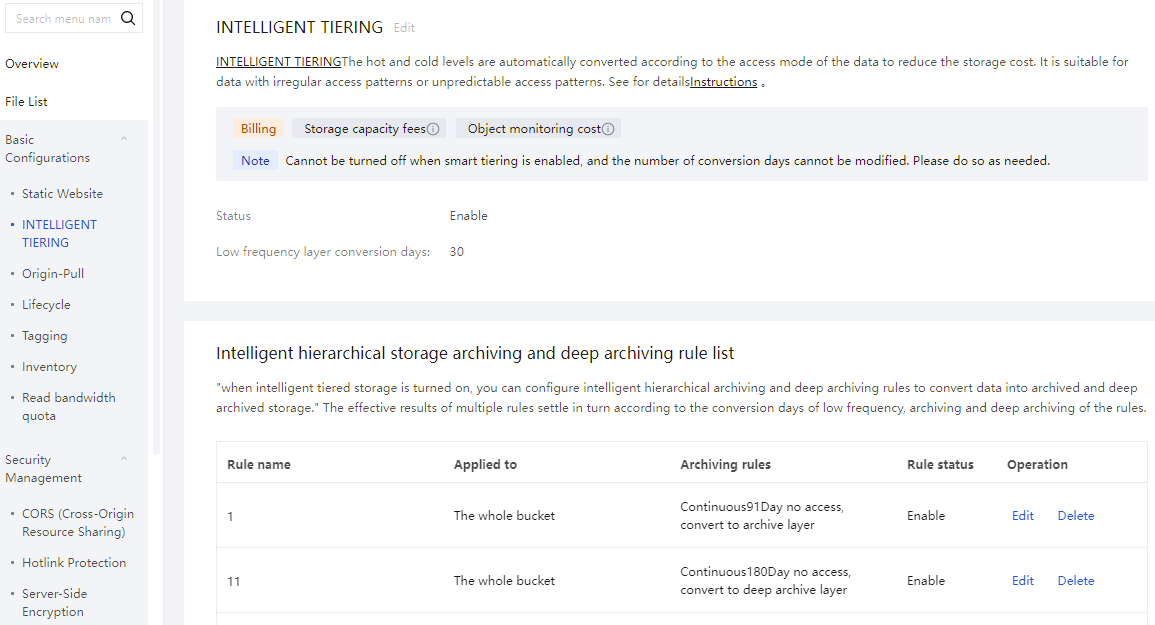
Storage Tier Transition Order
Users can enable archive tier transition and deep archive tier transition separately or enable both at the same time. The transition will proceed sequentially based on the configured days for the infrequent access tier, archive tier, and deep archive tier.
Configuration Samples | Configuration Details | Effective Result |
Sample 1 | 30 days for the infrequent access tier, 100 days for the archive tier, and 190 days for the deep archive tier | After 30 consecutive days of no access, transition from the standard access tier to the infrequent access tier will occur. After 100 consecutive days of no access, transition from the infrequent access tier to the archive tier will occur. After 190 consecutive days of no access, transition from the archive tier to the deep archive tier will occur. |
Example 2 | 30 days for the infrequent access tier, and 190 days for the deep archive tier | After 30 consecutive days of no access, transition from the standard access tier to the infrequent access tier will occur. After 190 consecutive days of no access, transition from the infrequent access tier to the deep archive tier will occur. |
Example 3 | 60 days for the infrequent access tier and 91 days for the archive tier | After 60 consecutive days of no access, transition from the standard access tier to the infrequent access tier will occur. After 91 consecutive days of no access, transitions from the infrequent access tier to the archive tier will occur. |
Restoring intelligent tiering Objects from the Archive and Deep Archive Tiers
When an object remains unaccessed for many consecutive days, it will be transitioned from the infrequent access tier to the archive/deep archive tier. Once it enters the archive or deep archive tier, it needs to be restored using POST Object restore before the data can be read.
Unlike the restoration of regular archive types and deep archive types of objects, the restoration of intelligent tiering archive and deep archive tier objects does not create a standard replica; instead, the object itself will directly return to the frequent access tier. Therefore, when initiating a retrieval request for intelligent tiering archive/deep archive tier objects, there is no need to specify the number of days for retrieval.
