数据表管理
Download
聚焦模式
字号
用户可以使用数据湖计算 DLC 控制台或者 API,执行 DDL 语句创建数据库。
创建数据表
途径一:在数据探索进行创建
1. 登录 数据湖计算 DLC 控制台,选择服务所在区域,登录用户需要有创建数据表的权限。
2. 进入 数据探索 模块,在左侧列表中,单击已有数据库,鼠标悬停表行,然后单击
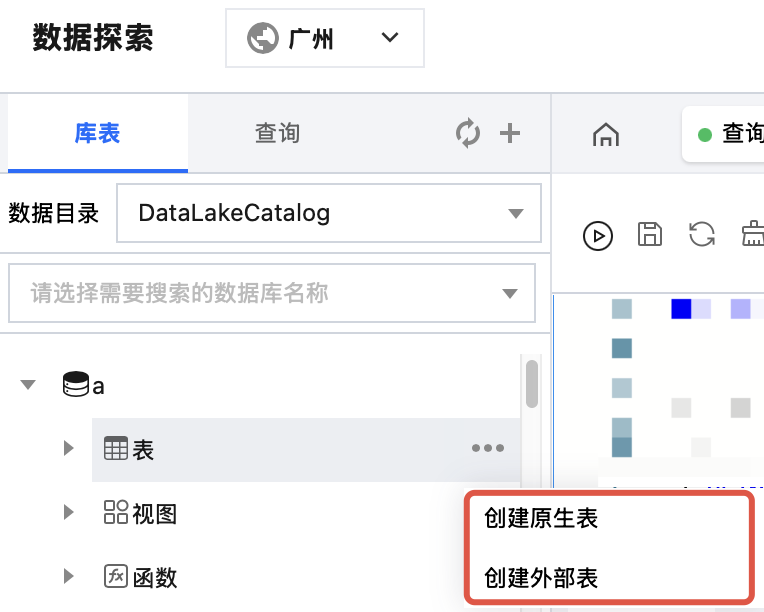
说明:
原生表是指 DLC 托管存储上的表,原生表您无需关注底层 Iceberg 存储格式,且具备数据优化等能力。使用原生表需要先开启托管存储,详情参考托管存储配置。
外部表的底层数据在您自己的对象存储上,创建外部表需要指定数据路径。
3. 单击 创建原生表/创建外部表 后,系统会自动在生成创建数据表的 SQL 模板,用户可以修改 SQL 模板创建数据表。单击 运行 按钮后,执行创建数据表的 SQL 语句,完成创建。
途径二:在数据管理进行创建
数据管理模块支持管理托管存储于 DLC 的原生表及外部表。
1. 登录 数据湖计算 DLC 控制台,选择服务所在区域,登录用户需要有创建数据表的权限。
