跨源分析 EMR Hive 数据
Download
聚焦模式
字号
数据湖计算 DLC 支持配置 EMR Hive 的数据源进行跨源联合分析。
说明:
标准引擎-presto暂不支持该功能,可使用 SuperSQL 类型的引擎及标准引擎-spark进行分析。
使用前准备
获取 EMR Hive 地址。
使用具备创建数据目录权限的账号,详细权限请参见 DLC 权限概述。
创建 EMR Hive 数据源
1. 登录 数据湖计算 DLC 控制台,选择服务地域。
2. 通过左侧导航栏进入数据探索,单击库表栏的+按钮,选择新建数据目录。
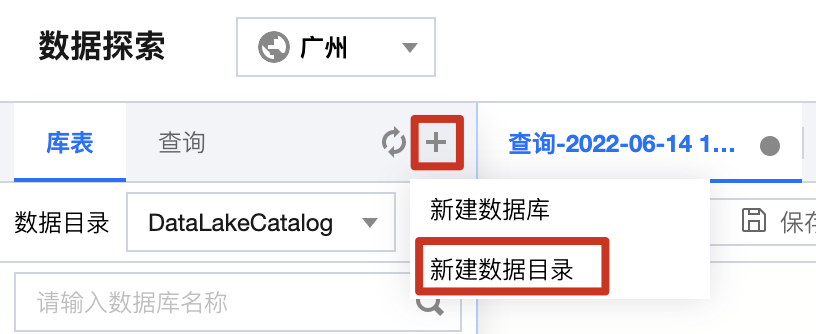
3. 选择连接类型为 EMR Hive(HDFS),选择 EMR 的对应实例,VPC 信息将在实例选择后默认填充。EMR Hive 支持 EMR 的版本:2.3.5,2.3.7,3.1.1,3.1.2。
注意:
需具备 EMR Hive 实例的相关权限才可进行选择。
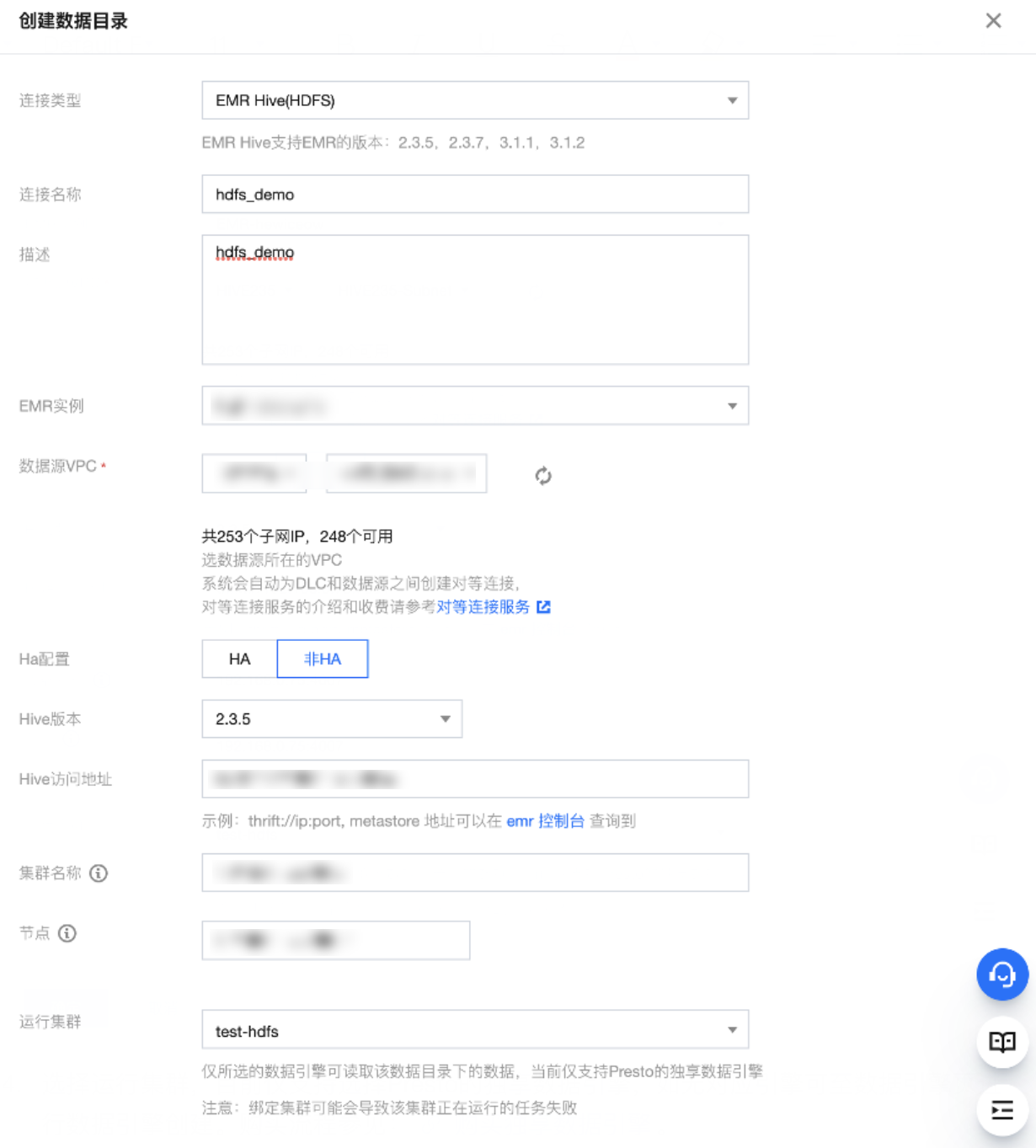
4. 选择运行集群,目前仅支持选择Presto的独享数据引擎,如无对应引擎可至数据引擎页进行数据引擎创建。购买流程请参见 购买独享数据引擎。
注意:
所选数据引擎网段不可与 EMR 实例网段相同,否则将导致网络冲突,无法进行数据查询分析。
5. 单击确认按钮即可完成数据目录创建。
查询 EMR Hive 数据
完成数据目录创建之后,即可在数据探索页的数据目录菜单进行数据目录切换。
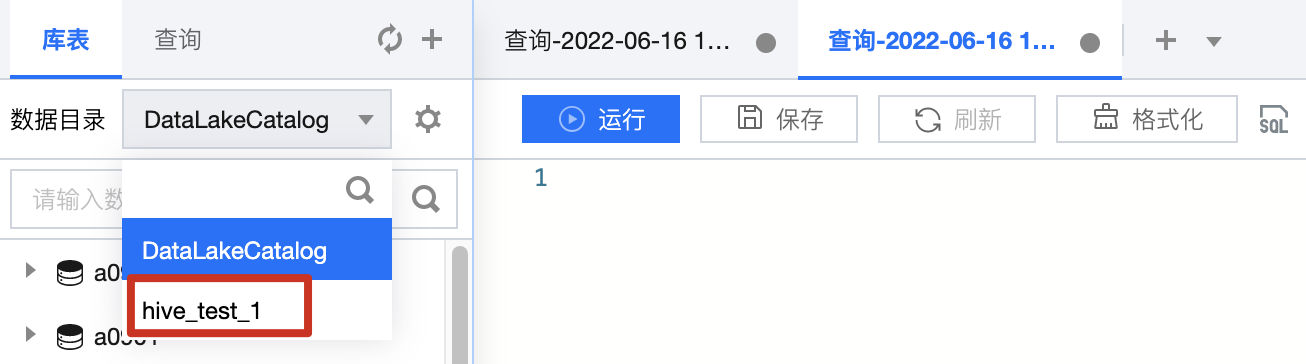
注意:
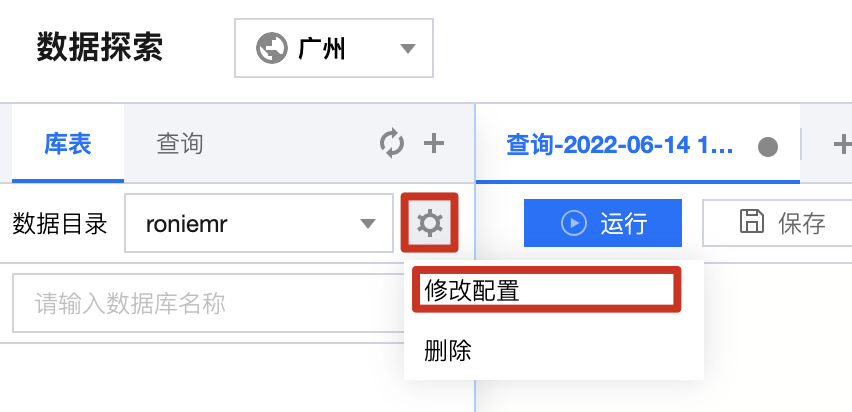
仅绑定的数据引擎可查询该数据目录,其他数据引擎将无法进行查询。如需变更绑定的引擎,可单击数据目录判的设置按钮就行编辑修改。
文档反馈