Similar to the regular archive types, intelligent tiering archive tier objects support expedited, standard, and bulk retrieval modes; like the regular deep archive types, intelligent tiering deep archive tier objects support standard and bulk retrieval modes.
In terms of charges, apart from the archive tier expedited retrieval fee (priced the same as the regional archive storage expedited retrieval fee), no other retrieval fees, retrieval request fees, or re-warming replica storage fees are charged.
| Archive Storage Type | Intelligent Tiering Object - Archive Tier | Deep Archive Storage Type | Intelligent Tiering Object - Deep Archive Tier | |
Storage Fee | | Storage fees are charged according to the current regional archive storage type | | Storage fees are charged according to the current regional deep archive storage type | |
Whether retrieval generates a replica | | Yes, it is necessary to specify the retention period, and replica storage fees are incurred according to standard storage pricing. | No, there will be no replica storage fees. | Yes, it is necessary to specify the retention period, and replica storage fees are incurred according to standard storage pricing. | No, there will be no replica storage fees. |
Retrieval Mode | | Expedited mode Standard mode Bulk mode | Expedited mode Standard mode Bulk mode | Standard mode Bulk mode | Standard mode Bulk mode |
Retrieval Fee (In USD/GB) | Expedited | ARCHIVE data retrieval fees (expedited) | Expedited Retrieval Fee for Intelligent Tiering Archive Tier (Same Pricing as Archiving Storage) | \\ | \\ |
Standard | ARCHIVE data retrieval fees (standard) | Free | DEEP ARCHIVE data retrieval fees (standard) | Free | |
Bulk | ARCHIVE data retrieval fees (bulk) | Free | DEEP ARCHIVE data retrieval fees (bulk) | Free | |
Retrieval Request Fees (In USD/10,000 Calls) | | not billed | not billed | Deep Archive Standard Retrieval Request Fee
Deep Archive Bulk Retrieval Request Fee | Free |
Read/Write Request Fee | | Consistent with the standard storage fee after the restoration | Intelligent Tiering Read and Write Request Fee | Deep Archive Read and Write Request Fee | Intelligent Tiering Read and Write Request Fee |
During the restoration process, you can use HeadObject to check the restoration status of intelligent tiering archive tier/deep archive tier objects.
When in the process of restoration, the response header of HEAD Object will include x-cos-restore and x-cos-restore-status. For example, x-cos-restore:ongoing-request="true", cos-restore-status:tier="bulk"; request-date="Mon, 18 Nov 2019 09:34:50 GMT".
After the restoration is complete, intelligent tiering objects directly return to the frequent access tier, and the response header `x-cos-storage-tier` of HEAD Object is `FREQUENT`.
How to Use
To store your object in the COS INTELLIGENT TIERING storage class, enable INTELLIGENT TIERING for the bucket, and then specify the storage class of your object as INTELLIGENT TIERING.
Using COS Console
Setting INTELLIGENT TIERING upon object uploads
1. Log in to the COS Console.
2. In the left menu bar, click bucket list to enter bucket list page.
3. Locate the bucket that needs intelligent tiered storage, click its name, and enter the bucket management page.
4. Click Basic Configuration > Intelligent Tiering, locate the intelligent tiering storage configuration item, click Edit to toggle on the current status, and configure according to the configuration item description.
Note:
Once intelligent tiering storage is configured, this configuration cannot be closed or suspended.
Low-frequency layer conversion days: This parameter is used to specify the time when converting to the infrequent access tier. Selectable number of days are 30, 60, and 90. For example, when set to 30 days, the system will move objects from the frequent access tier to the infrequent access tier after 30 consecutive days of no access.
5. After confirming that the configuration information is correct, click Save, complete the secondary confirmation according to the prompts, and intelligent tiering can be enabled.
6. Once enabled, intelligent tiering storage supports configuring archiving and deep archiving rules. Intelligent tiered objects within the specified range can be converted to the archive tier and deep archive tier. If you do not need to configure intelligent tiered archiving and deep archiving rules, skip to Procedure 10.