2. 通过左侧菜单进入元数据管理,进入数据库,单击数据表所在的数据库名称,进入数据库管理页面。
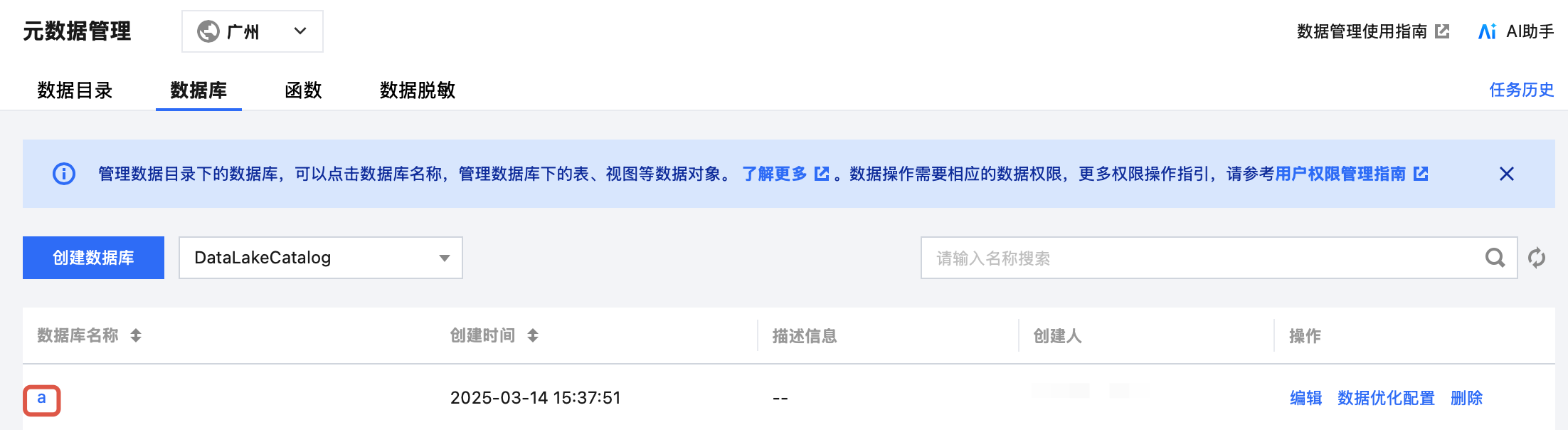
3. 单击创建原生表或创建外部表按钮,进入数据表配置页面。
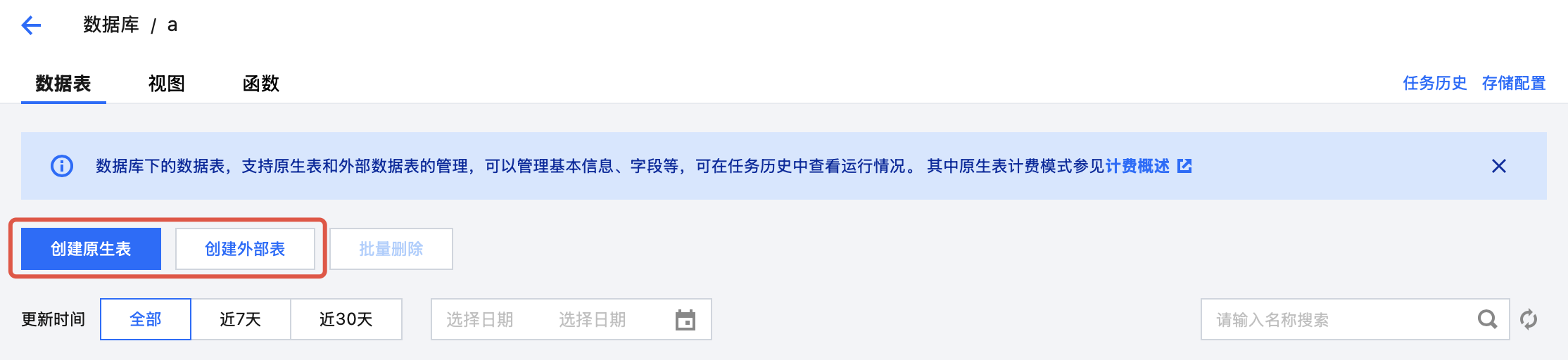
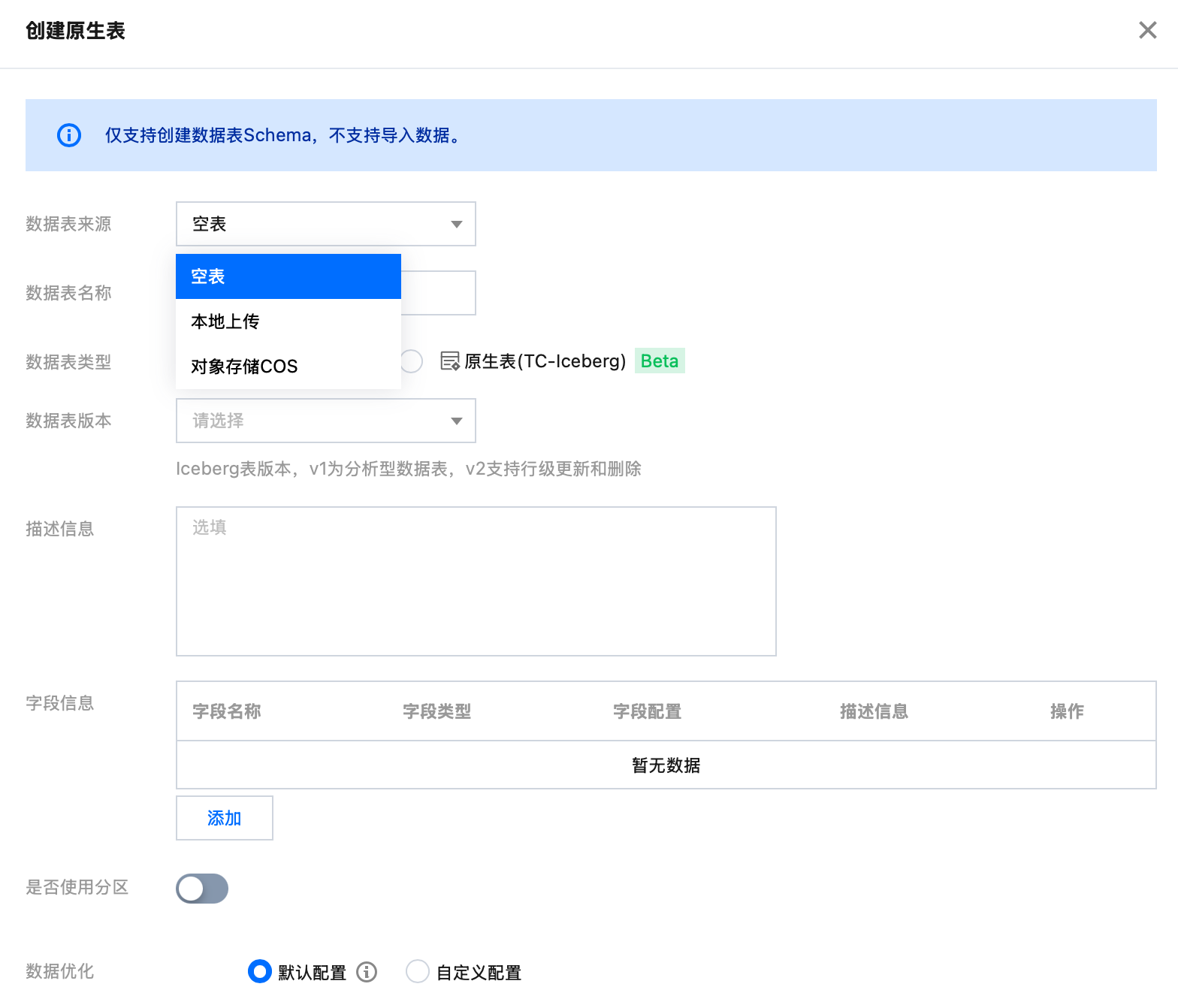
4. 原生表数据来源支持空表、本地上传、对象存储 COS 三种不同类型,选择不同数据来源对应不同的创建流程。原生表支持数据优化等能力,可以选择继承库治理规则或单独启闭。
4.1 创建空表:创建一个没有记录的空表。
数据表名称:非数字开头,支持大小写字母、数字及下划线—,最多128个字符。
支持填写数据表描述信息。
可手动添加和输入列名称和字段类型。支持 array/map/struct 三种复杂类型字段的配置。
4.2 本地上传:将本地表单文件上传至 DLC 形成数据表,支持100MB 以内的文件。
CSV:支持可视化配置解析 CSV 规则,包括压缩格式、列分割符号、字段域符。支持自动推断数据文件的 Schema 和将首行解析为列名。
Json:DLC 仅将 Json 的第一层级识别为列,支持自动推断 Json 文件的 Shema,系统会将 Json 第一层字段识别为列名。
支持 Parquet、ORC、AVRO 等常见大数据格式数据文件。
可手动添加和输入列名称和字段类型。
若选择了自动推断结构,DLC 会自动填充识别到的列、列名称、字段类型,若不正确请手动修改。
4.3 通过对象存储 COS 创建数据表。
通过读取当前账户下的COS数据桶进行数据表创建。
CSV:支持可视化配置解析 CSV 规则,包括压缩格式、列分割符号、字段域符。支持自动推断数据文件的 Schema 和将首行解析为列名。
Json:DLC 仅将 Json 的第一层级识别为列,支持自动推断 Json 文件的 Shema,系统会将 Json 第一层字段识别为列名。
支持 Parquet、ORC、AVRO 等常见大数据格式数据文件。
可手动添加和输入列名称和字段类型。
若选择了自动推断结构,DLC 会自动填充识别到的列、列名称、字段类型,若不正确请手动修改。
5. 数据分区通常为提高查询性能,会对大数据量的表进行分区。DLC 支持按照数据分区查询数据,用户需要在此步骤添加分区信息。通过分区您的数据,您可以限制每个查询扫描的数据量,从而提高查询性能并降低使用成本。DLC 遵从 Apache Hive 的分区规则。