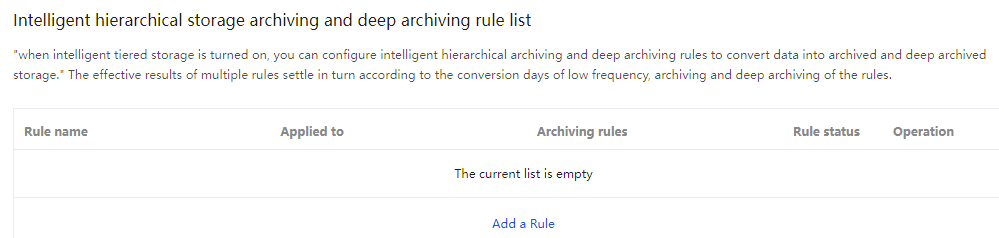
7. Click Add Rule. Configuration items are described below:
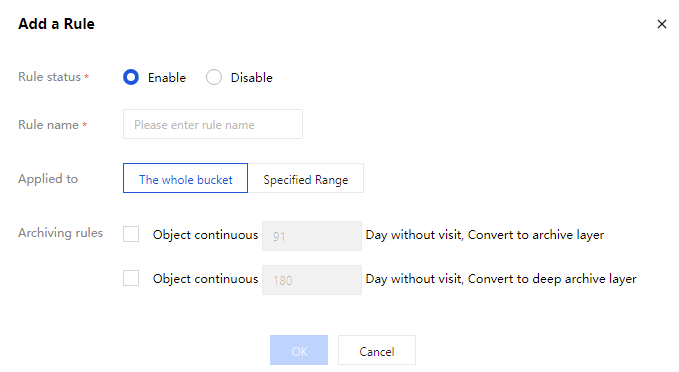
Rule name: Enter your rule name. Once created, it cannot be modified.
Application scope: These intelligent tiering archive and deep archiving rules can be applied to the entire bucket or objects in a specified range. Currently supported ranges are:
Object prefix: Specify objects with the same file prefix to execute intelligent tiering archive and deep archiving rules, such as prefix/.
Object tag: Specify objects with the same tag to execute intelligent tiering archive and deep archiving rules. A maximum of 10 tags can be specified. Case-sensitive.
Note:
You can specify both object prefix and object tag. The relationship between object prefix and object tag, or between object tags, is "AND" (all conditions must be satisfied at the same time). For example, if you set the object prefix to doc and the object tag key-value pair to
group = IT in intelligent tiering archive and deep archiving rules, the specified objects will be all objects in the current bucket with the object key prefix doc and the object tag group = IT.Archive rules: Supports configuration of the number of days for intelligent tiered objects to be switched to archive and deep archive. Configure at least one.
8. After confirming the information, click Confirm, and you will see the intelligent tiering archive and deep archiving rules.
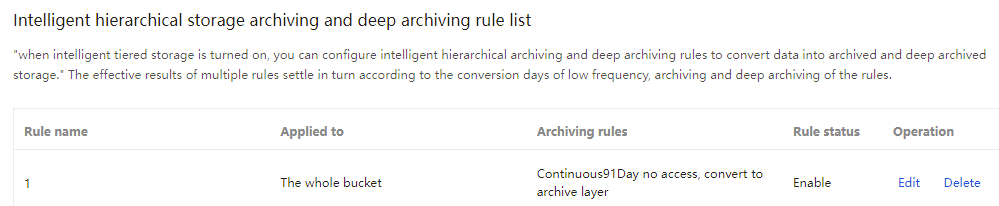
Note:
The effective result of the rules follows the configured conversion days for infrequent, archive, and deep archive tiers, settling sequentially.
For example, a user configures three rules: set the low-frequency tier conversion days to 30, set the archive tier conversion days to 100, and set the deep archive tier conversion days to 190. The effective result is: if an intelligent tiering object in the specified range has no access for 30 consecutive days, it converts from the standard tier to the low-frequency tier; if no access for 100 consecutive days, it converts from the low-frequency tier to the archive tier; if no access for 190 consecutive days, it converts from the archive tier to the deep archive tier.
9. To stop the intelligent tiering archive and deep archiving rules, click Edit, change the corresponding rule status to Disabled, or just delete the lifecycle rule.
10.
After enabling the intelligent tiering storage configuration, click File List in the left menu bar.
11. On the File List page, click Upload File.
12. In the pop-up window, select upload file, click Parameter Configuration to set object properties, and choose Intelligent Tiering Storage in the storage type configuration.