分区列对应表的 COS 路径下的一个子目录,目录的命名规则为分区列名=分区列值。
示例:
说明:
示例代码仅供参考,需要根据实际业务场景进行修改。例如将“bucket_name”替换为您的存储桶名称。
cosn://nanjin-bucket/CSV/year=2021/month=10/day=10/demo1.csvcosn://nanjin-bucket/CSV/year=2021/month=10/day=11/demo2.csv
如果有多个分区列,则需要按照建表语句中指定的分区列顺序依次嵌套。
CREATE EXTERNAL TABLE IF NOT EXISTS `COSDataCatalog`.`dlc_demo`.`table_demo` (`_c0` string,`_c1` string,`_c2` string,`_c3` string) PARTITIONED BY (`year` string, `month` string, `day` string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ('separatorChar' = ',', 'quoteChar' = '"')STORED AS TEXTFILELOCATION 'cosn://bucket_name/folder_name/';
查询数据表基本信息
途径一:在数据探索中进行查询
在数据表项目中,鼠标悬停数据表名称行,然后单击
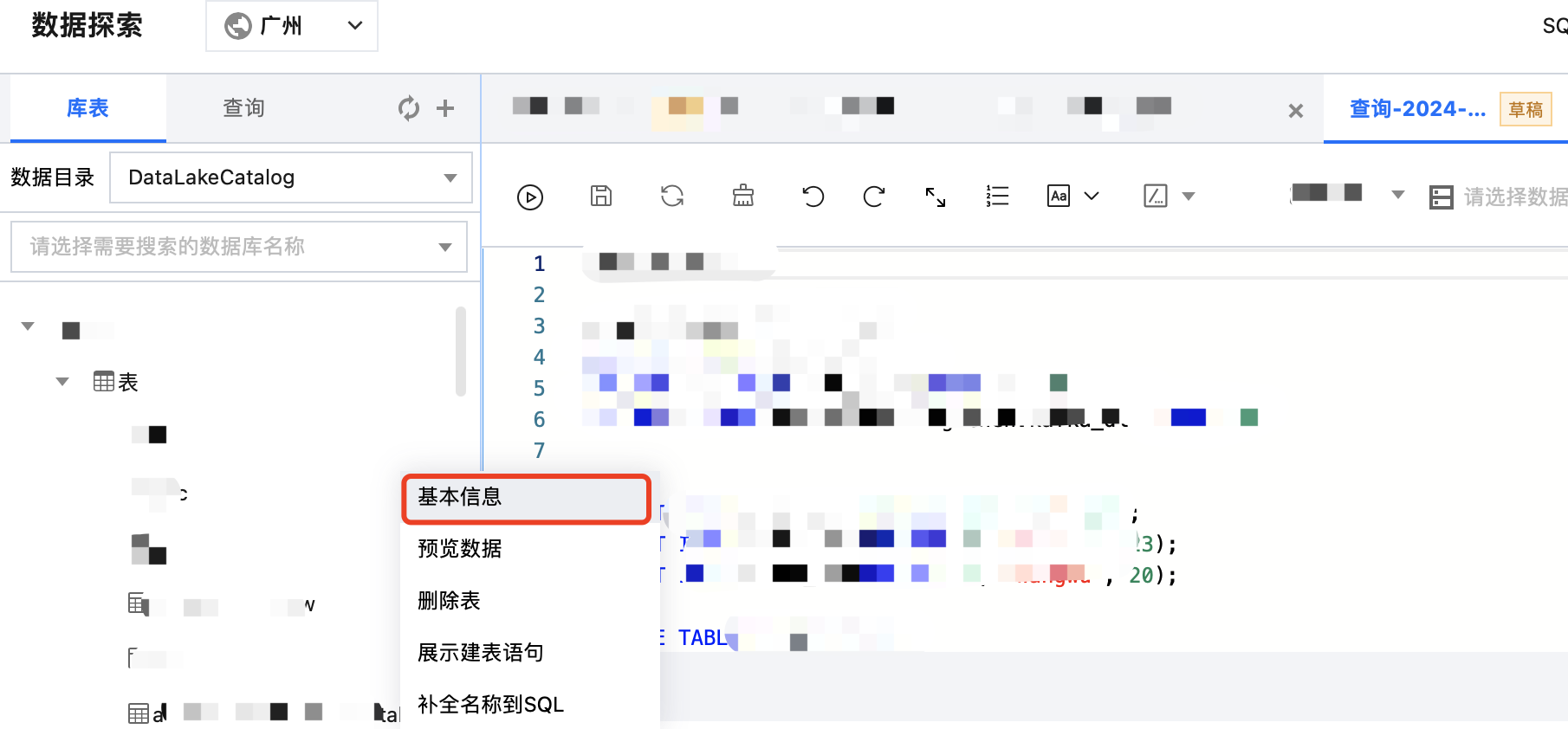
数据表基本信息如下:
途径二:在数据管理进行查看
1. 登录数据湖计算 DLC 控制台,选择服务所在区域,登录用户需要有查看数据表的权限。
2. 通过左侧菜单进入元数据管理模块,在数据库页面下,单击数据表所在的数据库名称,进入数据库管理页面,支持查询数据表的行数、存储空间、创建人、字段、分区等信息。
自助查询数据表分区信息
说明:
下方示例需要根据您的实际业务场景替换数据库名和表名称。
SuperSQL Spark SQL 引擎:
select * from `DataLakeCatalog`.`db`.`tb$partitions`
SuperSQL 作业引擎和标准引擎:
select * from `DataLakeCatalog`.`db`.`tb`.`partitions`
查询数据表分区信息
数据表管理支持查询数据表的分区相关信息,通过分区信息,用户可以查看表各个分区的记录数、文件数量、数据存储量及更新时间等信息。
1. 登录 数据湖计算 DLC 控制台,选择服务所在区域,登录用户需要有查看数据表的权限。
2. 通过左侧菜单进入元数据管理,进入数据库,单击数据表所在的数据库名称,进入数据库管理页面。
3. 选择数据库,进入数据表管理页面,选择数据表点击,选择分区信息,进入分区信息显示页面。
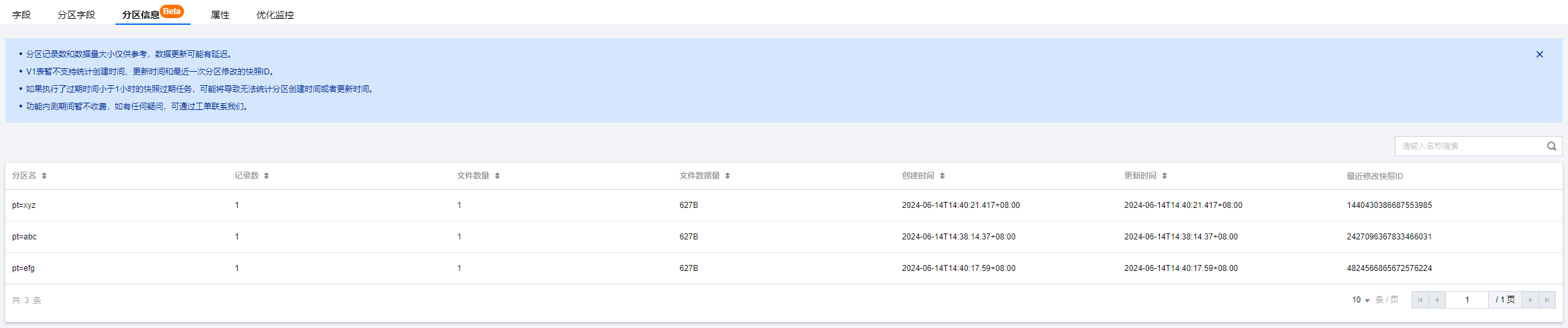
数据分区页面分页显示查看表的分区信息,用户可根据名称、记录数、文件数据、文件存储量等字段排序,查询分区信息的分区情况。如用户想查看某个固定的分区,可通过输入名称分区名称进行搜索。
说明:
1. 分区信息统计目前只支持统计 DLC 原生表。
2. 分区信息统计当前处于 Beta 测试阶段,如用户要开启分区信息统计,请联系我们。
预览数据表数据
在数据表项目中,鼠标悬停数据表名称行,然后单击
数据预览功能默认展示前100条数据。
编辑数据表信息
支持在数据管理模块编辑数据表的描述信息。
1. 登录 数据湖计算 DLC 控制台,选择服务所在区域,登录用户需要有编辑数据表的权限。
2. 通过左侧菜单进入元数据管理 > 数据库页面,单击数据表所在的数据库名称,进入数据库管理页面。
3. 找到需要编辑的数据,单击右侧的编辑按钮进行编辑。
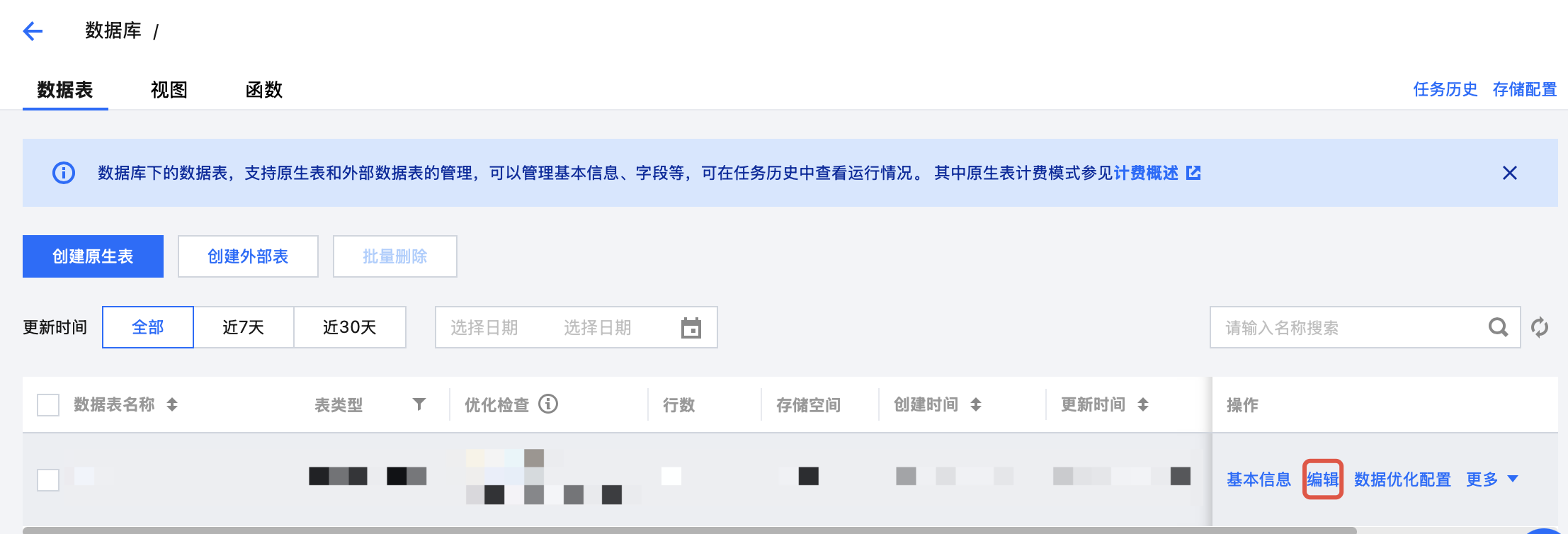
4. 修改后单击确定按钮即可完成编辑。
删除数据表
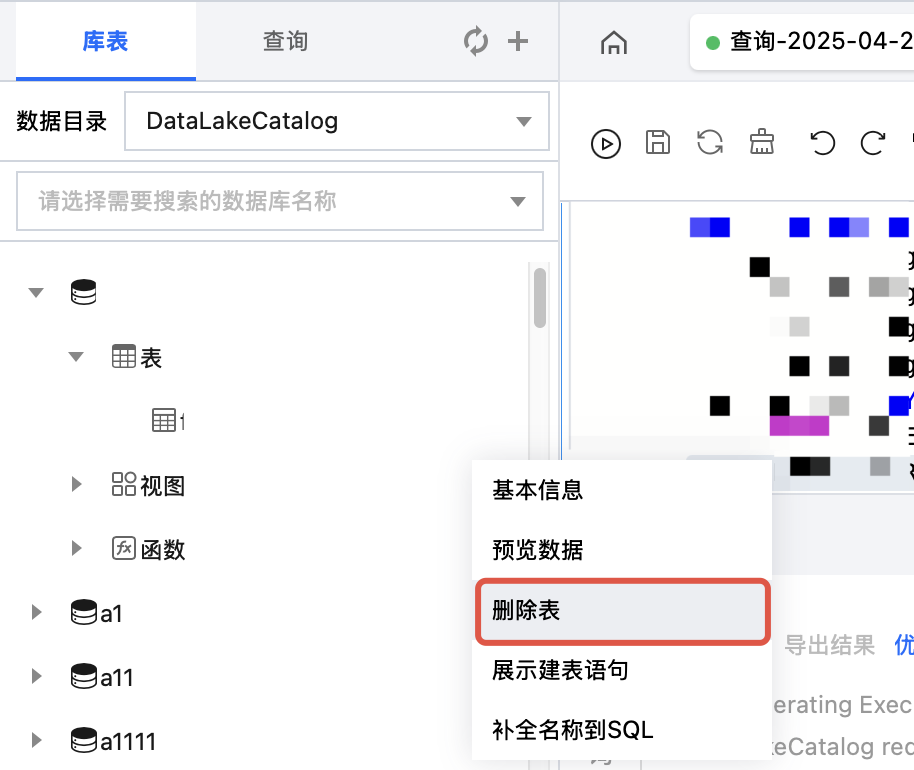
途径一:在数据探索进行删除
在数据表项目中,鼠标悬停数据表名称行,然后单击
删除外表,删除数据表仅是删除 DLC 中存储的元数据信息,不会影响数据源文件。
删除DataLakeCatalog目录下的数据表,将会清空所有该数据表数据,请谨慎操作。
途径二:在数据管理进行删除
目前数据管理内仅支持管理托管存储于DLC的数据库表,外表请使用途径一进行删除。
1. 登录数据湖计算 DLC 控制台,选择服务所在区域,登录用户需要有删除数据表的权限。
2. 通过左侧菜单进入元数据管理 > 数据库,单击数据表所在的数据库名称,进入数据库管理页面。