13. Click Upload to upload objects as Intelligent Tiered Storage Type. COS will automatically conduct storage tier conversion. For other configuration items about upload operation, please refer to Upload Object.
Moving in-cloud objects to INTELLIGENT TIERING
You can perform the following steps to move in-cloud objects to the INTELLIGENT TIERING storage class:
1. On the bucket configuration page, create a lifecycle rule. For detailed directions, see Setting Lifecycle.
2. Specify the application range and transition objects to INTELLIGENT TIERING.
Using the REST API
You can use the following APIs to configure INTELLIGENT TIERING:
1. Use RESTful APIs to enable INTELLIGENT TIERING for your bucket. For more information, see the following API documentation:
To enable intelligent tiering and set the transition days for the infrequent access tier:
PUT Bucket IntelligentTiering (id is not default)
GET Bucket IntelligentTiering (id is not default)
To configure or delete archive and deep archive tier rules:
PUT Bucket IntelligentTiering (id is not default)
GET Bucket IntelligentTiering (id is not default)
DELETE Bucket IntelligentTiering (id is not default)
2. After enabling INTELLIGENT TIERING for the bucket, use the following APIs to store the object in the INTELLIGENT TIERING storage class:
3. You can use the following APIs to query the storage class or storage tier of an object:
4. You can use the following RESTful APIs to delete objects in the INTELLIGENT TIERING storage class:
5. To retrieve objects from the intelligent tiering archive tier and deep archive tier, please refer to the following API: POST Object restore.
Using the SDK
Currently, all COS SDKs support INTELLIGENT TIERING. To use this storage class, set
StorageClass to INTELLIGENT_TIERING or MAZ_INTELLIGENT_TIERING when uploading an object. For more information, see Uploading Object.Use Limits
INTELLIGENT TIERING has the following limits:
Configuration Restrictions: Once intelligent tiering is enabled, it cannot be disabled. If intelligent tiering is not needed, you can modify the storage class of the files.
Conversion Days Limit: The conversion days cannot be modified once configured. The conversion days for the infrequent access tier can be 30, 60, or 90 days; for the archive tier, it must be at least 91 days and a maximum of 730 days; for the deep archive tier, it must be at least 180 days and a maximum of 730 days, and must be greater than the conversion days of the archive tier.
Initial storage tier: A new object is stored in the frequent access tier by default, and will only be moved to the infrequent access tier if it hasn’t been accessed for a certain period.
Minimum storage size: An object smaller than 64 KB can only be stored in the frequent access tier and cannot be moved between the frequent and infrequent access tiers. Objects are billed based on their actual sizes.
Operation: Uploading objects to INTELLIGENT TIERING using the APPEND Object API is not supported.
Lifecycle: Objects in the INTELLIGENT TIERING storage class can only be transitioned to ARCHIVE or DEEP ARCHIVE. If a STANDARD object is transitioned to INTELLIGENT TIERING, it will be stored in the frequent access tier. If a STANDARD_IA object is transitioned to INTELLIGENT TIERING, it will be stored in the infrequent access tier.
Bucket replication: During bucket replication, if INTELLIGENT TIERING is not enabled for the destination bucket, the object cannot be copied to the INTELLIGENT TIERING storage class.
FAQs
How is INTELLIGENT TIERING billed?
INTELLIGENT TIERING fees include INTELLIGENT TIERING storage usage fees and INTELLIGENT TIERING object monitoring fees.
INTELLIGENT TIERING storage usage fees are charged differently depending on the storage tier of objects.
When objects are stored in the frequent access tier, STANDARD storage usage fees are charged.
When objects are stored in the infrequent access tier, STANDARD_IA storage usage fees are charged.
Note:
STANDARD and STANDARD_IA storage usage fees vary by region. For details about their pricing, see Product Pricing.
Request fees and traffic fees are also incurred during object upload and download. For the billing examples, see Traffic Fee Billing Example and Request Fee Billing Example.
INTELLIGENT TIERING object monitoring fees are charged based on the number of objects stored (excluding files smaller than 64 KB). For detailed pricing, see Pricing | Cloud Object Storage.
Example
Suppose an organization has 100,000 objects (all above 64 KB, 1 TB in total), and the data is stored in the INTELLIGENT TIERING storage class in Beijing region and transitioned to the infrequent access tier after 30 days. If 20% of the objects (i.e., 20,000 objects) are transitioned to the infrequent access tier every 30 days, the object monitoring fees and storage usage fees for every 30 days will be as follows:
Note:
In the table below, the object monitoring fees for Beijing region are 0.25 USD/10,000 objects per 30 days, that is, 0.00833333 (0.25 / 30) USD/10,000 objects per day.
Storage Days | 30-day Object Monitoring Fees (USD) | 30-day INTELLIGENT TIERING Storage Usage Fees (USD) | 30-day STANDARD Storage Usage Fees (USD) |
30 * 1 | 0.25/10,000 objects * 100,000 | 1024 * 0.024 / 30 * 30 = 24.58 | 1024 * 0.024 / 30 * 30 = 24.58 |
30 * 2 | 0.25/10,000 objects * 100,000 | 819.2 * 0.024 / 30 * 30 + 204.8 * 0.08 / 30 * 30 = 23.35 | 1024 * 0.024 / 30 * 30 = 24.58 |
30 * 3 | 0.25/10,000 objects * 100,000 | 655.36 * 0.024 / 30 * 30 + 368.64 * 0.08 / 30 * 30 = 22.36 | 1024 * 0.024 / 30 * 30 = 24.58 |
30 * 4 | 0.25/10,000 objects * 100,000 | 524.288 * 0.024 / 30 * 30 + 499.712 * 0.08 / 30 * 30 = 21.58 | 1024 * 0.024 / 30 * 30 = 24.58 |
30 * 5 | 0.25/10,000 objects * 100,000 | 419.4304 * 0.024 / 30 * 30 + 604.5696 * 0.08 / 30 * 30 = 20.95 | 1024 * 0.024 / 30 * 30 = 24.58 |
30 * 6 | 0.25/10,000 objects * 100,000 | 335.54432 * 0.024 / 30 * 30 + 688.45568 * 0.08 / 30 * 30 = 20.45 | 1024 * 0.024 / 30 * 30 = 24.58 |
As you can see, using INTELLIGENT TIERING reduces storage costs over time. Only a small amount of monitoring cost is required every 30 days.
What types of objects is INTELLIGENT TIERING suitable for?
INTELLIGENT TIERING is suitable for large objects (such as audio and video, logs, etc.) whose access patterns change. Larger average object sizes mean you pay less for monitoring per GB objects. If your business has relatively fixed data access patterns, you can set lifecycle configuration to specify the time to transition objects to STANDARD_IA without the need to use INTELLIGENT TIERING.
How can I store objects in INTELLIGENT TIERING?
You can store objects in INTELLIGENT TIERING as follows:
Incremental objects: You just need to specify the storage class as INTELLIGENT TIERING when uploading the objects.
Existing objects: You can modify the storage class to INTELLIGENT TIERING using the
COPY API. You can also use the lifecycle feature to transition STANDARD or STANDARD_IA objects to INTELLIGENT TIERING.Note:
In INTELLIGENT TIERING, objects smaller than 64 KB will always be stored in STANDARD. Therefore, for objects smaller than 64 KB, we recommend you upload them to the STANDARD, STANDARD_IA, ARCHIVE, or DEEP ARCHIVE storage class as needed to reduce costs.
How do I disable INTELLIGENT TIERING configuration?
INTELLIGENT TIERING configuration can't be disabled once enabled. If you don't need to store your objects in INTELLIGENT TIERING, you just need to specify the storage class as a non-INTELLIGENT TIERING class such as STANDARD, STANDARD_IA, ARCHIVE, or DEEP ARCHIVE when uploading the objects.
The rules for intelligent tiering archive tier/deep archive tier support deletion. You can delete the corresponding rules to prevent new INT objects from descending into the archive tier/deep archive tier.
How are charges applied for archiving in the intelligent tiering and deep archive tier?
Storage fee: Charged according to the regional archive and deep archive storage fees.
Retrieval fee and retrieval request fee: Apart from the expedited retrieval fees for the archive tier, no other retrieval fees nor retrieval request fees are charged.
Rewarming replica fee: Not charged.
Bantuan dan Dukungan
Apakah halaman ini membantu?
Anda juga dapat Menghubungi Penjualan atau Mengirimkan Tiket untuk meminta bantuan.
masukan