3. 单击需要删除的数据表右方的删除按钮,二次确认后可删除对应的数据表,同时清空数据表数据。
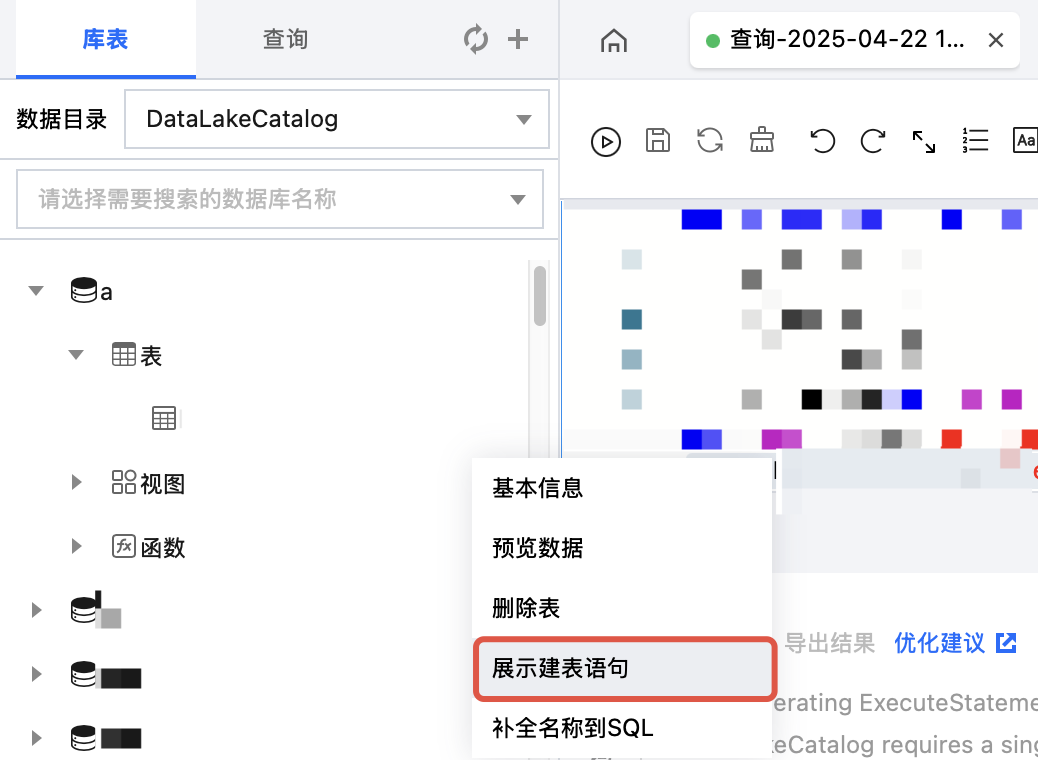
展示建表语句
在数据表项目中,鼠标悬停数据表名称行,然后单击
系统约束
DLC 允许每个数据库下的数据表最大数量为4096个,每个数据表支持的最大分区数为100,000,每个数据表的属性列最大数量为4096个。
DLC 会把相同 COS 路径下的数据文件识别为同一张表的数据,请确保在单独的文件夹层次结构中保留单独表的数据。
DLC 不支持 COS 多版本数据,只能查询 COS 存储桶中最新版本的数据。
DLC 上创建的所有表是外表,在创建表的 SQL 语句中必须包含 EXTERNAL 关键字。
表名称在同一个数据库下必须唯一。
表名称不区分大小写,仅支持英文字符、数字和下划线(_),最长为128个字符。
若表为分区表时,需要手动执行 ADD PARTITION 语句或者 MSCK 语句,添加分区信息,才能查询到该分区数据。详情可参见 查询分区表。
使用 CSV 建表时,DLC 会默认把所有字段类型转化为 string,但是不影响原数据字段的计算和查询。
文档反馈